







目录
一、概述
来自ECCV 2024的论文,提出一种从文本提示或单视图图像生成的高分辨率3D模型。
(1)使用非对称的U-Net作为高吞吐量的主干网络,可处理多视图图像输入。
(2)使用多视图图像信息来生成高分辨率三维高斯模型。
(3)提出两种数据增强方法,来克服多视图图像渲染和扩散模型生成之间的域差距。
二、相关工作
1、高分辨率三维生成
基于优化的方法(SDS):通过利用表达能力强的三维表示,如DMTet、Gaussian Splatting和高分辨率的监督信号,通过优化的方式将二维扩散模型提取到三维,但生成速度较慢,需要耗费大量计算资源。
Magic3D从NeRF辐射场转为DMTet,DMTet是一种新的渲染表示方法,结合了几何网格和哈希网格纹理,捕捉高质量3D信息,并且可以使用可微分光栅化的高效渲染。
Fantasia3D提到基于解纠缠几何形状和外观形状直接训练DMTet。
另外就是使用GS的方法但是需要再优化期间进行初始化和致密化,而该论文可以通过前馈方法来生成足够数量的三维高斯模型。
2、高效的三维生成
相较于SDS的方法,前馈方法可以从大规模3D数据集中更加有效的去生成三维资产,几秒内生成,但是分辨率较低(就是基于NeRF的前馈方法如三视角NeRF)。
另外使用点云和体素在大规模数据集中只能生成简单的三维资产。
相对于Instant3D从文本生成模型,LGM可以通过先从单视图生成多视图,再使用多视图生成三维资产。
而LGM通过3DGS+非对称的U-Net可以只需要5s中从单视图生成高分辨率三维资产,并且可以推广到网格。
3、基于3DGS的生成
一方面是3DGS+SDS的方法,比如GSGen和GaussianDreamer讨论了不同的密集化和初始化方法,虽然提高了计算速度,但仍然需要几分钟的时间。
三视角GS(TriplaneGaussian)生成的GS视觉效果较差,另外转换为网格时可能存在明显的缺陷。
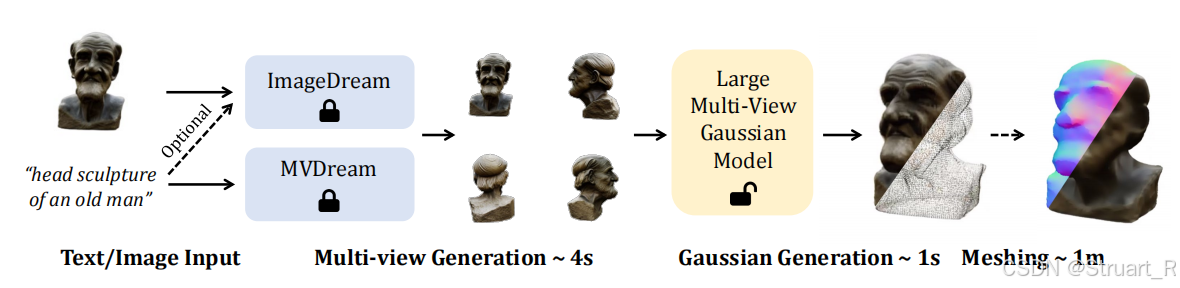
而对于该论文,首先童工MVDream和ImageDream利用单视图生成四视图视角,并通过四视图视角生成3DGS模型,并进一步生成网格模型。
三、前置知识
1、MVDream
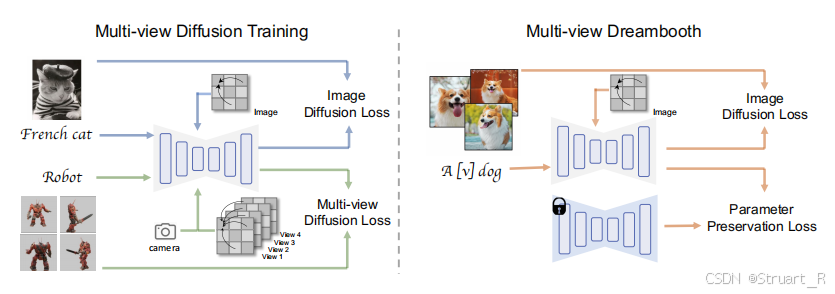
MVDream是一种从给定文本提示中生成一致的多视图图像的扩散模型。MVDream使用两个部分进行训练,左图上部分考虑文本到图片的扩散损失,左图下部分考虑基于已知相机位姿的四视角下(正交)的扩散损失。右图是另一种更加个性化的生成3D模型的方法,可以直接训练一个多视图的DreamBooth模型,然后进行NeRF优化。
2、ImageDream
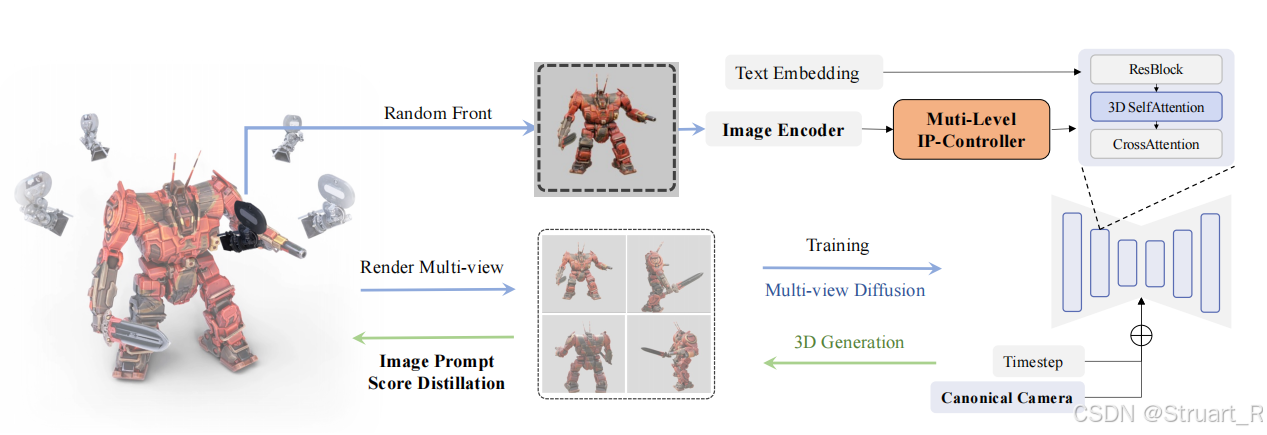
ImageDream提出一种从单个图像生成高质量3D模型的框架,另外也增强了图像-文本对齐作为Embedding引入多级控制器。
多级控制器由三部分组成:全局控制器,局部控制器,像素控制器。
全局控制器:将CLIP图像特征与文本特征对齐。
局部控制器:利用CLIP编码局部特征,更好地捕捉物体结构信息,也避免过度敏感,同时引入重采样模块来平衡特征。
像素控制器:通过在注意力层(3D自注意力机制)中融入输入的图像特征(经过VAE编码),来更好地集成物体的外观和纹理信息。
注意:ImageDream的基本框架来自于MVDream,所以生成的图像也是四视角图像。
四、LGM
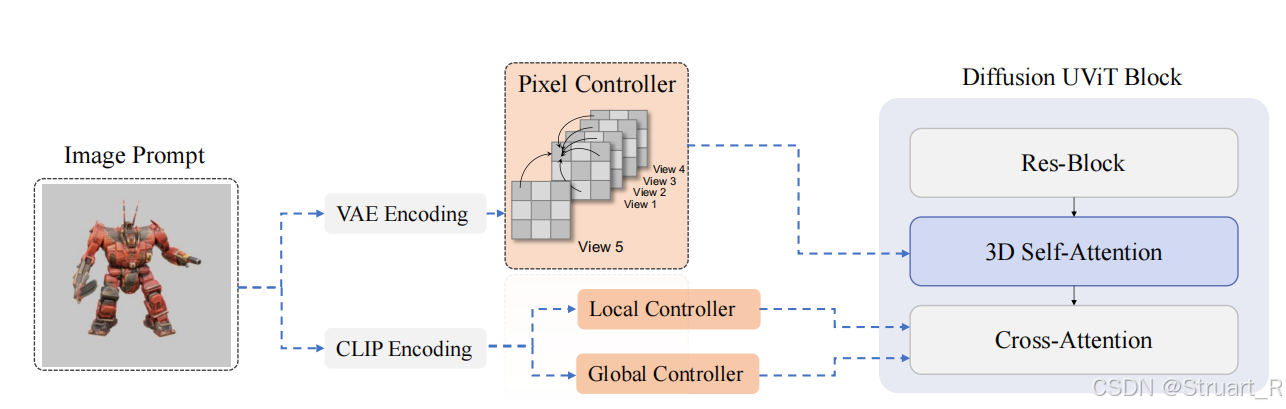
LGM框架可以通过输入文本或者单视角图片,经过预训练好的ImageDream和MVDream,生成四视角的图片,之后经过LGM模型进行3DGS渲染后,再进行进一步的网格化处理(Mesh),得到三维数字资产。从输入图像和文本到生成3DGS模型只需要5s中,这大大降低了渲染时间。
下图为LGM框架。
在LGM框架中最核心的就是LGM模型(Large-Multi-View Gaussian Model),将嵌入相机射线的四视角图片作为输入,经过非对称的U-Net(其中注意力机制使用了多视角自注意力机制),输出多视角GS特征,并通过可微分的渲染器将这些GS特征渲染到新的视角下,得到新视角图像。
另外作者也提出由于3DGS特征转换为Occupancy Field容易存在空洞,这其中的原因是GS特征相对稀疏,所以可以先训练一个NeRF模型(替代原来训练GS模型),之后利用Marching Cubes算法从NeRF中提取初步的网格,并进一步优化和纹理映射得到最终的Mesh网格模型,这样可以使得渲染的几何表面更加致密化。
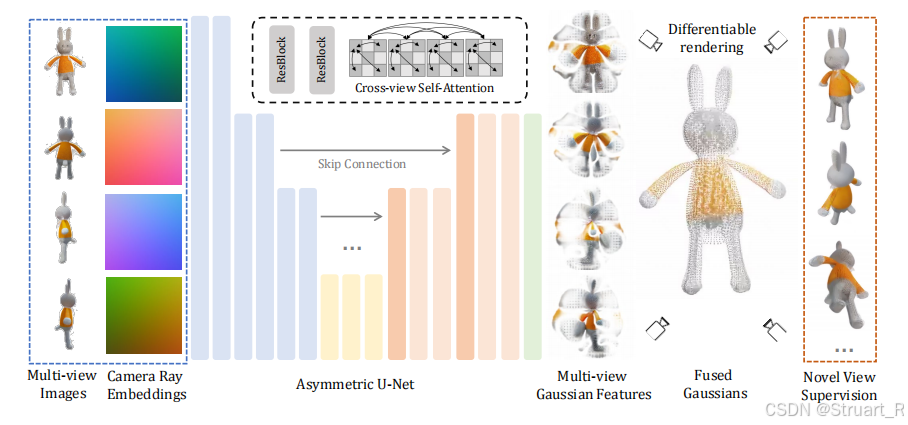
1、光线嵌入
Plücker光线:一种表示三维空间中直线的数学工具将一条直线用一个六维向量表示(三维方向向量,三维位置向量),一般由相机的姿态和内参计算图片中每个像素点对应的射线,用于光线追踪问题。
对于任何一个Plücker光线的计算,我们已知光线的起点(相机的世界坐标位置)和每个像素的视线方向。
计算流程:
(1)计算光线的起点:相机的世界坐标
(2)计算光线的方向:由相机的投影矩阵和每个像素的坐标,来计算每条光线的方向。
(3)计算位置向量:
(4)Plücker光线向量:输出6维向量
光线嵌入:将RGB的输入图像与Plücker光线向量组合成一个新的9维向量。
光线嵌入的意义:引入光线追踪,帮助网络更好理解多视角信息。
2、非对称U-Net
非对称U-Net的输入是经过光线嵌入后的多视角图像,输出多视角3DGS特征。
非对称U-Net由6层编码器,3层中间层和5层输出层构成,输出更小的分辨率,也就限制了输出的高斯特征数量,来提高效率。
另外在非对称U-Net中采用了残差层和自注意力层,更好地捕捉跨视角的特征关联。在上图中提出Cross-view自注意力机制,可以更好在自注意力层捕捉不同视角下的信息,但是在代码中优先没有使用Cross-view self attention,只是使用了普通的自注意力机制并且加了一些内存的优化。
3、数据增强
数据增强的目的是处理不一致的多视角输入,也是保证视角之间不重复,视角更加不一致,提高模型的鲁棒性。
(1)网格扭曲(Grid Distortion):相较于以往使用2D扩散模型合成多视角图像,但由于扩散模型生成不同视角会导致一定的随机性,无法保证3D模型的一致性。网格扭曲方法,除了第一视角(正面视角)不动,其他三个输入视角会随机应用网格扭曲,模拟不一致性。
(2)轨道相机抖动(Orbital Camera Jitter):模拟相机姿态的错误变动,提高泛化能力,保证第一视角不动,其他三个视角的相机位姿会随机转动,使得模型更加容忍不准确的相机姿态和光线嵌入。
4、损失函数
损失函数为两个部分:RGB损失函数,alpha损失函数。
对于损失函数,我们针对于输入的四视图RGB图片,alpha图片和渲染后的四视图图片,alpha图片之间建立损失。
RGB损失函数:MSE损失函数和基于VGG的LPIPS损失函数。(LPIPS损失函数见上一个博客)
alpha损失函数:针对于alpha图片计算MSE均方差。
总损失:
5、网格提取
利用3DGS的参数训练一个NeRF模型,并通过NeRF训练两个哈希网格,来重建集合和外观,并通过Marching Cubes算法精炼一次网格,之后使用这两个网格进行可微分渲染得到Mesh网格。
五、实验
生成效果。
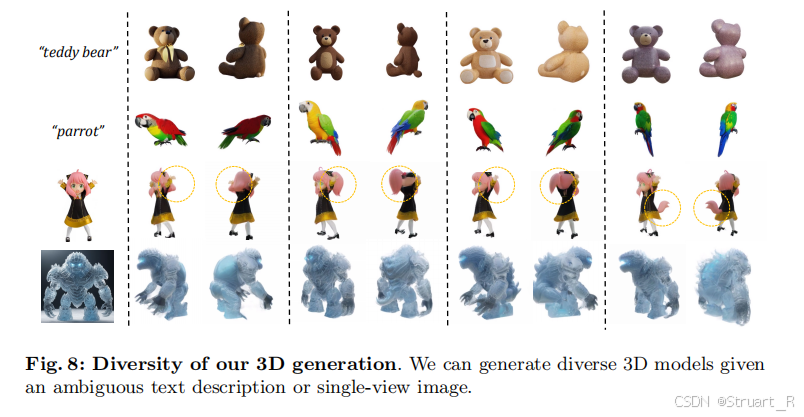
在Limitation里面提到说,一方面使用预训练ImageDreamer模型分辨率256*256较低,不能生成大视角下的3D模型,另外生成的多视角图片也存在不一致性,所以导致最后3DGS模型存在残影。

















 1053
1053

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









