








🎩 欢迎来到技术探索的奇幻世界👨💻
📜 个人主页:@一伦明悦-CSDN博客
✍🏻 作者简介: C++软件开发、Python机器学习爱好者
🗣️ 互动与支持:💬评论 👍🏻点赞 📂收藏 👀关注+
如果文章有所帮助,欢迎留下您宝贵的评论,
点赞加收藏支持我,点击关注,一起进步!
引言
主成分分析(Principal Component Analysis, PCA)是一种常用的机器学习和数据分析技术,用于降低数据维度、识别数据中的模式、发现变量之间的关系等。以下是PCA技术的详细介绍:
基本概念:
- PCA旨在通过线性变换将原始数据投影到一个新的坐标系中,新坐标系中的坐标轴称为主成分。这些主成分按照方差大小递减的顺序排列,第一主成分具有最大的方差,第二主成分具有第二大的方差,依此类推。
数学原理:
- PCA通过计算数据的协方差矩阵或相关矩阵,然后对其进行特征值分解(或奇异值分解),以获得主成分和对应的特征向量。这些特征向量定义了新的坐标系,而数据投影到这些特征向量上形成的新坐标即为主成分。
应用步骤:
- 数据标准化:对原始数据进行标准化处理,使得不同维度的数据具有相同的尺度。
- 计算协方差矩阵:计算标准化后的数据的协方差矩阵。
- 特征值分解:对协方差矩阵进行特征值分解或奇异值分解,得到特征值和特征向量。
- 选择主成分:按照特征值的大小选择前k个主成分,这些主成分对应的特征向量构成了新的特征空间。
降维和数据压缩:
- PCA通过保留最重要的主成分(即方差较大的主成分)来实现数据的降维,从而减少数据的复杂度和存储空间,同时保留数据中的关键信息。
PCA的应用领域:
- 数据可视化:通过降维将高维数据可视化到二维或三维空间,帮助分析人员理解数据的结构。
- 特征提取:在机器学习中,PCA可以用来提取数据中最重要的特征,以便于后续的分类、回归或聚类任务。
- 噪声过滤:PCA可以过滤掉数据中的噪声成分,提高数据的质量和后续分析的准确性。
正文
01-对数据集进行主成分分析并计算各主成分的方差贡献率
这段代码主要进行了以下操作:
导入所需的模块:
- 导入了numpy(np)、pandas(pd)和matplotlib.pyplot(plt)等常用的数据处理和可视化模块。
- 导入了Axes3D和cm模块用于创建3D图形和设置颜色映射。
- 使用warnings模块过滤警告信息,避免在程序运行过程中输出警告。
- 设置matplotlib绘图显示中文字符的字体和解决负号显示问题。
- 导入了make_regression、make_circles、make_s_curve等数据集生成函数,以及train_test_split等模型选择相关函数。
- 导入FactorAnalyzer用于因子分析。
创建子图及设置图形参数:
- 使用plt.subplots创建1行2列的子图,设置子图的大小为15x6。
生成数据并进行可视化:
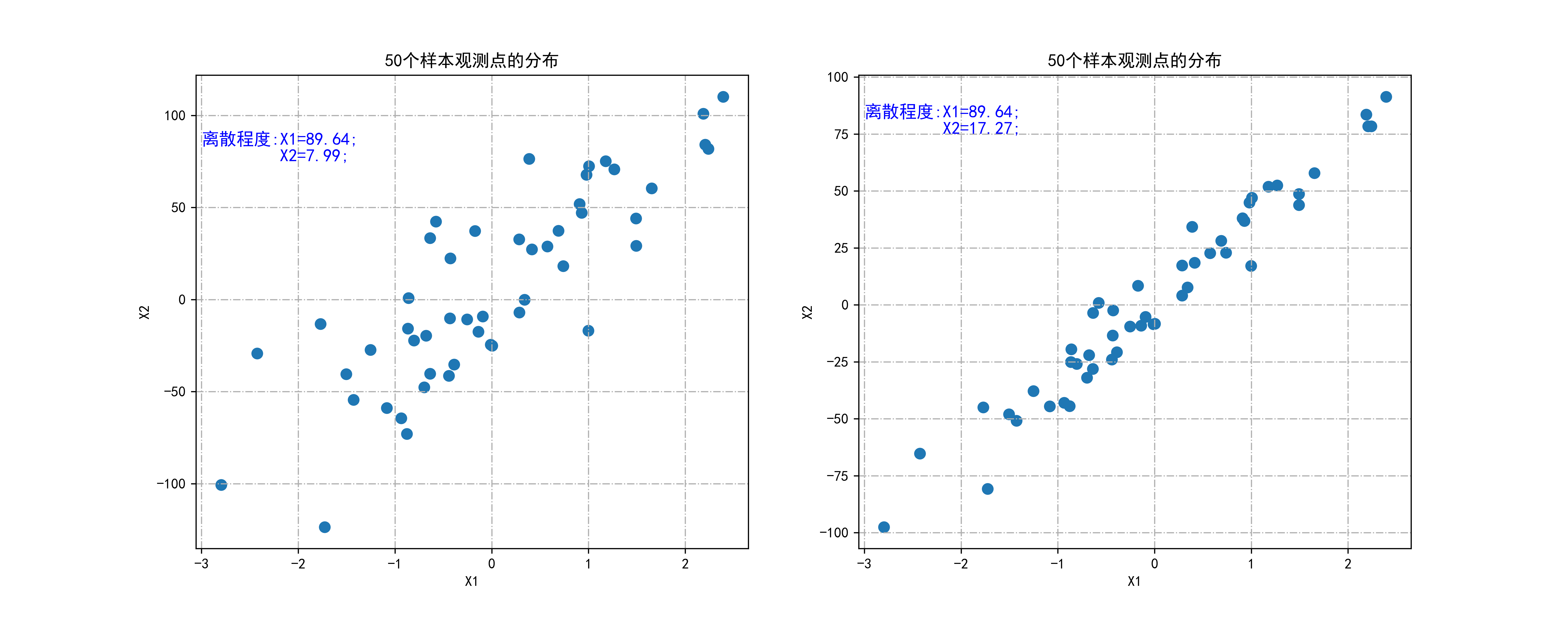
- 对于noise取30和10两种情况,分别生成包含50个样本观测点的数据集。
- 使用make_regression生成具有线性关系的数据集,其中包括一个特征和一个目标变量,同时受到指定程度的噪声干扰。
- 将生成的数据集绘制为散点图分布在两个子图中。
- 设置子图标题、横纵坐标标签、显示网格线,并在图中添加标注显示各特征的离散程度。
保存图形:
- 使用plt.savefig将绘制的图形保存为文件,文件名为"…/4.png",分辨率为500dpi。
总体来说,这段代码通过生成具有线性关系的带有噪声的数据集,并通过散点图可视化展示了各个特征的分布情况,同时对数据的离散程度进行了说明。并最终将绘制的图形保存为文件。
#本章需导入的模块
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from pylab import *
import matplotlib.cm as cm
import warnings
warnings.filterwarnings(action = 'ignore')
%matplotlib inline
plt.rcParams['font.sans-serif']=['SimHei'] #解决中文显示乱码问题
plt.rcParams['axes.unicode_minus']=False
from sklearn.datasets import make_regression,make_circles,make_s_curve
from sklearn.model_selection import train_test_split
from scipy.stats import multivariate_normal
from sklearn import decomposition
from factor_analyzer import FactorAnalyzer
fig,axes=plt.subplots(nrows=1,ncols=2,figsize=(15,6))
N=50
for i,noise in enumerate([30,10]):
X,Y=make_regression(n_samples=N,n_features=1,random_state=123,noise=noise,bias=0)
X=np.hstack((X,Y.reshape(len(X),1)))
axes[i].scatter(X[:,0],X[:,1],marker="o",s=50)
axes[i].set_title("%d个样本观测点的分布"%N)
axes[i].set_xlabel("X1")
axes[i].set_ylabel("X2")
axes[i].grid(True,linestyle='-.')
axes[i].text(-3,75,"离散程度:X1=%.2f;\n X2=%.2f;"
%(np.std(X[:,0])/np.mean(X[:,0]),np.std(X[:,1])/np.mean(X[:,1])),fontdict={'size':'12','color':'b'})
plt.savefig("../4.png", dpi=500) 运行结果如下图所示:
这段代码的作用是使用主成分分析(PCA)对生成的带有噪声的数据集进行降维,并可视化降维后的结果。
具体解释如下:
创建子图及设置图形参数:
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(15, 6)):创建包含1行2列的子图,每个子图的大小为15x6英寸。PCA模型的应用:
pca = decomposition.PCA(n_components=2, random_state=1):初始化PCA对象,指定降维后保留的主成分数量为2,并设置随机种子以确保结果的可重复性。生成数据并进行降维:
for i, noise in enumerate([30, 10])::循环两次,分别处理噪声为30和10的情况。X, Y = make_regression(n_samples=N, n_features=1, random_state=123, noise=noise, bias=0):生成包含50个样本观测点的数据集,其中特征数为1,同时受指定程度的噪声影响。X = np.hstack((X, Y.reshape(len(X), 1))):将生成的特征X和目标变量Y合并成一个数组。pca.fit(X):对数据集X进行PCA拟合,计算主成分和其它相关参数。获取PCA结果并绘图:
pca.singular_values_:获取PCA模型中的奇异值,即主成分的特征值。pca.components_:获取PCA模型的主成分(特征向量)。y = pca.transform(X):将原始数据集X转换到主成分空间,得到降维后的数据y。axes[i].scatter(y[:, 0], y[:, 1], marker="o", s=50):在第i个子图中绘制降维后的数据y的散点图,x轴为第一个主成分,y轴为第二个主成分。axes[i].set_title("%d个样本观测点的分布(方差贡献率:y1=%.3f,y2=%.3f)\n系数:%s"%(N, p1, p2, a)):设置子图标题,显示样本数量、每个主成分的方差贡献率、以及主成分系数。axes[i].set_xlabel("y1")和axes[i].set_ylabel("y2"):设置子图的x轴和y轴标签。axes[i].grid(True, linestyle='-.'):显示子图的网格线。保存图形:
plt.savefig("../4.png", dpi=500):将绘制的子图保存为
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











