










基础常识
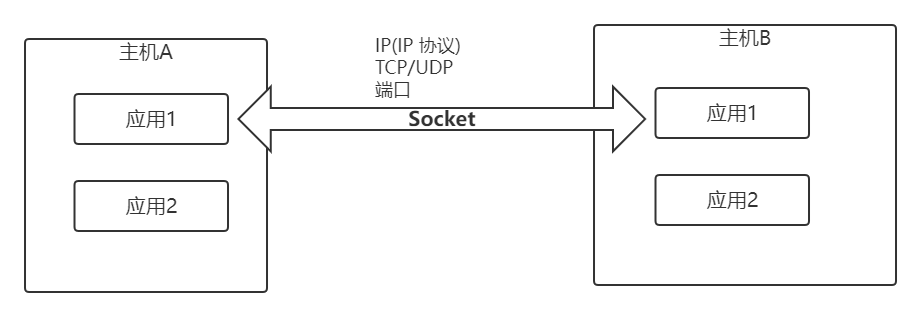
Socket是应用层与TCP/IP协议族通信的中间软件抽象层,它是一组接口。在设计模式中,Socket其实就是一个门面模式,它把复杂的TCP/IP协议族隐藏在Socket接口后面,对用户来说,一组简单的接口就是全部,让Socket去组织数据,以符合指定的协议。
主机 A 的应用程序要能和主机 B 的应用程序通信,必须通过 Socket 建立连接,而建立 Socket 连接必须需要底层TCP/IP 协议来建立 TCP 连接。建立 TCP 连接需要底层 IP 协议来寻址网络中的主机。
网络层使用的 IP 协议可以帮助我们根据 IP 地址来找到目标主机,但是一台主机上可能运行着多个应用程序,如何才能与指定的应用程序通信就要通过 TCP 或 UPD 的地址也就是端口号来指定。这样就可以通过一个 Socket 实例唯一代表一个主机上的一个应用程序的通信链路了。
短连接与长连接
短连接:
连接->传输数据->关闭连接
传统HTTP是无状态的,浏览器和服务器每进行一次HTTP操作,就建立一次连接,但任务结束就中断连接。
也可以这样理解:短连接是指SOCKET连接后发送后接收完数据后马上断开连接。
长连接:
连接->传输数据->保持连接 -> 传输数据-> .........->关闭连接。
长连接指建立SOCKET连接后不管是否使用都保持连接。
那我们如何选择,什么时候用长连接,什么时候用短连接?
长连接多用于操作频繁,点对点的通讯,而且连接数不能太多情况,。每个TCP连接都需要三步握手,这需要时间,如果每个操作都是先连接,再操作的话那么处理速度会降低很多,所以每个操作完后都不断开,下次处理时直接发送数据包就OK了,不用建立TCP连接。例如:数据库的连接用长连接, 如果用短连接频繁的通信会造成socket错误,而且频繁的socket 创建也是对资源的浪费。
而像WEB网站的http服务一般都用短链接,因为长连接对于服务端来说会耗费一定的资源,而像WEB网站这么频繁的成千上万甚至上亿客户端的连接用短连接会更省一些资源。
也就是说,长连接和短连接的选择要视情况而定。
网络通讯流程
在通信编程里提供服务的叫服务端,连接服务端使用服务的叫客户端。
在开发过程中,如果类的名字有Server或者ServerSocket的,表示这个类是给服务端容纳网络服务用的,如果类的名字只有Socket的,那么表示这是负责具体的网络读写的。那么对于服务端来说ServerSocket就只是个场所(娱乐场所),具体和客户端沟通的还是一个一个的socket(娱乐事件),所以在通信编程里,ServerSocket并不负责具体的网络读写,ServerSocket就只是负责接收客户端连接后,新启一个socket来和客户端进行沟通。这一点对所有模式的通信编程都是适用的。
在通信编程里,我们关注的是如下三个方面:
1、连接(客户端连接服务器,服务器等待和接收连接)
2、读网络数据
3、写网络数据
所有模式的通信编程都是围绕着这三件事情进行的。服务端提供IP和监听端口,客户端通过连接操作想服务端监听的地址发起连接请求,通过三次握手连接,如果连接成功建立,双方就可以通过套接字进行通信。
JDK网络编程(BIO)
传统的同步阻塞模型开发中,ServerSocket负责绑定IP地址,启动监听端口;Socket负责发起连接操作。连接成功后,双方通过输入和输出流进行同步阻塞式通信。代码如下:
public class Client {
public static void main(String[] args) throws IOException {
//客户端启动必备
Socket socket = null;
//实例化与服务端通信的输入输出流
ObjectOutputStream output = null;
ObjectInputStream input = null;
//服务器的通信地址
InetSocketAddress addr = new InetSocketAddress("127.0.0.1",10001);
try{
socket = new Socket();
/*连接服务器*/
socket.connect(addr);
output = new ObjectOutputStream(socket.getOutputStream());
input = new ObjectInputStream(socket.getInputStream());
/*向服务器输出请求*/
output.writeUTF("lijin");
output.flush();
//接收服务器的输出
System.out.println(input.readUTF());
}finally{
if (socket!=null) socket.close();
if (output!=null) output.close();
if (input!=null) input.close();
}
}
}
public class Server {
public static void main(String[] args) throws IOException {
/*服务器必备*/
ServerSocket serverSocket = new ServerSocket();
/*绑定监听端口*/
serverSocket.bind(new InetSocketAddress(10001));
System.out.println("Server start.......");
while(true){
new Thread(new ServerTask(serverSocket.accept())).start();
}
}
private static class ServerTask implements Runnable{
private Socket socket = null;
public ServerTask(Socket socket) {
this.socket = socket;
}
@Override
public void run() {
/*拿和客户端通讯的输入输出流*/
try(
ObjectInputStream inputStream = new ObjectInputStream(socket.getInputStream());
ObjectOutputStream outputStream = new ObjectOutputStream(socket.getOutputStream())
){
/*服务器的输入*/
String userName = inputStream.readUTF();
System.out.println("Accept clinet message:"+userName);
outputStream.writeUTF("Hello,"+userName);
outputStream.flush();
}catch (Exception e){
e.printStackTrace();
}
finally {
try {
socket.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
以上代码是传统BIO通信模型:采用BIO通信模型的服务端,通常由一个独立的Acceptor线程负责监听客户端的连接,它接收到客户端连接请求之后为每个客户端创建一个新的线程进行链路处理,处理完成后,通过输出流返回应答给客户端,线程销毁。即典型的一请求一应答模型,同时数据的读取写入也必须阻塞在一个线程内等待其完成。该模型最大的问题就是缺乏弹性伸缩能力,当客户端并发访问量增加后,服务端的线程个数和客户端并发访问数呈1:1的正比关系,Java中的线程也是比较宝贵的系统资源,线程数量快速膨胀后,系统的性能将急剧下降,随着访问量的继续增大,系统最终就死掉了。
为了改进这种一连接一线程的模型,我们可以使用线程池来管理这些线程,实现1个或多个线程处理N个客户端的模型(但是底层还是使用的同步阻塞I/O),通常被称为“伪异步I/O模型“。
public class ServerPool {
private static ExecutorService executorService
= Executors.newFixedThreadPool(
Runtime.getRuntime().availableProcessors());
public static void main(String[] args) throws IOException {
//服务端启动必备
ServerSocket serverSocket = new ServerSocket();
//表示服务端在哪个端口上监听
serverSocket.bind(new InetSocketAddress(10001));
System.out.println("Start Server ....");
try{
while(true){
executorService.execute(new ServerTask(serverSocket.accept()));
}
}finally {
serverSocket.close();
}
}
//每个和客户端的通信都会打包成一个任务,交个一个线程来执行
private static class ServerTask implements Runnable{
private Socket socket = null;
public ServerTask(Socket socket){
this.socket = socket;
}
@Override
public void run() {
//实例化与客户端通信的输入输出流
try(ObjectInputStream inputStream =
new ObjectInputStream(socket.getInputStream());
ObjectOutputStream outputStream =
new ObjectOutputStream(socket.getOutputStream())){
//接收客户端的输出,也就是服务器的输入
String userName = inputStream.readUTF();
System.out.println("Accept client message:"+userName);
//服务器的输出,也就是客户端的输入
outputStream.writeUTF("Hello,"+userName);
outputStream.flush();
}catch(Exception e){
e.printStackTrace();
}finally {
try {
socket.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
RPC框架
为什么要有RPC?
以前我们是一个应用使用一台机器部署,将所有功能和模块都写在一起,比如电商系统
随着业务和技术发展,我们需要提高性能,后面就会将不同的业务功能放到线程里来实现异步和提升性能。
但是业务越来越复杂,业务量越来越大,单个应用或者一台机器的资源是肯定背负不起的,这个时候,那会怎么做呢?
将核心业务抽取出来,作为独立的服务,放到其他服务器上或者形成集群。这个时候就会请出RPC,系统变为分布式的架构。
为什么说千万级流量分布式、微服务架构必备的RPC框架?和LocalCall的代码进行比较,因为引入rpc框架对我们现有的代码影响最小,同时又可以帮我们实现架构上的扩展。现在的开源rpc框架,有什么?dubbo,grpc等等
当服务越来越多,各种rpc之间的调用会越来越复杂,这个时候我们会引入中间件,比如说MQ、缓存,同时架构上整体往微服务去迁移,引入了各种比如容器技术docker,DevOps等等。最终会变为如图所示来应付千万级流量,但是不管怎样,rpc总是会占有一席之地。
什么是RPC?
RPC(Remote Procedure Call ——远程过程调用),它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络的技术。
一次完整的RPC同步调用流程:
1)服务消费方(client)以本地调用方式调用客户端存根;
2)什么叫客户端存根?就是远程方法在本地的模拟对象,一样的也有方法名,也有方法参数,client stub接收到调用后负责将方法名、方法的参数等包装,并将包装后的信息通过网络发送到服务端;
3)服务端收到消息后,交给代理存根在服务器的部分后进行解码为实际的方法名和参数
4) server stub根据解码结果调用服务器上本地的实际服务;
5)本地服务执行并将结果返回给server stub;
6)server stub将返回结果打包成消息并发送至消费方;
7)client stub接收到消息,并进行解码;
8)服务消费方得到最终结果。
RPC框架的目标就是要中间步骤都封装起来,让我们进行远程方法调用的时候感觉到就像在本地调用一样。
RPC和HTTP
rpc字面意思就是远程过程调用,只是对不同应用间相互调用的一种描述,一种思想。具体怎么调用?实现方式可以是最直接的tcp通信,也可以是http方式,在很多的消息中间件的技术书籍里,甚至还有使用消息中间件来实现RPC调用的,我们知道的dubbo是基于tcp通信的,gRPC是Google公布的开源软件,基于最新的HTTP2.0协议,底层使用到了Netty框架的支持。所以总结来说,rpc和http是完全两个不同层级的东西,他们之间并没有什么可比性。
实现RPC框架
实现RPC框架需要解决的那些问题
代理问题
代理本质上是要解决什么问题?要解决的是被调用的服务本质上是远程的服务,但是调用者不知道也不关心,调用者只要结果,具体的事情由代理的那个对象来负责这件事。既然是远程代理,当然是要用代理模式了。
代理(Proxy)是一种设计模式,即通过代理对象访问目标对象.这样做的好处是:可以在目标对象实现的基础上,增强额外的功能操作,即扩展目标对象的功能。那我们这里额外的功能操作是干什么,通过网络访问远程服务。
jdk的代理有两种实现方式:静态代理和动态代理。
public class Client2 {
//远程调用类
public static IUserService getStub() throws Exception{
//创建代理类
InvocationHandler handler = new InvocationHandler() {
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
Socket socket = new Socket("127.0.0.1", 8888);
ByteArrayOutputStream out = new ByteArrayOutputStream();
DataOutputStream dos = new DataOutputStream(out);
dos.writeInt(13);
socket.getOutputStream().write(out.toByteArray());
socket.getOutputStream().flush();
DataInputStream dis = new DataInputStream(socket.getInputStream());
int ReceId = dis.readInt();
String name = dis.readUTF();
User user = new User(ReceId, name);
dos.close();
socket.close();
return user;
}
};
//执行动态代理(传入类加载器、接口、代理对象; 返回对象)
Object o = Proxy.newProxyInstance(IUserService.class.getClassLoader(),
new Class[]{IUserService.class},handler);
return (IUserService)o;
}
}
序列化问题
序列化问题在计算机里具体是什么?我们的方法调用,有方法名,方法参数,这些可能是字符串,可能是我们自己定义的java的类,但是在网络上传输或者保存在硬盘的时候,网络或者硬盘并不认得什么字符串或者javabean,它只认得二进制的01串,怎么办?要进行序列化,网络传输后要进行实际调用,就要把二进制的01串变回我们实际的java的类,这个叫反序列化。java里已经为我们提供了相关的机制Serializable。
登记的服务实例化
登记的服务有可能在我们的系统中就是一个名字,怎么变成实际执行的对象实例,当然是使用反射机制。
反射机制是什么?
反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性;这种动态获取的信息以及动态调用对象的方法的功能称为java语言的反射机制。
反射机制能做什么
反射机制主要提供了以下功能:
•在运行时判断任意一个对象所属的类;
•在运行时构造任意一个类的对象;
•在运行时判断任意一个类所具有的成员变量和方法;
•在运行时调用任意一个对象的方法;
•生成动态代理。
public class Client3 {
//远程调用类
public static Object getStub(final Class clazz) throws Exception{
InvocationHandler handler = new InvocationHandler() {
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
Socket socket = new Socket("127.0.0.1", 8888);
ObjectOutputStream oos = new ObjectOutputStream(socket.getOutputStream());
//TODO 送入的class 灵活了
String className = clazz.getName();
String methodName = method.getName();
Class[] parametersTypes = method.getParameterTypes();
//TODO 传递class到服务器
oos.writeUTF(className);
oos.writeUTF(methodName);
oos.writeObject(parametersTypes);
oos.writeObject(args);
oos.flush();
//TODO 返回对象
ObjectInputStream ois = new ObjectInputStream(socket.getInputStream());
Object o = ois.readObject();
oos.close();
socket.close();
return o ;
}
};
Object o = Proxy.newProxyInstance(clazz.getClassLoader(),
new Class[]{clazz},handler);
return o;
}
}
/**
* 服务端:服务更灵活-提供多个类、多个方法的远程接口调用
*/
public class Server3 {
private static boolean running = true;
public static void main(String[] args) throws Exception{
ServerSocket serverSocket = new ServerSocket(8888);
while (running){
Socket socket = serverSocket.accept();
process(socket);
socket.close();
}
serverSocket.close();
}
private static void process(Socket socket) throws Exception{
InputStream in = socket.getInputStream();
OutputStream out = socket.getOutputStream();
ObjectInputStream ois = new ObjectInputStream(in);
//TODO 拿到客户端传递过来的class
String clazzName =ois.readUTF();
String methodName =ois.readUTF();
Class[] parameterTypes = (Class[])ois.readObject();
Object[] args =(Object[])ois.readObject();
//反射拿到class
Class clazz =Class.forName(clazzName);
if(clazz.isInterface()){
if(clazzName.equals("com.msb.netty.pre.IUserService")){
clazz = UserServiceImpl.class;
}
//这里可以使用反射机制拿到所有接口对应的实现类
}
Method method = clazz.getMethod(methodName,parameterTypes);
Object object = method.invoke(clazz.newInstance(),args);
//TODO 返回值:使用对象进行返回
ObjectOutputStream oos = new ObjectOutputStream(out);
oos.writeObject(object);
oos.flush();
}
}
一些思考:
在Dubbo里:
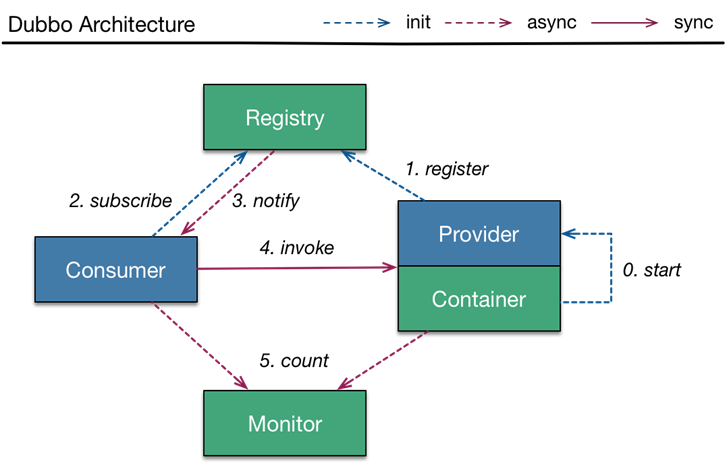
服务容器负责启动,加载,运行服务提供者。
服务提供者在启动时,向注册中心注册自己提供的服务。
服务消费者在启动时,向注册中心订阅自己所需的服务。
注册中心返回服务提供者地址列表给消费者,如果有变更,注册中心将基于长连接推送变更数据给消费者。
服务消费者,从提供者地址列表中,基于软负载均衡算法,选一台提供者进行调用,如果调用失败,再选另一台调用。
服务消费者和提供者,在内存中累计调用次数和调用时间,定时每分钟发送一次统计数据到监控中心。
和Dubbo的比较后,我们可以看到前面我们的一些系统实现:
1、性能欠缺,表现在网络通信机制,序列化机制等等
2、负载均衡、容灾和集群功能很弱
3、服务的注册和发现机制也很差劲
Dubbo和SpringCloud哪个更好
协议上比较:http相对更规范,更标准,更通用,无论哪种语言都支持http协议。如果你是对外开放API,例如开放平台,外部的编程语言多种多样,你无法拒绝对每种语言的支持,相应的,如果采用http,无疑在你实现SDK之前,支持了所有语言,所以,现在开源中间件,基本最先支持的几个协议都包含RESTful。
RPC协议性能要高的多,例如Protobuf、Thrift、Kyro等,(如果算上序列化)吞吐量大概能达到http的二倍。响应时间也更为出色。千万不要小看这点性能损耗,公认的,微服务做的比较好的,例如,netflix、阿里,曾经都传出过为了提升性能而合并服务。
服务全面上比较:当然是springloud更胜一筹,但也就意味着在使用springloud上其实更重量级一点,dubbo目前版本专注于服务治理,使用上更轻量一点。
就国内的热度来说,如果我们看百度指数的查询结果,springloud和dubbo几乎是半斤八两,dubbo相比起来还略胜一筹
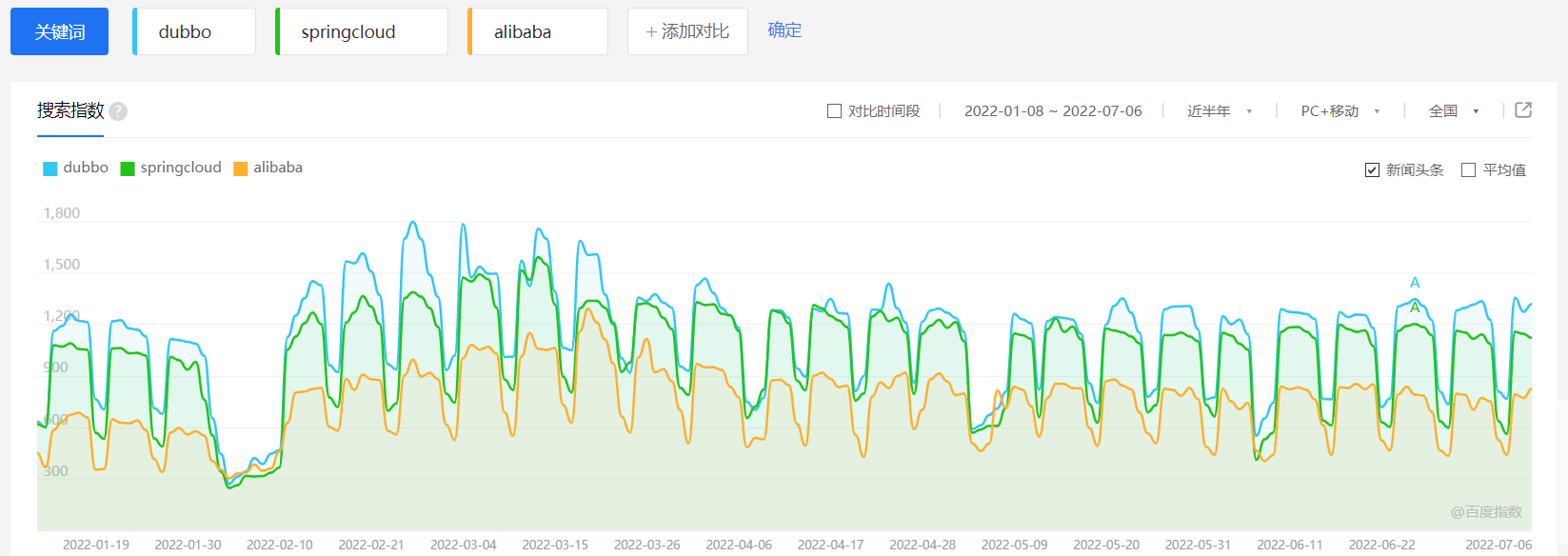
总的来说对外开放的服务推荐采用RESTful,内部调用推荐采用RPC方式。当然不能一概而论,还要看具体的业务场景。















 378
378











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









