






一、释义
首先对Iris数据集(鸢尾花数据集)进行简单介绍:
1.它分为三个类别,即Iris setosa(山鸢尾)、Iris versicolor(变色鸢尾)和Iris virginica(弗吉尼亚鸢尾),每个类别各有50个实例。
2.数据集定义了五个属性:sepal length(花萼长)、sepal width(花萼宽)、petal length(花瓣长)、petal width(花瓣宽)、class(类别)。
3.最后一个属性一般作为类别属性,其余属性为数值,单位为厘米。
注:鸢尾花数据集在sklearn中有保存,我们可以直接使用库中的数据集
二、k-means代码原理
K-means算法是典型的基于距离(欧式距离、曼哈顿距离)的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大。该算法认为簇是由距离靠近的对象组成的,因此把得到紧凑且独立的簇作为最终目标。
1.K-mean算法步骤如下:
1. 先定义总共有多少个簇类,随机选取K个样本为簇中⼼。
2.分别计算所有样本到随机选取的K个簇中⼼的距离。
3.样本离哪个中⼼近就被分到哪个簇中⼼。
4.计算各个中⼼样本的均值(最简单的⽅法就是求样本每个点的平均值)作为新的簇心。
5.重复2、3、4直到新的中⼼和原来的中⼼基本不变化的时候,算法结束。
算法结束条件:
1.当每个簇的质心,不再改变时就可以停止k-menas
2.当循环次数达到事先规定的次数时,停止k-means
三、解释代码
1.首先导入相应的库和数据
import matplotlib.pyplot as plt
import numpy as np
from sklearn.cluster import KMeans
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, precision_score, recall_score2. 取部分特征作散点图
取它的petal length(花瓣长)、petal width(花瓣宽)作为特征作图
plt.scatter(iris_X[:50,2],iris_X[:50,3],label='setosa',marker='o')
plt.scatter(iris_X[50:100,2],iris_X[50:100,3],label='versicolor',marker='x')
plt.scatter(iris_X[100:,2],iris_X[100:,3],label='virginica',marker='+')
plt.xlabel('petal length')
plt.ylabel('petal width')
plt.title("actual result")
plt.legend()
plt.show()
3.k均值聚类
1.jupyter notebook已经把k-means方法封装好了 只需要调用即可(这里我们选着k值为3)
estimator = KMeans(n_clusters=3) # 构造聚类器
estimator.fit(X) # 聚类2.k-means代码细节
class KMeans(object):
def __init__(self, input_data, k):
# data是一个包含所有样本的numpy数组
# data示例,每行是一个坐标
# [[1 2],
# [2 3],
# [3 4]]
self.data = input_data
self.k = k
# 保存聚类中心的索引和类样本的索引
self.centers = []
self.clusters = []
self.capacity = len(input_data)
self.__pick_start_point()
def __pick_start_point(self):
# 随机确定初始簇心
self.centers = []
if self.k < 1 or self.k > self.capacity:
raise Exception("K值错误")
indexes = random.sample(np.arange(0, self.capacity, step=1).tolist(), self.k)
for index in indexes:
self.centers.append(self.data[index])
def __distance(self, i, center):
diff = self.data[i] - center
return np.sum(np.power(diff, 2))**0.5
def __calCenter(self, cluster):
# 计算该簇的中心
cluster = np.array(cluster)
if cluster.shape[0] == 0:
return False
return (cluster.T @ np.ones(cluster.shape[0])) / cluster.shape[0]
def cluster(self):
changed = True
while changed:
self.clusters = []
for i in range(self.k):
self.clusters.append([])
for i in range(self.capacity):
min_distance = sys.maxsize
center = -1
# 寻找簇
for j in range(self.k):
distance = self.__distance(i, self.centers[j])
if min_distance > distance:
min_distance = distance
center = j
# 加入簇
self.clusters[center].append(self.data[i])
newCenters = []
for cluster in self.clusters:
newCenters.append(self.__calCenter(cluster).tolist())
if (np.array(newCenters) == self.centers).all():
changed = False
else:
self.centers = np.array(newCenters)4.绘制k-means结果
# 绘制k-means结果
x0 = X[label_pred == 0]
x1 = X[label_pred == 1]
x2 = X[label_pred == 2]
plt.scatter(x0[:, 0], x0[:, 1], c="red", marker='o', label='label0')
plt.scatter(x1[:, 0], x1[:, 1], c="green", marker='*', label='label1')
plt.scatter(x2[:, 0], x2[:, 1], c="blue", marker='+', label='label2')
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.legend(loc=2)
plt.show()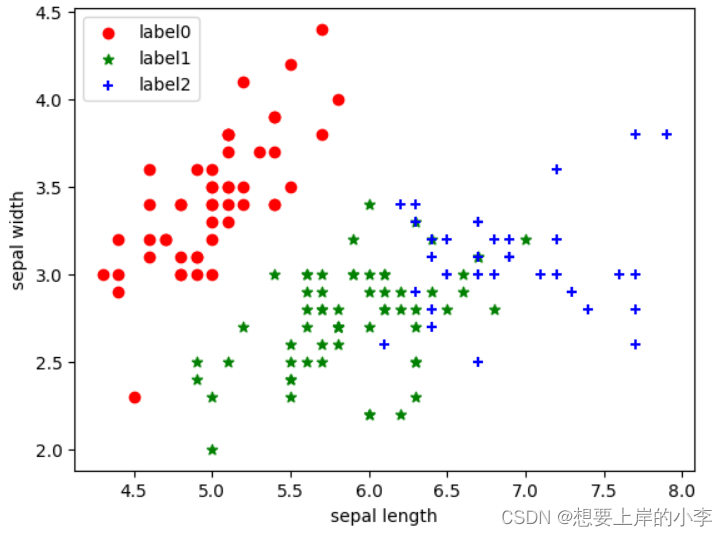
5.看学习效果
print('准确率:', accuracy_score(y_test, y_pred))
print('精确率:', precision_score(y_test, y_pred, average='weighted'))
print('召回率:', recall_score(y_test, y_pred, average='weighted')) 
四、完整代码
import matplotlib.pyplot as plt
import numpy as np
from sklearn.cluster import KMeans
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, precision_score, recall_score
iris = datasets.load_iris()
X = iris.data
Y = iris.target
x_train, x_test, y_train, y_test = train_test_split(X, Y, test_size=0.3, random_state=100)
X = iris.data[:, :4] # #表示我们取特征空间中的4个维度
print(X.shape)
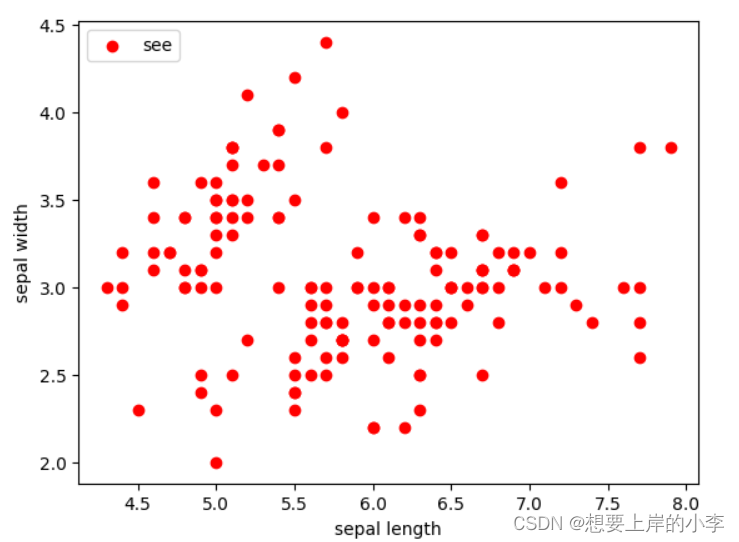
# 绘制数据分布图
plt.scatter(X[:, 0], X[:, 1], c="red", marker='o', label='see')
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.legend(loc=2)
plt.show()
estimator = KMeans(n_clusters=3) # 构造聚类器
estimator.fit(X) # 聚类
y_pred = estimator.predict(x_test)
label_pred = estimator.labels_ # 获取聚类标签
# 绘制k-means结果
x0 = X[label_pred == 0]
x1 = X[label_pred == 1]
x2 = X[label_pred == 2]
plt.scatter(x0[:, 0], x0[:, 1], c="red", marker='o', label='label0')
plt.scatter(x1[:, 0], x1[:, 1], c="green", marker='*', label='label1')
plt.scatter(x2[:, 0], x2[:, 1], c="blue", marker='+', label='label2')
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.legend(loc=2)
plt.show()
print('准确率:', accuracy_score(y_test, y_pred))
print('精确率:', precision_score(y_test, y_pred, average='weighted'))
print('召回率:', recall_score(y_test, y_pred, average='weighted'))

















 5032
5032

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











