







 本文详细介绍了如何使用Pandas在Python中进行数据结构操作,包括创建Series和DataFrame,重命名列,数据过滤、排序、分组和统计。同时涵盖了数据预处理和数据可视化中的常见问题解决方法。
本文详细介绍了如何使用Pandas在Python中进行数据结构操作,包括创建Series和DataFrame,重命名列,数据过滤、排序、分组和统计。同时涵盖了数据预处理和数据可视化中的常见问题解决方法。
Tips:"分享是快乐的源泉💧,在我的博客里,不仅有知识的海洋🌊,还有满满的正能量加持💪,快来和我一起分享这份快乐吧😊!
喜欢我的博客的话,记得点个红心❤️和小关小注哦!您的支持是我创作的动力!数据源存放在我的资源下载区啦!
数据可视化(五):Pandas高级统计——函数映射、数据结构、分组聚合等问题解决,能否成为你的工作备用锦囊?
目录
- 1. pandas数据结构
- 2. pandas统计
- 3. pandas数据过滤与排序
- 问题1:选择Goals列显示。
- 问题2:多少队伍参加Euro2012?
- 问题3:数据集中有多少列?
- 问题4:选择Team、Yellow Cards、Red Cards三列形成新的DataFrame,命名为discipline。
- 问题5:对discipline采用Red Cards以及Yellow Cards(先按Red Cards排再按Yellow Cards排)降序排序。
- 问题6:计算Team的平均Yellow Cards数,四舍五入保留整数。
- 问题7:将进球超过6(goals>6)的行找出来。
- 问题8:找出G开头Team的所有行。
- 问题9:选择除了最后三列以外的所有列。
- 问题10:只显示England、Italy、Russia三队的Shooting Accuracy列。
- 4. pandas数据分组
- 5. pandas函数映射
1. pandas数据结构
import pandas as pd
import numpy as np
问题1:创建3个不同的Series,长度都是100。
- 第一个:每个元素是1~4(包含)随机整数
- 第二个:每个元素是1~3(包含)随机整数
- 第三个:每个元素是10000~20000(包含)随机整数
# 创建第一个Series,每个元素是1~4(包含)随机整数
series1 = pd.Series(np.random.randint(1, 5, size=100))
series1

# 创建第二个Series,每个元素是1~3(包含)随机整数
series2 = pd.Series(np.random.randint(1, 4, size=100))
series2
# 创建第三个Series,每个元素是10000~20000(包含)随机整数
series3 = pd.Series(np.random.randint(10000, 20001, size=100))
series3
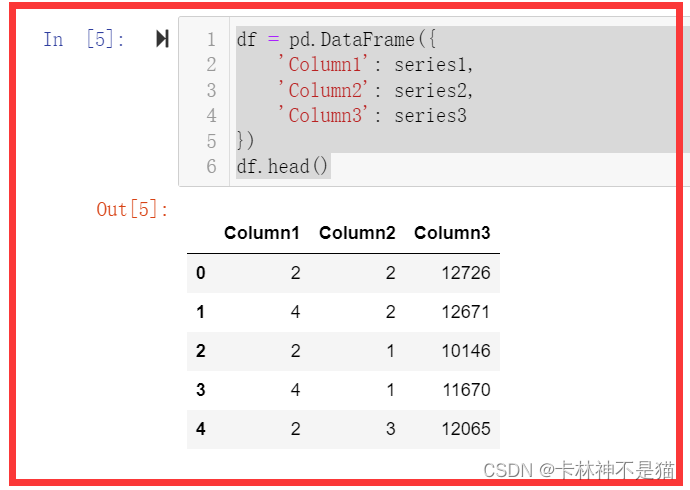
问题2:利用这3个Series作为3列创建一个DataFrame。
df = pd.DataFrame({
'Column1': series1,
'Column2': series2,
'Column3': series3
})
df.head()
问题3:将上面DataFrame的列名改为bedrs、bathrs和price_sqr_meter。
new_columns = ["bedrs","bathrs","price_sqr_meter"]
df.columns = new_columns
df.head()

问题4:利用上面3个Series作为1列创建一个DataFrame
# 使用 concat 函数将三个 Series 合并成一个新的 Series
# ignore_index=True 参数用于重置合并后 Series 的索引
combined_series = pd.concat([series1, series2, series3], ignore_index=True)
combined_series
# 将 series 转化为 dataframe
df = pd.DataFrame({"Concat":combined_series})
df
问题5:上面的DataFrame的index到99为止,请将其reindex为0~299。
# 重新索引 df,使其索引从 0 到 299
# 使用 NaN 填充新增的索引位置
df_reindexed = df.reindex(range(300))
# 打印重新索引后的 DataFrame
df_reindexed
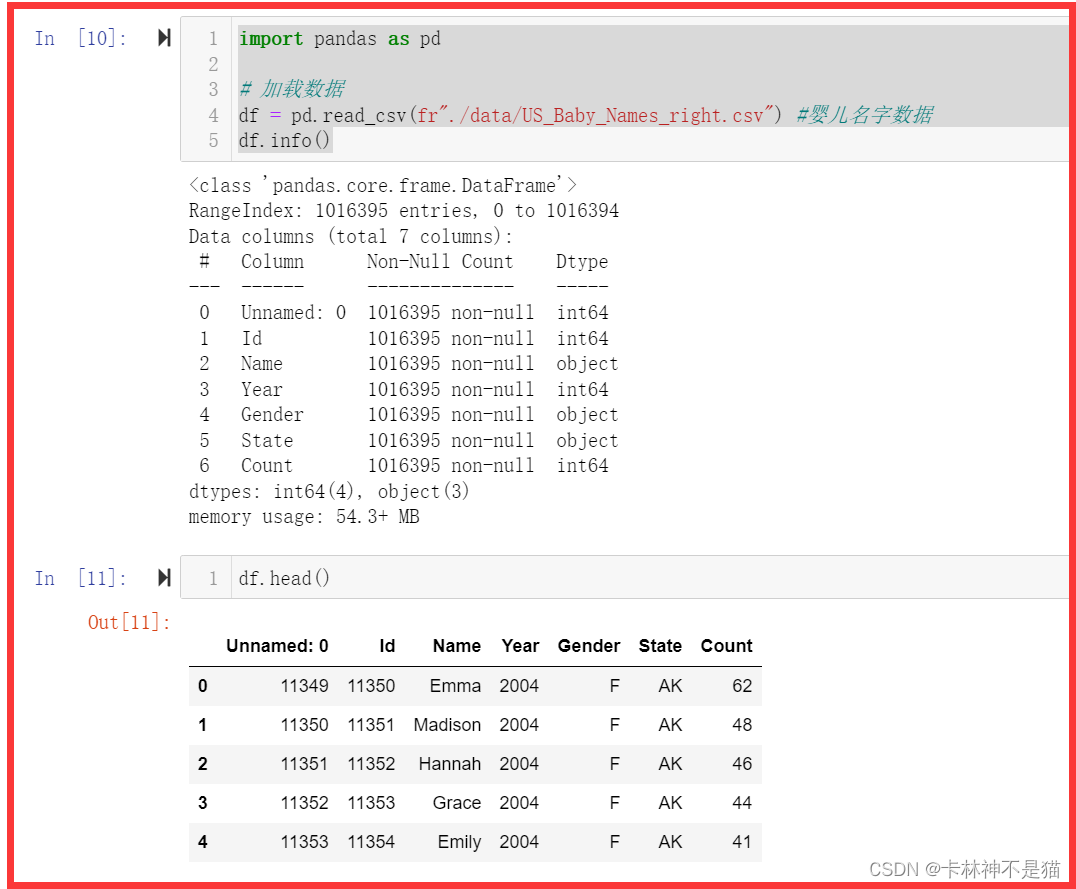
2. pandas统计
import pandas as pd
# 加载数据
# assets/US_Baby_Names_right.zip解压
df = pd.read_csv('assets/US_Baby_Names_right.csv') #婴儿名字数据
df.info()
df.head()
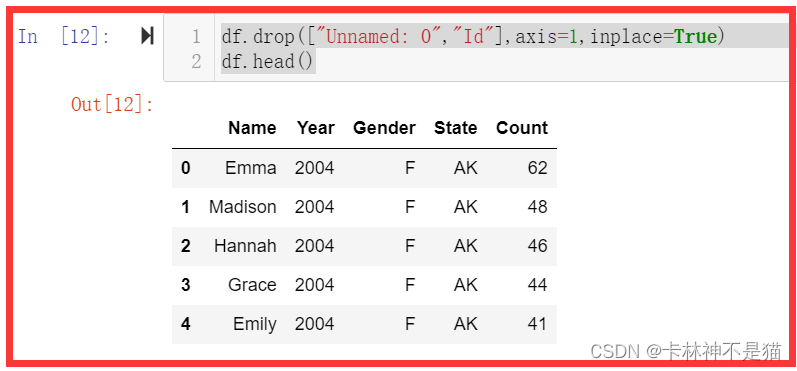
问题1:删除列’Unnamed: 0’ 和 ‘Id’。
df.drop(["Unnamed: 0","Id"],axis=1,inplace=True)
df.head()
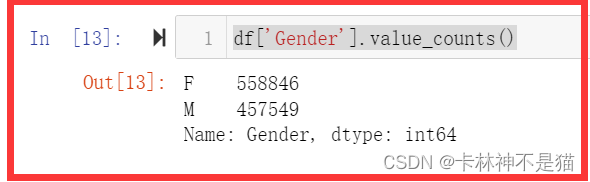
问题2:男孩和女孩的总数是多少?
df['Gender'].value_counts()
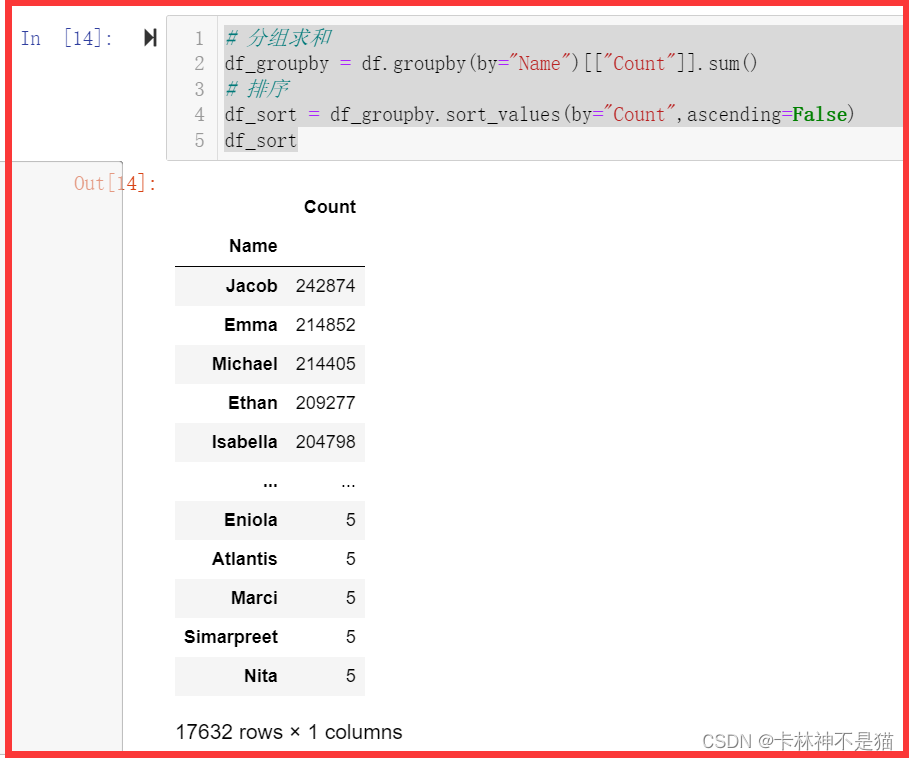
问题3:将数据按照Name分组统计出现数量,并按照降序排列。
# 分组求和
df_groupby = df.groupby(by="Name")[["Count"]].sum()
# 排序
df_sort = df_groupby.sort_values(by="Count",ascending=False)
df_sort
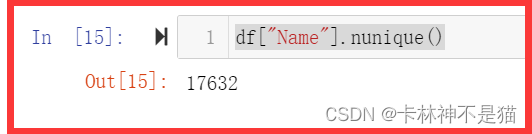
问题4:数据集中有多少不同名字?
df["Name"].nunique()
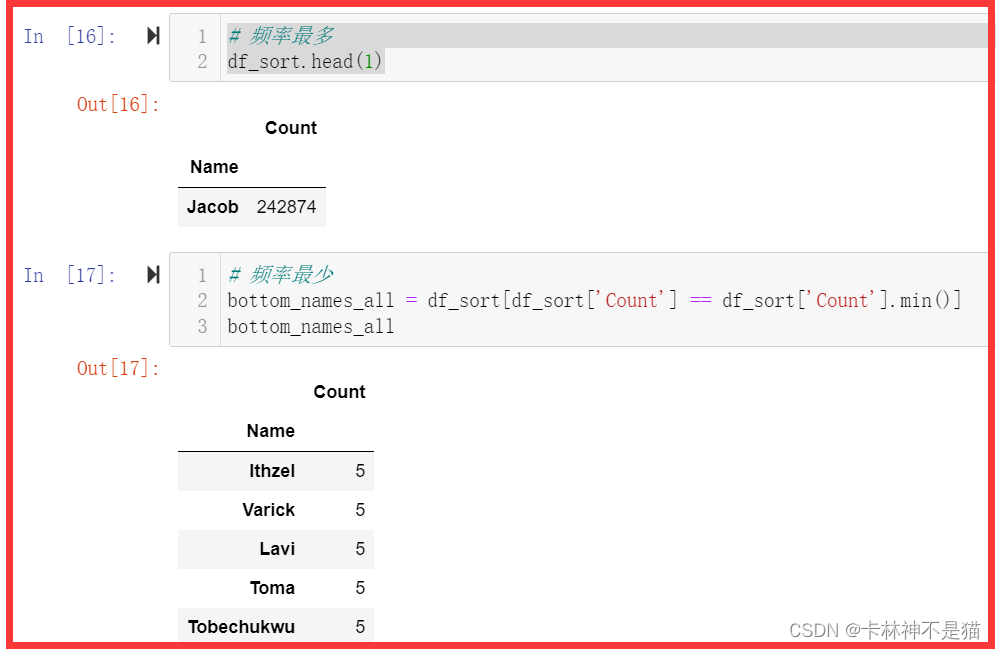
问题5: 出现频率最多和最少的名字是(可能数量不唯一,按排序结果)?
# 频率最多
df_sort.head(1)
3. pandas数据过滤与排序
import pandas as pd
# 加载数据
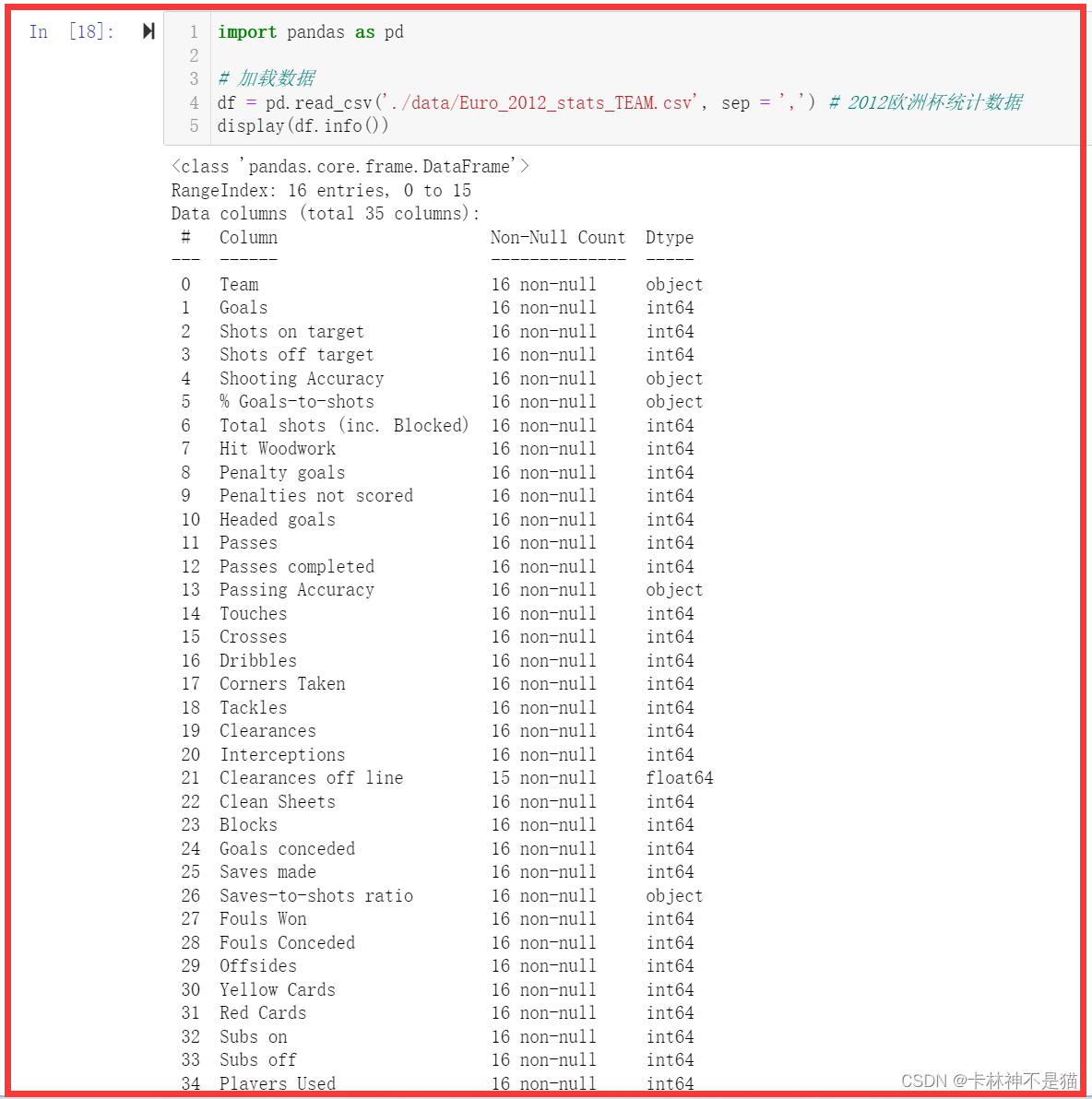
df = pd.read_csv('assets/Euro_2012_stats_TEAM.csv', sep = ',') # 2012欧洲杯统计数据
display(df.info())
df.head()
问题1:选择Goals列显示。
df[["Goals"]].head()


问题2:多少队伍参加Euro2012?
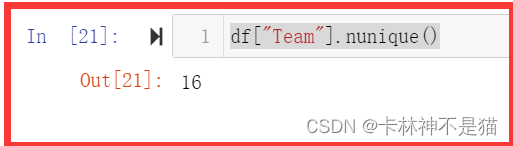
df["Team"].nunique()
问题3:数据集中有多少列?
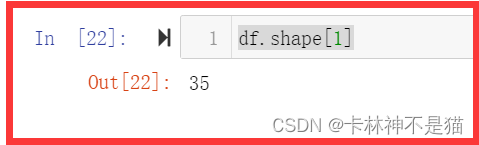
df.shape[1]
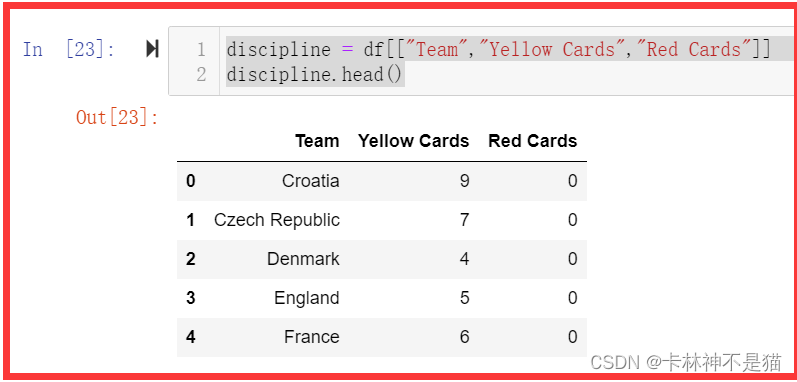
问题4:选择Team、Yellow Cards、Red Cards三列形成新的DataFrame,命名为discipline。
discipline = df[["Team","Yellow Cards","Red Cards"]]
discipline.head()
问题5:对discipline采用Red Cards以及Yellow Cards(先按Red Cards排再按Yellow Cards排)降序排序。
discipline_sorted = discipline.sort_values(by=["Red Cards","Yellow Cards"],ascending=False)
discipline_sorted.head()

问题6:计算Team的平均Yellow Cards数,四舍五入保留整数。
discipline.groupby(by="Team")[["Yellow Cards"]].mean().round()

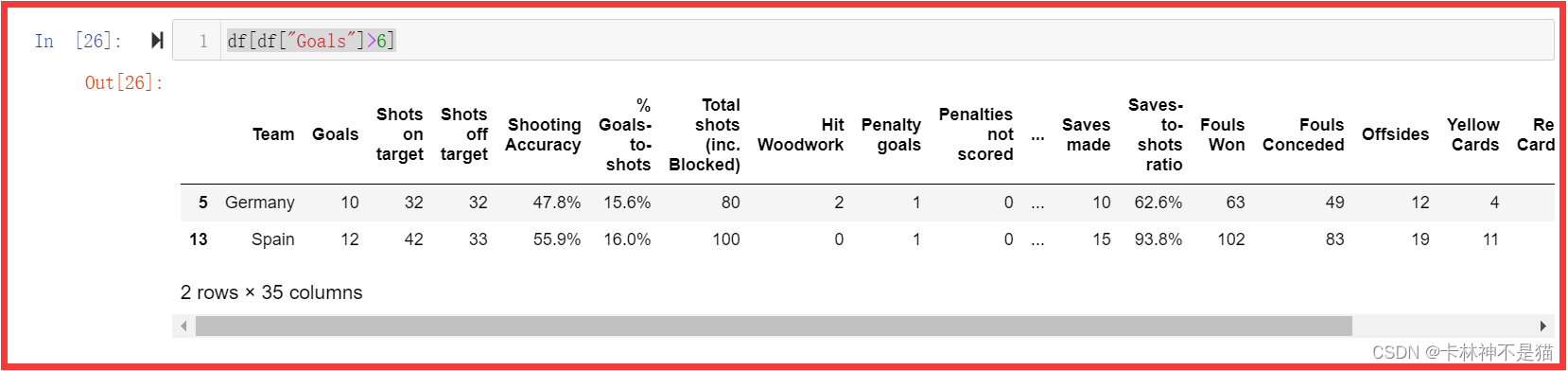
问题7:将进球超过6(goals>6)的行找出来。
df[df["Goals"]>6]
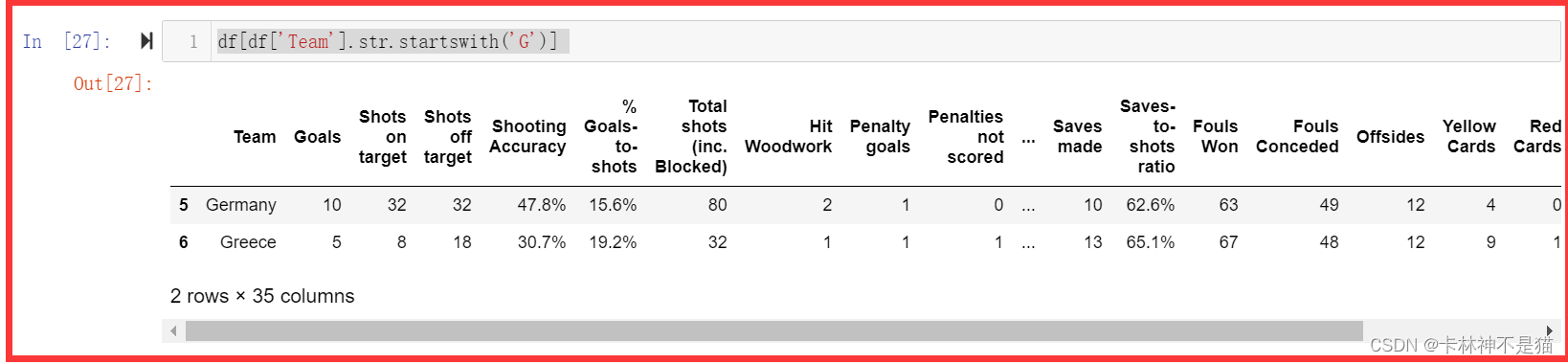
问题8:找出G开头Team的所有行。
df[df['Team'].str.startswith('G')]
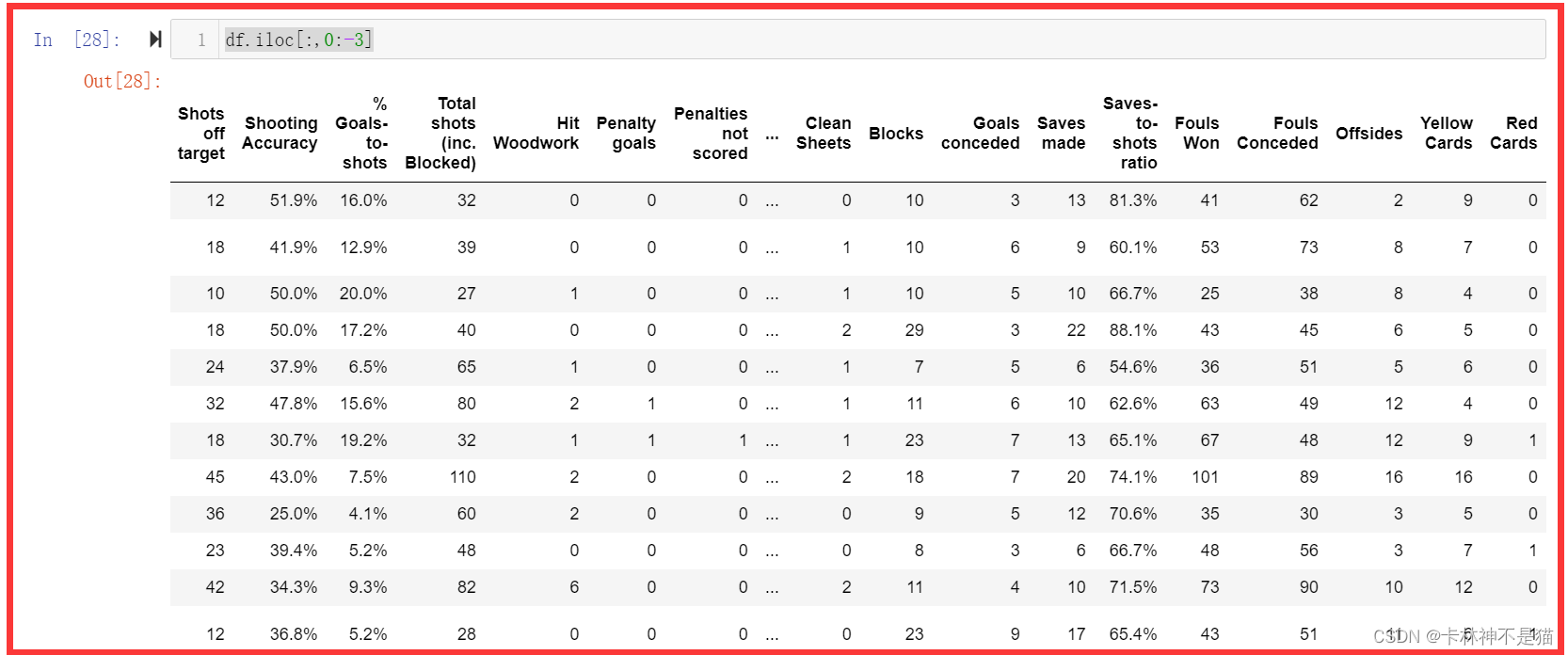
问题9:选择除了最后三列以外的所有列。
df.iloc[:,0:-3]
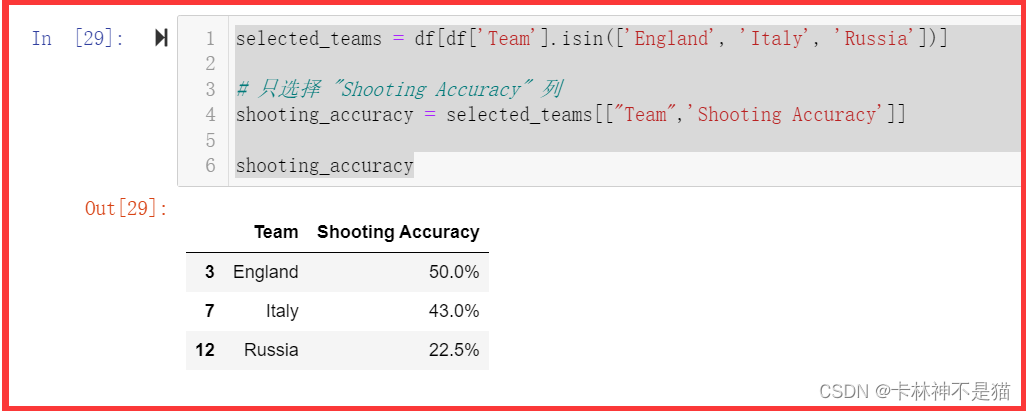
问题10:只显示England、Italy、Russia三队的Shooting Accuracy列。
selected_teams = df[df['Team'].isin(['England', 'Italy', 'Russia'])]
# 只选择 "Shooting Accuracy" 列
shooting_accuracy = selected_teams[["Team",'Shooting Accuracy']]
shooting_accuracy
4. pandas数据分组
import pandas as pd
# 加载数据
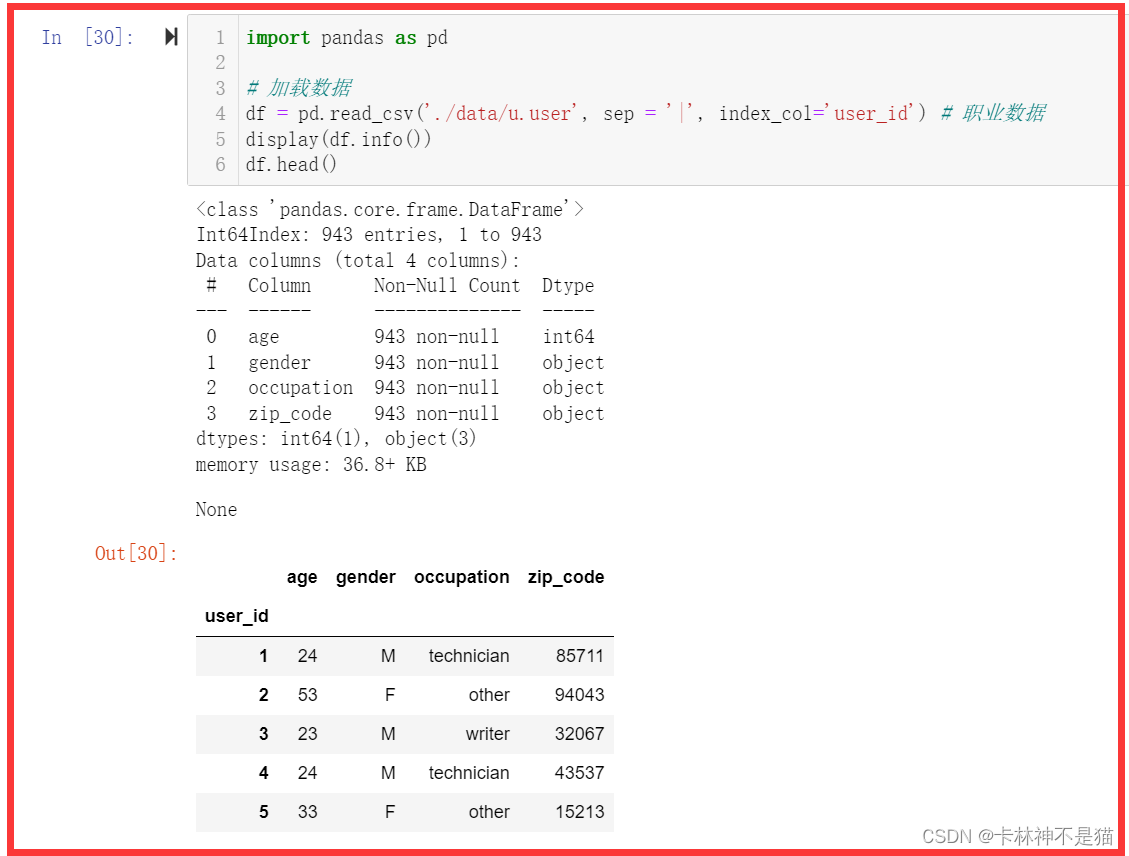
df = pd.read_csv('assets/u.user', sep = '|', index_col='user_id') # 职业数据
display(df.info())
df.head()
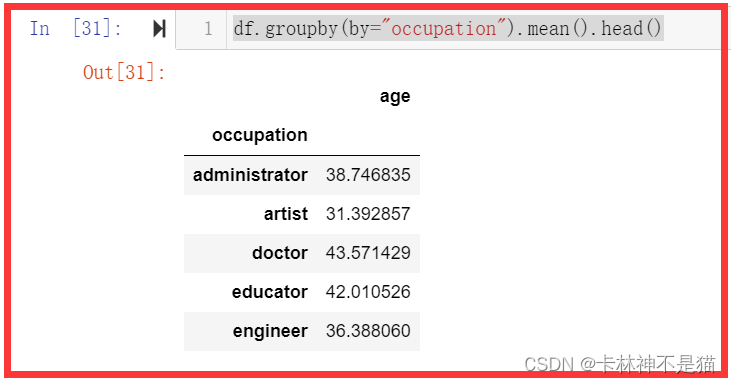
问题1:计算每种职业的平均年龄。
df.groupby(by="occupation").mean().head()
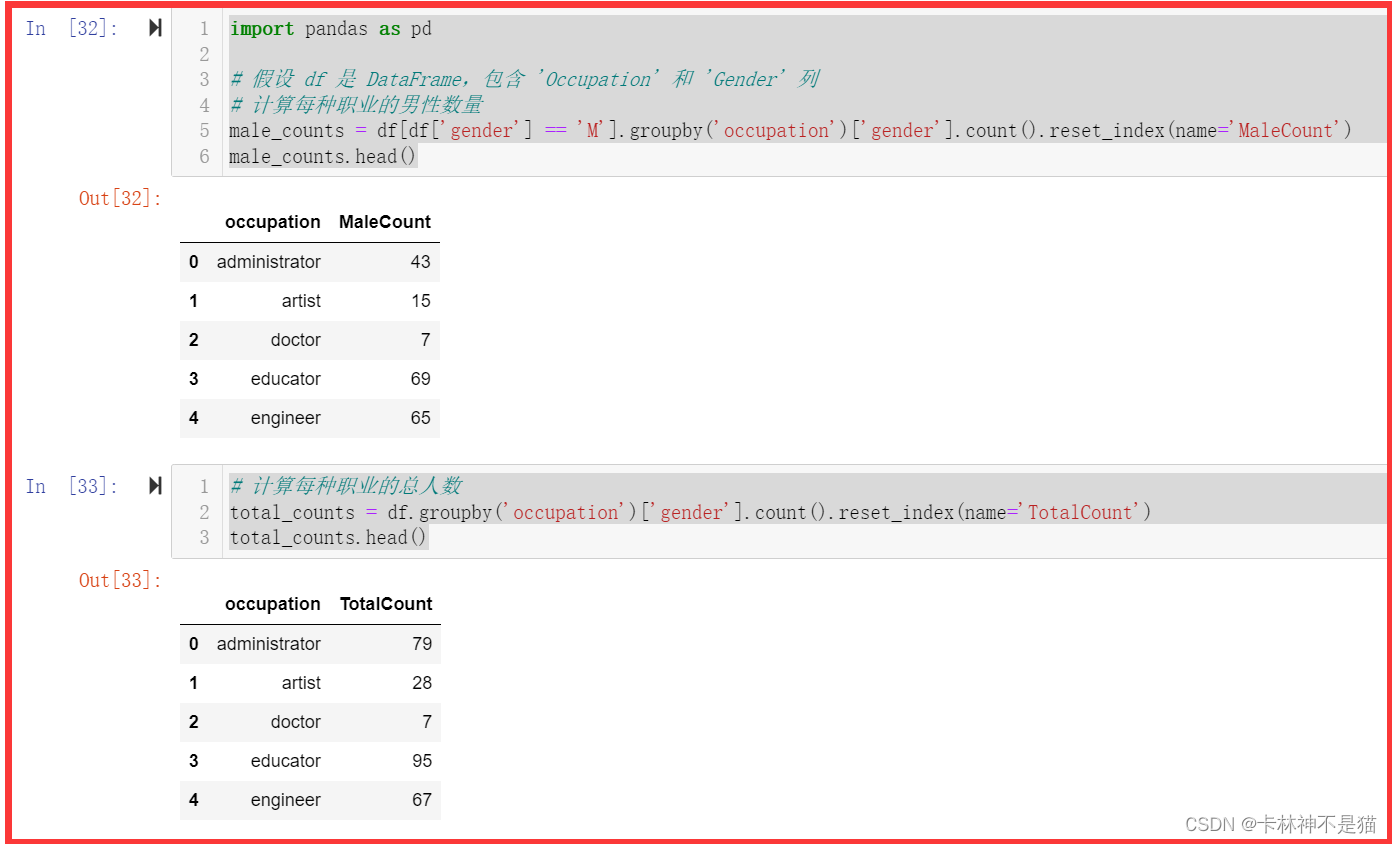
问题2:计算每种职业的男性占比,并从大到小排序。(难,选做)
import pandas as pd
# 假设 df 是 DataFrame,包含 'Occupation' 和 'Gender' 列
# 计算每种职业的男性数量
male_counts = df[df['gender'] == 'M'].groupby('occupation')['gender'].count().reset_index(name='MaleCount')
male_counts.head()
# 计算每种职业的总人数
total_counts = df.groupby('occupation')['gender'].count().reset_index(name='TotalCount')
total_counts.head()
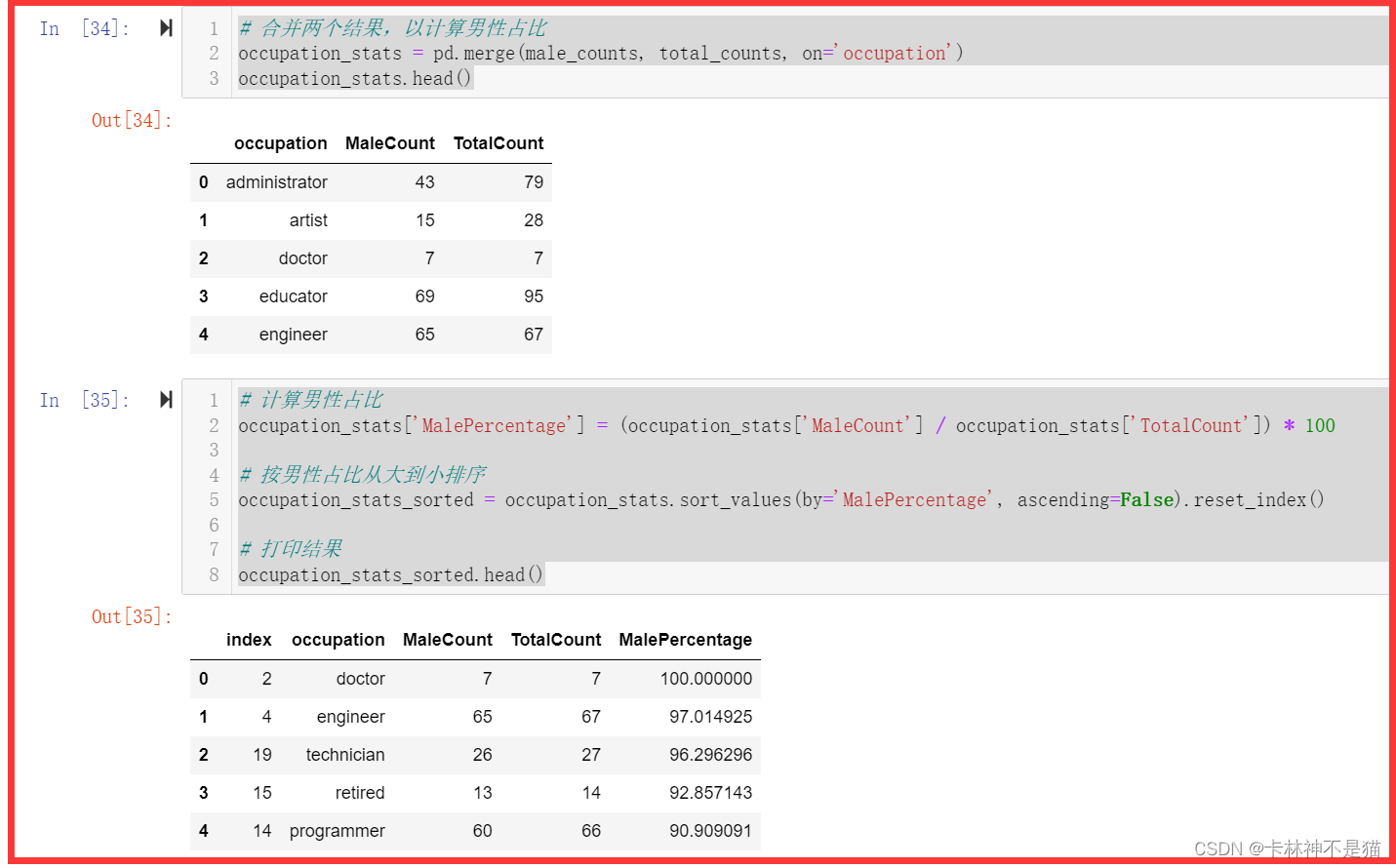
# 合并两个结果,以计算男性占比
occupation_stats = pd.merge(male_counts, total_counts, on='occupation')
occupation_stats.head()
# 计算男性占比
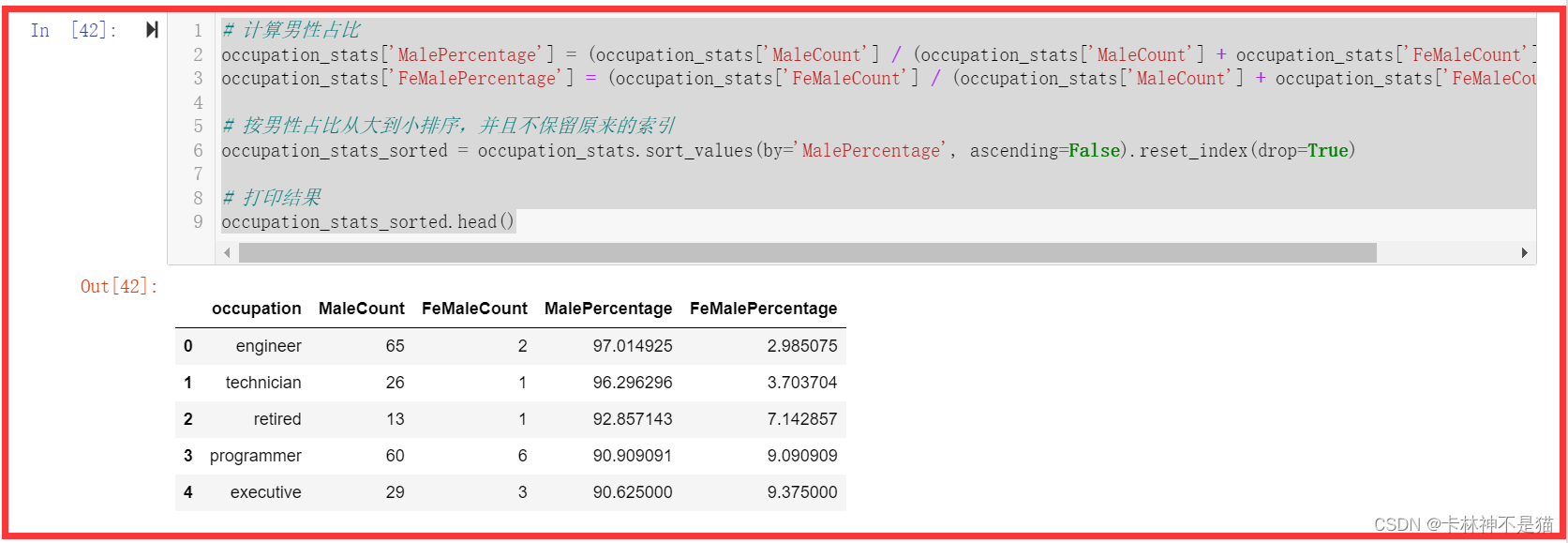
occupation_stats['MalePercentage'] = (occupation_stats['MaleCount'] / occupation_stats['TotalCount']) * 100
# 按男性占比从大到小排序
occupation_stats_sorted = occupation_stats.sort_values(by='MalePercentage', ascending=False).reset_index()
# 打印结果
occupation_stats_sorted.head()
问题3: 对于每种职业,计算最小和最大年龄。
# 最小年龄,不能两个 []
df.groupby(by="occupation")["age"].min().reset_index(name='Min_Age').head()
# 最大年龄,不能两个 []
df.groupby(by="occupation")["age"].max().reset_index(name='Max_Age').head()
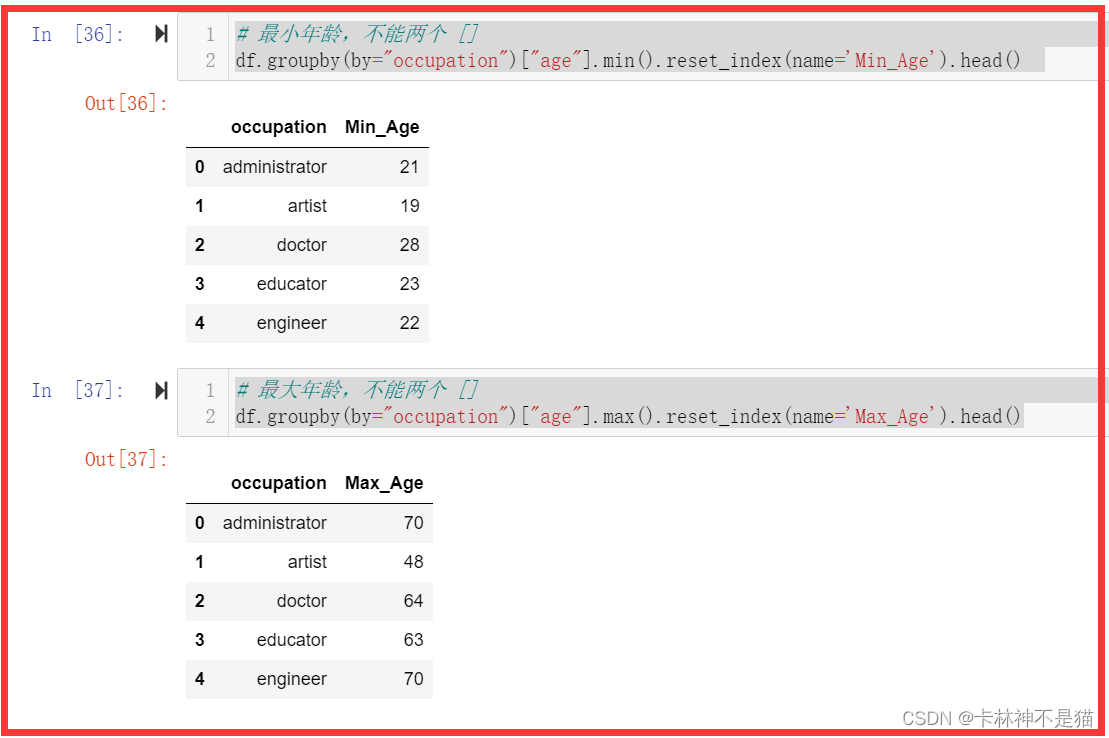
问题4:按职业、性别分组,计算平均年龄。
df.groupby(by=["occupation","gender"])["age"].mean().reset_index(name= "Mean_Age").head()
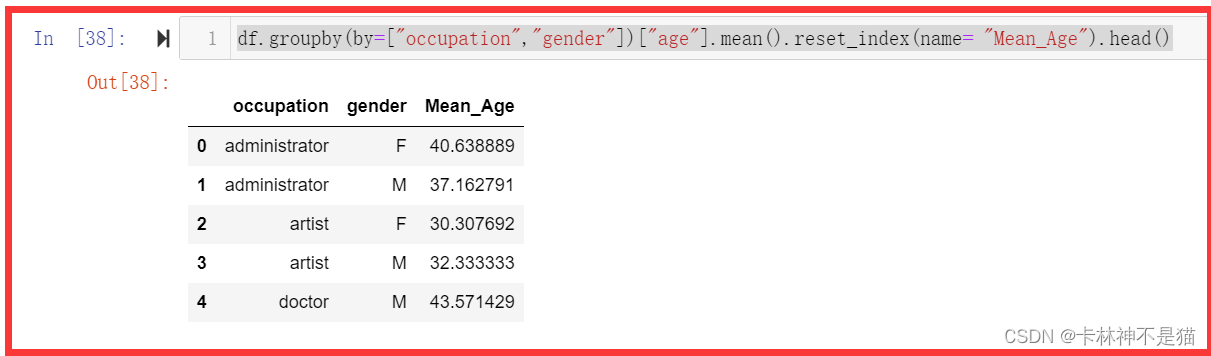
问题5:对于每种职业,显示男女性别占比。(难,选做)
import pandas as pd
# 假设 df 是你的 DataFrame,包含 'Occupation' 和 'Gender' 列
# 计算每种职业的男性数量
male_counts = df[df['gender'] == 'M'].groupby('occupation')['gender'].count().reset_index(name='MaleCount')
male_counts.head()
# 计算每种职业的女性数量
female_counts = df[df['gender'] == 'F'].groupby('occupation')['gender'].count().reset_index(name='FeMaleCount')
female_counts.head()
# 合并两个结果,以计算男性女性占比
occupation_stats = pd.merge(male_counts, female_counts, on='occupation')
occupation_stats.head()
# 计算男性占比
occupation_stats['MalePercentage'] = (occupation_stats['MaleCount'] / (occupation_stats['MaleCount'] + occupation_stats['FeMaleCount']) ) * 100
occupation_stats['FeMalePercentage'] = (occupation_stats['FeMaleCount'] / (occupation_stats['MaleCount'] + occupation_stats['FeMaleCount']) ) * 100
# 按男性占比从大到小排序,并且不保留原来的索引
occupation_stats_sorted = occupation_stats.sort_values(by='MalePercentage', ascending=False).reset_index(drop=True)
# 打印结果
occupation_stats_sorted.head()

5. pandas函数映射
import pandas as pd
import numpy
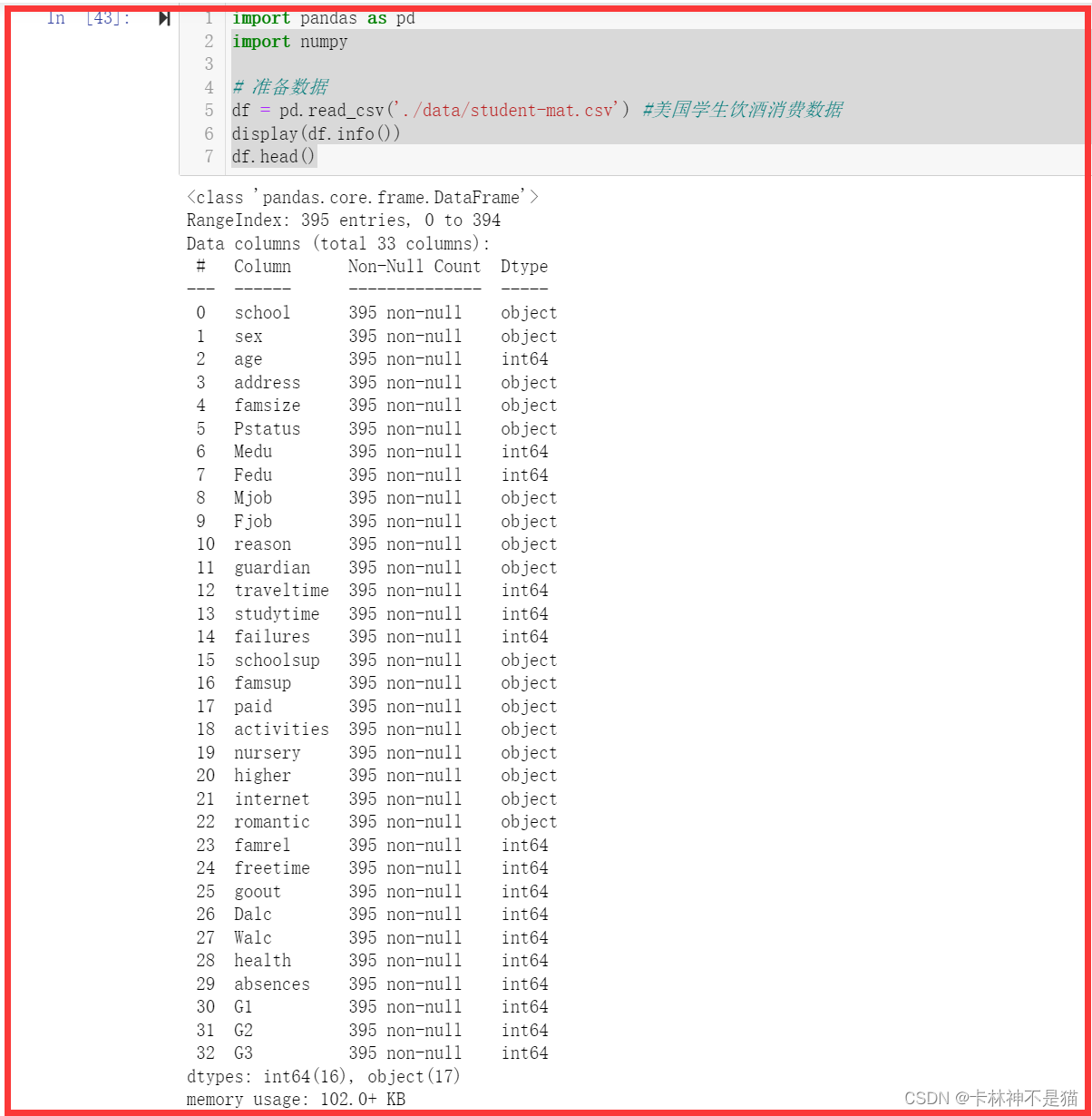
# 准备数据
df = pd.read_csv('assets/student-mat.csv') #美国学生饮酒消费数据
display(df.info())
df.head()
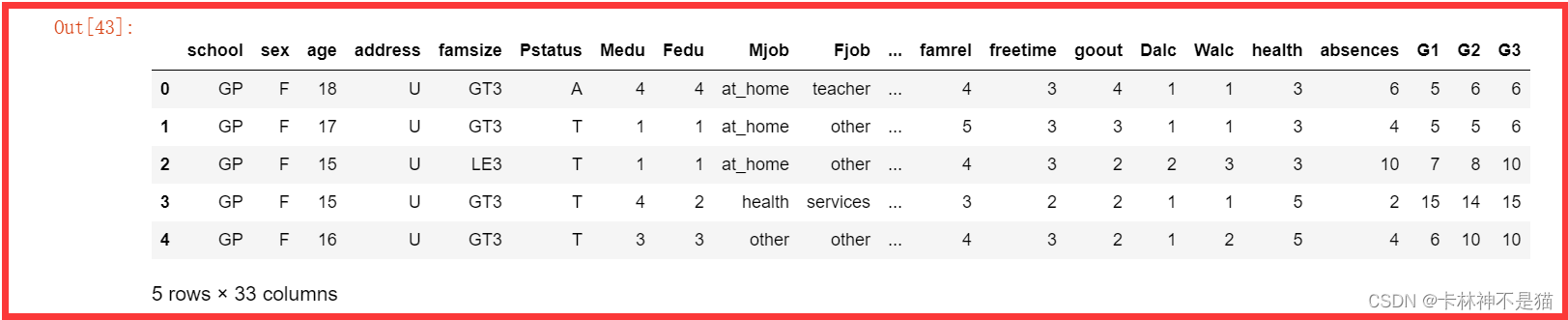
问题1:切片列school到列guardian。
df.loc[:,"school":"guardian"]

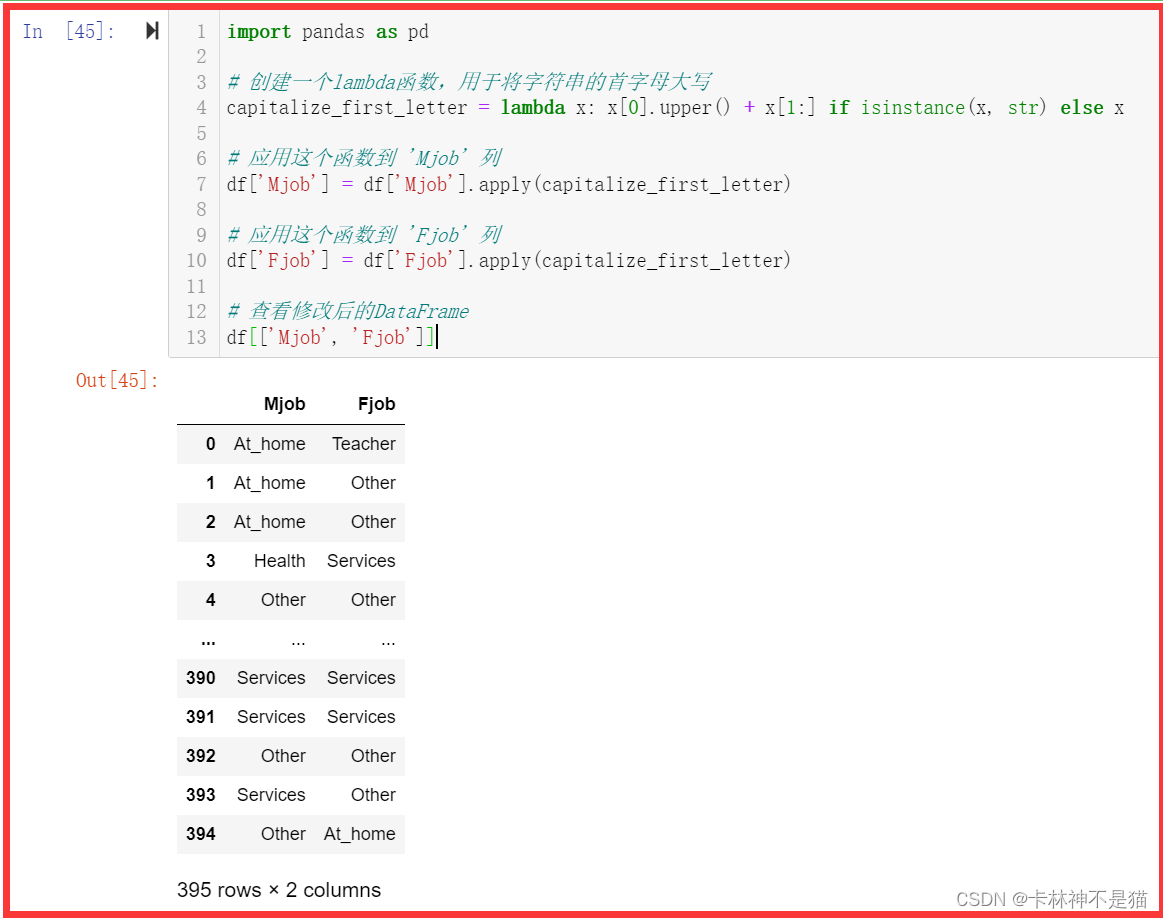
问题2:创建lambda函数用于将字符串首字母大写,并应用到Mjob和Fjob列数据。
import pandas as pd
# 创建一个lambda函数,用于将字符串的首字母大写
capitalize_first_letter = lambda x: x[0].upper() + x[1:] if isinstance(x, str) else x
# 应用这个函数到 'Mjob' 列
df['Mjob'] = df['Mjob'].apply(capitalize_first_letter)
# 应用这个函数到 'Fjob' 列
df['Fjob'] = df['Fjob'].apply(capitalize_first_letter)
# 查看修改后的DataFrame
df[['Mjob', 'Fjob']]
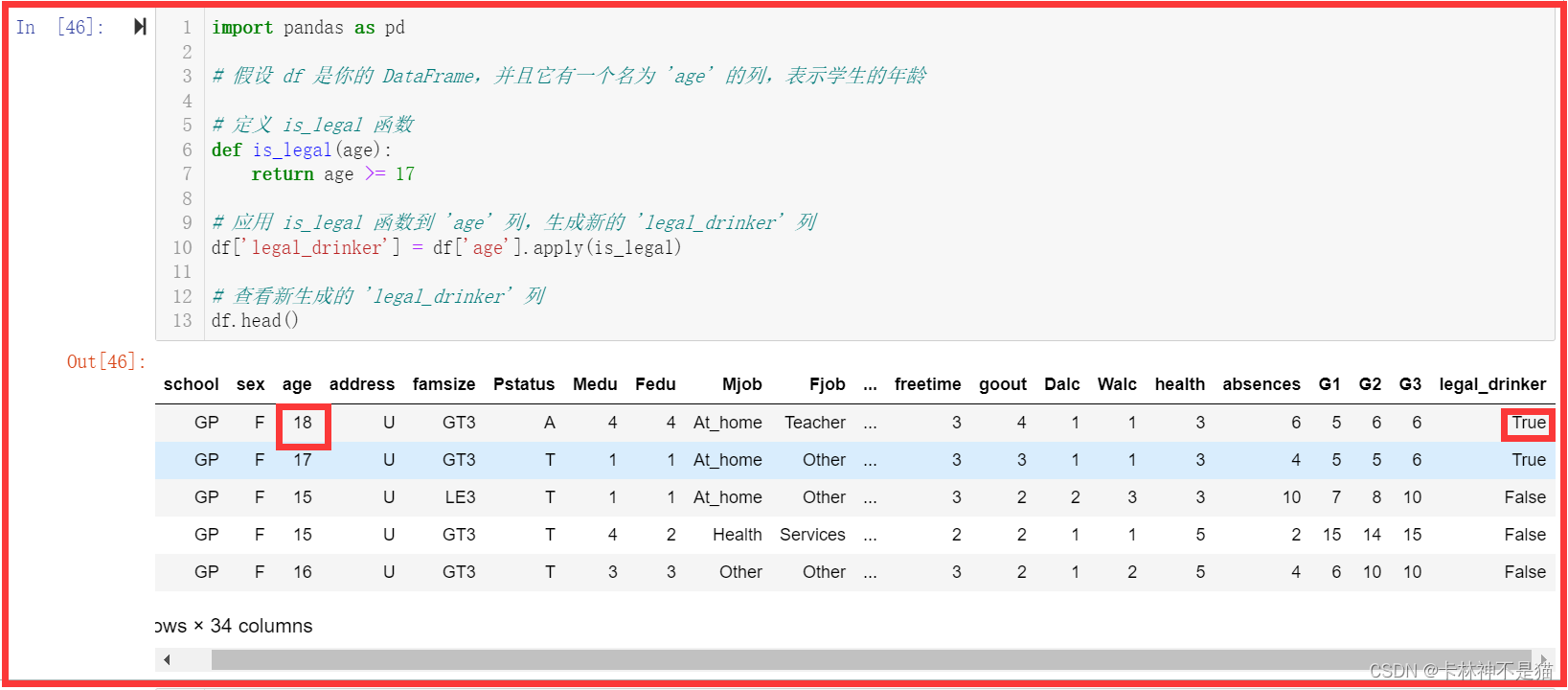
问题3:创建函数is_legal(),并应用到数据集,返回一个新列legal_drinker,列元素值为布尔类型,True表示学生年龄大于等于17(合法饮酒),False表示小于17(不合法饮酒)。
import pandas as pd
# 假设 df 是你的 DataFrame,并且它有一个名为 'age' 的列,表示学生的年龄
# 定义 is_legal 函数
def is_legal(age):
return age >= 17
# 应用 is_legal 函数到 'age' 列,生成新的 'legal_drinker' 列
df['legal_drinker'] = df['age'].apply(is_legal)
# 查看新生成的 'legal_drinker' 列
df.head()

















 3198
3198

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











