






一、概述
1.计算机视觉的定义
计算机视觉(Computer Vision)是一个跨学科的研究领域,主要涉及如何使计算机能够通过处理和理解数字图像或视频来自动进行有意义的分析和决策。其目标是使计算机能够从视觉数据中获取高层次的理解,类似于人类的视觉处理能力。
具体来说,计算机视觉包括以下几个主要任务:
- 图像分类:识别图像中主要的物体或场景。例如,给定一张图片,确定它是猫还是狗。
- 目标检测:在图像中定位和识别多个目标。例如,在街景图像中识别并标注汽车、行人和交通标志的位置。
- 图像分割:将图像分割成不同的区域或对象。例如,将一张医疗影像分割成不同的器官和组织。
- 姿态估计:识别和分析人体或物体的姿态。例如,识别人类骨骼的关键点位置以估计其动作。
- 场景理解:从图像中理解更复杂的场景信息,包括物体之间的关系和背景环境。
- 三维重建:从二维图像中恢复三维结构信息。例如,从多张二维图片生成一个三维模型。
- 动作识别:从视频中识别和分类动作。例如,识别视频中人物是否在走路、跑步或跳舞。
计算机视觉技术在许多领域有广泛的应用,包括但不限于自动驾驶、医疗影像分析、人脸识别、监控系统、增强现实和虚拟现实、机器人技术以及智能制造。
为了实现这些目标,计算机视觉结合了多种技术和方法,包括但不限于图像处理、模式识别、机器学习和深度学习等。近年来,随着深度学习尤其是卷积神经网络(CNN)的发展,计算机视觉技术取得了显著的进展,显著提高了在图像和视频分析任务中的性能。
2.计算机视觉的应用/任务
计算机视觉在许多领域有广泛的应用,涵盖了从日常生活到高科技工业的各个方面。以下是一些主要的应用和任务:
1. 自动驾驶
- 目标检测和识别:识别道路上的车辆、行人、交通标志和其他障碍物。
- 车道检测:检测道路上的车道线,帮助车辆保持在正确的车道内。
- 路径规划:根据周围环境的变化规划行驶路线。
2. 医疗影像分析
- 图像分割:分割医学影像中的不同器官和病变区域,如肿瘤检测。
- 诊断辅助:辅助医生对X光片、CT扫描、MRI影像等进行诊断。
- 手术导航:在手术过程中提供实时的影像指导。
3. 安防监控
- 人脸识别:用于身份验证和监控,识别人脸并匹配数据库中的身份信息。
- 行为分析:检测和分析人群行为,识别潜在的异常或危险行为。
- 入侵检测:检测并报警未授权的进入。
4. 零售和电子商务
- 产品识别:识别商品并进行分类,用于库存管理和推荐系统。
- 虚拟试穿:通过增强现实技术,顾客可以虚拟试穿衣服或配饰。
- 客户分析:通过摄像头分析顾客的行为和购物模式,以优化店铺布局和营销策略。
5. 工业自动化
- 质量检测:检测生产线上产品的缺陷,如裂缝、瑕疵和尺寸偏差。
- 机器人引导:为工业机器人提供视觉导航,执行复杂的组装和操作任务。
- 自动化监控:监控生产过程,检测异常情况并及时报警。
6. 智能家居
- 人脸识别:用于智能门锁、安防系统和用户个性化服务。
- 姿态识别:识别用户的姿态和动作,用于控制家电设备或提供健康监测。
- 环境监测:通过摄像头监测家居环境,检测火灾、烟雾或水泄漏等情况。
7. 文档处理
- 光学字符识别(OCR):将扫描的文档或图片中的文字转换为可编辑的文本。
- 表单识别和处理:自动识别和提取表单中的信息,用于数据录入和管理。
- 手写体识别:识别和转换手写文字为数字文本。
8. 娱乐和媒体
- 视频编辑:自动标记和剪辑视频中的精彩片段,生成视频摘要。
- 特效制作:在电影和电视制作中添加视觉特效和动画。
- 增强现实(AR)和虚拟现实(VR):为游戏和娱乐应用提供沉浸式体验。
9. 农业和环境监测
- 作物监测:通过无人机和卫星图像监测农作物的生长情况和健康状态。
- 害虫检测:识别农作物上的病害和害虫,提供早期预警和防治措施。
- 环境保护:监测森林、河流和海洋的生态环境,检测污染和自然灾害。
这些应用展示了计算机视觉在不同领域的广泛潜力和实际价值。随着技术的不断进步,计算机视觉的应用范围和深度将会进一步扩展。
二、图像处理基本操作
1.图像存储在矩阵中,其中每个元素代表像素值

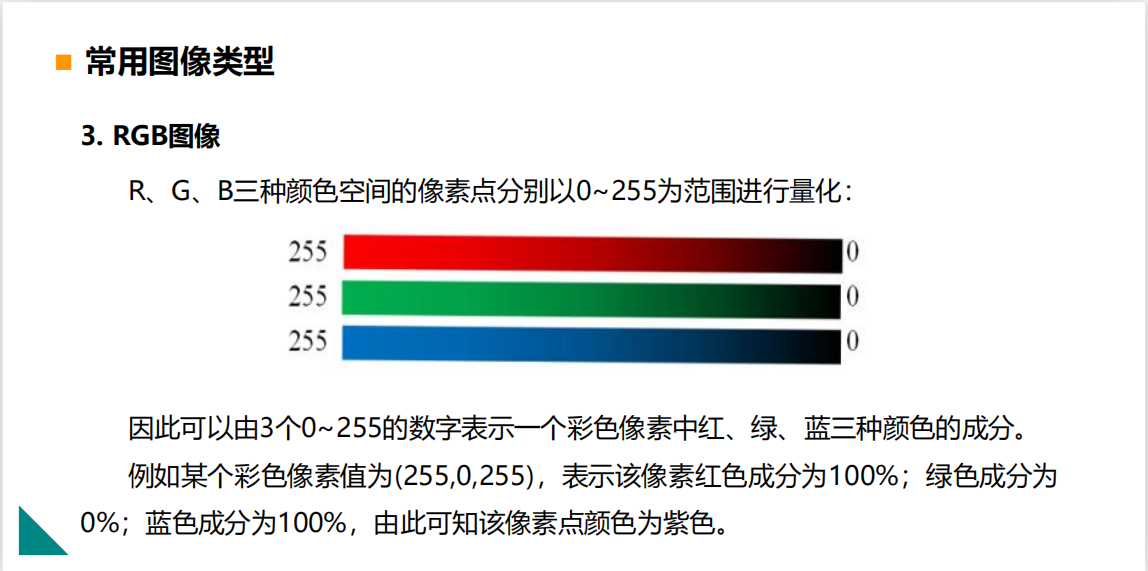
2.图像的表示:二值图像,灰度图,RGB图


灰度图如何量化
灰度图像的量化是指将连续的灰度值(从黑到白的所有中间灰度级别)离散化为有限的灰度级别。这一过程通常涉及以下几个步骤:
1. 原始灰度图像的灰度范围
原始灰度图像的每个像素值通常在一个特定的范围内。例如,对于8位灰度图像,灰度值在0到255之间,其中0表示黑色,255表示白色,介于0和255之间的值表示不同的灰度级别。
2. 确定量化级别
量化级别决定了将灰度值离散化为多少个灰度级。例如,可以选择将灰度值量化为4个、8个、16个等不同数量的级别。假设我们选择将灰度值量化为 ( L ) 个级别。
3. 计算量化间隔
量化间隔(bin size)是将灰度值范围划分为 ( L ) 个级别的间隔。对于一个8位灰度图像,量化间隔计算公式为:
[]
其中 () 是每个量化级别的宽度。
4. 应用量化

5.例子

6.总结
灰度图像量化是将连续的灰度值离散化为有限的灰度级别的过程。通过选择适当的量化级别,可以在减少数据量的同时保留图像的主要视觉信息。量化后的图像在存储、传输和处理上更为高效。
6bit 量化 量化值是多少
将灰度图像量化为6位(6-bit)意味着我们将灰度值分成 ( 2^6 = 64 ) 个量化级别。这意味着原始的8位灰度值(范围从0到255)将被离散化为64个级别。下面是具体的量化过程:
1. 确定量化间隔
对于6位量化,量化级别为64:
2. 计算量化值
每个原始灰度值将被映射到一个新的量化值。量化值可以通过以下公式计算:
其中 ( I ) 是原始灰度值, ( ) 是量化间隔。
量化后的灰度值可以通过以下公式确定:

例子
为了更好地理解这个过程,让我们通过一些具体的灰度值示例来说明:


总结
6位量化将灰度图像分为64个级别,每个级别对应的量化间隔为4。通过将原始灰度值除以量化间隔并取整,然后映射回具体的灰度值,可以得到量化后的灰度图像。这个过程减少了灰度级别,从而简化了图像数据。
3.常见颜色空间
HSV
HSV(Hue, Saturation, Value)是色彩空间的一种,它将颜色表示为色调(Hue)、饱和度(Saturation)和明度(Value)。这种表示方法与人类对颜色的感知更接近,因此在图像处理和计算机视觉中被广泛使用。下面是对HSV色彩空间的详细解释:
1. 色调 (Hue)
- 色调表示颜色的类型,范围通常在0到360度。
- 每个角度对应一种颜色:0度为红色,120度为绿色,240度为蓝色。
- 色调环绕一圈形成一个色环。
2. 饱和度 (Saturation)
- 饱和度表示颜色的纯度或灰度成分的多少。
- 范围从0到1(或0%到100%)。
- 0表示完全没有颜色(灰色),1表示完全纯色。
3. 明度 (Value)
- 明度表示颜色的亮度或强度。
- 范围从0到1(或0%到100%)。
- 0表示最暗(黑色),1表示最亮(白色或最亮的颜色)。
4.优势
- 直观:HSV色彩空间更符合人类对颜色的感知方式。
- 灵活:在进行颜色筛选和调整时,HSV比RGB更方便。
5.应用场景
- 图像分割:通过色调筛选特定颜色。
- 颜色校正:调整饱和度和明度以改善图像质量。
- 增强现实:在实时视频处理中使用色调分割对象。
HSV色彩空间在图像处理和计算机视觉中具有广泛的应用和实用性,尤其适合需要处理和分析颜色的任务。
YUV
YUV是一种颜色表示方法,广泛应用于视频压缩、图像处理和传输中。它将颜色信息分解为亮度(Y)和色度(U和V)分量。与RGB色彩空间不同,YUV分离了图像的亮度和色度信息,便于在图像处理和视频压缩中进行高效处理。
1. 分量介绍
- Y(Luminance):亮度分量,表示图像的明暗程度。这个分量包含了图像的灰度信息。
- U(Chrominance - Blue Projection):色度分量之一,表示蓝色的投影。
- V(Chrominance - Red Projection):色度分量之一,表示红色的投影。
2. 优势
- 分离亮度和色度:YUV分离了亮度和色度信息,使得在视频压缩和传输中可以优先保留更多的亮度信息,而降低色度信息的精度,从而减少数据量。
- 兼容性:YUV色彩空间与黑白电视信号兼容,确保在彩色电视上播放时可以兼容黑白电视。
3. 应用场景
- 视频压缩:许多视频压缩标准(如MPEG、H.264)都使用YUV色彩空间,因为它能更好地压缩视频数据。
- 图像处理:在图像处理中,可以独立处理亮度和色度分量,提高处理效率和效果。
- 电视广播:YUV色彩空间在模拟和数字电视广播中被广泛使用。
4.总结
YUV色彩空间通过将颜色分解为亮度和色度分量,提供了一种高效的颜色表示方法。它在视频压缩、图像处理和传输中具有广泛的应用,尤其适用于需要处理和优化亮度和色度信息的场景。
4.图像平滑:均值滤波、中值滤波、低通滤波(允许低频分量通过,高平分量滤除)
图像平滑是一种区域增强的算法,主要目的是通过减少图像中的高频噪声来改善图像的质量。能够减少甚至消除噪声并保持高频边缘信息是图像平滑算法追求的目标。

均值滤波(Mean Filtering)
均值滤波(Mean Filtering),也称为平均滤波,是一种简单且常用的图像平滑技术,用于减少图像中的噪声。其基本思想是通过用局部邻域内像素的平均值替换中心像素值来达到平滑效果。这种方法在平滑图像的同时,可以有效地保留图像的主要特征。
1. 基本原理

2.数学表示

3. Python 示例
使用Python和OpenCV实现均值滤波:
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 读取灰度图像
image = cv2.imread('image.jpg', cv2.IMREAD_GRAYSCALE)
# 应用均值滤波
kernel_size = 5
filtered_image = cv2.blur(image, (kernel_size, kernel_size))
# 显示原始图像和均值滤波后的图像
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.title('Original Image')
plt.imshow(image, cmap='gray')
plt.axis('off')
plt.subplot(1, 2, 2)
plt.title(f'Mean Filtered Image (Kernel Size: {kernel_size}x{kernel_size})')
plt.imshow(filtered_image, cmap='gray')
plt.axis('off')
plt.show()4. 优点和缺点
优点:
- 简单易实现:均值滤波算法简单,计算开销低。
- 平滑效果好:能够有效地去除图像中的高频噪声。
缺点:
- 模糊边缘:由于计算均值时考虑了周围所有像素,图像的边缘和细节部分可能会被模糊。
- 不适用于脉冲噪声:对于含有脉冲噪声的图像,均值滤波可能无法有效去噪,反而可能扩散噪声。
5. 应用场景
- 噪声去除:均值滤波广泛用于图像预处理,去除随机噪声。
- 图像平滑:在图像处理中,均值滤波常用于平滑图像,以减少图像中的细节或进行图像分割前的预处理。
均值滤波作为一种基础的图像处理技术,在图像预处理和噪声去除中具有广泛的应用。然而,对于某些应用场景,如边缘保留和去除脉冲噪声,可能需要使用更高级的滤波技术,如中值滤波或双边滤波。

中值滤波(Median Filtering)
中值滤波(Median Filtering)是一种常用的非线性滤波技术,用于去除图像中的噪声,同时保留图像的边缘信息。它在处理椒盐噪声(salt-and-pepper noise)方面特别有效。中值滤波的基本思想是用邻域内像素值的中值替换中心像素值,从而减少噪声的影响。
1. 基本原理

3. Python 示例
使用Python和OpenCV实现中值滤波:
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 读取灰度图像
image = cv2.imread('image.jpg', cv2.IMREAD_GRAYSCALE)
# 应用中值滤波
kernel_size = 5
filtered_image = cv2.medianBlur(image, kernel_size)
# 显示原始图像和中值滤波后的图像
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.title('Original Image')
plt.imshow(image, cmap='gray')
plt.axis('off')
plt.subplot(1, 2, 2)
plt.title(f'Median Filtered Image (Kernel Size: {kernel_size}x{kernel_size})')
plt.imshow(filtered_image, cmap='gray')
plt.axis('off')
plt.show()4. 优点和缺点
优点:
- 保留边缘:中值滤波在去噪的同时,能够很好地保留图像的边缘信息。
- 有效去除脉冲噪声:特别适用于去除椒盐噪声和其他类似的脉冲噪声。
缺点:
- 计算复杂度较高:由于需要对窗口内的像素进行排序,中值滤波的计算复杂度高于均值滤波。
- 不适用于高斯噪声:对于高斯噪声,中值滤波的效果可能不如高斯滤波。
5. 应用场景
- 噪声去除:中值滤波广泛用于去除图像中的椒盐噪声和其他类似的脉冲噪声。
- 图像预处理:在图像分割、边缘检测等图像处理任务中,中值滤波常用于平滑图像,同时保留重要的边缘信息。
中值滤波作为一种非线性滤波技术,在去除脉冲噪声和保留边缘信息方面具有显著优势。虽然计算复杂度较高,但在许多实际应用中,中值滤波仍然是非常有效的选择。

低通滤波器(Low-Pass Filter)
低通滤波器(Low-Pass Filter)是一种允许低频信号通过并阻止高频信号的滤波器。它在图像处理中的主要作用是平滑图像,减少图像中的高频噪声,同时保留图像中的低频信息。低通滤波器在边缘检测、图像降噪和图像重采样等领域中有广泛的应用。
1. 低通滤波的基本原理
在图像处理中,低通滤波的基本思想是将图像的高频成分(如噪声、细节等)进行衰减,而保留图像的低频成分(如整体的光滑区域)。这可以通过空间域或频域来实现。
空间域中的低通滤波
在空间域中,低通滤波通常通过卷积操作实现,常用的低通滤波器包括均值滤波器和高斯滤波器。
- 均值滤波器(Mean Filter):使用邻域内像素的平均值替代中心像素值。
- 高斯滤波器(Gaussian Filter):使用加权平均值替代中心像素值,其中权重由高斯分布决定。

频域中的低通滤波

2. 数学表示

3. Python 示例
以下是使用Python和OpenCV实现低通滤波的示例:
使用均值滤波器(空间域)
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 读取图像
image = cv2.imread('image.jpg', cv2.IMREAD_GRAYSCALE)
# 应用均值滤波
kernel_size = 5
mean_filtered_image = cv2.blur(image, (kernel_size, kernel_size))
# 显示原始图像和均值滤波后的图像
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.title('Original Image')
plt.imshow(image, cmap='gray')
plt.axis('off')
plt.subplot(1, 2, 2)
plt.title(f'Mean Filtered Image (Kernel Size: {kernel_size}x{kernel_size})')
plt.imshow(mean_filtered_image, cmap='gray')
plt.axis('off')
plt.show()使用高斯滤波器(空间域)
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 读取图像
image = cv2.imread('image.jpg', cv2.IMREAD_GRAYSCALE)
# 应用高斯滤波
kernel_size = 5
sigma = 1.0
gaussian_filtered_image = cv2.GaussianBlur(image, (kernel_size, kernel_size), sigma)
# 显示原始图像和高斯滤波后的图像
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.title('Original Image')
plt.imshow(image, cmap='gray')
plt.axis('off')
plt.subplot(1, 2, 2)
plt.title(f'Gaussian Filtered Image (Kernel Size: {kernel_size}x{kernel_size}, Sigma: {sigma})')
plt.imshow(gaussian_filtered_image, cmap='gray')
plt.axis('off')
plt.show()使用低通滤波器(频域)
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 读取图像
image = cv2.imread('image.jpg', cv2.IMREAD_GRAYSCALE)
# 进行傅里叶变换
dft = cv2.dft(np.float32(image), flags=cv2.DFT_COMPLEX_OUTPUT)
dft_shift = np.fft.fftshift(dft)
# 创建低通滤波器
rows, cols = image.shape
crow, ccol = rows // 2 , cols // 2
mask = np.zeros((rows, cols, 2), np.uint8)
r = 30 # 低通滤波器的半径
center = [crow, ccol]
x, y = np.ogrid[:rows, :cols]
mask_area = (x - center[0])**2 + (y - center[1])**2 <= r*r
mask[mask_area] = 1
# 应用滤波器并进行逆傅里叶变换
fshift = dft_shift * mask
f_ishift = np.fft.ifftshift(fshift)
img_back = cv2.idft(f_ishift)
img_back = cv2.magnitude(img_back[:, :, 0], img_back[:, :, 1])
# 显示原始图像和低通滤波后的图像
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.title('Original Image')
plt.imshow(image, cmap='gray')
plt.axis('off')
plt.subplot(1, 2, 2)
plt.title('Low-Pass Filtered Image (Frequency Domain)')
plt.imshow(img_back, cmap='gray')
plt.axis('off')
plt.show()4. 优点和缺点
优点:
- 减少噪声:有效去除图像中的高频噪声。
- 平滑图像:使图像变得更加平滑,适合在图像分割和特征提取之前使用。
缺点:
- 模糊细节:会模糊图像中的细节和边缘。
- 不适用于所有噪声类型:对于某些类型的噪声(如低频噪声),效果不佳。
5. 应用场景
- 图像降噪:在去除图像中的随机噪声时使用。
- 图像平滑:在图像分割、边缘检测等处理之前对图像进行平滑处理。
- 信号处理:在音频和通信信号处理中,用于滤除高频干扰信号。
低通滤波器作为一种基本的图像处理工具,在去除噪声和平滑图像方面具有广泛的应用。然而,在使用时需要注意它可能带来的图像模糊问题,并根据具体应用选择合适的滤波器和参数。
5.图像锐化:高通滤波(加强图像的边缘)
高通是图像锐化 低通图像平滑
• 在图像的判读或识别中常需要突出边缘和轮廓信息,而图像锐化处理的目的是加
强图像中景物的边缘和轮廓,使模糊图像变得更清晰。
• 图像模糊的可能是因为图像受到平均或积分运算,因此对图像采用逆运算。例
如对连续图像微分或对离散图像差分运算,即可使模糊图像的质量得到改善。
• 从频率域角度看,图像的模糊是因为高频分量受到衰减,所以采用合适的高通
滤波器也可以使图像的清晰度增加
三、图形去噪/边缘检测/深度学习基础
1.常见图像噪声:高斯噪声、椒盐噪声、脉冲噪声
噪声的特点是什么
噪声在图像处理和信号处理中是一个常见的概念,它具有几个基本特点,包括以下几点:
1.随机性(随机分布):
- 噪声是在信号或图像中无规律地出现的不希望的信号成分。它通常由于环境、传感器本身的限制、传输过程中的干扰等因素引入。
- 噪声的分布通常是随机的,没有明显的可预测模式,如白噪声和高斯噪声。
2.无用信息(非信息性):
- 噪声是与所需信号或图像信息无关的信号成分,它不包含任何有用的信息,通常会干扰或模糊真实数据的内容。
3. 影响信号质量:
- 噪声会降低信号或图像的质量,使得原始信息变得不清晰或难以识别。
- 在图像中,噪声可能表现为像素的随机变化,使图像看起来粗糙或不连续。
4. 多样性:
- 噪声可以有多种形式和来源,如椒盐噪声(随机黑白像素)、高斯噪声(服从高斯分布的随机变化)等。
- 每种类型的噪声可能需要不同的处理方法来有效降低其对信号或图像的影响。
5.波动性:
- 噪声的强度和分布通常会随着时间或空间的变化而波动,这使得在处理中需要考虑噪声的动态特性。
在图像处理中,理解噪声的特点对于选择合适的去噪方法和优化处理步骤至关重要。不同类型的噪声可能需要不同的处理策略,以在保留尽可能多有用信息的同时有效降低噪声水平。

常见图像噪声:
• 椒盐噪声:黑色像素和白色像素随机出现,椒盐噪声也称为脉冲噪声
• 脉冲噪声:白色像素随机出现
• 高斯噪声:噪声强度变化服从高斯分布
2.图像去噪流程,如高斯噪声(高斯平滑),椒盐噪声(中值滤波)(综合题)
(1)高斯噪声
高斯噪声(Gaussian Noise)是图像处理和信号处理中的常见问题,去除高斯噪声的过程称为去噪。以下是一个标准的高斯噪声去噪流程:
1. 图像预处理
在进行去噪之前,首先需要对图像进行预处理。这可能包括:
- 灰度化:如果图像是彩色的,可以先将其转换为灰度图像。
- 归一化:将像素值归一化到0-1范围内,以便后续处理。
2. 选择去噪方法
去除高斯噪声的方法有很多种,常用的包括:




3. 应用去噪方法
根据选择的去噪方法,对图像进行处理。一般步骤包括:
- 构建滤波器:根据选择的滤波器构建滤波器核或函数。
- 应用滤波器:将滤波器应用到图像上,得到去噪后的图像。
4. 后处理
去噪后,可以进行一些后处理来提高图像质量:
- 对比度调整:调整图像的对比度,使得细节更明显。
- 锐化处理:增强图像的边缘和细节。
5. 评价去噪效果
通过一些评价指标来判断去噪效果,例如:
- 峰值信噪比(PSNR):评估去噪后图像的质量。
- 结构相似性(SSIM):评估去噪后图像与原图像的相似性。
示例代码
以下是一个简单的Python代码示例,使用OpenCV进行高斯噪声的去噪:
import cv2
import numpy as np
# 读取图像
image = cv2.imread('noisy_image.jpg', cv2.IMREAD_GRAYSCALE)
# 高斯滤波去噪
denoised_image = cv2.GaussianBlur(image, (5, 5), 1.5)
# 显示结果
cv2.imshow('Original Image', image)
cv2.imshow('Denoised Image', denoised_image)
cv2.waitKey(0)
cv2.destroyAllWindows()通过以上步骤和代码,可以实现高斯噪声的有效去除,从而提高图像的质量。不同的方法适用于不同的场景,需要根据实际情况选择合适的去噪方法。
(2)椒盐噪声
椒盐噪声(Salt-and-Pepper Noise)是一种常见的图像噪声,表现为图像中出现随机的黑白像素点。去除椒盐噪声的过程可以通过多种方法实现。以下是一个详细的椒盐噪声去噪流程:
1. 图像预处理
在进行去噪之前,首先需要对图像进行预处理,这可能包括:
- 灰度化:如果图像是彩色的,可以先将其转换为灰度图像。
- 归一化:将像素值归一化到0-1范围内,以便后续处理。
2. 选择去噪方法
去除椒盐噪声的方法有多种,常用的包括:




3. 应用去噪方法
根据选择的去噪方法,对图像进行处理。一般步骤包括:
- 构建滤波器:根据选择的滤波器构建滤波器核或函数。
- 应用滤波器:将滤波器应用到图像上,得到去噪后的图像。
4. 后处理
去噪后,可以进行一些后处理来提高图像质量:
- 对比度调整:调整图像的对比度,使得细节更明显。
- 锐化处理:增强图像的边缘和细节。
5. 评价去噪效果
通过一些评价指标来判断去噪效果,例如:
- 峰值信噪比(PSNR):评估去噪后图像的质量。
- 结构相似性(SSIM):评估去噪后图像与原图像的相似性。
示例代码
以下是一个简单的Python代码示例,使用OpenCV进行椒盐噪声的去噪:
import cv2
import numpy as np
# 读取图像
image = cv2.imread('noisy_image.jpg', cv2.IMREAD_GRAYSCALE)
# 添加椒盐噪声
def add_salt_and_pepper_noise(image, prob):
noisy = np.copy(image)
num_salt = np.ceil(prob * image.size * 0.5)
num_pepper = np.ceil(prob * image.size * 0.5)
# 添加盐噪声
coords = [np.random.randint(0, i - 1, int(num_salt)) for i in image.shape]
noisy[coords[0], coords[1]] = 1
# 添加胡椒噪声
coords = [np.random.randint(0, i - 1, int(num_pepper)) for i in image.shape]
noisy[coords[0], coords[1]] = 0
return noisy
noisy_image = add_salt_and_pepper_noise(image, 0.05)
# 中值滤波去噪
denoised_image = cv2.medianBlur(noisy_image, 3)
# 显示结果
cv2.imshow('Original Image', image)
cv2.imshow('Noisy Image', noisy_image)
cv2.imshow('Denoised Image', denoised_image)
cv2.waitKey(0)
cv2.destroyAllWindows()通过以上步骤和代码,可以有效地去除椒盐噪声,从而提高图像的质量。不同的方法适用于不同的场景,需要根据实际情况选择合适的去噪方法。
3.边缘检测流程,如canny边缘检测(综合题)
边缘检测是图像处理中的一种重要技术,用于识别图像中的边缘。边缘是图像中灰度变化显著的区域,通常对应物体的边界。以下是一个标准的边缘检测步骤:
1. 图像预处理
在进行边缘检测之前,通常需要对图像进行预处理。这些预处理步骤可能包括:
- 灰度化:将彩色图像转换为灰度图像,以简化处理。
- 平滑处理:使用高斯滤波等方法对图像进行平滑处理,减少噪声对边缘检测的影响。
import cv2
# 读取彩色图像
image = cv2.imread('image.jpg')
# 转换为灰度图像
gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 使用高斯滤波进行平滑处理
blurred_image = cv2.GaussianBlur(gray_image, (5, 5), 1.5)2. 计算梯度
计算图像的梯度以获取边缘信息。常用的方法有Sobel算子、Prewitt算子和Roberts算子等。梯度算子会计算图像在x和y方向的导数。
# 使用Sobel算子计算梯度
grad_x = cv2.Sobel(blurred_image, cv2.CV_64F, 1, 0, ksize=3)
grad_y = cv2.Sobel(blurred_image, cv2.CV_64F, 0, 1, ksize=3)
# 计算梯度幅值和方向
magnitude = cv2.magnitude(grad_x, grad_y)
angle = cv2.phase(grad_x, grad_y, angleInDegrees=True)3. 非极大值抑制
非极大值抑制用于细化边缘,通过保留局部最大值并抑制其他值,使得边缘更加清晰。
def non_maximum_suppression(magnitude, angle):
row, col = magnitude.shape
suppressed = np.zeros((row, col), dtype=np.float32)
angle = angle % 180
for i in range(1, row-1):
for j in range(1, col-1):
q = 255
r = 255
# 根据梯度方向选择比较的像素
if (0 <= angle[i, j] < 22.5) or (157.5 <= angle[i, j] <= 180):
q = magnitude[i, j+1]
r = magnitude[i, j-1]
elif 22.5 <= angle[i, j] < 67.5:
q = magnitude[i+1, j-1]
r = magnitude[i-1, j+1]
elif 67.5 <= angle[i, j] < 112.5:
q = magnitude[i+1, j]
r = magnitude[i-1, j]
elif 112.5 <= angle[i, j] < 157.5:
q = magnitude[i-1, j-1]
r = magnitude[i+1, j+1]
# 保留局部最大值
if (magnitude[i, j] >= q) and (magnitude[i, j] >= r):
suppressed[i, j] = magnitude[i, j]
else:
suppressed[i, j] = 0
return suppressed
suppressed_image = non_maximum_suppression(magnitude, angle)4. 双阈值处理
双阈值处理用于进一步筛选边缘,通过设置高阈值和低阈值,将边缘分为强边缘、弱边缘和非边缘。
# 设置高阈值和低阈值
high_threshold = suppressed_image.max() * 0.09
low_threshold = high_threshold * 0.5
# 应用双阈值
strong_edges = (suppressed_image > high_threshold)
weak_edges = ((suppressed_image >= low_threshold) & (suppressed_image <= high_threshold))
# 初始化输出图像
edges = np.zeros_like(suppressed_image)
edges[strong_edges] = 255
edges[weak_edges] = 755. 边缘连接
连接弱边缘和强边缘,确保弱边缘连接到强边缘才被保留。
def edge_tracking(edges, weak=75, strong=255):
row, col = edges.shape
for i in range(1, row-1):
for j in range(1, col-1):
if edges[i, j] == weak:
# 检查8邻域是否有强边缘
if ((edges[i+1, j-1] == strong) or (edges[i+1, j] == strong) or (edges[i+1, j+1] == strong)
or (edges[i, j-1] == strong) or (edges[i, j+1] == strong)
or (edges[i-1, j-1] == strong) or (edges[i-1, j] == strong) or (edges[i-1, j+1] == strong)):
edges[i, j] = strong
else:
edges[i, j] = 0
return edges
final_edges = edge_tracking(edges)6. 显示结果
显示原始图像和处理后的边缘检测结果。
cv2.imshow('Original Image', image)
cv2.imshow('Edges', final_edges)
cv2.waitKey(0)
cv2.destroyAllWindows()通过上述步骤,可以有效地进行边缘检测。常用的边缘检测算法包括Canny边缘检测、Sobel边缘检测和Laplacian边缘检测,其中Canny边缘检测结合了上述多个步骤,效果较好。
Canny
Canny边缘检测是一种广泛使用的边缘检测算法,旨在提取图像中的边缘特征。其主要步骤如下:
- 高斯滤波 (Gaussian Filtering):

- 计算梯度 (Gradient Calculation):
使用Sobel算子计算图像的梯度强度和方向。Sobel算子分别在水平方向(Gx)和垂直方向(Gy)上计算梯度。
- 非极大值抑制 (Non-maximum Suppression):
在梯度方向上对梯度强度进行抑制,只保留局部最大值,以细化边缘,使边界更清晰。具体步骤包括:
-
- 对每个像素,沿梯度方向检查两个相邻像素的梯度强度。
- 如果当前像素的梯度强度大于相邻像素的梯度强度,则保留,否则抑制为0。
- 双阈值检测 (Double Thresholding):
使用两个阈值(低阈值和高阈值)进一步过滤边缘。
-
- 如果像素的梯度强度大于高阈值,则被认为是强边缘。
- 如果像素的梯度强度介于低阈值和高阈值之间,则被认为是弱边缘。
- 如果像素的梯度强度小于低阈值,则被抑制为非边缘。
- 边缘连接 (Edge Tracking by Hysteresis):
通过连接弱边缘和强边缘来形成最终的边缘。
-
- 从强边缘像素开始,沿着梯度方向搜索弱边缘,如果连接到强边缘,则将弱边缘视为真实边缘。
总结来说,Canny边缘检测算法通过这五个步骤实现了对图像边缘的准确检测,减少了噪声的影响,精确地定位边缘,并通过双阈值和边缘连接步骤保证了边缘检测的连贯性。
4.全连接神经网络结构:输入层、隐藏层、输出层
全联接网络的输出层什么的。设计一下手写字,激活函数选择 结构图画出
全连接神经网络(Fully Connected Neural Network, FCNN)是一种基础的神经网络结构,由输入层、隐藏层和输出层组成。每一层中的神经元与前一层的所有神经元相连接。以下是各个层的详细介绍:
1. 输入层(Input Layer)
输入层是神经网络的第一层,它接受外部数据并将其传递给网络的下一层。输入层的神经元数量取决于输入数据的特征数量。例如,如果输入的是一个28x28像素的灰度图像,输入层将有784个神经元(28x28=784)。
2. 隐藏层(Hidden Layers)
隐藏层位于输入层和输出层之间,可以有一个或多个隐藏层。每一层中的神经元通过权重与前一层的所有神经元相连接。隐藏层的作用是通过激活函数引入非线性,使网络能够学习和表示复杂的模式和特征。
a. 权重和偏置(Weights and Biases)
每个连接都有一个权重,用于调整输入信号的强度。每个神经元还有一个偏置,用于调整激活函数的输出。
b. 激活函数(Activation Function)
每个隐藏层的神经元通常使用非线性激活函数,如ReLU、Sigmoid、Tanh等,以引入非线性并使网络能够学习复杂的特征。
3. 输出层(Output Layer)
输出层是神经网络的最后一层,它将隐藏层的输出转换为网络的最终输出。输出层的神经元数量取决于具体任务。例如,对于二分类问题,输出层通常有一个神经元,输出一个表示类别概率的值。对于多分类问题,输出层的神经元数量等于类别数量,通常使用Softmax激活函数来输出每个类别的概率。
4.神经网络的工作流程
- 前向传播(Forward Propagation):输入数据经过输入层传递到隐藏层,经过激活函数处理后传递到下一层,最终传递到输出层,得到预测结果。
- 损失计算(Loss Calculation):通过损失函数计算预测结果与真实标签之间的误差。
- 反向传播(Backward Propagation):根据损失计算结果,使用梯度下降法调整权重和偏置,以减少误差。
- 迭代训练(Iterative Training):重复前向传播和反向传播的过程,直到损失函数收敛或达到预定的训练次数。
5.示例代码
以下是一个简单的Python代码示例,使用Keras构建和训练一个全连接神经网络,用于MNIST手写数字识别:
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten
from tensorflow.keras.datasets import mnist
from tensorflow.keras.utils import to_categorical
# 加载MNIST数据集
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
# 预处理数据
train_images = train_images.reshape((60000, 28 * 28)).astype('float32') / 255
test_images = test_images.reshape((10000, 28 * 28)).astype('float32') / 255
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)
# 构建全连接神经网络模型
model = Sequential([
Flatten(input_shape=(28, 28)), # 输入层
Dense(512, activation='relu'), # 隐藏层1
Dense(256, activation='relu'), # 隐藏层2
Dense(10, activation='softmax') # 输出层
])
# 编译模型
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
# 训练模型
model.fit(train_images, train_labels, epochs=5, batch_size=128, validation_split=0.2)
# 评估模型
test_loss, test_acc = model.evaluate(test_images, test_labels)
print(f"Test accuracy: {test_acc}")6.解释
- Flatten层:将28x28的输入图像展开为784维的向量。
- Dense层:全连接层,分别有512个、256个和10个神经元。前两层使用ReLU激活函数,最后一层使用Softmax激活函数。
- 编译和训练:使用Adam优化器和交叉熵损失函数进行编译,并用训练数据进行训练。
- 评估模型:在测试数据上评估模型的性能。
通过上述结构和步骤,全连接神经网络能够处理并识别复杂的数据模式,用于各种分类、回归和预测任务。
在神经网络中,引入非线性激活函数是至关重要的,原因主要包括以下几个方面:
1. 引入非线性
线性模型的输出是输入的线性组合。如果没有非线性激活函数,无论网络多深,每一层的输出仍然是输入的线性组合。因此,网络的表现能力受到极大限制。引入非线性激活函数后,网络可以拟合复杂的非线性函数,从而提高模型的表达能力和拟合能力。
2. 多层感知机的计算能力
多层感知机(MLP)需要非线性激活函数来成为通用函数近似器(universal approximator)。理论上证明,只要有足够的隐藏单元和非线性激活函数,MLP可以逼近任何连续函数。这是由“通用近似定理”证明的。
3. 增强模型的复杂性
激活函数引入非线性,使得神经网络可以处理复杂的模式和特征。例如,图像中的边缘、纹理等复杂特征,以及自然语言处理中的语义关系等。这些特征通常不能通过简单的线性变换来表示。
4. 实现数据分布的非线性分离
对于分类问题,输入数据往往是非线性分布的。通过引入非线性激活函数,神经网络能够将输入数据投影到高维空间中,使得线性不可分的数据在高维空间中变得线性可分,从而提高分类性能。
常见的非线性激活函数
以下是一些常见的非线性激活函数及其特点:
1. Sigmoid函数
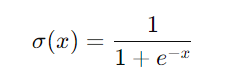
- 优点:将输入压缩到0到1之间,有效地将输入映射到固定范围。
- 缺点:容易导致梯度消失问题,尤其是在深层网络中。
2. Tanh函数
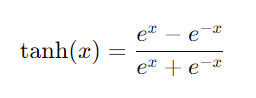
- 优点:将输入压缩到-1到1之间,相较于Sigmoid函数,输出的均值接近0,收敛速度较快。
- 缺点:也容易导致梯度消失问题。
3. ReLU(Rectified Linear Unit)
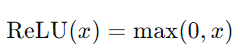
- 优点:计算简单,高效,不容易出现梯度消失问题。
- 缺点:可能导致“神经元死亡”,即一些神经元输出恒为0。
4. Leaky ReLU
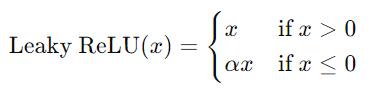
- 优点:避免了ReLU的神经元死亡问题,允许小的负梯度通过。
- 缺点:需要额外调节参数(\alpha)。
5. ELU(Exponential Linear Unit)
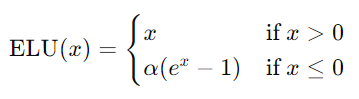
- 优点:负值部分有较好的梯度传递效果,减少神经元死亡问题。
- 缺点:计算相对复杂,需要调节参数(\alpha)。
通过以上激活函数的非线性转换,神经网络可以更好地拟合复杂的数据模式,解决各种复杂的实际问题。
5.设计手写数字分类的全连接神经网络和卷积神经网络,画出结构图、激活函数等(综合题)
设计手写数字分类的全连接神经网络
以下是一个手写数字分类全连接神经网络的设计,基于MNIST数据集。这个神经网络包含输入层、两个隐藏层和一个输出层。
1. 网络结构
- 输入层(Input Layer):接收28x28的灰度图像,共784个神经元。
- 隐藏层1(Hidden Layer 1):包含512个神经元,使用ReLU激活函数。
- 隐藏层2(Hidden Layer 2):包含256个神经元,使用ReLU激活函数。
- 输出层(Output Layer):包含10个神经元,使用Softmax激活函数,用于分类10种手写数字(0-9)。
2. 结构图
Input Layer (784 neurons)
|
V
Hidden Layer 1 (512 neurons, ReLU)
|
V
Hidden Layer 2 (256 neurons, ReLU)
|
V
Output Layer (10 neurons, Softmax)3. 激活函数

设计一个用于手写数字分类的全连接神经网络,具体步骤如下:
1.网络结构设计
- 输入层:28x28=784个节点(因为MNIST数据集中的图片是28x28像素)
- 隐藏层1:128个节点,激活函数ReLU
- 隐藏层2:64个节点,激活函数ReLU
- 输出层:10个节点(对应0到9共10个数字),激活函数Softmax(用于多分类)
2.绘制网络结构图
Input Layer (784 nodes)
|
Hidden Layer 1 (128 nodes, ReLU)
|
Hidden Layer 2 (64 nodes, ReLU)
|
Output Layer (10 nodes, Softmax)3.激活函数
4.PyTorch实现代码
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
# 定义全连接神经网络
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(28*28, 128) # 输入层到隐藏层1
self.fc2 = nn.Linear(128, 64) # 隐藏层1到隐藏层2
self.fc3 = nn.Linear(64, 10) # 隐藏层2到输出层
def forward(self, x):
x = x.view(-1, 28*28) # 展平图像
x = torch.relu(self.fc1(x)) # 隐藏层1 + ReLU激活函数
x = torch.relu(self.fc2(x)) # 隐藏层2 + ReLU激活函数
x = self.fc3(x) # 输出层
return torch.softmax(x, dim=1) # Softmax激活函数
# 超参数
batch_size = 64
learning_rate = 0.001
num_epochs = 10
# 数据预处理
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
# 下载并加载MNIST数据集
trainset = torchvision.datasets.MNIST(root='./data', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=batch_size, shuffle=True)
testset = torchvision.datasets.MNIST(root='./data', train=False, download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=batch_size, shuffle=False)
# 初始化网络和优化器
net = Net()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=learning_rate)
# 训练网络
for epoch in range(num_epochs):
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 100 == 99: # 每100个mini-batch输出一次
print(f'[Epoch {epoch + 1}, Mini-batch {i + 1}] loss: {running_loss / 100:.3f}')
running_loss = 0.0
print('Finished Training')
# 测试网络
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f'Accuracy of the network on the 10000 test images: {100 * correct / total} %')4.解释代码
1.网络定义:创建一个包含两个隐藏层和一个输出层的全连接神经网络,并在每个隐藏层使用ReLU激活函数,在输出层使用Softmax激活函数。
2.数据预处理:使用torchvision.transforms对MNIST数据集进行预处理,标准化数据并加载训练和测试数据集。
3.训练网络:通过迭代训练数据集,计算损失并使用Adam优化器更新网络权重。
4.测试网络:在测试数据集上评估训练好的模型,计算其分类准确率。
这个网络的结构和代码实现对于手写数字分类任务非常合适,可以作为入门的深度学习示例。
设计手写数字分类的卷积神经网络,画出结构图、激活函数等
好的,我将设计一个简单的卷积神经网络(CNN)用于手写数字分类(MNIST数据集),并画出结构图及激活函数的部分。
1.卷积神经网络结构简单介绍
我们将设计一个经典的卷积神经网络结构,适用于处理28x28像素(32x32像素)的手写数字图像,输出为10个类别(0到9)。
神经网络结构图
Input (28x28x1) -> Conv1 (32 filters of 3x3) -> ReLU -> MaxPool1 (2x2) ->
Conv2 (64 filters of 3x3) -> ReLU -> MaxPool2 (2x2) ->
Flatten -> FC1 (128) -> ReLU -> FC2 (10) -> Softmax- Input层: 输入为28x28像素(32x32像素)的单通道灰度图像(1表示单通道)。
- Conv1层: 第一个卷积层,包含32个3x3大小的滤波器(filters),使用ReLU激活函数。
- MaxPool1层: 第一个最大池化层,使用2x2的窗口进行池化操作,减小特征图的空间大小。
- Conv2层: 第二个卷积层,包含64个3x3大小的滤波器,使用ReLU激活函数。
- MaxPool2层: 第二个最大池化层,同样使用2x2的窗口进行池化操作。
- Flatten层: 将卷积层输出的特征图展平为向量,为全连接层做准备。
- FC1层: 全连接层,包含128个神经元,使用ReLU激活函数。
- FC2层: 输出层,包含10个神经元,使用Softmax激活函数进行多类别分类。
2.激活函数
在上述结构中,使用了ReLU作为卷积层和全连接层的激活函数,Softmax作为输出层的激活函数。ReLU激活函数有助于引入非线性,并能有效地减少梯度消失问题,而Softmax则适用于多类别分类任务,将网络输出转换为概率分布。
这是一个简单但有效的卷积神经网络结构,适用于手写数字分类任务。
当设计卷积神经网络(CNN)用于手写数字分类时,我们需要考虑网络的层次结构、激活函数以及每一层的作用。下面我会详细说明每一层的功能和结构,并画出网络的结构图。
3.卷积神经网络结构详解(28输入为x28)
神经网络结构图
Input (28x28x1)
|
|-- Conv1 (32 filters of 3x3)
| |
| |-- ReLU
|
|-- MaxPool1 (2x2)
|
|-- Conv2 (64 filters of 3x3)
| |
| |-- ReLU
|
|-- MaxPool2 (2x2)
|
|-- Flatten
|
|-- FC1 (128)
| |
| |-- ReLU
|
|-- FC2 (10)
|
|-- Softmax层次结构和功能说明
1.Input层:
- 输入图像尺寸为28x28像素,单通道(灰度图像),因此输入的维度为28x28x1。
2.Conv1层:
- 卷积层包含32个3x3大小的滤波器(filters),步长为1,使用零填充(padding)使得输出特征图大小保持不变。
- 每个滤波器与输入图像进行卷积操作,生成32个大小为28x28x32的特征图。
- 激活函数:ReLU(修正线性单元),引入非线性。
3.MaxPool1层:
- 最大池化层使用2x2大小的窗口,步长为2,对每个32通道的特征图进行下采样。
- 输出特征图大小为14x14x32,减少计算量并提取主要特征。
4.Conv2层:
- 第二个卷积层包含64个3x3大小的滤波器,步长为1,同样使用零填充。
- 每个滤波器对上一层的特征图进行卷积操作,生成64个大小为14x14x64的特征图。
- 激活函数:ReLU,继续引入非线性。
5.MaxPool2层:
- 第二个最大池化层使用2x2大小的窗口,步长为2,对每个64通道的特征图进行下采样。
- 输出特征图大小为7x7x64,再次减少维度,保留主要特征。
6.Flatten层:
- 将最后一个卷积层的输出特征图展平为一维向量,大小为7x7x64=3136维,作为全连接层的输入。
7.FC1层:
- 全连接层包含128个神经元,每个神经元与前一层的每一个输入连接。
- 激活函数:ReLU,继续引入非线性,帮助网络学习复杂的特征。
8.FC2层:
- 输出层为全连接层,包含10个神经元,对应于10个类别(0到9)的概率。
- 激活函数:Softmax,将输出转换为类别概率分布,便于分类任务的多类别判定。
4.激活函数

5.卷积神经网络结构详解(输入为32x32)
神经网络结构图
Input (32x32x1)
|
|-- Conv1 (32 filters of 3x3)
| |
| |-- ReLU
|
|-- MaxPool1 (2x2)
|
|-- Conv2 (64 filters of 3x3)
| |
| |-- ReLU
|
|-- MaxPool2 (2x2)
|
|-- Flatten
|
|-- FC1 (128)
| |
| |-- ReLU
|
|-- FC2 (10)
|
|-- Softmax结构调整说明
1.Input层:
- 输入图像大小变为32x32像素,单通道灰度图像,因此输入的维度为32x32x1。
2.Conv1层:
- 第一个卷积层(Conv1)仍然使用32个3x3大小的滤波器进行卷积操作。
- 由于输入图像大小增加,输出特征图的大小变为30x30x32(如果使用零填充(padding='valid'),则为30x30x32)。
3.MaxPool1层:
- 第一个最大池化层(MaxPool1)仍然使用2x2大小的窗口进行池化操作,步长为2。
- 输出特征图大小变为15x15x32。
4.Conv2层:
- 第二个卷积层(Conv2)使用64个3x3大小的滤波器进行卷积操作。
- 输出特征图的大小变为13x13x64(如果使用零填充(padding='valid'),则为13x13x64)。
5.MaxPool2层:
- 第二个最大池化层(MaxPool2)仍然使用2x2大小的窗口进行池化操作,步长为2。
- 输出特征图大小变为6x6x64。
6.Flatten层:
- 将最后一个卷积层的输出特征图展平为一维向量,大小为6x6x64=2304维,作为全连接层的输入。
7.FC1层:
- 全连接层(FC1)的输入维度为2304。
- 仍然包含128个神经元,每个神经元与前一层的每一个输入连接。
8.FC2层:
- 输出层仍然为全连接层(FC2),包含10个神经元,对应于10个类别(0到9)的概率。
6.激活函数

7.总结
卷积神经网络在输入图像大小变化时,通过卷积层和池化层的运算,能够自适应地调整输出特征图的大小。这种特性使得CNN在处理不同大小的图像时具有较强的灵活性和适应性。
6.卷积神经网络结构:卷积层-池化层-全连接层,每层的作用,卷积层输出特征图计算
卷积神经网络(Convolutional Neural Network,CNN)通常由多个层组成,包括卷积层(Convolutional Layer)、池化层(Pooling Layer)和全连接层(Fully Connected Layer)。下面详细解释每一层的作用及卷积层输出特征图的计算方式。
1. 卷积层(Convolutional Layer)
- 作用:
-
- 卷积层是CNN的核心组成部分,用于提取输入图像的特征。
- 它通过卷积操作在输入图像上滑动一个或多个卷积核(filter),每个卷积核都是一个小的可学习的权重矩阵。
- 卷积操作可以捕捉到局部的空间关系,从而在不同位置共享权重,减少参数数量并增加模型的泛化能力。
- 输出特征图计算:

2. 池化层(Pooling Layer)
- 作用:
-
- 池化层用于减少卷积层输出的空间尺寸(宽度和高度),同时保留重要的特征。
- 常见的池化操作包括最大池化(Max Pooling)和平均池化(Average Pooling)。
- 输出特征图计算:

3. 全连接层(Fully Connected Layer)
- 作用:
-
- 全连接层将前面卷积层或池化层的输出“展平”成一个向量,并与权重矩阵进行全连接,用于学习图像全局的特征表示和进行分类等任务。
- 输出特征图计算:
-
- 全连接层没有特征图的概念,它的输入是一个一维向量。
- 输入向量的大小取决于前一层的输出大小。
4.总结
- 卷积层用于提取图像的局部特征,输出多个特征图。
- 池化层通过减少特征图的空间尺寸来降低计算成本和控制过拟合。
- 全连接层将前面层的输出映射为最终的分类输出或特征表示。
这些层的结合使得CNN能够有效地学习图像中的层次化特征,并在许多计算机视觉任务中表现出色。
卷积层输出特征图计算
卷积层(Convolutional Layer)在卷积神经网络(CNN)中是至关重要的组成部分,用于从输入图像中提取特征。计算卷积层输出特征图的过程涉及输入图像、卷积核、步长(stride)、填充(padding)等参数的影响。
1.输入和卷积核

2.填充(Padding)和步长(Stride)
在进行卷积操作时,通常会使用填充和步长来控制输出特征图的大小。
- 填充(Padding): 填充是在输入图像周围添加额外的像素(通常是0),以便保持卷积后输出特征图的尺寸与输入图像相同或更接近。填充量用(P)表示,通常有两种填充方式:
-
- Valid Padding(无填充):不添加额外像素,输出特征图较小。
- Same Padding(全填充):在输入图像周围均匀添加足够的像素,使得输出特征图尺寸保持与输入图像相同。
- 步长(Stride): 步长指的是卷积核在输入图像上滑动的步长大小。通常用(S)表示,步长越大,输出特征图尺寸越小。
3.输出特征图的计算公式



4.示例

在卷积神经网络(CNN)中,卷积核数量(也称为滤波器数量)和卷积层输出特征图的深度之间存在密切的关系。理解这两者之间的关系对于理解CNN的工作原理至关重要。
1.卷积核数量(滤波器数量)
卷积层中的每个滤波器(卷积核)都负责从输入数据中提取特定的特征。卷积核的数量决定了卷积层输出的特征图的深度。例如,如果卷积层有 ( K ) 个卷积核,那么该层的输出将是一个大小为 (
) 的特征图,其中 ( W ) 和 ( H ) 是特征图的宽度和高度,( K ) 是卷积核的数量。
2.特征图的深度
特征图的深度等于卷积核的数量。每个卷积核生成一个通道的输出,因此特征图的深度与卷积核的数量是一致的。
3.为什么需要多个卷积核?
多个卷积核的存在使得网络能够学习并捕捉输入数据的多个不同特征。每个卷积核可以学习不同的特征检测器,例如边缘、纹理、颜色或者更高级的特征,如形状或模式。通过多个卷积核并行地处理输入数据,CNN可以在特征空间中更全面地表示图像或其他输入数据。
4.深度的影响
深度(或通道数)决定了卷积层输出的特征图的丰富程度。更深的特征图可以提供更多关于输入数据的信息,这对于后续层次的学习和决策至关重要。在整个网络中,每一层的深度都是由其前一层的卷积核数量决定的。
5.示例
假设一个卷积层有 ( K = 32 ) 个卷积核,输入特征图的尺寸为 ()(宽度为28,高度为28,通道数为3,如RGB图像)。那么该卷积层的输出特征图的尺寸为 (
),其中32是卷积核的数量,也是特征图的深度。
6.总结
卷积核数量决定了卷积层输出特征图的深度,每个卷积核负责生成一个通道的输出。通过增加卷积核的数量,CNN能够学习到更多的特征表示,从而提高网络对输入数据的理解和表达能力。
7.分析全连接和卷积网络的区别
全连接神经网络(Fully Connected Neural Network)和卷积神经网络(Convolutional Neural Network,CNN)在结构和应用上有显著的区别,主要体现在以下几个方面:
1. 结构与特征提取
- 全连接神经网络:
-
- 每个神经元与上一层的所有神经元连接,即每一层的神经元与上一层的所有神经元都有权重连接。
- 没有显式地考虑输入的空间结构,对于图像等二维数据,将其展平成一维向量作为输入。
- 主要用于处理结构化数据,如特征向量或时间序列数据,能够学习全局特征和复杂的非线性关系。
- 卷积神经网络:
-
- 使用卷积层提取输入数据的局部特征,通过滑动窗口的方式,对输入数据进行卷积操作,以捕捉空间层次结构。
- 卷积操作允许网络在学习中共享参数,减少了参数数量和计算量,提高了模型的效率和泛化能力。
- 池化层进一步减少特征图的维度,保留重要的特征信息。
- 特别适用于处理图像、视频等具有空间结构的数据,能够有效地处理大规模的输入数据,并在计算机视觉和自然语言处理等领域表现出色。
2. 参数共享与稀疏连接
- 全连接神经网络:
-
- 每个神经元与上一层的所有神经元连接,需要大量的参数来训练网络。
- 每个连接都有独立的权重,没有参数共享的概念。
- 卷积神经网络:
-
- 卷积操作中的卷积核参数在整个输入特征图上共享,这意味着同一特征检测器在输入的不同位置都使用相同的权重。
- 参数共享使得模型更加高效,减少了训练参数的数量,同时也有助于增强模型对数据的平移不变性(translation invariance)。
3. 层次结构与适用场景
- 全连接神经网络:
-
- 适合处理维度较低、结构化的数据,如MNIST手写数字数据集。
- 网络结构较为简单直接,可以用于解决分类、回归等问题,但对于大规模数据和处理空间关系较强的任务效果有限。
- 卷积神经网络:
-
- 通过卷积层和池化层,能够有效地提取输入数据的局部特征,并保留其空间结构。
- 特别适用于处理图像、视频等大规模数据集,如ImageNet,能够学习到数据的层次化特征表示,从而在视觉任务中取得优秀的效果。
4.总结
全连接神经网络和卷积神经网络在结构、参数共享、适用场景等方面有显著的差异。全连接网络适用于处理结构化数据和较低维度的问题,而卷积神经网络则专注于处理具有空间结构的数据,如图像和视频,通过卷积操作有效地提取局部特征并保留空间信息,适合于计算机视觉和自然语言处理等需要处理复杂数据结构的任务。
全连接神经网络(FCN)每层神经元与上一层所有神经元连接,适合处理结构化数据;卷积神经网络(CNN)通过卷积层提取局部特征并共享参数,适合处理图像等具有空间结构的数据,效率高且能提取高级特征。
8.网络训练过程中过拟合/欠拟合的表现
在神经网络训练过程中,过拟合(overfitting)和欠拟合(underfitting)是两种常见的问题,它们可以通过模型在训练集和验证集上的表现来进行识别。
1.过拟合(Overfitting)
过拟合指的是模型在训练集上表现良好,但在测试集或验证集上表现较差的情况。其主要表现包括:
- 训练集表现好:模型在训练数据上能够达到较低的训练误差,表现非常好。
- 验证集表现差:模型在验证集(或测试集)上的表现明显差于训练集,验证误差较大。
- 模型复杂度高:模型可能具有过多的参数或复杂度,导致学习到了训练数据中的噪声和细节,而不是泛化到新数据。
- 泛化能力差:模型对新数据的预测能力不强,容易受到噪声干扰,无法很好地泛化到未见过的数据样本。
2.欠拟合(Underfitting)
欠拟合则是指模型在训练集上和验证集上的表现都较差,其主要表现包括:
- 训练集表现差:模型在训练数据上的表现就很一般,训练误差较高。
- 验证集表现差:模型在验证集(或测试集)上的表现同样差,验证误差也较大。
- 模型复杂度低:模型可能过于简单,不能捕捉数据的复杂关系和特征。
- 欠拟合原因:可能是模型不够复杂,或者训练不足(epochs不够多、数据量不足等)。
3.如何处理过拟合和欠拟合?
- 过拟合处理方法:
-
- 增加数据量:增加训练数据可以减少过拟合。
- 数据增强:对训练数据进行变换或扩充,增加数据的多样性。
- 正则化:如L1、L2正则化或者Dropout等方法来减少模型复杂度。
- 提前停止(Early Stopping):在验证集误差达到最小值时停止训练,避免继续训练导致过拟合。
- 欠拟合处理方法:
-
- 增加模型复杂度:增加模型的层数或者每层神经元的数量。
- 训练更长时间:增加训练轮数(epochs)或调整学习率。
- 特征工程:对输入特征进行更好的预处理或特征选择,以提高模型的表现能力。
通过观察模型在训练集和验证集上的表现,可以及时调整模型结构和训练策略,以解决过拟合和欠拟合问题,从而提高模型的泛化能力和预测性能。
- 优点:能够提高模型的泛化能力,通过对激活值进行归一化,抑制较大值,增强局部竞争性。
4. 重叠的最大池化层(Overlapping Max Pooling)
- 创新点:使用重叠的最大池化层,而不是传统的不重叠池化。
- 优点:重叠池化可以在一定程度上减少过拟合,并且能够更好地保留特征信息。
5. 数据增强和Dropout
- 创新点:使用数据增强(如随机裁剪、水平翻转等)和Dropout技术。
- 优点:数据增强增加了训练样本的多样性,减轻了过拟合。Dropout在训练过程中随机忽略一部分神经元,进一步减少过拟合。
6. 大型卷积核和多卷积层结构
- 创新点:AlexNet使用了较大的卷积核(如11x11、5x5)和多个卷积层。
- 优点:较大的卷积核能够捕捉更多的空间信息,多个卷积层可以提取更丰富的特征。
7. 使用大的数据集(ImageNet)
- 创新点:在ImageNet数据集上进行训练,该数据集包含1500万张带有标签的高分辨率图像,分为1000个类别。
- 优点:大规模数据集使得深度学习模型能够学习到更加复杂和泛化的特征,提高了模型的性能。
8.AlexNet的网络结构
为了更好地理解这些创新点,我们来看看AlexNet的具体网络结构:
1.输入层:224x224x3 的图像。
2.卷积层1:96个11x11卷积核,步长4,重叠最大池化(3x3,步长2),ReLU激活。
3.卷积层2:256个5x5卷积核,重叠最大池化(3x3,步长2),ReLU激活。
4.卷积层3:384个3x3卷积核,ReLU激活。
5.卷积层4:384个3x3卷积核,ReLU激活。
6.卷积层5:256个3x3卷积核,重叠最大池化(3x3,步长2),ReLU激活。
7.全连接层1:4096个神经元,ReLU激活,Dropout。
8.全连接层2:4096个神经元,ReLU激活,Dropout。
9.输出层:1000个神经元,Softmax激活。
9.结论
AlexNet通过一系列创新设计,在ImageNet竞赛中取得了突破性的成果。它的成功证明了深度卷积神经网络在图像分类任务中的强大能力,并且这些设计思路也在后续的深度学习研究中被广泛应用和进一步发展。
2.VGG网络设计要点,小卷积核优势、特征图减半通道数翻倍原因分析、512通道后不增加原因(综合题)
VGG(Visual Geometry Group)网络是由牛津大学的Visual Geometry Group在2014年提出的一种深度卷积神经网络模型。VGG网络的设计在于其简单而有效的架构。以下是VGG网络的设计要点:
1. 使用小卷积核
- 设计要点:VGG网络使用一系列3x3的小卷积核,而不是使用更大的卷积核。
- 优点:多个3x3卷积核堆叠可以模拟更大感受野的效果(例如两个3x3卷积核堆叠的感受野相当于一个5x5卷积核),同时保留了更多的细节信息,并减少了参数数量。
2. 深层结构
- 设计要点:VGG网络通过增加网络的深度来提高性能,最深的VGG-19包含19个权重层。
- 优点:增加网络深度能够捕捉更复杂的特征,提升模型的表达能力和性能。
3. 固定的卷积和池化层配置
- 设计要点:在每个卷积层之后加入一个ReLU激活函数,并在一系列卷积层之后插入一个最大池化层。
- 优点:这种固定配置有助于简化网络设计,同时保证每个卷积块之后的尺寸减半,从而逐渐减少特征图的尺寸。
4. 全连接层
- 设计要点:在卷积层之后,VGG网络使用了三个全连接层,其中前两个全连接层每层有4096个神经元,最后一层是一个1000个神经元的输出层(对于ImageNet数据集)。
- 优点:全连接层有助于整合特征图中的信息,从而进行分类。
5. 数据增强和Dropout
- 设计要点:在训练过程中使用数据增强技术(如随机裁剪、水平翻转)和Dropout正则化。
- 优点:数据增强增加了训练样本的多样性,减轻了过拟合。Dropout在训练过程中随机忽略一部分神经元,进一步减少过拟合。
6.VGG网络结构
VGG网络有多个变体,最著名的是VGG-16和VGG-19。以下是VGG-16的网络结构:
1.输入层:224x224x3 的图像。
2.卷积层1:64个3x3卷积核,ReLU激活。
3.卷积层2:64个3x3卷积核,ReLU激活,最大池化(2x2,步长2)。
4.卷积层3:128个3x3卷积核,ReLU激活。
5.卷积层4:128个3x3卷积核,ReLU激活,最大池化(2x2,步长2)。
6.卷积层5:256个3x3卷积核,ReLU激活。
7.卷积层6:256个3x3卷积核,ReLU激活。
8.卷积层7:256个3x3卷积核,ReLU激活,最大池化(2x2,步长2)。
9.卷积层8:512个3x3卷积核,ReLU激活。
10.卷积层9:512个3x3卷积核,ReLU激活。
11.卷积层10:512个3x3卷积核,ReLU激活,最大池化(2x2,步长2)。
12.卷积层11:512个3x3卷积核,ReLU激活。
13.卷积层12:512个3x3卷积核,ReLU激活。
14.卷积层13:512个3x3卷积核,ReLU激活,最大池化(2x2,步长2)。
15.全连接层1:4096个神经元,ReLU激活,Dropout。
16.全连接层2:4096个神经元,ReLU激活,Dropout。
17.输出层:1000个神经元,Softmax激活。
- 解释:3x3卷积核通过对局部区域进行细致扫描,可以更好地捕捉到图像中的细节特征,如边缘、纹理等。这在处理高分辨率图像时尤其有用。
4. 避免过拟合
- 优势:减少过拟合的风险。
- 解释:较小的卷积核和较少的参数数量有助于防止模型过拟合,因为模型的容量相对较小,更倾向于学习数据中的一般特征而非噪声。
5. 更稳定的梯度传播
- 优势:有助于稳定梯度的传播,缓解梯度消失问题。
- 解释:由于小卷积核的堆叠使得网络更加深层,每层的梯度更新较小,避免了梯度爆炸或消失的问题。这使得网络能够有效地训练得更深。
6. 模块化设计
- 优势:简化了网络的设计和实现。
- 解释:使用统一的3x3卷积核使得网络的每一层具有一致的设计,这简化了网络的结构并使其更容易实现和调整。
7.VGG网络中的卷积块示例
在VGG网络中,每个卷积块通常由多个3x3卷积层组成,之后是一个池化层。例如,在VGG-16中,前几个卷积块的结构如下:
-
1.第一卷积块:
- 64个3x3卷积核,ReLU激活。
- 64个3x3卷积核,ReLU激活。
- 最大池化(2x2)。
-
3.第三卷积块:
- 256个3x3卷积核,ReLU激活。
- 256个3x3卷积核,ReLU激活。
- 256个3x3卷积核,ReLU激活。
- 最大池化(2x2)。
-
2.第二卷积块:
- 128个3x3卷积核,ReLU激活。
- 128个3x3卷积核,ReLU激活。
- 最大池化(2x2)。
通过这样的设计,VGG网络在保持高效特征提取的同时,显著提升了模型的深度和复杂性,达到了优秀的性能。
8.结论
VGG网络通过使用小卷积核(例如3x3卷积核),在参数效率、特征提取能力、网络深度、梯度传播和网络设计方面都获得了显著的优势。这些设计选择不仅提升了模型的性能,还为后续的卷积神经网络架构设计提供了宝贵的经验和灵感。
特征图减半通道数翻倍原因分析
在VGG网络设计中,每经过一个池化层,特征图的空间尺寸(宽度和高度)减半,同时特征图的通道数(深度)翻倍。这种设计有其特定的原因和优势。以下是这种设计策略的详细分析:
1. 控制计算量和内存使用
- 空间尺寸减半:
-
- 计算优势:每次特征图的空间尺寸减半,计算量减少到原来的一半。池化操作(如2x2最大池化)可以有效地减少特征图的尺寸,降低随后的卷积运算的计算成本。
- 内存优势:减少特征图的尺寸可以显著降低内存占用。这对于训练深度神经网络,尤其是处理高分辨率输入图像时非常重要。
- 通道数翻倍:
-
- 信息量保持:尽管空间尺寸减半,但通过增加特征图的通道数,网络可以保持甚至增加特征表示的能力。这意味着即使特征图变小了,网络也能够捕捉到更多的特征信息。
- 平衡计算量:翻倍通道数增加了一些计算量,但整体计算量仍在可控范围内,因为减少了特征图的空间尺寸。这种平衡使得网络在计算效率和表达能力之间达到了较好的折中。
2. 深度增加特征表达能力
- 层数增加:
-
- 特征提取能力增强:通过不断减小空间尺寸并增加通道数,VGG网络可以堆叠更多的卷积层。这使得网络能够学习到更复杂和抽象的特征。
- 逐层提取特征:前面的卷积层可能会捕捉到图像中的低级特征(如边缘、纹理),而后面的卷积层则会逐渐提取到高级特征(如物体的形状、部件)。
3. 防止过拟合
- 通道数翻倍:
-
- 正则化效果:增加通道数有助于网络从不同的通道学习到不同的特征,增强了特征表示的多样性,有助于防止过拟合。
- 更丰富的特征表示:更多的通道数使得每一层可以表示更丰富的特征,从而提升模型的泛化能力。
4. 一致的设计原则
- 模块化设计:
-
- 简化网络结构:VGG网络的这种设计使得每个卷积块的结构一致,便于设计、实现和调试。每个卷积块都是由多个3x3卷积层和一个池化层组成。
- 可扩展性:这种结构的模块化设计使得网络可以很容易地扩展,通过增加或减少卷积块来调整网络的深度和复杂度。
5.示例:VGG-16的网络结构
VGG-16网络的设计很好地体现了这种策略:
1.输入层:224x224x3 的图像。
2.第一卷积块:
- 卷积层:64个3x3卷积核,ReLU激活。
- 卷积层:64个3x3卷积核,ReLU激活。
- 池化层:最大池化(2x2),特征图尺寸减半。
3.第二卷积块:
- 卷积层:128个3x3卷积核,ReLU激活。
- 卷积层:128个3x3卷积核,ReLU激活。
- 池化层:最大池化(2x2),特征图尺寸减半。
4.第三卷积块:
- 卷积层:256个3x3卷积核,ReLU激活。
- 卷积层:256个3x3卷积核,ReLU激活。
- 卷积层:256个3x3卷积核,ReLU激活。
- 池化层:最大池化(2x2),特征图尺寸减半。
5.第四卷积块:
- 卷积层:512个3x3卷积核,ReLU激活。
- 卷积层:512个3x3卷积核,ReLU激活。
- 卷积层:512个3x3卷积核,ReLU激活。
- 池化层:最大池化(2x2),特征图尺寸减半。
6.第五卷积块:
- 卷积层:512个3x3卷积核,ReLU激活。
- 卷积层:512个3x3卷积核,ReLU激活。
- 卷积层:512个3x3卷积核,ReLU激活。
- 池化层:最大池化(2x2),特征图尺寸减半。
7.全连接层:
- 全连接层:4096个神经元,ReLU激活,Dropout。
- 全连接层:4096个神经元,ReLU激活,Dropout。
- 输出层:1000个神经元,Softmax激活。
6.结论
VGG网络通过每次减半特征图的空间尺寸和翻倍通道数,有效地控制了计算量和内存使用,同时保持或增强了特征表示能力。这种设计策略不仅提高了模型的表达能力和泛化能力,还确保了网络的训练和推理效率。这种模块化、深层次的设计思路为后续的深度卷积神经网络提供了重要的启示和基础。
VGG512通道后不增加原因
在VGG网络中,特征图的通道数在达到512后不再继续增加。这个设计选择背后有多种原因,主要包括计算复杂度、内存限制、有效特征提取和过拟合防范等因素。以下是详细分析:
1. 计算复杂度和内存限制
- 计算复杂度:每个卷积层的计算复杂度与输入特征图的通道数和输出特征图的通道数成正比。如果通道数继续增加,计算复杂度将会显著增加,导致训练和推理时间变长。
- 内存使用:更高的通道数需要更多的内存来存储特征图和相应的梯度信息。在训练过程中,这会增加显存的需求,对硬件资源提出更高要求。
2. 有效特征提取
- 饱和点:特征提取的能力在某个点之后会达到饱和。512个通道已经能够捕捉到足够丰富和多样的特征,进一步增加通道数可能对提高特征表示的能力贡献有限。
- 信息冗余:增加过多的通道数可能导致信息冗余,网络在更多的通道上提取相似的特征,这样做的边际效益递减。
3. 网络深度和特征抽象
- 层次特征提取:VGG网络的设计思想是通过增加网络深度来逐层提取更抽象、更复杂的特征。在达到512个通道后,网络已经足够深,能够从图像中提取出高级特征,继续增加通道数对特征抽象的提升效果有限。
- 非线性表达:通过更多层的小卷积核和非线性激活函数(如ReLU),VGG网络能够实现复杂的特征表达。通道数达到512后,通过增加层数而不是通道数来继续提升特征抽象能力。
4. 过拟合防范
- 过拟合风险:增加通道数会增加网络的容量,使其更容易过拟合训练数据。512个通道已经能够提供足够的模型容量,通过使用512通道并适当深度的网络,VGG能够在不过拟合的情况下学习到丰富的特征。
- 正则化:保持通道数在合理范围内可以减少过拟合的风险。VGG网络中还使用了Dropout等正则化技术来进一步防止过拟合。
5. 经验和实践
- 经验设计:在实际实验中,研究者发现512通道已经能够在图像分类任务(如ImageNet)上取得非常好的效果。进一步增加通道数并没有带来显著的性能提升,反而增加了计算和存储成本。
- 设计简化:在网络设计中,使用固定的最大通道数(如512)可以简化网络结构,使其更容易实现和调试。
6.结论
VGG网络在特征图通道数达到512后不再增加,这一设计选择是综合考虑计算复杂度、内存限制、有效特征提取、过拟合防范以及实践经验的结果。通过这种策略,VGG网络能够在保持高效特征提取和强大表达能力的同时,避免不必要的计算和存储开销,最终实现了在各种图像分类任务中的优秀表现。
3.ResNet网络 某个残差单元的画图、1*1卷积层的作用、特征图大小、通道数如何保持一致的(综合题)
ResNet(Residual Network)是由何恺明等人提出的一种深度神经网络架构,在2015年的ImageNet竞赛中取得了优异成绩。其最大的特点是引入了残差学习(Residual Learning)的概念,从而解决了随着网络深度增加,训练变得困难的问题。
ResNet的关键概念
- 残差块(Residual Block):传统的深层网络直接学习期望映射函数(H(x)),ResNet通过学习残差函数(F(x) = H(x) - x)来简化学习过程。具体来说,残差块通过引入跳跃连接(skip connection)或快捷连接(shortcut connection),使得输入(x)可以直接在网络中传播:
[y = F(x,{W_i}) + x]
其中,(F(x,{W_i}))表示学习的残差函数,({W_i})表示该层的参数,(y)是输出。 - 跳跃连接:在每个残差块中,输入(x)可以直接加到输出上。这种结构可以有效缓解梯度消失问题,使得梯度能够更容易地传播到更早的层,从而使得深层网络的训练更加稳定。
ResNet的结构
ResNet 的基本单元是残差块。根据层数不同,常见的 ResNet 有 ResNet-18、ResNet-34、ResNet-50、ResNet-101 和 ResNet-152 等。其中,ResNet-50、ResNet-101 和 ResNet-152 使用了瓶颈块(bottleneck block),每个瓶颈块包含三个卷积层(1x1, 3x3, 1x1),而 ResNet-18 和 ResNet-34 则使用基本的残差块,每个残差块包含两个3x3卷积层。
ResNet的优势
- 解决深度网络的退化问题:深度网络中,随着层数增加,网络性能可能会变差。这是由于梯度消失和梯度爆炸问题导致的。ResNet通过引入跳跃连接,使得梯度可以直接传递,缓解了这些问题。
- 更高的性能:ResNet在图像分类、目标检测等任务中取得了显著的性能提升。其结构简单但效果卓越,被广泛应用于各类计算机视觉任务中。
ResNet的实现
一个典型的ResNet实现(以PyTorch为例)如下:
import torch
import torch.nn as nn
import torch.nn.functional as F
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, in_planes, planes, stride=1):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.shortcut = nn.Sequential()
if stride != 1 or in_planes != self.expansion * planes:
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, self.expansion * planes, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(self.expansion * planes)
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
out += self.shortcut(x)
out = F.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, num_blocks, num_classes=1000):
super(ResNet, self).__init__()
self.in_planes = 64
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.layer1 = self._make_layer(block, 64, num_blocks[0], stride=1)
self.layer2 = self._make_layer(block, 128, num_blocks[1], stride=2)
self.layer3 = self._make_layer(block, 256, num_blocks[2], stride=2)
self.layer4 = self._make_layer(block, 512, num_blocks[3], stride=2)
self.linear = nn.Linear(512 * block.expansion, num_classes)
def _make_layer(self, block, planes, num_blocks, stride):
strides = [stride] + [1] * (num_blocks - 1)
layers = []
for stride in strides:
layers.append(block(self.in_planes, planes, stride))
self.in_planes = planes * block.expansion
return nn.Sequential(*layers)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = F.max_pool2d(out, kernel_size=3, stride=2, padding=1)
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = F.avg_pool2d(out, 4)
out = out.view(out.size(0), -1)
out = self.linear(out)
return out
def ResNet18():
return ResNet(BasicBlock, [2, 2, 2, 2])
def ResNet34():
return ResNet(BasicBlock, [3, 4, 6, 3])
# Example of creating a ResNet-18 model
model = ResNet18()
print(model)这个代码定义了ResNet的基本块(BasicBlock)和ResNet的整体结构,并提供了构建ResNet-18和ResNet-34模型的函数。
1*1卷积层的作用
1x1卷积层(1x1 Convolution)在卷积神经网络(CNN)中有多个重要作用,尤其是在现代深度学习架构中,比如ResNet、Inception等。以下是1x1卷积层的主要作用:
1. 降维和升维
1x1卷积层可以用来改变输入特征图的通道数(即维度),从而在不改变特征图的空间尺寸的情况下进行降维或升维。这对于减少计算量和内存消耗特别有用。例如,假设输入特征图有 (C_{in}) 个通道,通过1x1卷积核可以将其变为 (C_{out}) 个通道。
降维:减少通道数,从而降低计算和存储需求。
升维:增加通道数,允许后续层更丰富地表达特征。
2. 引入非线性
1x1卷积层后通常会跟随非线性激活函数(如ReLU),这使得网络可以更好地捕捉复杂的非线性特征。这相当于在通道维度上进行的逐像素操作,每个像素位置都进行一个线性变换(卷积操作),再通过非线性激活函数,引入复杂的非线性表达能力。
3. 特征融合
通过1x1卷积,可以将不同通道的信息进行整合和重新组合。每个输出通道通过学习不同的权重,将输入的所有通道信息进行加权求和,从而实现信息融合。这对于模型提取更有效的特征非常重要。
4. 计算效率
相比于较大卷积核(如3x3或5x5),1x1卷积核的计算复杂度更低,因为其计算量仅与输入通道和输出通道相关,而不涉及空间维度(宽和高)的操作。因此,1x1卷积层可以显著减少计算量。
5. 构建深度瓶颈块
在ResNet的瓶颈块中,1x1卷积层用于在3x3卷积层前后进行降维和升维。例如,在ResNet-50中,1x1卷积层先将输入的高维度特征降维,再通过3x3卷积进行空间特征提取,最后再通过1x1卷积升维。这种设计不仅降低了计算量,还提升了模型的表达能力。
示例:1x1卷积层在瓶颈块中的使用
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, in_planes, planes, stride=1):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, planes * self.expansion, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(planes * self.expansion)
self.shortcut = nn.Sequential()
if stride != 1 or in_planes != planes * self.expansion:
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, planes * self.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * self.expansion)
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = F.relu(self.bn2(self.conv2(out)))
out = self.bn3(self.conv3(out))
out += self.shortcut(x)
out = F.relu(out)
return out在这个瓶颈块中,conv1 和 conv3 都是1x1卷积层,用于降维和升维,而 conv2 则是3x3卷积层,用于特征提取。
结论
1x1卷积层在CNN中起到关键作用,通过降维和升维、引入非线性、特征融合以及提高计算效率等方式,极大地增强了网络的表达能力和计算效率。
特征图大小、通道数如何保持一致的
在ResNet(Residual Network)中,特征图的空间尺寸和通道数的一致性是通过以下几种策略来实现的:
1. 空间尺寸的一致性
填充(Padding)
在卷积操作中,通过填充可以保持特征图的空间尺寸不变。对于标准的3x3卷积核,通常会在输入特征图的边缘添加1个像素的填充(padding=1)。这样可以确保输出特征图的尺寸与输入特征图的尺寸相同。
例如,一个3x3卷积核的填充:
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=1, padding=1)步幅(Stride)
步幅决定了卷积核在特征图上移动的步长。通常,步幅设置为1以保持特征图的空间尺寸不变。如果步幅设置为2,则特征图的尺寸会减半。为了在网络中某些层实现下采样,可以在卷积层设置步幅为2,但这通常会在后续层中使用适当的操作来恢复特征图的尺寸。
2. 通道数的一致性
残差块(Residual Block)
在ResNet中,残差块(Residual Block)是保持特征图通道数一致的关键组件。残差块主要分为两种:基本块(Basic Block)和瓶颈块(Bottleneck Block)。
基本块(Basic Block)
在基本块中,通常会使用相同的输入和输出通道数,并通过适当的填充和步幅确保这一点。以下是基本块的示例代码:
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, in_planes, planes, stride=1):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.shortcut = nn.Sequential()
if stride != 1 or in_planes != self.expansion * planes:
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, self.expansion * planes, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(self.expansion * planes)
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
out += self.shortcut(x)
out = F.relu(out)
return out瓶颈块(Bottleneck Block)
在瓶颈块中,通过1x1卷积进行降维和升维操作。以下是瓶颈块的示例代码:
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, in_planes, planes, stride=1):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, planes * self.expansion, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(planes * self.expansion)
self.shortcut = nn.Sequential()
if stride != 1 or in_planes != planes * self.expansion:
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, planes * self.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * self.expansion)
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = F.relu(self.bn2(self.conv2(out)))
out = self.bn3(self.conv3(out))
out += self.shortcut(x)
out = F.relu(out)
return out3. 快捷连接(Shortcut Connection)
在残差块中,为了使输入特征图与输出特征图的尺寸一致,通常会使用快捷连接。如果输入特征图和输出特征图的尺寸不一致,可以通过1x1卷积进行调整:
if stride != 1 or in_planes != self.expansion * planes:
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, planes * self.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * self.expansion)
)4. 网络结构
在整个ResNet结构中,通过重复上述基本块和瓶颈块,并在需要时进行调整,确保特征图的尺寸和通道数一致。例如,ResNet-50的结构可以通过多个瓶颈块实现,在每个阶段的开始部分进行下采样,并通过1x1卷积调整通道数。
5.总结
通过以上策略,ResNet在保持特征图空间尺寸和通道数一致方面提供了一个有效的解决方案。适当的填充、步幅设置和在残差块中进行调整,确保了特征图在不同层之间传递时能够保持尺寸和通道数的一致性,使得网络能够更稳定地进行训练和推理。
五、图像生成
1.GAM网络:生成器、判别器组成
生成对抗网络(Generative Adversarial Network, GAN)是一种深度学习模型,由Ian Goodfellow等人在2014年提出。GANs主要用于生成逼真的数据样本,如图像、声音等,其核心思想是通过两个神经网络(生成器和判别器)之间的对抗过程进行训练。
GAN的基本构成
GAN由两个主要部分组成:
1.生成器(Generator, G):
- 生成器网络接受一个随机噪声向量(z)作为输入,输出一个数据样本(G(z)),该样本尽可能接近真实数据分布。
- 目标是欺骗判别器,使得生成的数据样本被判别器认为是真实的。
2.判别器(Discriminator, D):
- 判别器网络接受一个数据样本(真实样本或生成样本)作为输入,输出该样本是真实的概率(D(x))。
- 目标是区分真实样本和生成样本。
GAN的训练过程(交替训练)
GAN的训练过程是一个动态博弈过程,生成器和判别器相互竞争并不断改进:
1.判别器的训练:

2.生成器的训练:

损失函数
GAN的优化目标可以表示为:
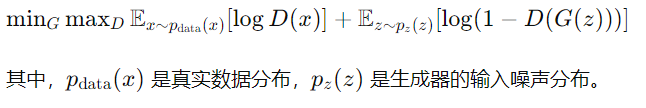
代码示例
以下是一个使用PyTorch实现简单GAN的示例:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
# 定义生成器
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.model = nn.Sequential(
nn.Linear(100, 256),
nn.ReLU(True),
nn.Linear(256, 512),
nn.ReLU(True),
nn.Linear(512, 1024),
nn.ReLU(True),
nn.Linear(1024, 28*28),
nn.Tanh()
)
def forward(self, x):
return self.model(x).view(x.size(0), 1, 28, 28)
# 定义判别器
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(28*28, 1024),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(1024, 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 1),
nn.Sigmoid()
)
def forward(self, x):
return self.model(x.view(x.size(0), 28*28))
# 超参数
batch_size = 64
learning_rate = 0.0002
num_epochs = 50
latent_dim = 100
# 数据加载和预处理
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.5], std=[0.5])
])
dataset = datasets.MNIST(root='./data', train=True, transform=transform, download=True)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
# 初始化模型
generator = Generator()
discriminator = Discriminator()
# 损失函数和优化器
criterion = nn.BCELoss()
optimizer_G = optim.Adam(generator.parameters(), lr=learning_rate)
optimizer_D = optim.Adam(discriminator.parameters(), lr=learning_rate)
# 训练GAN
for epoch in range(num_epochs):
for i, (imgs, _) in enumerate(dataloader):
# 训练判别器
real_labels = torch.ones(batch_size, 1)
fake_labels = torch.zeros(batch_size, 1)
real_imgs = imgs
z = torch.randn(batch_size, latent_dim)
fake_imgs = generator(z)
real_loss = criterion(discriminator(real_imgs), real_labels)
fake_loss = criterion(discriminator(fake_imgs.detach()), fake_labels)
d_loss = real_loss + fake_loss
optimizer_D.zero_grad()
d_loss.backward()
optimizer_D.step()
# 训练生成器
g_loss = criterion(discriminator(fake_imgs), real_labels)
optimizer_G.zero_grad()
g_loss.backward()
optimizer_G.step()
# 打印损失
if i % 100 == 0:
print(f'Epoch [{epoch}/{num_epochs}] Batch [{i}/{len(dataloader)}] Loss D: {d_loss.item()}, Loss G: {g_loss.item()}')
print("Training finished.")GAN的挑战
- 不稳定性:GAN的训练过程容易不稳定,可能会导致生成器或判别器的过拟合或欠拟合。
- 模式崩溃:生成器可能会陷入生成一小部分模式而忽略其他可能的样本,这被称为模式崩溃(mode collapse)。
结论
GAN是一种强大的生成模型,通过生成器和判别器的对抗训练,可以生成逼真的数据样本。尽管GAN在许多应用中表现出色,但其训练过程具有挑战性,需要仔细的调参和设计。
GAN网络生成器、判别器组成
生成对抗网络(Generative Adversarial Network, GAN)由两个主要组件组成:生成器(Generator)和判别器(Discriminator)。这两个网络相互对抗,生成器试图生成逼真的数据以欺骗判别器,而判别器则试图区分真实数据和生成数据。
1. 生成器(Generator)
生成器的任务是接受一个随机噪声向量作为输入,输出尽可能逼真的数据样本。生成器通常由一系列的全连接层或卷积层组成,根据具体的任务(例如图像生成、文本生成)选择适当的网络架构。
生成器的典型结构(以图像生成为例)
- 输入层:一个随机噪声向量(通常来自均匀分布或正态分布)。
- 全连接层:将噪声向量映射到一个高维空间。
- 卷积转置层(转置卷积):逐步上采样以生成高分辨率的图像。
- 激活函数:通常使用ReLU激活函数,最后一层使用Tanh激活函数以生成范围在[-1, 1]之间的像素值。
import torch.nn as nn
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.model = nn.Sequential(
nn.Linear(100, 256),
nn.ReLU(True),
nn.Linear(256, 512),
nn.ReLU(True),
nn.Linear(512, 1024),
nn.ReLU(True),
nn.Linear(1024, 28*28),
nn.Tanh()
)
def forward(self, x):
return self.model(x).view(x.size(0), 1, 28, 28)2. 判别器(Discriminator)
判别器的任务是接受一个数据样本(真实样本或生成样本)作为输入,输出该样本是真实的概率。判别器通常由一系列的卷积层和全连接层组成,最终输出一个介于0和1之间的概率值。
判别器的典型结构(以图像分类为例)
- 输入层:一个数据样本(例如图像)。
- 卷积层:逐步下采样以提取特征。
- 全连接层:将特征映射到一个概率值。
- 激活函数:通常使用Leaky ReLU激活函数,最后一层使用Sigmoid激活函数以输出概率值。
import torch.nn as nn
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(28*28, 1024),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(1024, 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 1),
nn.Sigmoid()
)
def forward(self, x):
return self.model(x.view(x.size(0), 28*28))3. GAN的训练过程
GAN的训练过程是生成器和判别器的对抗过程:
1.训练判别器:
- 使用真实数据样本训练判别器,使其输出接近1(真实)。
- 使用生成的数据样本训练判别器,使其输出接近0(假的)。
2.训练生成器:
- 使用生成的数据样本训练生成器,使判别器认为这些数据是真实的(即输出接近1)。
这种训练过程通过交替更新判别器和生成器的参数,实现生成器生成越来越逼真的数据,同时判别器也变得越来越强大。
4.GAN的整体训练示例
以下是一个完整的GAN训练过程的示例代码:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
# 定义生成器和判别器(前面已经定义过)
# 超参数
batch_size = 64
learning_rate = 0.0002
num_epochs = 50
latent_dim = 100
# 数据加载和预处理
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.5], std=[0.5])
])
dataset = datasets.MNIST(root='./data', train=True, transform=transform, download=True)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
# 初始化模型
generator = Generator()
discriminator = Discriminator()
# 损失函数和优化器
criterion = nn.BCELoss()
optimizer_G = optim.Adam(generator.parameters(), lr=learning_rate)
optimizer_D = optim.Adam(discriminator.parameters(), lr=learning_rate)
# 训练GAN
for epoch in range(num_epochs):
for i, (imgs, _) in enumerate(dataloader):
# 训练判别器
real_labels = torch.ones(batch_size, 1)
fake_labels = torch.zeros(batch_size, 1)
real_imgs = imgs
z = torch.randn(batch_size, latent_dim)
fake_imgs = generator(z)
real_loss = criterion(discriminator(real_imgs), real_labels)
fake_loss = criterion(discriminator(fake_imgs.detach()), fake_labels)
d_loss = real_loss + fake_loss
optimizer_D.zero_grad()
d_loss.backward()
optimizer_D.step()
# 训练生成器
g_loss = criterion(discriminator(fake_imgs), real_labels)
optimizer_G.zero_grad()
g_loss.backward()
optimizer_G.step()
# 打印损失
if i % 100 == 0:
print(f'Epoch [{epoch}/{num_epochs}] Batch [{i}/{len(dataloader)}] Loss D: {d_loss.item()}, Loss G: {g_loss.item()}')
print("Training finished.")5.结论
生成对抗网络通过生成器和判别器的对抗训练,能够生成逼真的数据样本。生成器通过学习生成数据来欺骗判别器,而判别器通过学习区分真实数据和生成数据,从而不断提升自身能力。这种对抗机制使GAN在图像生成、数据增强、风格迁移等任务中表现出色。
GAN工作原理
生成对抗网络(Generative Adversarial Network, GAN)的工作原理基于两个神经网络——生成器(Generator)和判别器(Discriminator)之间的对抗训练。这两个网络相互竞争,生成器试图生成逼真的数据样本以欺骗判别器,而判别器则试图区分真实数据和生成数据。通过这种对抗过程,生成器逐渐学会生成高质量的样本。
GAN的基本构成
GAN的训练过程是生成器和判别器的对抗过程:
1.训练判别器:
- 使用真实数据样本训练判别器,使其输出接近1(真实)。
- 使用生成的数据样本训练判别器,使其输出接近0(假的)。
2.训练生成器:
- 使用生成的数据样本训练生成器,使判别器认为这些数据是真实的(即输出接近1)。
这种训练过程通过交替更新判别器和生成器的参数,实现生成器生成越来越逼真的数据,同时判别器也变得越来越强大。
GAN的损失函数
GAN的训练通过一个二人零和博弈过程进行,生成器和判别器分别优化以下目标函数:

GAN的训练过程
GAN的训练过程可以概括为以下步骤:
GAN的训练过程可以概括为以下步骤:
1.初始化生成器和判别器的参数。
2.训练判别器:
- 使用真实样本训练判别器,使其输出接近1(表示真实)。
- 使用生成器生成的假样本训练判别器,使其输出接近0(表示虚假)。
- 优化判别器的损失函数(L_D)以提高其区分真实和虚假样本的能力。
3.训练生成器:
- 生成假样本并通过判别器进行评估。
- 生成器的目标是使判别器认为生成的假样本是真实的,即最大化(
)。
- 优化生成器的损失函数(L_G)以提高生成样本的质量。
4.重复步骤2和步骤3直到生成器和判别器达到一个动态平衡,即判别器不能轻易区分真实和生成样本。
GAN的训练代码示例
以下是使用PyTorch实现的一个简单的GAN训练示例:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
# 定义生成器
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.model = nn.Sequential(
nn.Linear(100, 256),
nn.ReLU(True),
nn.Linear(256, 512),
nn.ReLU(True),
nn.Linear(512, 1024),
nn.ReLU(True),
nn.Linear(1024, 28*28),
nn.Tanh()
)
def forward(self, x):
return self.model(x).view(x.size(0), 1, 28, 28)
# 定义判别器
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(28*28, 1024),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(1024, 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 1),
nn.Sigmoid()
)
def forward(self, x):
return self.model(x.view(x.size(0), 28*28))
# 超参数
batch_size = 64
learning_rate = 0.0002
num_epochs = 50
latent_dim = 100
# 数据加载和预处理
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.5], std=[0.5])
])
dataset = datasets.MNIST(root='./data', train=True, transform=transform, download=True)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
# 初始化模型
generator = Generator()
discriminator = Discriminator()
# 损失函数和优化器
criterion = nn.BCELoss()
optimizer_G = optim.Adam(generator.parameters(), lr=learning_rate)
optimizer_D = optim.Adam(discriminator.parameters(), lr=learning_rate)
# 训练GAN
for epoch in range(num_epochs):
for i, (imgs, _) in enumerate(dataloader):
# 训练判别器
real_labels = torch.ones(batch_size, 1)
fake_labels = torch.zeros(batch_size, 1)
real_imgs = imgs
z = torch.randn(batch_size, latent_dim)
fake_imgs = generator(z)
real_loss = criterion(discriminator(real_imgs), real_labels)
fake_loss = criterion(discriminator(fake_imgs.detach()), fake_labels)
d_loss = real_loss + fake_loss
optimizer_D.zero_grad()
d_loss.backward()
optimizer_D.step()
# 训练生成器
g_loss = criterion(discriminator(fake_imgs), real_labels)
optimizer_G.zero_grad()
g_loss.backward()
optimizer_G.step()
# 打印损失
if i % 100 == 0:
print(f'Epoch [{epoch}/{num_epochs}] Batch [{i}/{len(dataloader)}] Loss D: {d_loss.item()}, Loss G: {g_loss.item()}')
print("Training finished.")GAN的挑战
- 不稳定性:GAN的训练过程容易不稳定,可能会导致生成器或判别器的过拟合或欠拟合。
- 模式崩溃:生成器可能会陷入生成一小部分模式而忽略其他可能的样本,这被称为模式崩溃(mode collapse)。
- 训练难度:需要仔细调整超参数(如学习率、批量大小)和网络结构,以实现平衡的对抗训练。
结论
GAN通过生成器和判别器的对抗训练,能够生成逼真的数据样本。其成功的关键在于两者的对抗过程,使得生成器逐渐学习生成高质量的样本。尽管训练过程具有挑战性,但GAN在图像生成、数据增强、风格迁移等任务中展现了强大的能力。
GAN的输入输出
生成对抗网络(Generative Adversarial Network, GAN)的输入和输出主要围绕生成器(Generator)和判别器(Discriminator)展开。以下是详细的输入输出说明:
生成器(Generator)
输入
- 随机噪声向量(z):
-
- 生成器的输入是一个随机噪声向量,通常从均匀分布或正态分布中采样。
- 这个噪声向量通常是低维的,例如,长度为100的向量。
输出
- 生成的假样本(G(z)):
-
- 生成器的输出是一个与真实数据分布相似的假样本。
- 对于图像生成任务,生成器的输出通常是一个图像,例如28x28像素的MNIST手写数字图像。
判别器(Discriminator)
输入
- 数据样本(x):
-
- 判别器的输入可以是来自真实数据分布的样本(真实样本)或生成器生成的样本(假样本)。
- 对于图像生成任务,输入通常是图像数据。
输出
- 判别概率(D(x)):
-
- 判别器的输出是一个概率值,表示输入样本为真实样本的概率。
- 输出值介于0和1之间,其中接近1表示样本更可能是真实的,接近0表示样本更可能是生成的。
GAN的训练流程
1.训练判别器:
- 输入:真实样本和生成样本。
- 输出:对每个输入样本的判别概率。
- 目标:最大化判别器对真实样本判别为真的概率,同时最小化判别器对生成样本判别为假的概率。
2.训练生成器:
- 输入:随机噪声向量。
- 输出:生成的假样本。
- 目标:生成器希望判别器认为这些生成的假样本是真实的(即最大化判别器对假样本判别为真的概率)。
总结
- 生成器的输入:随机噪声向量,输出为生成的假样本。
- 判别器的输入:数据样本(真实样本或生成样本),输出为样本为真实数据的概率。
- 训练过程:通过交替训练生成器和判别器,实现生成器生成更逼真的样本,判别器提高区分真假样本的能力。
六、目标检测
1.性能指标:IoU、mAP、FPS
在计算机视觉领域,尤其是目标检测和分割任务中,性能指标是评估模型效果和效率的关键。以下是三种常见的性能指标:IoU、mAP和FPS。
1. IoU(Intersection over Union)
IoU是评估目标检测和分割模型精度的指标。它表示预测边界框与真实边界框之间的重叠度。
计算方法
- Intersection:预测边界框与真实边界框的交集区域。
- Union:预测边界框与真实边界框的并集区域。
- IoU公式:[
]
解释
- IoU的取值范围是0到1。
- IoU越接近1,表示预测的边界框与真实边界框的重叠程度越高,检测效果越好。
- 通常在计算平均精度(AP)时,会设定一个IoU阈值,如0.5或0.75,作为正样本的判定标准。
2. mAP(mean Average Precision)
mAP是目标检测任务中常用的综合性能评估指标,它结合了精确率(Precision)和召回率(Recall)。
计算方法
- Precision:正确检测到的目标数 / 检测到的目标总数。
- Recall:正确检测到的目标数 / 真实目标总数。
- AP(Average Precision):
-
- AP是针对每个类别计算的平均精度。
- 通过绘制Precision-Recall曲线,并计算曲线下的面积得到AP。
- mAP公式:[
]其中,(N)是类别总数,(
)是第(i)个类别的平均精度。
解释
- mAP的取值范围是0到1。
- mAP越高,表示模型在所有类别上的检测效果越好。
3. FPS(Frames Per Second)
FPS是衡量目标检测或分割模型处理速度的指标,表示模型每秒能处理的帧数。
计算方法
- FPS公式:[
]
解释
- FPS的值越高,表示模型处理速度越快,适合实时应用。
- 计算FPS时,通常会忽略数据加载和预处理时间,只计算模型前向传播的时间。
4.示例代码
下面是一个示例代码,用于计算IoU、mAP和FPS。
计算IoU
def calculate_iou(boxA, boxB):
# 计算交集
xA = max(boxA[0], boxB[0])
yA = max(boxA[1], boxB[1])
xB = min(boxA[2], boxB[2])
yB = min(boxA[3], boxB[3])
interArea = max(0, xB - xA + 1) * max(0, yB - yA + 1)
# 计算并集
boxAArea = (boxA[2] - boxA[0] + 1) * (boxA[3] - boxA[1] + 1)
boxBArea = (boxB[2] - boxB[0] + 1) * (boxB[3] - boxB[1] + 1)
iou = interArea / float(boxAArea + boxBArea - interArea)
return iou计算mAP(假设已经有预测结果和真实标签)
import numpy as np
def calculate_ap(recall, precision):
# 计算AP
recall = np.concatenate(([0.], recall, [1.]))
precision = np.concatenate(([0.], precision, [0.]))
for i in range(len(precision) - 1, 0, -1):
precision[i - 1] = np.maximum(precision[i - 1], precision[i])
indices = np.where(recall[1:] != recall[:-1])[0]
ap = np.sum((recall[indices + 1] - recall[indices]) * precision[indices + 1])
return ap
def calculate_map(predictions, ground_truths, iou_threshold=0.5):
aps = []
for class_id in range(num_classes):
class_predictions = [p for p in predictions if p[0] == class_id]
class_ground_truths = [g for g in ground_truths if g[0] == class_id]
# Sort by confidence
class_predictions.sort(key=lambda x: x[1], reverse=True)
# Match predictions to ground truths
tp = np.zeros(len(class_predictions))
fp = np.zeros(len(class_predictions))
detected = []
for i, prediction in enumerate(class_predictions):
pred_box = prediction[2:]
max_iou = 0
max_gt_idx = -1
for j, gt in enumerate(class_ground_truths):
if j not in detected:
iou = calculate_iou(pred_box, gt[1:])
if iou > max_iou:
max_iou = iou
max_gt_idx = j
if max_iou >= iou_threshold:
tp[i] = 1
detected.append(max_gt_idx)
else:
fp[i] = 1
# Calculate precision and recall
tp_cumsum = np.cumsum(tp)
fp_cumsum = np.cumsum(fp)
recall = tp_cumsum / len(class_ground_truths)
precision = tp_cumsum / (tp_cumsum + fp_cumsum)
# Calculate AP and append to list
aps.append(calculate_ap(recall, precision))
mAP = np.mean(aps)
return mAP计算FPS
import time
def calculate_fps(model, dataloader):
start_time = time.time()
num_frames = 0
for images, _ in dataloader:
outputs = model(images)
num_frames += images.size(0)
total_time = time.time() - start_time
fps = num_frames / total_time
return fps5.总结
- IoU:用于评估单个检测框的精度。
- mAP:用于评估模型在所有类别上的整体检测效果。
- FPS:用于评估模型的处理速度。
2.一阶段和二阶段算法区别、典型网络举例
一阶段(One-Stage)和二阶段(Two-Stage)算法是目标检测领域中常用的两种不同的方法。它们在处理目标检测任务时有着不同的设计思路和特点。
一阶段算法(One-Stage Algorithms)
一阶段算法指的是直接在单一网络中预测目标的类别和位置。这类算法通常以更简单和直接的方式处理目标检测问题,而且速度较快。典型特点包括:
- 单阶段处理:一次性输出目标框的类别和位置。
- 较高的处理速度:通常比二阶段算法快,适合实时应用。
- 损失函数综合考虑:通常使用综合类别分类损失和边界框回归损失的损失函数。
- 较少的后处理步骤:由于直接输出框,通常不需要复杂的非极大值抑制(NMS)等后处理步骤。
典型的一阶段算法
1.YOLO(You Only Look Once)系列:
- YOLOv1、YOLOv2、YOLOv3等版本。
- 通过将整个图像分成网格,每个网格直接预测多个边界框和类别概率。
- 使用全局损失函数来同时优化位置和类别预测。
2.SSD(Single Shot MultiBox Detector):
- 将不同尺度的特征图用于预测不同大小的边界框。
- 每个特征图位置直接预测类别和位置。
二阶段算法(Two-Stage Algorithms)
二阶段算法则分为两个阶段来处理目标检测任务,首先生成候选区域(region proposal),然后对这些候选区域进行分类和位置调整。虽然通常速度较一阶段算法慢,但在精度上往往更高。
- 两阶段处理:第一阶段生成候选框,第二阶段分类和精细化调整位置。
- 复杂的流程:通常包括候选框生成、特征提取、分类和边界框回归等多个步骤。
- 精细的后处理:需要进行NMS等步骤以合并重叠的预测框。
典型的二阶段算法
1.Faster R-CNN:
- 首先使用区域提议网络(Region Proposal Network, RPN)生成候选框。
- 然后使用这些候选框进行类别分类和边界框回归。
- 使用两个独立的损失函数来优化区域提议和目标检测。
2.Mask R-CNN:
- 在Faster R-CNN的基础上增加了分割(Mask)分支,用于生成精确的目标掩码。
- 依然是二阶段算法,但是在第二阶段增加了分割任务。
总结
- 一阶段算法更简单直接,速度快,适合实时应用,但通常牺牲一定的准确性。
- 二阶段算法通常精度更高,因为它们通过生成候选框和后续处理来更精细地调整预测,但速度相对较慢。
- 选择算法应根据具体应用场景需求(如精度、速度要求)来确定,有时也可以结合使用以取得更好的综合效果。
3.Faster-RCNN的三个网络:特征提取网络、RPN网络、边界框回归和分类网络
Faster R-CNN(Faster Region-CNN)是一种经典的目标检测算法,它在R-CNN和Fast R-CNN的基础上进行了优化,提出了一种端到端的目标检测框架,结合了区域提议网络(Region Proposal Network, RPN)和目标检测网络。下面详细介绍Faster R-CNN的组成和工作原理。
组成部分
1.区域提议网络(RPN):
- Faster R-CNN引入了RPN作为网络的一部分,用于生成候选框(region proposals)。
- RPN通过滑动窗口在特征图上提取候选框,并为每个候选框生成边界框回归和目标/背景分类概率。
2.特征提取网络:
- Faster R-CNN可以使用各种预训练的深度卷积神经网络(如ResNet、VGG等)作为特征提取网络。
- RPN和后续的目标检测网络共享这些特征提取网络的卷积层,以提高计算效率和性能。
3.目标检测网络:
- 在RPN生成候选框后,这些候选框被送入目标检测网络进行进一步的分类和边界框回归。
- Faster R-CNN通常采用RoI池化层(Region of Interest Pooling)来对每个候选框提取固定大小的特征向量,然后送入全连接层进行分类和回归。
工作原理
1.特征提取:
- 输入图像经过特征提取网络(如ResNet),得到一系列特征图。
2.区域提议网络(RPN):
- RPN在特征图上滑动窗口,为每个窗口提取特征并预测多个候选框。
- 对每个候选框,RPN输出其边界框偏移量(用于调整候选框的位置)和目标/背景分类概率。
3.候选框筛选:
- 使用非极大值抑制(NMS)筛选RPN生成的候选框,保留具有高置信度的候选框。
4.目标检测网络:
- 对筛选后的候选框应用RoI池化层,将每个候选框映射成固定大小的特征向量。
- 特征向量经过全连接层,分别预测目标类别(分类)和精细化的边界框位置(回归)。
优点
- 端到端训练:整个Faster R-CNN模型可以端到端地训练,包括特征提取、区域提议和目标检测网络,优化效果更好。
- 高效性:引入RPN使得目标检测过程更加高效,可以快速生成候选框,避免了传统方法中复杂的多步骤流程。
- 准确性:在多个标准数据集上表现出较高的检测精度,特别是对小目标的检测效果较好。
示例代码
以下是一个简化的示例代码,展示了如何使用PyTorch实现Faster R-CNN模型的训练过程:
import torch
import torchvision
from torchvision.models.detection import FasterRCNN
from torchvision.models.detection.rpn import AnchorGenerator
# 使用预训练的ResNet作为特征提取网络
backbone = torchvision.models.resnet50(pretrained=True)
backbone.out_channels = 2048 # ResNet50的输出通道数
# RPN中Anchor的大小和长宽比
anchor_generator = AnchorGenerator(
sizes=((32, 64, 128, 256, 512),),
aspect_ratios=((0.5, 1.0, 2.0),)
)
# RoI Pooling大小
roi_pooler = torchvision.ops.MultiScaleRoIAlign(
featmap_names=['0'],
output_size=7,
sampling_ratio=2
)
# 定义Faster R-CNN模型
model = FasterRCNN(
backbone,
num_classes=91, # COCO数据集中的类别数
rpn_anchor_generator=anchor_generator,
box_roi_pool=roi_pooler
)
# 在COCO数据集上进行训练
# 示例中省略了数据加载和训练循环的具体实现总结
Faster R-CNN通过引入RPN作为区域提议网络,结合目标检测网络实现了更高效和准确的目标检测。它在深度学习目标检测领域有着广泛的应用和影响,为后续目标检测算法的发展奠定了重要基础。
Faster R-CNN(Faster Region-CNN)是一个端到端的目标检测框架,由三个主要部分组成:特征提取网络、区域提议网络(RPN)、以及边界框回归和分类网络。下面详细介绍每个部分的作用和结构。
1. 特征提取网络
特征提取网络主要负责从输入图像中提取高级别的语义特征。这些特征将用于后续的区域提议和目标检测任务。Faster R-CNN可以使用不同的预训练模型作为特征提取网络,例如ResNet、VGG等。
在实现中,通常会使用预训练的深度卷积神经网络,如下所示:
backbone = torchvision.models.resnet50(pretrained=True)这里以ResNet-50为例,该模型经过预训练,能够提供较好的图像特征表达能力。特征提取网络的输出通常是一个特征图,具有较高的通道数和分辨率,这些特征图将用作RPN网络的输入。
2. 区域提议网络(RPN)
区域提议网络(RPN)是Faster R-CNN中的核心组件,负责生成候选框(region proposals)。RPN通过在特征图上滑动不同大小和长宽比的滑动窗口(称为锚框),并预测每个锚框是否包含目标以及如何调整锚框的位置。
RPN的主要任务包括:
- 生成候选框:在特征图上生成大量的锚框。
- 预测边界框回归:为每个锚框预测边界框的调整量,用于修正锚框位置以更准确地拟合目标。
- 目标/背景分类:为每个锚框预测其包含目标的概率。
在Faster R-CNN中,RPN与特征提取网络共享卷积层的输出,这样可以减少计算开销,并且提高模型的效率和速度。
3. 边界框回归和分类网络
在区域提议生成后,通过RoI池化(Region of Interest Pooling)将每个候选框映射成固定大小的特征向量。然后,这些特征向量经过全连接层进行目标的分类和精细化的边界框回归。
具体来说,这个网络会:
- RoI池化:将每个候选框映射为固定大小的特征向量,保证所有的RoI(Region of Interest)特征具有相同的空间维度。
- 分类:使用全连接层对RoI进行分类,预测每个候选框的类别。
- 边界框回归:同样使用全连接层来预测每个候选框的精细化边界框调整量,以更准确地框出目标的位置。
这三个网络在Faster R-CNN中的协作使得模型能够快速且准确地检测图像中的目标,适用于多种复杂场景下的目标检测任务。
总结
Faster R-CNN通过特征提取网络、RPN网络和边界框回归和分类网络的组合,实现了高效和准确的目标检测。这种结构的设计使得模型在处理复杂场景和大规模数据时具有优秀的性能和鲁棒性。
4.SPP、Rol池化的定义(综合题)
SPP(Spatial Pyramid Pooling)和 RoI(Region of Interest)池化都是用于解决目标检测和图像分割任务中的特征提取问题的技术。
SPP(Spatial Pyramid Pooling)
SPP池化是一种用于解决不同尺度输入图像的尺寸问题的方法,它允许具有不同尺寸的输入图像在经过卷积神经网络(CNN)提取特征后能够生成固定大小的特征表示。
定义和作用
SPP池化的主要作用是将不同尺寸的特征图映射为固定长度的特征向量,而不需要调整输入图像的大小。这在目标检测中特别有用,因为检测到的目标可能在不同的尺度下具有不同的大小,SPP池化可以使得模型对于这些变化具有一定的鲁棒性。
工作原理
典型的SPP池化操作分为以下步骤:
- 输入特征图:给定一个输入特征图,通常来自于卷积神经网络的输出。
- 分层池化:将输入特征图分成不同的网格,并对每个网格执行池化操作。不同的是,SPP池化会在不同的尺度上执行池化操作,这些尺度通常是由网络预定义的。
- 汇总特征:将每个分层池化的结果串联起来,形成一个固定长度的特征向量。这样,无论输入图像的尺寸如何,都可以得到相同长度的特征向量。
RoI(Region of Interest)池化
RoI池化是一种用于处理不同大小的候选框(或称为区域)的池化技术,通常用于目标检测和图像分割任务中。
定义和作用
RoI池化的主要作用是对于每个不同大小的候选框(RoI),从特征图中提取固定大小的特征表示。这样做的好处是,在进行分类和边界框回归时,每个RoI都能够产生固定长度的特征向量,从而能够方便地连接到后续的全连接层进行分类或回归。
工作原理
RoI池化操作通常包括以下步骤:
- 输入特征图:从卷积神经网络(如Faster R-CNN中的特征提取网络)获取特征图。
- RoI输入:给定一组候选框(RoI),RoI池化会将每个RoI映射到特征图上,并对其进行池化操作。
- 池化操作:对于每个RoI,根据其在特征图上的位置和大小,执行池化操作(如最大池化),将RoI映射为固定大小的输出特征。
- 输出特征向量:将每个RoI池化的结果串联起来,形成一个固定长度的特征向量序列,作为后续分类或回归模型的输入。
总结
- SPP池化适用于解决不同尺寸输入图像的尺寸问题,允许CNN生成固定大小的特征表示。
- RoI池化则是用于处理不同大小的候选框,将每个RoI映射为固定长度的特征向量,以便后续的分类或回归任务。这两种池化技术在提升目标检测和图像分割模型性能中发挥了重要作用。
5.yolov3,输入416*416的图像,batchsize=8,20个类别,三个输出特征图尺寸计算
YOLOv3 的特征图尺寸计算与卷积神经网络的层级结构密切相关。具体来说,YOLOv3 通过多次卷积、池化等操作,逐步减少特征图的尺寸,最终生成三个不同尺度的特征图用于检测不同大小的目标。以下是详细的计算过程和解释。
1. YOLOv3 基础网络
YOLOv3 使用了一个类似于 Darknet-53 的骨干网络,这个网络包括多层卷积层,每层卷积层会对输入的特征图进行下采样(即减少分辨率)。每次下采样的操作通常是通过卷积层的步幅(stride)为 2 来实现的。
2. 特征图尺寸计算
输入图像尺寸
输入图像尺寸为 416x416 像素。
主要的卷积层和步幅
在 YOLOv3 的架构中,通常会进行 5 次下采样操作。每次下采样操作会将特征图的尺寸减少一半。以下是具体的下采样步骤:
- 输入图像尺寸:416x416
- 第一次下采样:通过卷积层(stride=2),特征图尺寸变为 208x208
- 第二次下采样:特征图尺寸变为 104x104
- 第三次下采样:特征图尺寸变为 52x52
- 第四次下采样:特征图尺寸变为 26x26
- 第五次下采样:特征图尺寸变为 13x13
特征图的生成
YOLOv3 使用这三个不同尺度的特征图来进行目标检测:
- 大尺度特征图(用于检测大目标):13x13
- 中尺度特征图(用于检测中等目标):26x26
- 小尺度特征图(用于检测小目标):52x52
3. 特征图尺寸计算公式
对于一个给定的输入图像,卷积操作之后的输出尺寸 ( W_{\text{out}} ) 和 ( H_{\text{out}} ) 可以通过以下公式计算:

其中:

YOLOv3 的卷积层大多使用 3x3 的卷积核和 stride=2 进行下采样。
4. 具体示例
以 YOLOv3 中一个典型的层为例:
- 输入图像尺寸:416x416
- 第一次卷积(3x3, stride=2):输出尺寸 208x208
- 第二次卷积(3x3, stride=2):输出尺寸 104x104
- 第三次卷积(3x3, stride=2):输出尺寸 52x52
- 第四次卷积(3x3, stride=2):输出尺寸 26x26
- 第五次卷积(3x3, stride=2):输出尺寸 13x13
5.总结
对于 YOLOv3 输入图像为 416x416,特征图的尺寸计算如下:
- 大特征图:13x13
- 中特征图:26x26
- 小特征图:52x52
这些特征图用于检测不同尺度的目标,确保 YOLOv3 在处理多种尺寸目标时具有较高的准确性和鲁棒性。
6.掌握一种目标检测算法的完整检测流程(综合题)
YOLO(You Only Look Once)是一个统一的目标检测算法,它将目标检测问题视为单个回归问题,从图像像素到边界框坐标和类别概率。完整的检测流程如下:
1. 输入预处理
- 图像缩放:将输入图像调整到网络所需的固定尺寸(如YOLOv3是416x416)。
- 归一化:将像素值归一化到[0, 1]范围内。
- 批量处理:将图像打包成批次输入到网络中。
2. 网络架构
- 卷积层:YOLO使用一系列卷积层来提取特征。YOLOv3使用Darknet-53作为其骨干网络,这是一种53层的卷积神经网络。
- 检测层:在特定层上进行检测,生成预测。YOLOv3有三个检测层,分别在不同的尺度上进行检测,适用于检测不同大小的目标。
3. 输出预测

4. 解码预测
- 边界框坐标:将网络输出的边界框坐标从相对值转换为绝对值。
- 置信度阈值:筛选出置信度低于某一阈值的预测。
- 非极大值抑制(NMS):去除重叠过多的边界框,只保留最高置信度的边界框。
5. 最终输出
- 目标类别:每个保留的边界框预测一个目标类别及其概率。
- 边界框位置:每个保留的边界框的位置在原图像上的绝对坐标。
6.具体流程图解
- 输入图像:一个(
)的RGB图像。
- 特征提取:通过Darknet-53骨干网络提取特征。
- 检测层预测:在不同尺度上进行预测,生成三个不同大小的输出张量。
- 解码预测:将网格坐标转换为图像上的边界框坐标。
- 置信度筛选:筛选出置信度低于阈值的边界框。
- 非极大值抑制:去除重叠的边界框,保留最高置信度的边界框。
- 输出结果:包含边界框、目标类别和置信度的最终检测结果。
通过以上步骤,YOLO可以高效地完成目标检测任务,实现对图像中目标的定位和分类。
YOLO(You Only Look Once)是一种高效的目标检测算法,其主要思想是将目标检测问题视为一个单一的回归问题,从而实现端到端的训练和推理。YOLOv3 是该系列算法的一个版本,具有高效且准确的目标检测性能。以下是 YOLO 检测算法的完整检测流程。
YOLO 检测流程
1.输入图像预处理
- 输入图像被调整为固定大小(例如 416x416),以适应网络的输入要求。
- 归一化处理,将像素值缩放到 [0, 1] 范围内。
- 图像进行批次处理(batch processing),如 batch size = 8。
2.特征提取
- 使用一个深度卷积神经网络(如 Darknet-53)对输入图像进行特征提取。
- 卷积操作在不同尺度上生成特征图。
- 共享卷积层,减少计算量,提高效率。
3.多尺度特征图生成
- YOLOv3 在三个不同尺度上生成特征图,以检测不同大小的目标。
- 这些特征图的尺寸通常为 13x13、26x26 和 52x52。
- 特征图的尺寸是通过多次卷积和下采样操作得到的。
4.预测生成
- 在每个尺度的特征图上进行预测。
- 每个单元格(grid cell)生成多个边界框预测(通常每个单元格生成 3 个预测框)。
- 每个预测框包含以下信息:
-
- 边界框的位置(x, y, w, h):中心坐标(x, y)以及宽度和高度(w, h)。
- 置信度分数(confidence score):表示该边界框包含目标的概率。
- 类别概率分布:表示该边界框所包含目标的具体类别的概率分布(对于 20 个类别,每个框会有 20 个概率值)。
5.边界框调整
- 使用锚框(anchor boxes)来预测边界框的形状和大小。
- 通过网络学习到的调整参数对锚框进行调整,以得到更精确的目标位置。
6.筛选和后处理
- 根据置信度分数和类别概率分布,筛选出高置信度的预测框。
- 应用非极大值抑制(Non-Maximum Suppression, NMS)算法,删除重叠较大的框,保留最优的检测结果。
7.输出结果
- 最终输出包含检测到的目标类别、边界框位置和置信度分数。
YOLOv3 具体检测流程示例
以下是使用 PyTorch 和 YOLOv3 实现检测流程的示例代码:
import torch
import torchvision
from torchvision.transforms import functional as F
from PIL import Image
import numpy as np
# 加载预训练的 YOLOv3 模型
model = torchvision.models.detection.yolov3(pretrained=True)
model.eval()
# 加载并预处理输入图像
def load_image(image_path):
image = Image.open(image_path).convert("RGB")
image = image.resize((416, 416))
image = F.to_tensor(image)
image = image.unsqueeze(0) # 增加 batch 维度
return image
image_path = 'path_to_your_image.jpg'
input_image = load_image(image_path)
# 执行目标检测
with torch.no_grad():
detections = model(input_image)
# 解析检测结果
def parse_detections(detections, threshold=0.5):
# 假设 batch size 为 1
detections = detections[0]
results = []
for detection in detections:Fast R-CNN检测流程
1. 输入图像与特征提取
- 输入图像:
-
- 给定一张输入图像,通常是RGB彩色图像。
- 特征提取:
-
- 使用预训练的卷积神经网络(例如VGG16、ResNet等)来提取输入图像的特征。
- 特征提取网络由多个卷积层和池化层组成,用于捕捉图像的空间特征和语义信息。
- 输出是一个低分辨率但高维度的特征图,表示输入图像的特征表示。
2. 区域提议(Region Proposals)
- 输入特征图:
-
- 从特征提取网络获得的特征图。
- 外部区域提议算法:
-
- 使用选择性搜索(Selective Search)等算法生成一组候选区域(Region Proposals)。
- 选择性搜索通过将图像分割成若干个候选区域,再将这些区域合并,生成多个不同尺度和宽高比的候选框。
- 通常生成2000个左右的候选区域。
3. RoI池化(RoI Pooling)
- 输入特征图和区域提议:
-
- 将特征提取网络的特征图和生成的候选区域提议输入到RoI池化层。
- 固定大小特征图:
-
- RoI池化将每个区域提议映射到特征图上,并裁剪对应的区域,调整为固定大小的特征图(例如7x7)。
- 具体方法是将每个候选区域划分为固定数量的网格(例如7x7),然后在每个网格中进行最大池化操作,从而输出固定大小的特征图。
4. 全连接层与分类和回归
- 全连接层:
-
- 固定大小的特征图通过一系列全连接层,进一步提取高层次特征。
- 这些全连接层可以是全连接层(fully connected layers)或全连接层的变种(例如,全局平均池化)。
- 分类层:
-
- 输出每个候选区域所属的类别(包括目标类别和背景)。
- 这是一个多分类任务,使用Softmax函数进行分类。
- 边界框回归层:
-
- 输出每个候选区域的边界框修正参数(通常是4个参数:dx, dy, dw, dh)。
- 这是一个回归任务,用于精确调整候选区域的边界框位置和大小。
5. 损失函数
- 分类损失:
-
- 使用交叉熵损失函数来衡量分类结果的准确性。
- 分类损失公式:[
]其中,(p)是分类概率,(u)是真实类别标签。
- 回归损失:
-
- 使用平滑L1损失函数来衡量边界框回归结果的准确性。
- 回归损失公式:[
]其中,(t)是预测的边界框参数,(v)是真实的边界框参数。
- 总损失:
-
- 分类损失和回归损失的加权和。
- 总损失公式:[
]其中,(
)是权重参数,[
]表示只有在u是目标类别时计算回归损失。
6. 训练与优化
- 联合训练:
-
- Fast R-CNN采用联合训练的方法,通过反向传播同时优化分类和回归任务的参数。
- 使用标准的反向传播算法更新网络权重。
- 优化器:
-
- 通常使用随机梯度下降(SGD)等优化器来最小化总损失函数,从而更新网络权重。
- 优化过程包括学习率设定、权重衰减和动量等技术。
7. 预测与后处理
- 分类结果和边界框:
-
- 训练好的模型对输入图像进行检测,输出候选区域的类别概率和修正后的边界框。
- 每个候选区域都有一个分类概率和对应的边界框位置。
- 非极大值抑制(NMS):
-
- 对检测结果进行非极大值抑制,去除重叠的检测框,只保留置信度较高的检测结果。
- NMS过程:按置信度排序,选择最高的检测框,移除与其重叠度超过阈值的其他检测框,重复此过程直到没有重叠度超过阈值的检测框。
8.总结
Fast R-CNN通过引入RoI池化层,将区域提议和检测步骤有效地结合在一个网络中,极大地提高了检测速度和精度。其主要创新在于在共享特征图上对候选区域进行池化和分类回归,从而避免了重复计算,提高了检测效率。
超参数
在神经网络和深度学习中,超参数(hyperparameters)是指在训练过程中需要预先设定的参数,而非通过训练数据学习得到的参数(如权重和偏置)。选择合适的超参数对模型的性能有重大影响。以下是一些常见的神经网络超参数及其作用:
1. 学习率(Learning Rate)
- 作用:控制每次参数更新的步长。
- 影响:学习率过高可能导致模型训练不稳定,学习率过低则会导致训练速度慢或陷入局部最优解。
- 调优策略:使用学习率衰减、学习率调度或自适应学习率算法(如Adam)。
2. 批大小(Batch Size)
- 作用:每次更新权重所使用的训练样本数量。
- 影响:较大的批大小可以提高训练稳定性,但需要更多的内存。较小的批大小可以使模型更快地更新,但可能会增加训练噪声。
- 调优策略:根据可用硬件资源进行调整,一般在32到512之间。
3. 优化器(Optimizer)
- 作用:决定如何更新网络的权重参数。
- 常用优化器:SGD(随机梯度下降)、Adam(自适应矩估计)、RMSprop等。
- 影响:不同优化器适用于不同类型的问题和数据集。
- 调优策略:根据具体任务选择合适的优化器,并调整其超参数(如Adam的β参数)。
4. 激活函数(Activation Function)
- 作用:决定每个神经元的输出。
- 常用激活函数:ReLU、Sigmoid、Tanh、Leaky ReLU等。
- 影响:激活函数的选择会影响梯度传播和模型收敛速度。
- 调优策略:根据任务性质选择合适的激活函数。
5. 正则化参数(Regularization Parameters)
- 作用:防止模型过拟合。
- 常用正则化方法:L1正则化、L2正则化、Dropout等。
- 影响:正则化强度过大会导致欠拟合,过小则不能有效防止过拟合。
- 调优策略:通过验证集调整正则化系数。
6. 隐藏层数和每层神经元数量(Number of Hidden Layers and Neurons per Layer)
- 作用:决定神经网络的深度和复杂度。
- 影响:更多的隐藏层和神经元可以增加模型的表示能力,但也会增加计算复杂度和过拟合风险。
- 调优策略:从简单结构开始,逐渐增加复杂度,并通过验证集评估性能。
7. 学习率衰减(Learning Rate Decay)
- 作用:在训练过程中逐渐降低学习率。
- 常用策略:Step Decay、Exponential Decay、Cosine Annealing等。
- 影响:有助于模型在接近最优解时进行更精细的参数调整。
- 调优策略:选择合适的衰减策略和参数。
8. Early Stopping
- 作用:在验证集性能不再提升时提前停止训练。
- 影响:防止过拟合并减少训练时间。
- 调优策略:设置合适的监控指标和耐心参数(patience)。
9. 动量(Momentum)
- 作用:加速SGD的收敛速度,通过积累过去梯度的动量来更新参数。
- 常用值:一般在0.9左右。
- 调优策略:根据具体任务和数据集进行调整。
10. Weight Initialization
- 作用:决定网络权重的初始值。
- 常用方法:Xavier初始化、He初始化等。
- 影响:影响训练的稳定性和收敛速度。
- 调优策略:根据激活函数选择合适的初始化方法。
11. 权重衰减(Weight Decay)
- 作用:一种正则化方法,防止权重过大。
- 影响:类似L2正则化,影响过拟合程度。
- 调优策略:通过验证集调整权重衰减系数。
12. 数据增强(Data Augmentation)
- 作用:通过对训练数据进行各种变换(如旋转、平移、缩放等)来增加数据量。
- 影响:防止过拟合,提高模型的泛化能力。
- 调优策略:选择合适的增强策略和参数。
13.总结
选择和调整神经网络的超参数是训练深度学习模型中的关键步骤。不同的任务和数据集可能需要不同的超参数设置,通过实验和验证集性能评估,可以找到适合特定任务的最佳超参数配置。
Faster R-CNN
Faster R-CNN(Region-based Convolutional Neural Networks)是一种先进的目标检测算法,结合了区域建议网络(RPN)和Fast R-CNN,实现了高效的目标检测。其主要流程如下:
1.输入图像:
- 将输入图像送入卷积神经网络(通常是预训练的深度卷积神经网络,如VGG、ResNet)以提取特征映射。
2.特征提取:
- 使用卷积神经网络的前几层来提取图像的特征映射。这些特征映射将用于后续的区域建议和目标检测。
3.区域建议网络(RPN):
- RPN在特征映射上滑动,通过一个小网络来生成区域建议。每个滑动窗口会生成一组建议边界框(anchors),并预测这些框是否包含目标及其精确位置。
- RPN的输出包括一组建议框及其对应的得分(目标存在的概率)。
4.候选区域生成:
- 从RPN生成的建议框中选择前N个最高分的框,经过非极大值抑制(NMS)处理,以减少冗余重叠的框。
5.ROI Pooling(区域兴趣池化):
- 将建议的区域映射回特征映射,并使用ROI Pooling层将每个建议区域调整为相同的大小。这一步将不同大小的建议框变换为固定大小的特征,便于后续的全连接层处理。
6.分类和回归:
- 经过ROI Pooling的特征区域被送入一系列全连接层,用于分类和边界框回归。
- 分类器会预测每个建议框的类别(包括背景类),回归器会进一步精确调整每个建议框的位置。
7.输出结果:
- 最终输出目标类别和精确的边界框坐标。
下面是Faster R-CNN的简化流程图:
输入图像 → 卷积神经网络(特征提取) → 特征映射 → RPN(生成区域建议) → ROI Pooling → 分类与回归 → 输出结果更详细的技术细节
1.RPN网络:
- RPN通过一个3x3的滑动窗口在特征映射上滑动,每个滑动窗口输出多个anchor。
- 对每个anchor进行二分类(目标/非目标)和边界框回归,生成候选区域。
2.Anchor生成:
- RPN生成的anchors通常有不同的尺寸和长宽比,覆盖不同大小和形状的目标。
3.损失函数:
- Faster R-CNN的训练包括两部分损失:RPN的损失和Fast R-CNN部分的损失。
- RPN损失包括分类损失和回归损失。Fast R-CNN的损失也是如此。
通过将RPN和Fast R-CNN结合在一起,Faster R-CNN大大提高了目标检测的速度和精度。
通过将RPN和Fast R-CNN结合在一起,Faster R-CNN大大提高了目标检测的速度和精度。
以下是Faster R-CNN检测流程的详细说明:
1. 输入图像
输入图像首先通过一个预训练的卷积神经网络(如VGG、ResNet等),用来提取特征映射。
2. 特征提取
使用卷积神经网络的前几层来提取图像的特征映射。这些特征映射将用于后续的区域建议和目标检测。
3. 区域建议网络(RPN)
RPN是Faster R-CNN的关键组成部分,负责生成候选区域(即感兴趣区域,RoI)。具体流程如下:
- 滑动窗口:在特征映射上使用一个固定大小的滑动窗口(通常是3x3)进行滑动。
- Anchor生成:每个滑动窗口生成一组称为anchor的候选框。这些anchor具有不同的尺度和宽高比(例如3种尺度和3种宽高比,共9个anchor)。
- 特征映射:滑动窗口区域内的特征通过一个小的神经网络(通常是两个1x1卷积层)来生成两个输出:一个是分类层,用于判断该anchor是否包含目标;另一个是回归层,用于调整anchor的边界框坐标。
- 分类和回归:分类层输出每个anchor是否包含目标的概率,回归层输出anchor的精确坐标修正。
- 非极大值抑制(NMS):为了减少冗余和重叠的候选框,对所有生成的anchor进行NMS,保留得分最高的一部分anchor(例如2000个)。
4. 候选区域生成
RPN输出的高分候选区域作为检测器的输入。这些候选区域是目标可能存在的区域。
5. ROI Pooling(区域兴趣池化)
将建议的区域(候选框)映射回特征映射,并使用ROI Pooling层将每个建议区域调整为相同的大小。这一步将不同大小的候选框变换为固定大小的特征,以便后续的全连接层处理。
6. 分类和回归
- 全连接层:经过ROI Pooling的特征区域被送入一系列全连接层,用于进一步处理。
- 分类器:全连接层之后的分类器会对每个候选区域进行分类,预测目标类别(包括背景类)。
- 回归器:同时,回归器会进一步调整每个候选区域的边界框坐标,提高定位精度。
7. 输出结果
最终输出目标类别和精确的边界框坐标。通常会使用另一次非极大值抑制来去除重叠的检测结果,得到最终的目标检测结果。
8.损失函数
Faster R-CNN的训练损失函数包括两个部分:
1.RPN损失:
- 分类损失:二分类损失,判断anchor是否包含目标。
- 回归损失:平滑L1损失,调整anchor的边界框坐标。
2.Fast R-CNN损失:
- 分类损失:多分类损失,判断候选区域的目标类别。
- 回归损失:平滑L1损失,进一步调整候选区域的边界框坐标。
9.总结
Faster R-CNN通过结合区域建议网络(RPN)和Fast R-CNN,实现了从图像到目标检测结果的高效流程。具体流程如下:
- 输入图像→ 2.特征提取→ 3.区域建议网络(RPN)→ 4.候选区域生成→ 5.ROI Pooling(区域兴趣池化)→ 6.分类和回归→ 7.输出结果
通过这个流程,Faster R-CNN能够在保持高精度的同时,实现较快的检测速度。
特征图计算
当一个大小为 () 的特征图通过一个 (
) 的卷积核进行卷积时,输出特征图的空间维度(宽度和高度)将取决于卷积的步长(stride)和填充(padding)的设置。以下是不同设置下的详细计算过程:
1. 无填充(Valid Padding)
无填充意味着在进行卷积时,不会在输入特征图的边界上添加额外的像素。卷积核只能在输入特征图的内部滑动,这会导致输出特征图的空间维度减少。

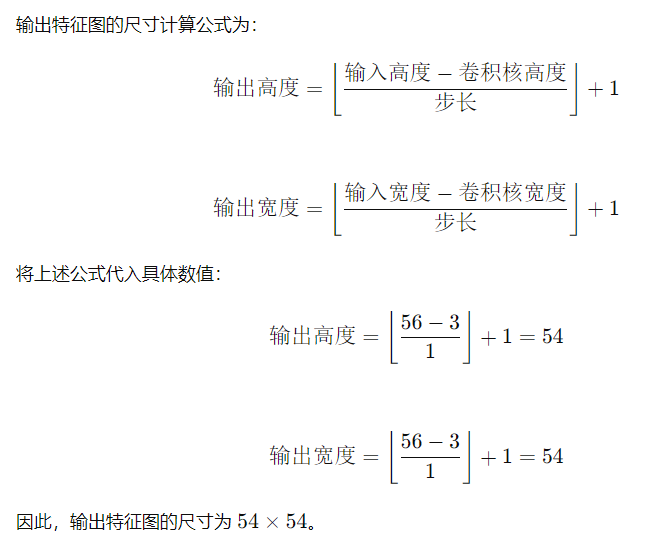
2. 填充(Same Padding)
填充意味着在输入特征图的边界上添加适当数量的像素,以确保输出特征图的空间维度与输入特征图相同。通常填充的像素数为 (卷积核尺寸-1) 的一半。


3. 其他填充和步长设置

4.总结

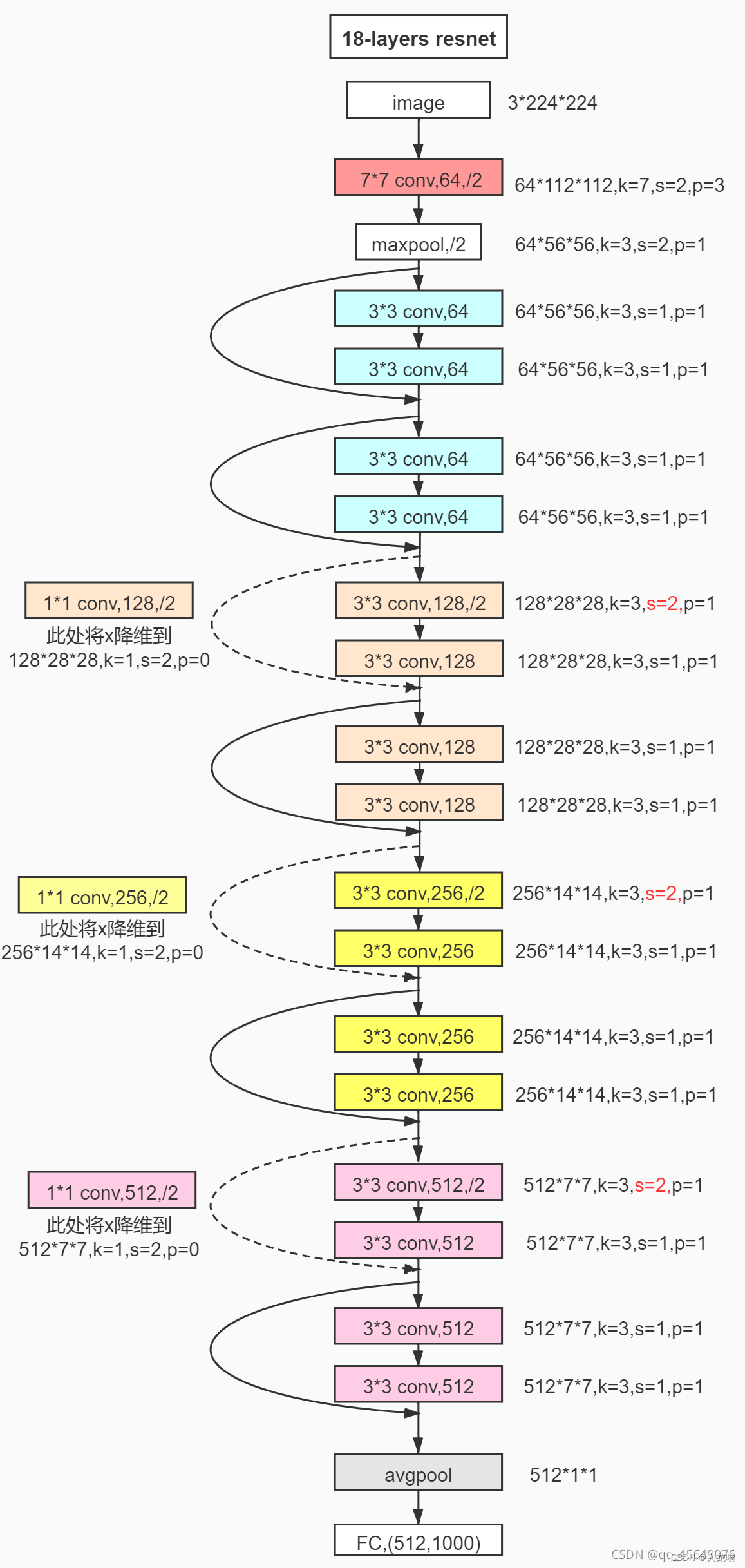
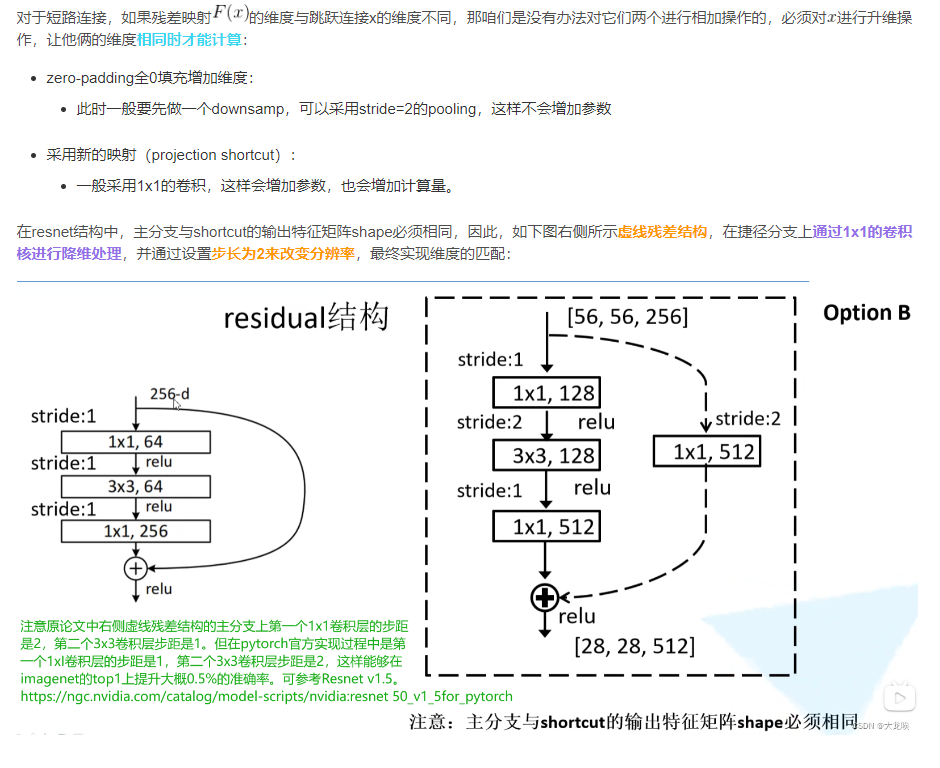
56*56*256不能直接加上,因为维度不同,经过1*1*512卷积降维再相加。下图加残差的时候也要观察是否要降维
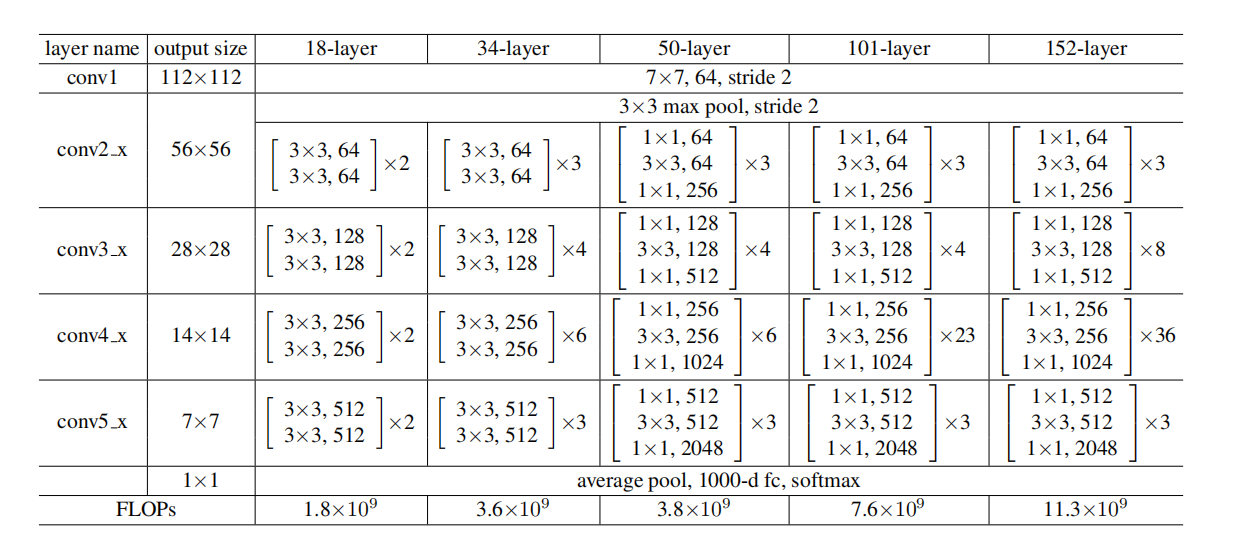
YOLOv1
YOLOv1(You Only Look Once)是由Joseph Redmon等人在2016年提出的一种实时目标检测方法。与之前的区域提议(Region Proposal)方法不同,YOLO将目标检测问题视为一个回归问题,从而在单次前向传播中同时预测物体的类别和边界框位置。以下是YOLOv1的关键概念和特点:
1. 网络结构
- 输入:YOLOv1接受固定大小的输入图像(如448x448像素)。
- 卷积层:由一系列卷积层和池化层组成的深度卷积神经网络,用于提取图像特征。
- 全连接层:将卷积层提取的特征通过全连接层映射到输出层,用于预测物体类别和边界框。
2. 输出表示
- S x S网格:将输入图像划分为SxS的网格(通常是7x7)。每个网格单元负责预测其中心落在该单元内的物体。
- 预测向量:每个网格单元预测B个边界框(通常是2个),以及每个边界框的置信度。预测向量包括:
-
- 边界框的坐标(x, y, w, h):x和y表示边界框中心相对于网格单元的偏移量,w和h表示边界框的宽度和高度。
- 置信度分数:表示边界框包含物体的概率以及边界框与物体的重叠程度(IoU)。
- C个类别概率:表示该网格单元包含的物体属于每个类别的概率。
3. 损失函数
- 均方误差(MSE):YOLOv1使用均方误差作为损失函数,对预测的边界框坐标、置信度分数和类别概率进行优化。
- 权重系数:为了解决边界框预测中的不平衡问题,损失函数中引入了不同的权重系数,如边界框坐标的损失和置信度的损失权重。
4. 优点
- 实时性:YOLOv1在单次前向传播中完成预测,速度快,适合实时应用。
- 全局推理:YOLOv1在预测过程中考虑了全局上下文信息,有助于减少背景误检。
5. 缺点
- 位置预测精度:由于每个网格单元只能预测固定数量的边界框,YOLOv1在处理小物体或密集物体时表现不佳。
- 空间约束:每个网格单元只能预测有限数量的类别和边界框,限制了其在复杂场景中的表现。
- 低分辨率特征图:特征图的分辨率较低,影响小物体的检测性能。
6.应用与影响
YOLOv1的提出开创了实时目标检测的新方向,随后版本(如YOLOv2、YOLOv3、YOLOv4、YOLOv5等)在其基础上进行了改进,进一步提高了检测精度和速度。在实际应用中,YOLO及其改进版本被广泛应用于自动驾驶、监控系统、人脸识别等领域。
YOLOv2
YOLOv2(You Only Look Once, Version 2)是YOLO系列的改进版本,由Joseph Redmon和Ali Farhadi于2016年提出。YOLOv2在YOLOv1的基础上进行了多项改进,以提高目标检测的准确性和速度。以下是YOLOv2的关键特点和改进:
1. 改进的网络结构
- Darknet-19:
-
- YOLOv2使用一种称为Darknet-19的网络架构,包含19个卷积层和5个最大池化层。这个网络比YOLOv1的架构更深、更复杂,能够提取更丰富的特征。
2. 训练技巧
- 批归一化(Batch Normalization):
-
- 在每一层后面加入批归一化,显著提升了模型的稳定性和收敛速度,并且提高了检测准确性。
- 高分辨率分类预训练:
-
- 在训练目标检测任务之前,先在高分辨率图像上进行分类预训练,然后再进行目标检测的微调。这种策略有助于模型学习到更精细的特征。
3. 锚框(Anchor Boxes)
- 使用锚框(Anchor Boxes):
-
- YOLOv2借鉴了Faster R-CNN的锚框机制,在网络训练和推理过程中使用预定义的边界框。这使得模型可以预测更准确和灵活的边界框。
- K-means聚类:
-
- 使用K-means聚类分析训练数据中的边界框尺寸,选择合适的锚框尺寸。这种方法使得模型能够更好地适应不同数据集的特征,提高了检测精度。
4. 多尺度训练
- 多尺度训练:
-
- 在训练过程中,YOLOv2每隔几个批次就随机选择不同的输入分辨率(320×320到608×608之间)。这种多尺度训练方法使得模型可以在不同分辨率下进行推理,从而提高了模型的鲁棒性和检测能力。
5. 改进的预测
- 直接定位预测:
-
- YOLOv2采用了一种新的边界框预测方法,通过预测相对于网格单元边界的偏移量,直接定位物体位置。这种方法比YOLOv1的中心点预测更加稳定和准确。
6. 分类和检测联合训练
- 分类和检测联合训练:
-
- 在目标检测任务的微调阶段,YOLOv2引入了分类数据,进行联合训练。这种策略利用了更多的标注数据,提高了模型的泛化能力。
7. Softmax替代
- 使用Logistic回归替代Softmax:
-
- YOLOv2在多标签分类问题中,使用多个独立的logistic分类器来预测每个类的存在概率,而不是使用softmax。这种方法允许同一个边界框预测多个类别,提高了多标签分类的表现。
8.总结
YOLOv2通过一系列结构和训练策略的改进,大大提升了目标检测的性能。相比YOLOv1,YOLOv2在速度和精度上都有显著提升,使其更加适用于实际应用中的实时目标检测任务。这些改进也为后续的YOLO版本(如YOLOv3、YOLOv4等)奠定了坚实的基础。
YOLOv3
YOLOv3(You Only Look Once, Version 3)是YOLO系列的第三个版本,由Joseph Redmon和Ali Farhadi于2018年提出。YOLOv3在YOLOv2的基础上进行了进一步的改进和优化,以提高检测精度和速度。以下是YOLOv3的关键特点和改进:
1. 改进的网络结构
- Darknet-53:
-
- YOLOv3使用了一种称为Darknet-53的网络架构,包含53个卷积层和一些残差块(Residual Blocks)。这种结构结合了残差网络(ResNet)的思想,使得模型更深、更强大,同时能够更好地进行梯度传递。
2. 多尺度预测
- 多尺度特征图预测:
-
- YOLOv3在不同尺度的特征图上进行预测,以更好地检测不同大小的物体。具体来说,YOLOv3在三个不同的尺度上进行检测:
-
-
- 原始特征图
- 下采样2倍的特征图
- 下采样4倍的特征图
-
-
- 这种多尺度预测方法使得YOLOv3能够更好地检测小物体、中等大小的物体和大物体。
3. 锚框(Anchor Boxes)
- 更好的锚框设计:
-
- YOLOv3继续使用YOLOv2的锚框机制,并通过K-means聚类分析训练数据中的边界框尺寸来选择合适的锚框。YOLOv3在每个尺度上使用不同的锚框,使得每个尺度都能更好地适应特定大小的物体。
4. 分类和检测
- 多标签分类:
-
- YOLOv3在多标签分类问题中,使用多个独立的logistic分类器来预测每个类的存在概率,而不是使用softmax。这种方法允许同一个边界框预测多个类别,提高了多标签分类的表现。
5. 预测机制
- 更细致的预测:
-
- YOLOv3在每个锚框上预测4个边界框坐标(tx, ty, tw, th)、一个置信度分数(objectness score)和每个类别的存在概率。这些预测通过sigmoid函数进行归一化,使得预测更加平滑和稳定。
6. 损失函数
- 改进的损失函数:
-
- YOLOv3在计算损失时,采用了新的边界框预测方法,通过预测相对于网格单元边界的偏移量,直接定位物体位置。这种方法比YOLOv1和YOLOv2的中心点预测更加稳定和准确。
7. 训练技巧
- 训练技巧:
-
- YOLOv3使用了一些新的训练技巧和超参数调整方法,以提高模型的训练效果和泛化能力。这包括更好的学习率调度策略、数据增强方法以及更高效的批处理技术。
8. 性能提升
- 精度和速度的平衡:
-
- YOLOv3在精度和速度之间取得了良好的平衡。在COCO数据集上的性能测试中,YOLOv3表现出色,能够在保持高速检测的同时,实现较高的检测精度。
9.总结
YOLOv3通过一系列结构和训练策略的改进,大大提升了目标检测的性能。相比YOLOv2,YOLOv3在速度和精度上都有显著提升,使其更加适用于实际应用中的实时目标检测任务。这些改进也为后续的YOLO版本(如YOLOv4、YOLOv5等)奠定了坚实的基础。
YOLOv5
YOLOv5(You Only Look Once, Version 5)是YOLO系列中的一个重要版本,由Ultralytics团队在2020年发布。YOLOv5的发布引起了广泛关注,因为它在保持高效的同时进一步提升了目标检测的性能。以下是YOLOv5的关键特点和改进:
1. 模型架构
- CSPDarknet53 Backbone:
-
- YOLOv5使用了CSPDarknet53(Cross Stage Partial Darknet53)作为主干网络。这种架构在特征提取过程中引入了跨阶段部分连接,减少了计算量并提高了模型的表现。
2. 锚框(Anchor Boxes)
- 自动锚框生成:
-
- YOLOv5使用K-means聚类算法自动生成锚框,以适应不同数据集的目标尺寸。这使得模型能够更好地处理各种类型的目标。
3. 多尺度预测
- 多尺度特征图预测:
-
- YOLOv5在三个不同尺度的特征图上进行检测,以提高对不同大小物体的检测能力。这种多尺度预测方法与YOLOv3类似,但在实现上进行了优化。
4. 数据增强
- Mosaic数据增强:
-
- YOLOv5引入了Mosaic数据增强技术,通过将四张图像拼接成一张,增强训练数据的多样性,提高模型的泛化能力。
- 自动混合精度训练:
-
- YOLOv5支持自动混合精度训练,利用半精度浮点数(FP16)进行计算,减少显存占用,提高训练速度。
5. 损失函数和优化
- 新的损失函数:
-
- YOLOv5采用了新的损失函数设计,结合了目标定位损失(CIoU)、分类损失和置信度损失,提高了模型的收敛速度和准确性。
6. 可解释性和易用性
- 开箱即用:
-
- YOLOv5提供了丰富的文档和教程,易于上手,并且支持直接在PyTorch中进行训练和推理。
- 模型尺寸:
-
- YOLOv5提供了不同尺寸的模型(YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x),用户可以根据具体需求选择合适的模型尺寸,实现速度和精度的平衡。
7. 性能优化
- 高效推理:
-
- YOLOv5在推理速度方面进行了优化,使其在边缘设备和移动设备上也能高效运行。
- 实用性和灵活性:
-
- YOLOv5可以在各种硬件平台上高效运行,包括CPU、GPU和TPU。模型设计灵活,适用于各种应用场景。
8.总结
YOLOv5通过一系列改进和优化,在保持高效检测的同时,进一步提升了模型的精度和速度。其易用性和灵活性使得YOLOv5在实际应用中非常受欢迎,适用于自动驾驶、视频监控、人脸识别等多个领域。YOLOv5的发布标志着目标检测技术的又一次重要进步,为实时目标检测任务提供了更强大的工具。
YOLOv1、YOLOv2、YOLOv3和YOLOv5的更详细介绍,包括网络结构和目标检测流程。
YOLOv1
网络结构
- 输入:YOLOv1接受固定大小的输入图像(448x448像素)。
- 卷积层:网络包含24个卷积层,用于提取图像特征。
-
- 每个卷积层的参数配置(如滤波器数量、大小、步长等)依次设置。
- 使用Leaky ReLU作为激活函数。
- 全连接层:包含两个全连接层:
-
- 第一个全连接层有4096个神经元,连接到卷积层的输出。
- 第二个全连接层连接到SxSx(Bx5 + C)的输出,即输出预测向量。
- 输出层:将图像划分为SxS的网格(通常是7x7),每个网格单元预测B个边界框(通常是2个)和C个类别(通常是20个)。
目标检测流程
- 图像输入:将输入图像调整为448x448像素。
- 特征提取:通过24个卷积层提取图像特征。
- 全连接层处理:通过两个全连接层,将特征映射到输出空间。
- 预测:在输出层,网络将图像划分为SxS的网格,每个网格单元预测B个边界框、每个边界框的置信度和C个类别概率。
- 非极大值抑制(NMS):筛选出重叠的边界框,只保留最高置信度的框。
YOLOv2
网络结构
- 输入:YOLOv2接受416x416或608x608像素的输入图像。
- Darknet-19 Backbone:使用19个卷积层和5个池化层进行特征提取。
-
- 每个卷积层后面添加批归一化(Batch Normalization),以提高训练稳定性和收敛速度。
- 使用Leaky ReLU作为激活函数。
- 全连接层:移除了全连接层,使用卷积层直接进行预测。
- 锚框(Anchor Boxes):引入锚框机制,每个网格单元预测多个锚框。
目标检测流程
- 图像输入:将输入图像调整为416x416或608x608像素。
- 特征提取:通过Darknet-19进行特征提取。
- 锚框生成:使用K-means聚类生成锚框,以适应数据集中的目标尺寸。
- 多尺度预测:在不同尺度的特征图上进行预测,每个网格单元预测多个锚框及其置信度和类别概率。
- 非极大值抑制(NMS):筛选出重叠的边界框,只保留最高置信度的框。
YOLOv3
网络结构
- 输入:YOLOv3接受320x320、416x416、608x608等多种分辨率的输入图像。
- Darknet-53 Backbone:使用53个卷积层和残差块(Residual Blocks)进行特征提取。
-
- 每个残差块包含多个卷积层,并引入跨层连接(skip connections)。
- 使用Leaky ReLU作为激活函数。
- 多尺度特征图:在三个不同尺度的特征图上进行预测,以处理不同大小的物体。
- 锚框(Anchor Boxes):改进锚框机制,每个网格单元预测多个锚框。
目标检测流程
- 图像输入:将输入图像调整为指定分辨率(如416x416)。
- 特征提取:通过Darknet-53进行特征提取。
- 多尺度预测:在三个不同尺度的特征图上进行预测,每个尺度的特征图负责不同大小的物体。
- 预测:每个网格单元预测多个锚框及其置信度和类别概率。
- 非极大值抑制(NMS):筛选出重叠的边界框,只保留最高置信度的框。
YOLOv5
网络结构
- 输入:YOLOv5接受多种分辨率的输入图像(如320x320、416x416、640x640)。
- CSPDarknet53 Backbone:使用CSP(Cross Stage Partial)结构的Darknet53进行特征提取。
-
- CSP结构将特征图划分为两部分,部分进入下一个卷积层,部分直接跳跃到后续层合并。
- 使用Leaky ReLU和Mish作为激活函数。
- PANet:采用PANet(Path Aggregation Network)提高特征融合能力。
-
- PANet通过自底向上的路径增强了特征金字塔。
- 多尺度特征图:在多个尺度的特征图上进行预测。
目标检测流程
- 图像输入:将输入图像调整为指定分辨率(如640x640)。
- 特征提取:通过CSPDarknet53进行特征提取。
- 特征融合:通过PANet进行多尺度特征融合。
- 多尺度预测:在多个尺度的特征图上进行预测,每个尺度的特征图负责不同大小的物体。
- 预测:每个网格单元预测多个锚框及其置信度和类别概率。
- 非极大值抑制(NMS):筛选出重叠的边界框,只保留最高置信度的框。
总结
- YOLOv1:首次将目标检测问题转换为单次前向传播的回归问题,通过全连接层预测边界框和类别概率,但存在预测小物体不准确的问题。
- YOLOv2:引入了锚框机制和批归一化,改进了特征提取网络(Darknet-19),提高了检测精度和速度。
- YOLOv3:采用更深的特征提取网络(Darknet-53)和多尺度特征图预测,进一步提高了检测性能,尤其在小物体检测方面表现更好。
- YOLOv5:在YOLOv3的基础上进行了优化,使用了CSPDarknet53和PANet进行特征提取和融合,引入了Mosaic数据增强和自动混合精度训练,显著提升了模型的精度和速度。















 380
380

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









