









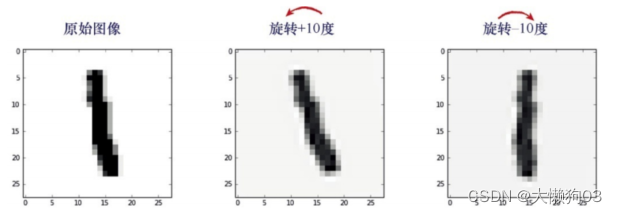
ndimage.interpolation.rotate()
可以将数组转过一个给定的角度
inputs_plus10_img =
scipy.ndimage.interpolation.rotate( scaled_input.reshape(28,28),
10,cval=0.01, reshape=False)
inputs_minus10_img =
scipy.ndimage.interpolation.rotate( scaled_input.reshape(28,28),
-10,cval=0.01, reshape=False)
原先的
scaled_input
数组被重新转变为
28
乘以
28
的数组,然 后进行了调整。
reshape=False
,这个参数防止程序库过分
“
热心
”
,将图像压扁,使得数组旋转后可以完全适合,而没有剪掉任何部分。
cval用来填充数组元素的值。避免0
作为神经网络的输入值,因此不使用0.0
作为默认值,而是使用
0.01
作为默认值。
过度旋转的图像添加到训练样本中,增加错误样本,会降低训练的质量。















 4102
4102











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









