







单独运行此模块文件,可以看到如下运行结果:
测试数据:0 摄氏度 = 32.00 华氏度
测试数据:0 华氏度 = -17.78 摄氏度
在 candf.py 模块文件的基础上,在同目录下再创建一个 demo.py 文件,并编写如下代码:
import candf
print(“32 摄氏度 = %.2f 华氏度” % candf.c2f(32))
print(“99 华氏度 = %.2f 摄氏度” % candf.f2c(99))
运行 demo.py 文件,其运行结果如下所示:
测试数据:0 摄氏度 = 32.00 华氏度
测试数据:0 华氏度 = -17.78 摄氏度
32 摄氏度 = 89.60 华氏度
99 华氏度 = 37.22 摄氏度
可以看到,Python解释器将模块(candf.py)中的测试代码也一块儿运行了,这并不是我们想要的结果。想要避免这种情况的关键在于,要让 Python 解释器知道,当前要运行的程度代码,是模块文件本身,还是导入模块的其它程序。
为了实现这一点,就需要使用 Python 内置的系统变量 **name**,它用于标识所在模块的模块名。例如,在 demo.py 程序文件中,添加如下代码:
print(name)
print(candf.name)
其运行结果为:
main
candf
可以看到,当前运行的程序,其 **name** 的值为 **main**,而导入到当前程序中的模块,其 **name** 值为自己的模块名。
因此,`if __name__ == '__main__':` 的作用是确保只有单独运行该模块时,此表达式才成立,才可以进入此判断语法,执行其中的测试代码;反之,如果只是作为模块导入到其他程序文件中,则此表达式将不成立,运行其它程序时,也就不会执行该判断语句中的测试代码。
## Python导入模块的3种方式(超级详细)
很多初学者经常遇到这样的问题,即自定义 [Python]( ) 模板后,在其它文件中用 import(或 from…import) 语句引入该文件时,Python 解释器同时如下错误:
ModuleNotFoundError: No module named ‘模块名’
意思是 Python 找不到这个模块名,这是什么原因导致的呢?要想解决这个问题,读者要先搞清楚 Python 解释器查找模块文件的过程。
通常情况下,当使用 import 语句导入模块后,Python 会按照以下顺序查找指定的模块文件:
* 在当前目录,即当前执行的程序文件所在目录下查找;
* 到 PYTHONPATH(环境变量)下的每个目录中查找;
* 到 Python 默认的安装目录下查找。
以上所有涉及到的目录,都保存在标准模块 sys 的 sys.path 变量中,通过此变量我们可以看到指定程序文件支持查找的所有目录。换句话说,如果要导入的模块没有存储在 sys.path 显示的目录中,那么导入该模块并运行程序时,Python 解释器就会抛出 ModuleNotFoundError(未找到模块)异常。
解决“Python找不到指定模块”的方法有 3 种,分别是:
1. 向 sys.path 中临时添加模块文件存储位置的完整路径;
2. 将模块放在 sys.path 变量中已包含的模块加载路径中;
3. 设置 path 系统环境变量。
不过,在详细介绍这 3 种方式之前,为了能更方便地讲解,本节使用前面章节已建立好的 hello.py 自定义模块文件(D:\python\_module\hello.py)和 say.py 程序文件(C:\Users\mengma\Desktop\say.py,位于桌面上),它们各自包含的代码如下:
#hello.pydef say (): print(“Hello,World!”)#say.pyimport hellohello.say()
显然,hello.py 文件和 say.py 文件并不在同一目录,此时运行 say.py 文件,其运行结果为:
Traceback (most recent call last):
File “C:\Users\mengma\Desktop\say.py”, line 1, in
import hello
ModuleNotFoundError: No module named ‘hello’
可以看到,Python 解释器抛出了 ModuleNotFoundError 异常。接下来,分别用以上 3 种方法解决这个问题。
### 导入模块方式一:临时添加模块完整路径
模块文件的存储位置,可以临时添加到 sys.path 变量中,即向 sys.path 中添加 D:\python\_module(hello.py 所在目录),在 say.py 中的开头位置添加如下代码:
import syssys.path.append(‘D:\python_module’)
注意:在添加完整路径中,路径中的 ‘’ 需要使用 \ 进行转义,否则会导致语法错误。再次运行 say.py 文件,运行结果如下:
Hello,World!
可以看到,程序成功运行。在此基础上,我们在 say.py 文件中输出 sys.path 变量的值,会得到以下结果:
[‘C:\Users\mengma\Desktop’, ‘D:\python3.6\Lib\idlelib’, ‘D:\python3.6\python36.zip’, ‘D:\python3.6\DLLs’, ‘D:\python3.6\lib’, ‘D:\python3.6’, ‘C:\Users\mengma\AppData\Roaming\Python\Python36\site-packages’, ‘D:\python3.6\lib\site-packages’, ‘D:\python3.6\lib\site-packages\win32’, ‘D:\python3.6\lib\site-packages\win32\lib’, ‘D:\python3.6\lib\site-packages\Pythonwin’, ‘D:\python\_module’]
该输出信息中,红色部分就是临时添加进去的存储路径。需要注意的是,通过该方法添加的目录,只能在执行当前文件的窗口中有效,窗口关闭后即失效。
### 导入模块方式二:将模块保存到指定位置
如果要安装某些通用性模块,比如复数功能支持的模块、矩阵计算支持的模块、图形界面支持的模块等,这些都属于对 Python 本身进行扩展的模块,这种模块应该直接安装在 Python 内部,以便被所有程序共享,此时就可借助于 Python 默认的模块加载路径。
Python 程序默认的模块加载路径保存在 sys.path 变量中,因此,我们可以在 say.py 程序文件中先看看 sys.path 中保存的默认加载路径,向 say.py 文件中输出 sys.path 的值,如下所示:
[‘C:\Users\mengma\Desktop’, ‘D:\python3.6\Lib\idlelib’, ‘D:\python3.6\python36.zip’, ‘D:\python3.6\DLLs’, ‘D:\python3.6\lib’, ‘D:\python3.6’, ‘C:\Users\mengma\AppData\Roaming\Python\Python36\site-packages’, ‘D:\python3.6\lib\site-packages’, ‘D:\python3.6\lib\site-packages\win32’, ‘D:\python3.6\lib\site-packages\win32\lib’, ‘D:\python3.6\lib\site-packages\Pythonwin’]
上面的运行结果中,列出的所有路径都是 Python 默认的模块加载路径,但通常来说,我们默认将 Python 的扩展模块添加在 `lib\site-packages` 路径下,它专门用于存放 Python 的扩展模块和包。
所以,我们可以直接将我们已编写好的 hello.py 文件添加到 `lib\site-packages` 路径下,就相当于为 Python 扩展了一个 hello 模块,这样任何 Python 程序都可使用该模块。
移动工作完成之后,再次运行 say.py 文件,可以看到成功运行的结果:
Hello,World!
### 导入模块方式三:设置环境变量
PYTHONPATH 环境变量(简称 path 变量)的值是很多路径组成的集合,Python 解释器会按照 path 包含的路径进行一次搜索,直到找到指定要加载的模块。当然,如果最终依旧没有找到,则 Python 就报 ModuleNotFoundError 异常。
由于不同平台,设置 path 环境变量的设置流程不尽相同,因此接下来就使用最多的 Windows、Linux、Mac OS X 这 3 个平台,给读者介绍如何设置 path 环境变量。
##### 在 Windows 平台上设置环境变量
首先,找到桌面上的“计算机”(或者我的电脑),并点击鼠标右键,单击“属性”。此时会显示“控制面板\所有控制面板项\系统”窗口,单击该窗口左边栏中的“高级系统设置”菜单,出现“系统属性”对话框,如图 1 所示。
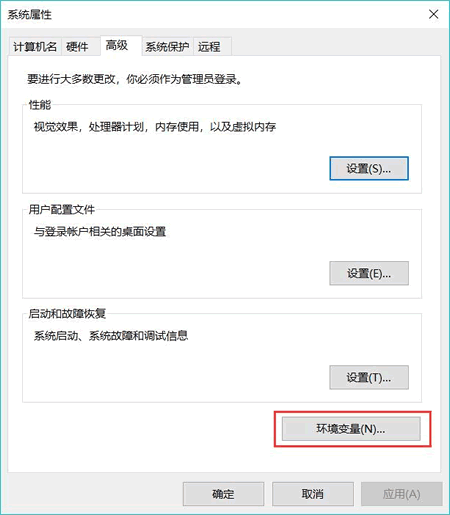
图 1 系统属性对话框
如图 1 所示,点击“环境变量”按钮,此时将弹出图 2 所示的对话框:
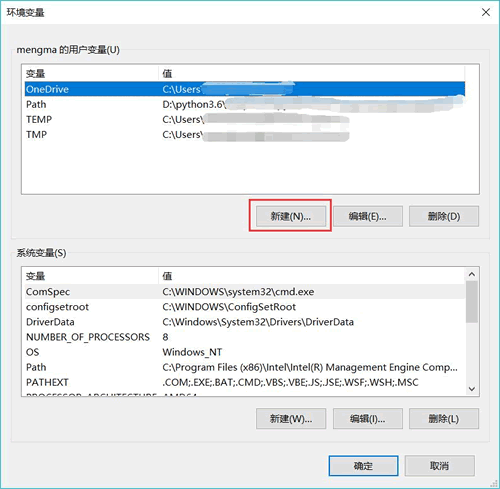
图 2 环境变量对话框
如图 2 所示,通过该对话框,就可以完成 path 环境变量的设置。需要注意的是,该对话框分为上下 2 部分,其中上面的“用户变量”部分用于设置当前用户的环境变量,下面的“系统变量”部分用于设置整个系统的环境变量。
通常情况下,建议大家设置设置用户的 path 变量即可,因为此设置仅对当前登陆系统的用户有效,而如果修改系统的 path 变量,则对所有用户有效。
>
> 对于普通用户来说,设置用户 path 变量和系统 path 变量的效果是相同的,但 Python 在使用 path 变量时,会先按照系统 path 变量的路径去查找,然后再按照用户 path 变量的路径去查找。
>
>
>
这里我们选择设置当前用户的 path 变量。单击用户变量中的“新建”按钮, 系统会弹出如图 3 所示的对话框。
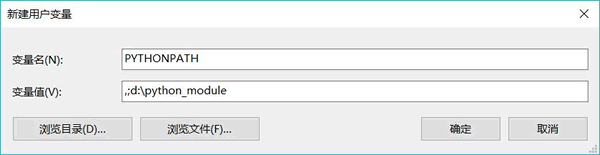
图 3 新建PYTHONPATH环境变量
其中,在“变量名”文本框内输入 PYTHONPATH,表明将要建立名为 PYTHONPATH 的环境变量;在“变量值”文本框内输入 `.;d:\python_ module`。注意,这里其实包含了两条路径(以分号 ;作为分隔符):
* 第一条路径为一个点(.),表示当前路径,当运行 Python 程序时,Python 将可以从当前路径加载模块;
* 第二条路径为 `d:\python_ module`,当运行 Python 程序时,Python 将可以从 `d:\python_ module` 中加载模块。
然后点击“确定”,即成功设置 path 环境变量。此时,我们只需要将模块文件移动到和引入该模块的文件相同的目录,或者移动到 `d:\python_ module` 路径下,该模块就能被成功加载。
##### 在 Linux 上设置环境变量
启动 Linux 的终端窗口,进入当前用户的 home 路径下,然后在 home 路径下输入如下命令:
ls - a
该命令将列出当前路径下所有的文件,包括隐藏文件。Linux 平台的环境变量是通过 .bash\_profile 文件来设置的,使用无格式编辑器打开该文件,在该文件中添加 PYTHONPATH 环境变量。也就是为该文件增加如下一行:
#设置PYTHON PATH 环境变量
PYTHONPATH=.:/home/mengma/python\_module
Linux 与 Windows 平台不一样,多个路径之间以冒号(:)作为分隔符,因此上面一行同样设置了两条路径,点(.)代表当前路径,还有一条路径是 `/home/mengma/python_module`(mengma 是在 Linux 系统的登录名)。
在完成了 PYTHONPATH 变量值的设置后,在 .bash\_profile 文件的最后添加导出 PYTHONPATH 变量的语句。
#导出PYTHONPATH 环境变量
export PYTHONPATH
重新登录 Linux 平台,或者执行如下命令:
source.bash\_profile
这两种方式都是为了运行该文件,使在文件中设置的 PYTHONPATH 变量值生效。
在成功设置了上面的环境变量之后,接下来只要把前面定义的模块(Python 程序)放在与当前所运行 Python 程序相同的路径中(或放在 `/home/mengma/python_module` 路径下),该模块就能被成功加载了。
##### 在Mac OS X 上设置环境变量
在 Mac OS X 上设置环境变量与 Linux 大致相同(因为 Mac OS X 本身也是类 UNIX 系统)。启动 Mac OS X 的终端窗口(命令行界面),进入当前用户的 home 路径下,然后在 home 路径下输入如下命令:
ls -a
该命令将列出当前路径下所有的文件,包括隐藏文件。Mac OS X 平台的环境变量也可通过,bash\_profile 文件来设置,使用无格式编辑器打开该文件,在该文件中添加 PYTHONPATH 环境变量。也就是为该文件增加如下一行:
#设置PYTHON PATH 环境变盘
PYTHONPATH=.:/Users/mengma/python\_module
Mac OS X 的多个路径之间同样以冒号(:)作为分隔符,因此上面一行同样设置了两条路径:点(.)代表当前路径,还有一条路径是 `/Users/mengma/python_module`(memgma 是作者在 Mac OS X 系统的登录名)。
在完成了 PYTHONPATH 变量值的设置后,在 .bash\_profile 文件的最后添加导出 PYTHONPATH 变量的语句。
#导出PYTHON PATH 环境变量
export PYTHONPATH
重新登录 Mac OS X 系统,或者执行如下命令:
source.bash\_profile
这两种方式都是为了运行该文件,使在文件中设置的 PYTHONPATH 变量值生效。
在成功设置了上面的环境变量之后,接下来只要把前面定义的模块(Python 程序)放在与当前所运行 Python 程序相同的路径中(或放在 `Users/mengma/python_module` 路径下),该模块就能被成功加载了。
## Python导入模块的本质
为了帮助大家更好地理解导入模块,下面定义一个新的模块,该模块比较简单,所以不再为之编写测试代码。该模块代码如下(编写在 fk\_module.py 文件中):
‘一个简单的测试模块: fk_module’
print(“this is fk_module”)
name = ‘fkit’
def hello():
print(“Hello, Python”)
接下来,在相同的路径下定义如下程序来使用该模块:
import fk_module
print(“================”)
打印fk_module的类型
print(type(fk_module))
print(fk_module)
由于前面在 PYTHONPATH 环境变量中已经添加了点(.),因此 Python 程序总可以加载相同路径下的模块。所以,上面程序可以成功导入 fk\_module 模块。
运行上面程序,可以看到如下输出结果:
## this is fk\_module
<class ‘module’>
<module ‘fk\_module’ from ‘C:\Users\mengma\Desktop\fk\_module.py’>
从输出结果来看,当程序导入 fk\_module 时,该模块中的输出语句会在 import 时自动执行。该程序中还包含一个与模块同名的变量,该变量的类型是 module。
使用“import fk\_module”导入模块的本质就是,将 fk\_module.py 中的全部代码加载到内存并执行,然后将整个模块内容赋值给与模块同名的变量,该变量的类型是 module,而在该模块中定义的所有程序单元都相当于该 module 对象的成员。
下面再试试使用 `from...import` 语句来执行导入,例如使用如下程序来测试该模块:
from fk_module import name, hello
print(“================”)
print(name)
print(hello)
打印fk_module
print(fk_module)
运行上面程序,可以看到如下输出结果:
## this is fk\_module
fkit
<function hello at 0x0000000001E7BAE8>
Traceback (most recent call last):
File “fk\_module\_test2.py”, line 22, in
print(fk\_module)
NameError: name ‘fk\_module’ is not defined
从上面的输出结果可以看出,即便使用 `from...import` 只导入模块中部分成员,该模块中的输出语句也会在 import 时自动执行,这说明 Python 依然会加载并执行模块中的代码。
使用“from fk\_module import name, hello”导入模块中成员的本质就是将 fk\_module.py 中的全部代码加载到内存并执行,然后只导入指定变量、函数等成员单元,并不会将整个模块导入,因此上面程序在输出 fk\_module 时将看到错误提示:`name 'fk module' is not defined`。
在导入模块后,可以在模块文件所在目录下看到一个名为“**pycache**”的文件夹,打开该文件夹,可以看到 Python 为每个模块都生成一个 \*.cpython-36.pyc 文件,比如 Python 为 fk\_module 模块生成一个 fk\_ module.cpython-36.pyc 文件,该文件其实是 Python 为模块编译生成的字节码,用于提升该模块的运行效率。
### 导入同一个模块多次,Python只执行一次
先看一个例子,将本节开头处的程序文件修改成如下内容:
import fk_module
import fk_module
print(“================”)
打印fk_module的类型
print(type(fk_module))
print(fk_module)
运行结果为:
## this is fk\_module
<class ‘module’>
<module ‘fk\_module’ from ‘C:\Users\mengma\Desktop\fk\_module.py’>
可以看到,修改后的程序中导入了 2 次 fk\_module 模块,其实完全没必要,此处导入两次只是为了说明一点:Python 很智能。虽然上面程序两次导入了 fk\_module 模块,但最后运行程序,我们看到输出语句只输出一条“this is fk\_module”,这说明第二次导入的 fk\_module 模块并没有起作用,这就是 Python 的“智能”之处。
当程序重复导入同一个模块时,Python 只会导入一次。道理很简单,因为这些变量、函数、类等程序单元都只需要定义一次即可,何必导入多次呢?相反,如果 Python 允许导入多次,反而可能会导致严重的后果。比如程序定义了 foo 和 bar 两个模块,假如 foo 模块导入了 bar 模块,而 bar 模块又导入了 foo 模块,这似乎形成了无限循环导入,但由于 Python 只会导入一次,所以这个无限循环导入的问题完全可以避免。
## Python \_\_all\_\_变量用法
事实上,当我们向文件导入某个模块时,导入的是该模块中那些名称不以下划线(单下划线“\_”或者双下划线“\_\_”)开头的变量、函数和类。因此,如果我们不想模块文件中的某个成员被引入到其它文件中使用,可以在其名称前添加下划线。
以前面章节中创建的 demo.py 模块文件和 test.py 文件为例(它们位于同一目录),各自包含的内容如下所示:
#demo.py
def say():
print(“人生苦短,我学Python!”)
def CLanguage():
print(“C语言中文网:http://c.biancheng.net”)
def disPython():
print(“Python教程:http://c.biancheng.net/python”)
#test.py
from demo import *
say()
CLanguage()
disPython()
执行 test.py 文件,输出结果为:
人生苦短,我学Python!
C语言中文网:http://c.biancheng.net
Python教程:http://c.biancheng.net/python
在此基础上,如果 demo.py 模块中的 disPython() 函数不想让其它文件引入,则只需将其名称改为 \_disPython() 或者 \_\_disPython()。修改之后,再次执行 test.py,其输出结果为:
人生苦短,我学Python!
C语言中文网:http://c.biancheng.net
Traceback (most recent call last):
File “C:/Users/mengma/Desktop/2.py”, line 4, in
disPython()
NameError: name ‘disPython’ is not defined
显然,test.py 文件中无法使用未引入的 disPython() 函数。
### Python模块\_\_all\_\_变量
除此之外,还可以借助模块提供的 **all** 变量,该变量的值是一个列表,存储的是当前模块中一些成员(变量、函数或者类)的名称。通过在模块文件中设置 **all** 变量,当其它文件以“from 模块名 import \*”的形式导入该模块时,该文件中只能使用 **all** 列表中指定的成员。
>
> 也就是说,只有以“from 模块名 import \*”形式导入的模块,当该模块设有 **all** 变量时,只能导入该变量指定的成员,未指定的成员是无法导入的。
>
>
>
举个例子,修改 demo.py 模块文件中的代码:
def say():
print(“人生苦短,我学Python!”)
def CLanguage():
print(“C语言中文网:http://c.biancheng.net”)
def disPython():
print(“Python教程:http://c.biancheng.net/python”)
all = [“say”,“CLanguage”]
可见,**all** 变量只包含 say() 和 CLanguage() 的函数名,不包含 disPython() 函数的名称。此时直接执行 test.py 文件,其执行结果为:
人生苦短,我学Python!
C语言中文网:http://c.biancheng.net
Traceback (most recent call last):
File “C:/Users/mengma/Desktop/2.py”, line 4, in
disPython()
NameError: name ‘disPython’ is not defined
显然,对于 test.py 文件来说,demo.py 模块中的 disPython() 函数是未引入,这样调用是非法的。
再次声明,**all** 变量仅限于在其它文件中以“from 模块名 import \*”的方式引入。也就是说,如果使用以下 2 种方式引入模块,则 **all** 变量的设置是无效的。
1. 以“import 模块名”的形式导入模块。通过该方式导入模块后,总可以通过模块名前缀(如果为模块指定了别名,则可以使用模快的别名作为前缀)来调用模块内的所有成员(除了以下划线开头命名的成员)。
仍以 demo.py 模块文件和 test.py 文件为例,修改它们的代码如下所示:
#demo.py
def say():
print(“人生苦短,我学Python!”)
def CLanguage():
print(“C语言中文网:http://c.biancheng.net”)
def disPython():
print(“Python教程:http://c.biancheng.net/python”)
all = [“say”]
#test.py
import demo
demo.say()
demo.CLanguage()
demo.disPython()
运行 test.py 文件,其输出结果为:
人生苦短,我学Python!
C语言中文网:http://c.biancheng.net
Python教程:http://c.biancheng.net/python
可以看到,虽然 demo.py 模块文件中设置有 **all** 变量,但是当以“import demo”的方式引入后,**all** 变量将不起作用。
2. 以“from 模块名 import 成员”的形式直接导入指定成员。使用此方式导入的模块,**all** 变量即便设置,也形同虚设。
仍以 demo.py 和 test.py 为例,修改 test.py 文件中的代码,如下所示:
from demo import say
from demo import CLanguage
from demo import disPython
say()
CLanguage()
disPython()
运行 test.py,输出结果为:
人生苦短,我学Python!
C语言中文网:http://c.biancheng.net
Python教程:http://c.biancheng.net/python
## Python包(存放多个模块的文件夹)
实际开发中,一个大型的项目往往需要使用成百上千的 [Python]( ) 模块,如果将这些模块都堆放在一起,势必不好管理。而且,使用模块可以有效避免变量名或函数名重名引发的冲突,但是如果模块名重复怎么办呢?因此,Python提出了包(Package)的概念。
什么是包呢?简单理解,包就是文件夹,只不过在该文件夹下必须存在一个名为“**init**.py” 的文件。
>
> 注意,这是 Python 2.x 的规定,而在 Python 3.x 中,**init**.py 对包来说,并不是必须的。
>
>
>
每个包的目录下都必须建立一个 **init**.py 的模块,可以是一个空模块,可以写一些初始化代码,其作用就是告诉 Python 要将该目录当成包来处理。
注意,**init**.py 不同于其他模块文件,此模块的模块名不是 **init**,而是它所在的包名。例如,在 settings 包中的 **init**.py 文件,其模块名就是 settings。
包是一个包含多个模块的文件夹,它的本质依然是模块,因此包中也可以包含包。例如,在前面章节中,我们安装了 numpy 模块之后可以在 Lib\site-packages 安装目录下找到名为 numpy 的文件夹,它就是安装的 numpy 模块(其实就是一个包),它所包含的内容如图 1 所示。
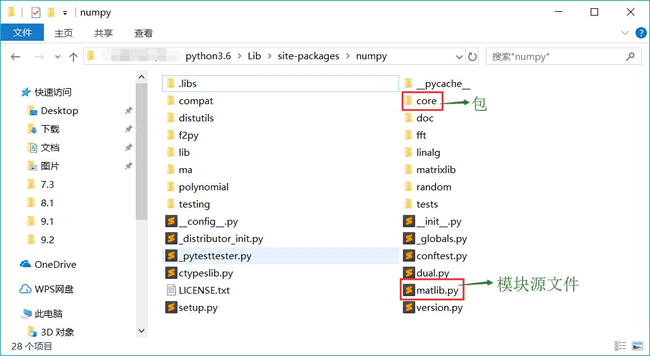
图 1 numpy包(模块)
从图 1 可以看出,在 numpy 包(模块)中,有必须包含的 **init**.py 文件,还有 matlib.py 等模块源文件以及 core 等子包(也是模块)。这正印证了我们刚刚讲过的,包的本质依然是模块,包可以包含包。
>
> Python 库:相比模块和包,库是一个更大的概念,例如在 Python 标准库中的每个库都有好多个包,而每个包中都有若干个模块。
>
>
>
## Python创建包,导入包(入门必读)
《[Python包]( )》一节中已经提到,包其实就是文件夹,更确切的说,是一个包含“**init**.py”文件的文件夹。因此,如果我们想手动创建一个包,只需进行以下 2 步操作:
1. 新建一个文件夹,文件夹的名称就是新建包的包名;
2. 在该文件夹中,创建一个 **init**.py 文件(前后各有 2 个下划线‘\_’),该文件中可以不编写任何代码。当然,也可以编写一些 [Python]( ) 初始化代码,则当有其它程序文件导入包时,会自动执行该文件中的代码(本节后续会有实例)。
例如,现在我们创建一个非常简单的包,该包的名称为 my\_package,可以仿照以上 2 步进行:
1. 创建一个文件夹,其名称设置为 my\_package;
2. 在该文件夹中添加一个 **init**.py 文件,此文件中可以不编写任何代码。不过,这里向该文件编写如下代码:
‘’’
http://c.biancheng.net/
创建第一个 Python 包
‘’’
print(‘http://c.biancheng.net/python/’)
可以看到,**init**.py 文件中,包含了 2 部分信息,分别是此包的说明信息和一条 print 输出语句。
由此,我们就成功创建好了一个 Python 包。
创建好包之后,我们就可以向包中添加模块(也可以添加包)。这里给 my\_package 包添加 2 个模块,分别是 module1.py、module2.py,各自包含的代码分别如下所示(读者可直接复制下来):
#module1.py模块文件
def display(arc):
print(arc)
#module2.py 模块文件
class CLanguage:
def display(self):
print(“http://c.biancheng.net/python/”)
现在,我们就创建好了一个具有如下文件结构的包:
my\_package
┠── **init**.py
┠── module1.py
┗━━ module2.py
当然,包中还有容纳其它的包,不过这里不再演示,有兴趣的读者可以自行调整包的结构。
### Python包的导入
通过前面的学习我们知道,包其实本质上还是模块,因此导入模块的语法同样也适用于导入包。无论导入我们自定义的包,还是导入从他处下载的第三方包,导入方法可归结为以下 3 种:
1. `import 包名[.模块名 [as 别名]]`
2. `from 包名 import 模块名 [as 别名]`
3. `from 包名.模块名 import 成员名 [as 别名]`
用 [] 括起来的部分,是可选部分,即可以使用,也可以直接忽略。
>
> 注意,导入包的同时,会在包目录下生成一个含有 **init**.cpython-36.pyc 文件的 **pycache** 文件夹。
>
>
>
##### 1) import 包名[.模块名 [as 别名]]
以前面创建好的 my\_package 包为例,导入 module1 模块并使用该模块中成员可以使用如下代码:
import my_package.module1
my_package.module1.display(“http://c.biancheng.net/java/”)
运行结果为:
http://c.biancheng.net/java/
可以看到,通过此语法格式导入包中的指定模块后,在使用该模块中的成员(变量、函数、类)时,需添加“包名.模块名”为前缀。当然,如果使用 as 给包名.模块名”起一个别名的话,就使用直接使用这个别名作为前缀使用该模块中的方法了,例如:
import my_package.module1 as module
module.display(“http://c.biancheng.net/python/”)
程序执行结果为:
http://c.biancheng.net/python/
另外,当直接导入指定包时,程序会自动执行该包所对应文件夹下的 **init**.py 文件中的代码。例如:
import my_package
my_package.module1.display(“http://c.biancheng.net/linux_tutorial/”)
直接导入包名,并不会将包中所有模块全部导入到程序中,它的作用仅仅是导入并执行包下的 **init**.py 文件,因此,运行该程序,在执行 **init**.py 文件中代码的同时,还会抛出 AttributeError 异常(访问的对象不存在):
http://c.biancheng.net/python/
Traceback (most recent call last):
File “C:\Users\mengma\Desktop\demo.py”, line 2, in
my\_package.module1.display(“http://c.biancheng.net/linux\_tutorial/”)
AttributeError: module ‘my\_package’ has no attribute ‘module1’
我们知道,包的本质就是模块,导入模块时,当前程序中会包含一个和模块名同名且类型为 module 的变量,导入包也是如此:
import my_package
print(my_package)
print(my_package.doc)
print(type(my_package))
运行结果为:
http://c.biancheng.net/python/
<module ‘my\_package’ from ‘C:\Users\mengma\Desktop\my\_package\**init**.py’>
http://c.biancheng.net/
创建第一个 Python 包
<class ‘module’>
##### 2) from 包名 import 模块名 [as 别名]
仍以导入 my\_package 包中的 module1 模块为例,使用此语法格式的实现代码如下:
from my_package import module1
module1.display(“http://c.biancheng.net/golang/”)
运行结果为:
http://c.biancheng.net/python/
http://c.biancheng.net/golang/
可以看到,使用此语法格式导入包中模块后,在使用其成员时不需要带包名前缀,但需要带模块名前缀。
当然,我们也可以使用 as 为导入的指定模块定义别名,例如:
from my_package import module1 as module
module.display(“http://c.biancheng.net/golang/”)
此程序的输出结果和上面程序完全相同。
同样,既然包也是模块,那么这种语法格式自然也支持 `from 包名 import *` 这种写法,它和 import 包名 的作用一样,都只是将该包的 **init**.py 文件导入并执行。
##### 3) from 包名.模块名 import 成员名 [as 别名]
此语法格式用于向程序中导入“包.模块”中的指定成员(变量、函数或类)。通过该方式导入的变量(函数、类),在使用时可以直接使用变量名(函数名、类名)调用,例如:
from my_package.module1 import display
display(“http://c.biancheng.net/shell/”)
运行结果为:
http://c.biancheng.net/python/
http://c.biancheng.net/shell/
当然,也可以使用 as 为导入的成员起一个别名,例如:
from my_package.module1 import display as dis
dis(“http://c.biancheng.net/shell/”)
该程序的运行结果和上面相同。
另外,在使用此种语法格式加载指定包的指定模块时,可以使用 \* 代替成员名,表示加载该模块下的所有成员。例如:
from my_package.module1 import *
display(“http://c.biancheng.net/python”)
## Python **init**.py作用详解
前面章节中,已经对包的创建和导入进行了详细讲解,并提供了大量的实例,这些实例虽然可以正常运行,但存在一个通病,即为了调用包内模块的成员(变量、函数或者类),代码中包含了诸多的 import 导入语句,非常繁琐。
要解决这个问题,就需要搞明白包内 **init**.py 文件的作用和用法。
我们知道,导入包就等同于导入该包中的 **init**.py 文件,因此完全可以在 **init**.py 文件中直接编写实现模块功能的变量、函数和类,但实际上并推荐大家这样做,因为包的主要作用是包含多个模块。因此 **init**.py 文件的主要作用是导入该包内的其他模块。
也就是说,通过在 **init**.py 文件使用 import 语句将必要的模块导入,这样当向其他程序中导入此包时,就可以直接导入包名,也就是使用`import 包名`(或`from 包名 import *`)的形式即可。
上节中,我们已经创建好的 my\_package 包,该包名包含 module1 模块、module2 模块和 **init**.py 文件。现在向 my\_package 包的 **init**.py 文件中编写如下代码:
从当前包导入 module1 模块
from . import module1
#from .module1 import *
从当前包导入 module2 模块
#from . import module2
from .module2 import *
可以看到,在 **init**.py 文件中用点(.)来表示当前包的包名,除此之外,from import 语句的用法和在程序中导入包的用法完全相同。
>
> 有关 from…import 语句的用法,可阅读《[Python创建包,导入包]( )》一节详细了解。
>
>
>
总的来说,**init**.py 文件是通过如下 2 种方式来导入包中模块的:
从当前包导入指定模块
from . import 模块名
从.模块名 导入所有成员到包中
from .模块名 import *
第 1 种方式用于导入当前包(模块)中的指定模块,这样即可在包中使用该模块。当在其他程序使用模块内的成员时,需要添加“包名.模块名”作为前缀,例如:
import my_package
my_package.module1.display(“http://c.biancheng.net/python/”)
运行结果为:
http://c.biancheng.net/python/
第 2 种方式表示从指定模块中导入所有成员,采用这种导入方式,在其他程序中使用该模块的成员时,只要使用包名作为前缀即可。例如如下程序:
import my_package
clangs = my_package.CLanguage()
clangs.display()
运行结果为:
http://c.biancheng.net/python/
## Python查看模块(变量、函数、类)方法
前面章节中,详细介绍了模块和包的创建和使用(严格来说,包本质上也是模块),有些读者可能有这样的疑问,即正确导入模块或者包之后,怎么知道该模块中具体包含哪些成员(变量、函数或者类)呢?
查看已导入模块(包)中包含的成员,本节给大家介绍 2 种方法。
### 查看模块成员:dir()函数
事实上,在前面章节的学习中,曾多次使用 dir() 函数。通过 dir() 函数,我们可以查看某指定模块包含的全部成员(包括变量、函数和类)。注意这里所指的全部成员,不仅包含可供我们调用的模块成员,还包含所有名称以双下划线“\_\_”开头和结尾的成员,而这些“特殊”命名的成员,是为了在本模块中使用的,并不希望被其它文件调用。
这里以导入 string 模块为例,string 模块包含操作字符串相关的大量方法,下面通过 dir() 函数查看该模块中包含哪些成员:
import string
print(dir(string))
程序执行结果为:
[‘Formatter’, ‘Template’, ‘\_ChainMap’, ‘\_TemplateMetaclass’, ‘**all**’, ‘**builtins**’, ‘**cached**’, ‘**doc**’, ‘**file**’, ‘**loader**’, ‘**name**’, ‘**package**’, ‘**spec**’, ‘\_re’, ‘\_string’, ‘ascii\_letters’, ‘ascii\_lowercase’, ‘ascii\_uppercase’, ‘capwords’, ‘digits’, ‘hexdigits’, ‘octdigits’, ‘printable’, ‘punctuation’, ‘whitespace’]
可以看到,通过 dir() 函数获取到的模块成员,不仅包含供外部文件使用的成员,还包含很多“特殊”(名称以 2 个下划线开头和结束)的成员,列出这些成员,对我们并没有实际意义。
因此,这里给读者推荐一种可以忽略显示 dir() 函数输出的特殊成员的方法。仍以 string 模块为例:
import string
print([e for e in dir(string) if not e.startswith(‘_’)])
程序执行结果为:
[‘Formatter’, ‘Template’, ‘ascii\_letters’, ‘ascii\_lowercase’, ‘ascii\_uppercase’, ‘capwords’, ‘digits’, ‘hexdigits’, ‘octdigits’, ‘printable’, ‘punctuation’, ‘whitespace’]
显然通过列表推导式,可在 dir() 函数输出结果的基础上,筛选出对我们有用的成员并显示出来。
### 查看模块成员:\_\_all\_\_变量
除了使用 dir() 函数之外,还可以使用 **all** 变量,借助该变量也可以查看模块(包)内包含的所有成员。
仍以 string 模块为例,举个例子:
import string
print(string.all)
程序执行结果为:
[‘ascii\_letters’, ‘ascii\_lowercase’, ‘ascii\_uppercase’, ‘capwords’, ‘digits’, ‘hexdigits’, ‘octdigits’, ‘printable’, ‘punctuation’, ‘whitespace’, ‘Formatter’, ‘Template’]
显然,和 dir() 函数相比,**all** 变量在查看指定模块成员时,它不会显示模块中的特殊成员,同时还会根据成员的名称进行排序显示。
不过需要注意的是,并非所有的模块都支持使用 **all** 变量,因此对于获取有些模块的成员,就只能使用 dir() 函数。
## Python \_\_doc\_\_属性:查看文档
在使用 dir() 函数和 **all** 变量的基础上,虽然我们能知晓指定模块(或包)中所有可用的成员(变量、函数和类),比如:
import stringprint(string.all)
程序执行结果为:
[‘ascii\_letters’, ‘ascii\_lowercase’, ‘ascii\_uppercase’, ‘capwords’, ‘digits’, ‘hexdigits’, ‘octdigits’, ‘printable’, ‘punctuation’, ‘whitespace’, ‘Formatter’, ‘Template’]
但对于以上的输出结果,对于不熟悉 string 模块的用户,还是不清楚这些名称分别表示的是什么意思,更不清楚各个成员有什么功能。
针对这种情况,我们可以使用 help() 函数来获取指定成员(甚至是该模块)的帮助信息。以前面章节创建的 my\_package 包为例,该包中包含 **init**.py 、module1.py 和 module2.py 这 3 个模块,它们各自包含的内容分别如下所示:
#init.py 文件中的内容
from my_package.module1 import *
from my_package.module2 import *
#module1.py 中的内容
#module1.py模块文件
def display(arc):
‘’’
直接输出指定的参数
‘’’
print(arc)
#module2.py中的内容
#module2.py 模块文件
class CLanguage:
‘’’
CLanguage是一个类,其包含:
display() 方法
‘’’
def display(self):
print(“http://c.biancheng.net/python/”)
现在,我们先借助 dir() 函数,查看 my\_package 包中有多少可供我们调用的成员:
import my_package
print([e for e in dir(my_package) if not e.startswith(‘_’)])
程序输出结果为:
[‘CLanguage’, ‘display’, ‘module1’, ‘module2’]
通过此输出结果可以得知,在 my\_package 包中,有以上 4 个成员可供我们使用。接下来,我们使用 help() 函数来查看这些成员的具体含义(以 module1 为例):
import my_package
help(my_package.module1)
输出结果为:
Help on module my\_package.module1 in my\_package:
NAME
my\_package.module1 - #module1.py模块文件
FUNCTIONS
display(arc)
直接输出指定的参数
FILE
c:\users\mengma\desktop\my\_package\module1.py
通过输出结果可以得知,module1 实际上是一个模块文件,其包含 display() 函数,该函数的功能是直接输出指定的 arc 参数。同时,还显示出了该模块具体的存储位置。
当然,有兴趣的读者还可以尝试运行如下几段代码:
#输出 module2 成员的具体信息
help(my_package.module2)
#输出 display 成员的具体信息
help(my_package.module1.display)
#输出 CLanguage 成员的具体信息
help(my_package.module2.CLanguage)
值得一提的是,之所以我们可以使用 help() 函数查看具体成员的信息,是因为该成员本身就包含表示自身身份的说明文档(本质是字符串,位于该成员内部开头的位置)。前面讲过,无论是函数还是类,都可以使用 **doc** 属性获取它们的说明文档,模块也不例外。
以 my\_package 包 module1 模块中的 display() 函数为例,我们尝试用 **doc** 变量获取其说明文档:
import my_package
print(my_package.module1.display.doc)
程序执行结果为:
直接输出指定的参数
>
> 其实,help() 函数底层也是借助 **doc** 属性实现的。
>
>
>
那么,如果使用 help() 函数或者 **doc** 属性,仍然无法满足我们的需求,还可以使用以下 2 种方法:
**自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。**
**深知大多数Python工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!**
**因此收集整理了一份《2024年Python开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。**






**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Python开发知识点,真正体系化!**
**由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新**
**如果你觉得这些内容对你有帮助,可以添加V获取:vip1024c (备注Python)**

### 最后
> **🍅 硬核资料**:关注即可领取PPT模板、简历模板、行业经典书籍PDF。
> **🍅 技术互助**:技术群大佬指点迷津,你的问题可能不是问题,求资源在群里喊一声。
> **🍅 面试题库**:由技术群里的小伙伴们共同投稿,热乎的大厂面试真题,持续更新中。
> **🍅 知识体系**:含编程语言、算法、大数据生态圈组件(Mysql、Hive、Spark、Flink)、数据仓库、Python、前端等等。
**一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**

则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!**
**因此收集整理了一份《2024年Python开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。**
[外链图片转存中...(img-4uuVIzD5-1712930519750)]
[外链图片转存中...(img-op6hZ2Tp-1712930519751)]




**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Python开发知识点,真正体系化!**
**由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新**
**如果你觉得这些内容对你有帮助,可以添加V获取:vip1024c (备注Python)**
[外链图片转存中...(img-camL428J-1712930519751)]
### 最后
> **🍅 硬核资料**:关注即可领取PPT模板、简历模板、行业经典书籍PDF。
> **🍅 技术互助**:技术群大佬指点迷津,你的问题可能不是问题,求资源在群里喊一声。
> **🍅 面试题库**:由技术群里的小伙伴们共同投稿,热乎的大厂面试真题,持续更新中。
> **🍅 知识体系**:含编程语言、算法、大数据生态圈组件(Mysql、Hive、Spark、Flink)、数据仓库、Python、前端等等。
**一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
[外链图片转存中...(img-hnS5bEod-1712930519751)]















 1197
1197

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









