







本文公众号端:
格式化输出![]() https://mp.weixin.qq.com/s?__biz=MzkwMjc0MTE3Mw==&mid=2247483945&idx=1&sn=cb7555e7a2720a1b0c2b7bdba7fcf135&chksm=c0a1aff3f7d626e56fd94f3514029d5a5834f3f86aa6af8294c0cb071f79ff1a8da05813367a#rd 在Python开发中,有时会遇到复杂冗长的数据结构,比如:
https://mp.weixin.qq.com/s?__biz=MzkwMjc0MTE3Mw==&mid=2247483945&idx=1&sn=cb7555e7a2720a1b0c2b7bdba7fcf135&chksm=c0a1aff3f7d626e56fd94f3514029d5a5834f3f86aa6af8294c0cb071f79ff1a8da05813367a#rd 在Python开发中,有时会遇到复杂冗长的数据结构,比如:
data = {
"name": "xiaoming",
"age": 18,
"hobbies": ["reading", "hiking", "coding"],
"education": {
"high_school": {
"name": "Good High School",
"educational_system": 3
},
"college": {
"name": "Good University",
"degree": "Bachelor of Science",
"major": "Computer Science",
"educational_system": 4
}
}
}
print(data)输出:
| {'name': 'xiaoming', 'age': 18, 'hobbies': ['reading', 'hiking', 'coding'], 'education': {'high_school': {'name': ' Good High School', 'educational_system': 3}, 'college': {'name': 'Good University', 'degree': 'Bachelor of Science', 'major': 'Computer Science', 'educational_system': 4}}} |
对于上述代码输出可以看到,输出的数据堆在一起,对于阅读以及调试等十分不便。而在编程中,数据的展示方式往往与用户体验、调试效率密切相关。无论是在开发过程中调试代码,还是在终端中输出结果,数据的可读性都起着至关重要的作用。所以面对如此繁杂的数据结构时,可以考虑调整其输出格式,使其更易理解。
而Python作为一门灵活且强大的编程语言,提供了多种工具和方法来格式化输出数据。通过这些格式化方案,开发者可以将原本冗杂的数据整理得更为工整、有序,使其不仅便于阅读和理解,还能为用户提供清晰直观的展示效果。无论是面对嵌套的数据结构、复杂的日志信息,还是多语言支持的需求,Python的格式化输出都能有效地提高代码的可读性和可维护性,为各类应用场景提供了优雅的解决方案。✨
在正文开始前,欢迎各位关注公众号【多棱领域】,我会持续更新有趣且使用的内容!

![]()
一. 格式化输出方案
本文将提供并介绍几个常用的格式化输出方案,以此抛砖引玉,希望能各位有所帮助。
1.自定义函数
可以采用自定义函数的方式格式化输出:
#可以进行递归的格式化输出函数
def custom_format(data,recursion):
#确定本次输出的空格数
space = ' '*recursion
#遍历输出
for key, value in data.items():
#如果要输出的是字典进行递归
if type(value) is dict:
print(f"{space}{key}: ")
custom_format(value,recursion+1)
else:
print(f"{space}{key}: {value}")
custom_format(data,0)输出:
name: xiaoming
age: 18
hobbies: ['reading', 'hiking', 'coding']
education:
high_school:
name: Good High School
educational_system: 3
college:
name: Good University
degree: Bachelor of Science
major: Computer Science
educational_system: 4 |
采用自定义函数进行格式化输出的方法是一种灵活且可定制的方式,可以根据特定需求自定义输出格式,并根据具体情况和需求编写,以实现各种特定的格式化输出,包括特定的排列顺序、特殊字符的处理等。
但是这种方案具有一定的维护成本,特别是在数据结构发生变化时,可能需要更新和调整函数以符合新的输出需求。使用自定义函数可能会引入额外的代码量,尤其是在需要处理复杂数据结构或多种输出情形时,可能需要编写大量的格式化函数。同时,自定义函数通常是针对特定情况和数据结构编写的,可能在其他环境或项目中不易重复使用。
2.采用pprint模块
import pprint
pprint.pprint(data)输出:
{'age': 18,
'education': {'college': {'degree': 'Bachelor of Science',
'educational_system': 4,
'major': 'Computer Science',
'name': 'Good University'},
'high_school': {'educational_system': 3,
'name': ' Good High School'}},
'hobbies': ['reading', 'hiking', 'coding'],
'name': 'xiaoming'} |
pprint 是 Python 标准库的一部分,无需额外安装,可以直接使用。使用 Python 的pprint 模块进行格式化输出也是一种常用的方式,它可以帮助打印复杂数据结构时更易于阅读,能输出更易读的格式化数据结构。同时其也支持多种显示格式,可以满足不同输出需求,如缩进、排序等。
但在处理大型复杂数据结构时,pprint的格式化过程可能会增加一些性能开销,导致输出速度较慢。虽然 pprint 能够自动格式化输出,但有时可能无法满足特定输出格式的需求,对于一些定制化的格式化要求可能有局限性。
3.采用JSON模块
import json
formatted_json = json.dumps(data, indent=4)
print(formatted_json)输出:
{
"name": "xiaoming",
"age": 18,
"hobbies": [
"reading",
"hiking",
"coding"
],
"education": {
"high_school": {
"name": " Good High School",
"educational_system": 3
},
"college": {
"name": "Good University",
"degree": "Bachelor of Science",
"major": "Computer Science",
"educational_system": 4
}
}
} |
使用 JSON 序列化工具进行格式化输出是一种常见的方式,可以方便地将数据结构序列化为 JSON 格式,以便于存储、传输和交换。JSON 是一种通用数据交换格式,因此 JSON 格式输出具有良好的跨平台兼容性。并且JSON 格式具有一定的易读性,结构清晰、简洁,对于这个例程相比上述使用的pprint,JSON格式输出的内容更为工整。JSON 还可以表示复杂的数据结构,如字典、列表等,序列化后方便存储和传输,有利于数据交换和集成。
当然,虽然JSON格式的数据也十分工整,但存在较多的数据嵌套时,客观性也相对复杂。而且在处理大型数据结构时,JSON 序列化和反序列化的性能可能较低,特别是对于复杂结构或嵌套层级深的数据。
4.采用yaml模块
import yaml
formatted_yaml_1 = yaml.dump(data, sort_keys=False)
print(formatted_yaml_1)输出:
name: xiaoming
age: 18
hobbies:
- reading
- hiking
- coding
education:
high_school:
name: ' Good High School'
educational_system: 3
college:
name: Good University
degree: Bachelor of Science
major: Computer Science
educational_system: 4 |
或者:
import yaml
formatted_yaml_1 = yaml.dump(data)
print(formatted_yaml_1)输出:
age: 18
education:
college:
degree: Bachelor of Science
educational_system: 4
major: Computer Science
name: Good University
high_school:
educational_system: 3
name: ' Good High School'
hobbies:
- reading
- hiking
- coding
name: xiaoming
|
使用 YAML 格式进行格式化输出在某些情况下可能比 JSON 更适合,尤其是对于阅读而言。YAML 具有比 JSON 更好的可读性和可编辑性,结构清晰,支持注释和缩进,更接近自然语言。YAML 格式可表示复杂的数据结构,如嵌套的字典、列表等,序列化后易于理解和编辑,并具有一定的灵活性,可以更轻松地处理特定情况下的数据格式要求。YAML 也支持注释,有助于说明数据的含义和用途。
但是与 JSON 相比,YAML 没有像 JSON 那样的严格标准,导致可能存在不同解析器之间的兼容性问题。而且YAML 的语法比 JSON 略为复杂,尤其在处理复杂嵌套结构时可能需要花费更多的精力来理解和编写。虽然YAML支持执行代码的功能,但也可能存在安全风险,尤其是在处理来自不可信源的YAML数据时需要特别小心。YAML 的解析和序列化性能可能不如 JSON 那么高效,特别是在处理大型数据结构时可能会有一定性能开销。
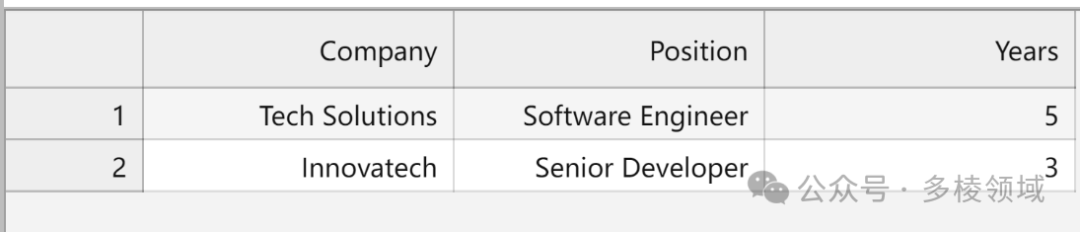
5.采用tabulate模块
from tabulate import tabulate
work_experience = [
{"Company": "Tech Solutions", "Position": "Software Engineer", "Years": 5},
{"Company": "Innovatech", "Position": "Senior Developer", "Years": 3}
]
print(tabulate(work_experience, headers="keys", tablefmt="grid"))输出:

使用 Python 的 tabulate 库进行格式化输出是一种简便的方式,特别适用于将数据转换为表格形式进行展示。tabulate 提供了简单易用的接口,能够快速将数据展示为漂亮的表格形式,无需手动编写格式化输出的代码。tabulate 可以处理各种数据结构,如列表、字典等,支持不同的数据源进行表格化输出,并提供了多种选项和参数,可以定制表格的样式、对齐方式、标题等,使得用户可以根据需求自定义输出格式。除了标准的文本表格输出外,tabulate 还支持将表格输出为 HTML、Markdown 等格式,具有一定的灵活性。
但是tabulate 更适用于较简单的表格数据展示,对于超大型数据或复杂嵌套数据的展示可能略显不足。虽然tabulate 提供了一定的定制选项,但在一些特定的格式化需求下可能存在限制,因此需要根据具体情况来判断是否适合使用。
6.使用pandas模块输出数据框
如果你有结构化的数据,pandas模块可以帮助你将数据以数据框的形式输出,并提供强大的格式化和操作功能。
import pandas as pd
df = pd.DataFrame(work_experience)
print(df)输出:

使用 Pandas 库进行格式化输出是处理和展示数据的常见方式,特别适用于数据分析和处理。除此之外,Pandas还提供了丰富的数据结构和功能,能够方便地进行数据操作、筛选、合并等处理,适用于处理复杂的数据集,并提供了多种数据展示方式,包括表格形式、图表、统计摘要等,能够满足不同需求的可视化展示。Pandas还能够处理多种数据源,包括 CSV、Excel、SQL 数据库等,方便用户对不同格式的数据进行操作和展示。
但是Pandas 作为一个额外的库,需要安装和管理额外的依赖,可能增加项目的复杂性和部署难度。对于少量简单数据的处理和展示,引入 Pandas 可能显得有些繁琐和不必要,可以选择更轻量级的方式来实现。
7.使用CSV模块进行格式化输出为CSV文件
如果你希望将数据保存为可读的 CSV 文件,可以使用CSV模块。
import csv
with open("work_experience.csv", mode="w", newline="") as file:
writer = csv.DictWriter(file, fieldnames=["Company", "Position", "Years"])
writer.writeheader()
writer.writerows(work_experience)
with open("work_experience.csv", mode="r") as file:
print(file.read())输出:
Company,Position,Years Tech Solutions,Software Engineer,5 Innovatech,Senior Developer,3 |
并在目录下产生一个CSV文件"work_experience.csv":
CSV 是一种通用的数据交换格式,广泛被支持和应用,使得导出的数据能够在不同系统和软件中方便地进行处理和读取。使用 Python 的 CSV 模块进行格式化输出是一种常见的处理和导出数据的方式。其提供了简单易用的方法来读取和写入 CSV 格式的数据,适用于处理简单的表格数据。相比于其他复杂的数据处理工具,使用 CSV 模块能够保持代码简洁和轻量,适用于处理少量数据或简单格式化输出的场景。CSV 模块还提供了各种参数和选项,能够控制输出的格式、分隔符等,使得用户可以根据需求定制输出格式。
但是,CSV 模块主要用于读写 CSV 格式的数据,对于一些复杂的数据处理和展示需求,可能无法提供足够的支持。对于包含复杂结构、多层嵌套的数据表格,使用 CSV 模块展示可能不够直观和灵活。
8.使用textwrap模块格式化长字符串
当数据中包含长字符串时,可以使用textwrap 模块来控制每行的字符数,使输出更整齐
import textwrap
description = ("xiaoming is a software engineer with over 3 years of experience "
"in developing scalable software solutions. he is proficient "
"in multiple programming languages including Python, Java, and C++. "
"his expertise lies in backend development, system design, and data engineering.")
formatted_description = textwrap.fill(description, width=50)
print(formatted_description)输出:
xiaoming is a software engineer with over 3 years of experience in developing scalable software solutions. he is proficient in multiple programming languages including Python, Java, and C++. his expertise lies in backend development, system design, and data engineering. |
textwrap 是Python标准库的一部分,不需要安装额外的依赖,方便在Python环境中直接使用。使用 Python 的 textwrap 模块进行文本格式化输出是一种处理长文本和段落的常见方法。textwrap 模块提供了简单易用的方法来格式化文本,可以将长文本按照指定的宽度进行自动换行,使得阅读和展示更加整洁。Textwrap也提供了多种定制选项,可控制换行的方式、缩进、填充字符等,使得用户可以根据需求定制化输出格式。对于需要处理长文本或段落的情况,使用textwrap 可以快速实现文本的格式化输出,提高可读性和美观度。
但是textwrap主要用于文本的自动换行处理,对于其他文本处理需求如文本分割、词性标注等功能提供的支持有限。而且虽然textwrap 提供了一些选项来定制格式化输出,但在一些特定的格式化需求下可能需要额外的处理或模块来实现。在一些特定的文本格式化需求下,或者对于复杂排版和布局的需要,textwrap 可能无法完全满足要求。在处理大量长文本时,由于textwrap需要遍历文本进行换行处理,可能会影响程序的运行性能,特别是对于大规模文本数据的处理。
![]()
总之,不同的格式化输出方法各有千秋,根据实际需求选择合适的方案,可以大大提升Python项目的可读性和数据处理能力。比如在高度定制化的输出场景中,可以考虑采用自定义函数实现;在快速查看复杂数据结构的简单场景,尤其是在调试过程中,可以考虑使用pprint模块或自定义函数;若还需要数据序列化、传输以及与外部系统交互,尤其是需要进行Web开发,可以采用JSON模块;如果需要输出更人性化的数据格式,比如需要进行编写配置文件,可以考虑采用yaml模块;若想将数据以表格形式展示,可以考虑采用tabulate模块、pandas模块或CSV模块;当然,如果只想进行命令行输出报告、统计数据展示,或生成可直接使用的HTML等格式,可以采用tabulate模块;若还有数据分析和处理的需求,要进行大规模数据的处理和分析任务,可以采用pandas模块;若仅进行简单数据的导入导出,尤其是与电子表格软件交互的场景,可以考虑使用CSV模块;若要对长文本进行格式化处理,以便于在有限宽度的界面中展示,可以使用textwrap模块。当然,面对不同开发环境的需求,可以综合使用上述多种方案。
![]()
二. 格式化输出的好处和应用
-
提高可读性:格式化输出使数据以清晰、结构化的方式呈现,有助于快速理解复杂的数据结构。通过缩进、换行和对齐,数据的层次和关系变得更加直观。
-
增强调试和日志记录:在调试过程中,格式化的输出可以帮助开发者更容易地识别和解决问题。格式化的日志文件也更易于后期分析和审计。
-
改善用户体验:格式化输出可以提升终端应用和用户界面的友好性。对于终端用户和系统管理员来说,整洁的数据展示让操作和分析变得更加轻松。
-
增强数据处理和展示能力:格式化工具如 pprint、json 和 yaml 不仅提供了标准的数据展示格式,还支持序列化和反序列化功能,便于数据存储和传输。
![]()
总之,Python 提供了多种格式化输出的方法,每种方法都有其独特的优势和应用场景。本文介绍的这些方案可以帮助开发者将复杂的数据以更为清晰、整洁的方式呈现。通过掌握这些格式化技巧,可以提升代码的可读性,优化用户体验,进而提高开发效率和数据处理能力。无论是在调试、日志记录还是数据展示中,合理使用格式化输出工具都能为你的 Python 项目带来显著的好处。
最后,如果本文对您有所帮助,欢迎关注、点赞、收藏、转发,我会持续更新有趣实用的内容,共同学习!✨















 1096
1096

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









