







xinference部署本地llm、embedding模型
由于langchain-chatchat0.3.0的更新,chatchat项目已支持glm4,但模型部署不再支持在config中修改本地路径,需要通过xinference等模型部署框架导入
相关文章:
langchain-chatchat +glm4-9b-chat 轻松实现知识库智能问答!超详细部署!无坑!
为了后续研究,这里将模型下载到了本地linux服务器
本文介绍如何通过xinference加载本地下载的模型
模型下载地址
这里直接通过Files栏将模型下载到本地
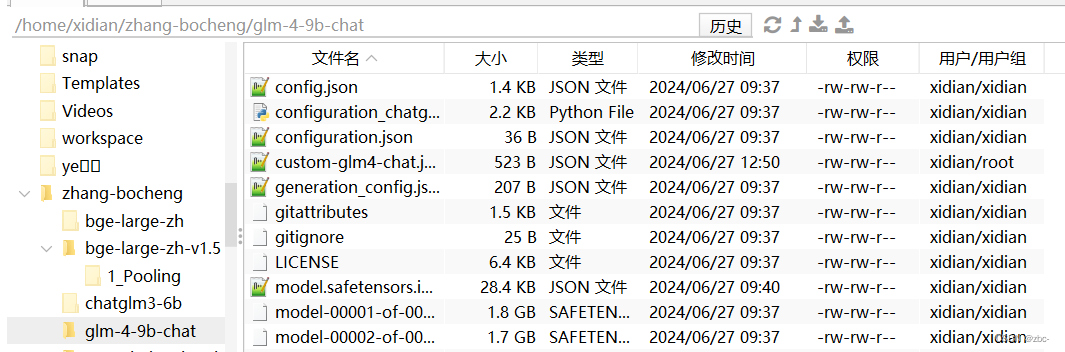
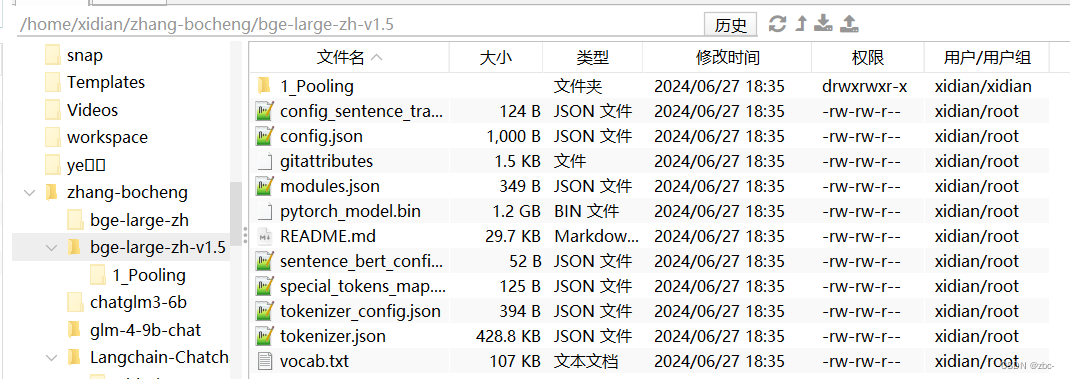
配置虚拟环境
- 创建虚拟环境
conda create --name xinference python=3.10.9 - 激活虚拟环境
conda activate xinference
安装依赖
参考官网安装教程
官网-安装
我这里仅安装了Transformers引擎
pip install "xinference[transformers]"
开启本地xinference服务
xinference-local --host 0.0.0.0 --port 9997
可以通过访问 http://127.0.0.1:9997/ui 来使用 UI,访问 http://127.0.0.1:9997/docs 来查看 API 文档。
加载本地llm模型— glm4-9b-chat
配置json文件
使用自定义模型的话,需要准备json格式的模型配置。
以下是配置信息,在“官方文档”的示例的基础上修改的。
json文件的各项参数 都根据glm4文档中对照即可
这里将模型参数截图如下:

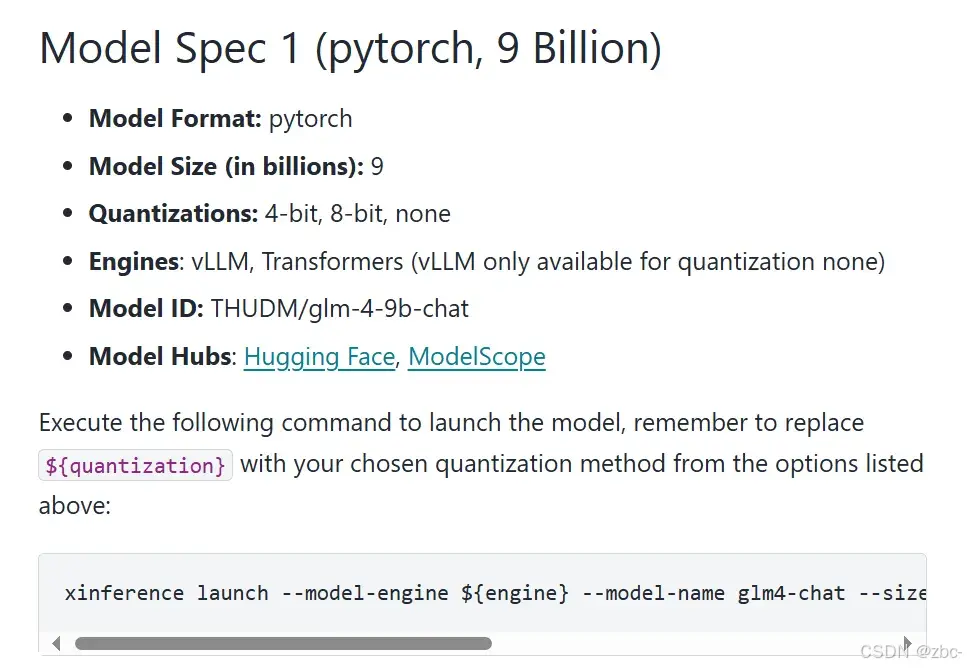
注意:
json文件中的模型名称改写成custom-glm4-chat.
model_uri是当前本地下载的模型的路径,(即cd到模型的路径,然后pwd获取这个路径即可填入)
将该配置文件命名为custom-glm4-chat.json,并放在当前模型路径中。
{
"version": 1,
"context_length": 131072,
"model_name": "custom-glm4-chat",
"model_lang": [
"en",
"zh"
],
"model_ability": [
"chat",
"tools"
],
"model_family": "glm4-chat",
"model_specs": [
{
"model_format": "pytorch",
"model_size_in_billions": 9,
"quantizations": [
"4-bit",
"8-bit",
"none"
],
"model_id": "THUDM/glm-4-9b-chat",
"model_uri": "/home/xidian/zhang-bocheng/glm-4-9b-chat"
}
]
}
注册模型
在当前模型路径下执行命令
xinference register --model-type LLM --file custom-glm4-chat.json --persist
开启模型
推理引擎根据 glm4文档 使用 Transformers
xinference launch --model-name custom-glm4-chat --model-format pytorch --model-engine Transformers
模型加载成功

加载本地embeding模型 — bge-large-zh-v1.5
下载依赖
pip install sentence-transformers
配置json文件

配置json文件的套路和上面一样
更改model_name和model_uri
其他参数参照文档(图片)修改即可
{
"model_name": "custom-bge-large-zh-v1.5",
"dimensions": 1024,
"max_tokens": 512,
"language": ["zh"],
"model_id": "BAAI/bge-large-zh-v1.5",
"model_uri": "/home/xidian/zhang-bocheng/bge-large-zh-v1.5"
}
注册模型
xinference register --model-type embedding --file custom-bge-large-zh-v1.5.json --persist
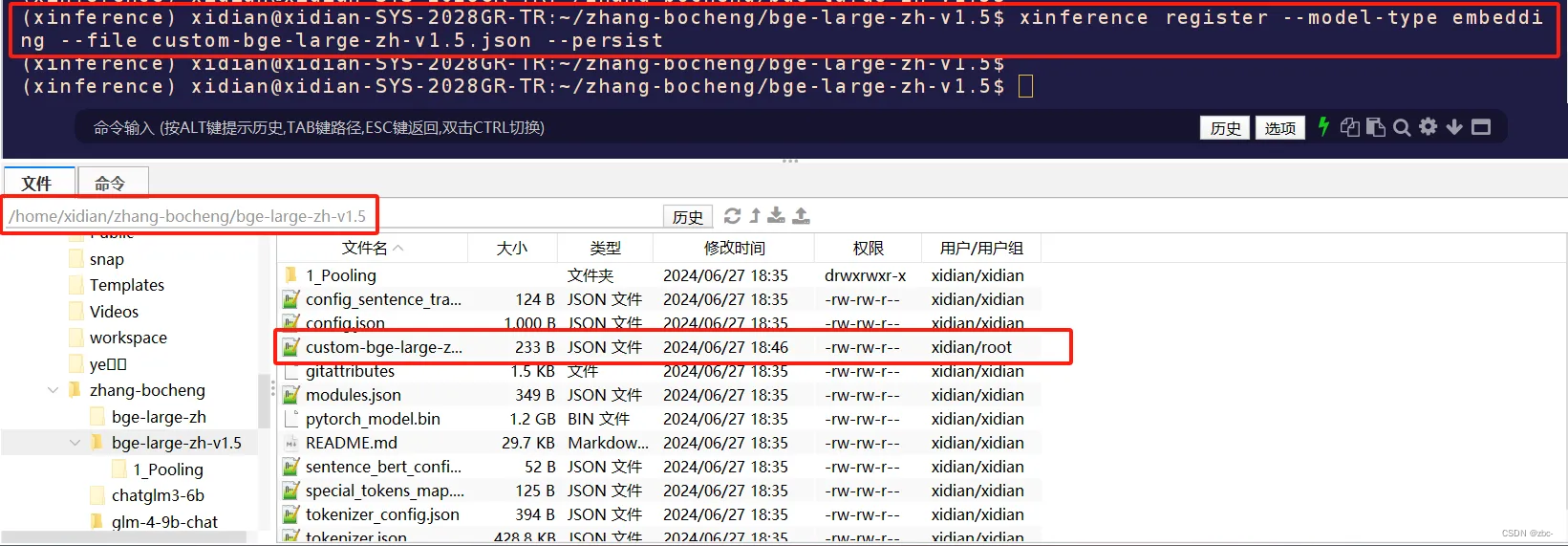
加载模型
xinference launch --model-name custom-bge-large-zh-v1.5 --model-type embedding
模型加载成功




















 6623
6623

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











