






目录
1 深度学习
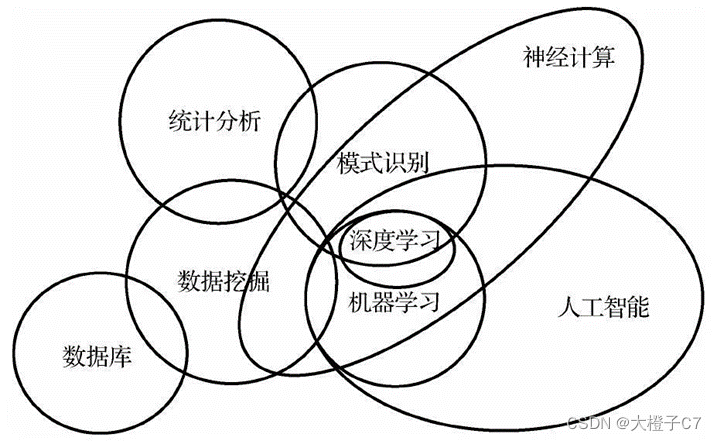
人工智能、机器学习、深度学习这三者的关系:
在实现人工智能的众多算法中,机器学习是发展较为快速的一支,是实现人工智能的途径之一。而深度学习则是机器学习的算法之一。如果把人工智能比喻成人类的大脑,机器学习则是人类通过大量数据来认知学习的过程,而深度学习则是学习过程中非常高效的一种算法。
1.1 人工智能
人工智能(Artificial Intelligence, AI)是为了赋予计算机以人类的理解能力与逻辑思维,其本质是希望机器能够像人类的大脑一样思考,并作出反应。
根据人工智能实现的水平,可分为3类:弱人工智能、强人工智能、超人工智能。
1.2 机器学习
机器学习的思想是让机器自动地从大量的数据中学习出规律,并利用该规律对未知的数据做出预测。
机器学习算法中最重要的就是数据,根据使用的数据形式,可以分为三大类:监督学习(Supervised Learning)、无监督学习(Unsupervised Learning)与强化学习(Reinforcement Learning)。
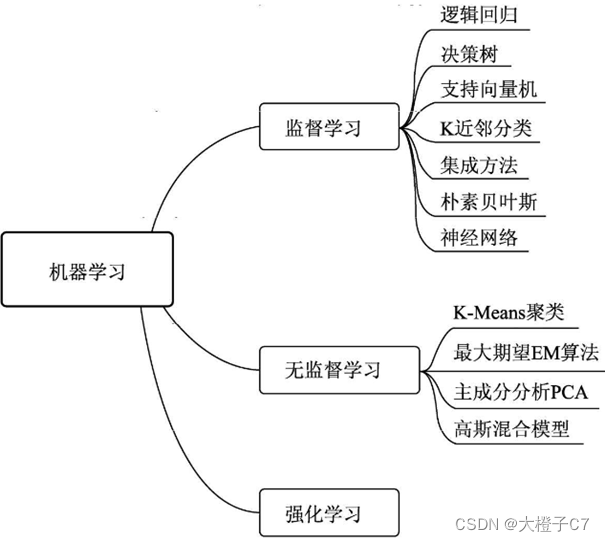
(1)监督学习
通常包括训练与预测阶段。在训练时利用带有人工标注标签的数据对模型进行训练,在预测时则根据训练好的模型对输入进行预测。监督学习通常分为分类与回归两个问题,常见算法有决策树(Decision Tree, DT)、支持向量机(Support Vector Machine,SVM)和神经网络等。
(2)无监督学习
对没有类别标记的样本进行学习,学习目的通常是发现数据内在结构,典型任务是聚类和降维。
聚类:在非监督学习中,所有数据没有标记,但是这些数据会呈现出聚群的结构,相似类型的数据会聚集在一起。把这些没有标记的数据分成一个个组合即聚类。
降维:指在某些限定条件下,降低随机变量个数。可进一步细分为变量选择和特征提取两大方法。
变量选择是指当数据中包含大量冗余或无关变量时,在原有变量中找出主要变量,从而简化模型,使之更容易被机器学习。
特征提取是从原始资料中构建富含资讯性且不冗余的特征值,它可以帮助接续的学习过程和归纳步骤,初始的资料集合被降到更容易管理的族群(特征)以便于学习,同时保持描述原始资料集的精准性与完整性。
(3)强化学习
让模型在一定的环境中学习,每次行动会有对应的奖励,目标是使奖励最大化。常见的强化学习有基于价值、策略与模型3种方法。
注:
半监督学习:介于监督学习与无监督学习之间,它要求对小部分的样本提供预测量的真实值。这种方法通过有效利用所提供的小部分监督信息,通常可以获得比无监督学习更好的效果,同时也把获取监督信息的成本控制在可以接受的范围。
1.3 深度学习
深度学习是特指利用深度神经网络的结构完成训练和预测的算法。主要是通过搭建深层的人工神经网络(Artificial Neural Network)来进行知识的学习,输入数据通常较为复杂、规模大、维度高。
1.3.1 深度学习发展历程

MCP(McCulloch and Pitts)人工神经元网络:希望使用简单的加权求和与激活函数来模拟人类的神经元过程。
感知器(Perception)模型:使用了梯度下降算法来学习多维的训练数据,成功地实现了二分类问题。
感知器线性问题:感知器仅仅是一种线性模型,对简单的亦或判断都无能为力,而生活中的大部分问题都是非线性的。
反向传播BP:将非线性的Sigmoid函数应用到了多层感知器中,并利用反向传播(Backpropagation)算法进行模型学习,使得模型能够有效地处理非线性问题。
LSTM:长短期记忆(Long short-term memory, LSTM)是一种特殊的RNN,主要是为了解决长序列训练过程中的梯度消失和梯度爆炸问题。简单来说,就是相比普通的RNN,LSTM能够在更长的序列中有更好的表现。
LeNet:卷积神经网络LeNet模型,可有效解决图像数字识别问题,被认为是卷积神经网络的鼻祖。
ReLU激活函数:有效地缓解了梯度消失现象
AlexNet网络:(重要节点)2012年,Alex等人提出的AlexNet网络在ImageNet大赛上以远超第二名的成绩夺冠,深度学习从此一发不可收拾,VGGNet、ResNet等优秀的网络接连问世。
AlexNet是在LeNet的基础上加深了网络的结构,学习更丰富更高维的图像特征。AlexNet的特点:
- 更深的网络结构
- 使用层叠的卷积层,即卷积层+卷积层+池化层来提取图像的特征
- 使用Dropout抑制过拟合
- 使用数据增强Data Augmentation抑制过拟合
- 使用Relu替换之前的sigmoid的作为激活函数
- 多GPU训练
VGGNet:在AlexNet的基础上拓宽了网络深度,本质上网络模型仍然是由卷积层和全连接层组成。经常被用来提取图像特征。
论文原文:《Very Deep Convolutional Networks for Large-Scale Image Recognition》
ResNet:该卷积神经网络又称残差网络,在2015年的ImageNet大赛中获得了图像分类和物体识别的优胜。其特点是容易优化,并且能够通过增加相当的深度来提高准确率。其内部的残差块使用了跳跃连接,缓解了在深度神经网络中增加深度带来的梯度消失问题。
论文原文:《Deep Residual Learning for Image Recognition》
1.3.2 深度学习中的核心因素
a.大数据:当前大部分的深度学习模型是有监督学习,依赖于数据的有效标注。
b.GPU:GPU为深度学习模型的快速训练提供了可能。GPU以及CUDA计算库专注于数据的并行计算,为模型训练提供了强有力的工具。
c.模型:在大数据与GPU的强有力支撑下,无数研究学者的奇思妙想,催生出了VGGNet、ResNet和FPN等一系列优秀的深度学习模型,并且在学习任务的精度、速度等指标上取得了显著的进步。
1.3.3 深度学习模型分类
根据网络结构的不同,深度学习模型可以分为
卷积神经网络(Convolutional Neural Network,CNN):一种带有卷积结构的深度神经网络,卷积结构可以减少深层网络占用的内存量,其三个关键的操作局部感受野、权值共享和pooling层,有效的减少了网络的参数个数,缓解了模型的过拟合问题。
循环神经网络(Recurrent Neural Network, RNN):一种用于处理序列数据的神经网络。相比一般的神经网络来说,他能够处理序列变化的数据。
生成式对抗网络(Generative Adviserial Network, GAN):一种生成式模型,通过让两个神经网络(生成网络与判别网络) 相互博弈的方式进行学习,从而生成新的样本数据,能有效解决样本数据不足的问题。
1.3.4 深度学习框架
PyTorch、TensorFlow、MXNet、Keras、Caffe和Theano等多种深度学习框架,广泛应用于计算机视觉、自然语言处理、语音识别等领域。
2 计算机视觉
视觉是人类最为重要的感知系统,大脑皮层中近一半的神经元与视觉有关系。计算机视觉则是研究如何使机器学会“看”的学科。
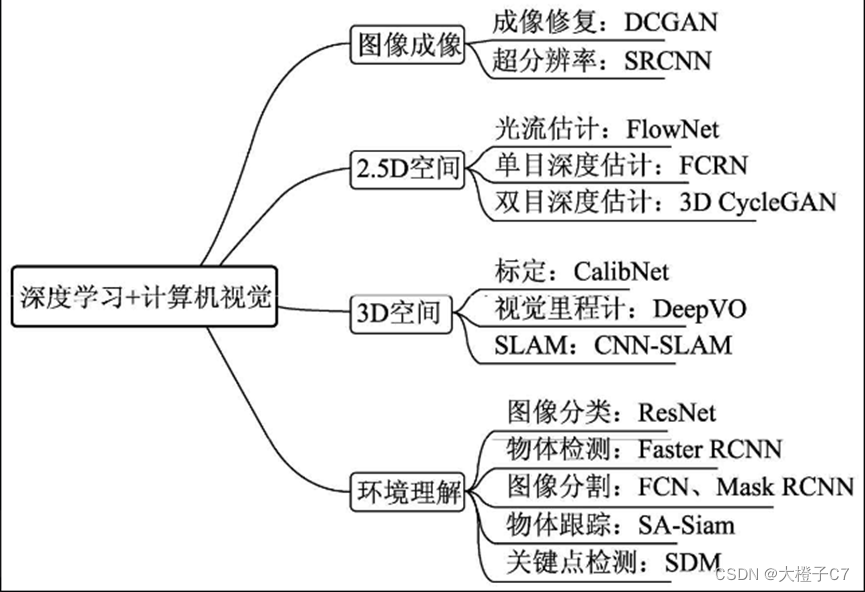
(1)图像成像:成像是计算机视觉较为底层的技术,深度学习在此发挥的空间更多的是成像后的应用,如修复图像的DCGAN网络,图像风格迁移的CycleGAN,在医学成像、卫星成像等领域中,超分辨率也至关重要,例如SRCNN(Super-Resolution CNN)。
(2)2.5D空间:通常将涉及2D运动或者视差的任务定义为2.5D空间问题,因为其任务跳出了单纯的2D图像,但又缺乏3D空间的信息。
(3)3D空间:3D空间的任务通常应用于机器人或者自动驾驶领域,将2D图像检测与3D空间进行结合。主要任务有相机标定(Camera Calibration)、视觉里程计(Visual Odometry, VO)及SLAM(Simultaneous Localization and Mapping)等。
(4)环境理解:环境的高语义理解是深度学习在计算机视觉中的主战场,相比传统算法其优势更为明显。主要任务有图像分类(Classification)、物体检测(Object Detection)、图像分割(Segmentation)、物体跟踪(Tracking)及关键点检测。其中,图像分割又可以细分为语义分割(Semantic Segmentation)与实例分割(Instance Segmentation)。
参考文献:
1.《深度学习之PyTorch物体检测实战》
2.无监督学习-https://www.xakpw.com/single/24075
3.卷积神经网络之AlexNet - Brook_icv - 博客园 (cnblogs.com)
注:
本文是学习所参考文献与资料后的整理与归纳,仅作学习记录,如有侵权请联系作者删除!欢迎大家指正与交流。














 1248
1248











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









