






深入研究XrayGLM的模型结构,并进行微调
目录
1. 项目结构:
.
├── CITATION.cff
├── LICENSE
├── README.md
├── XrayGLM_inference.ipynb
├── __pycache__
│ ├── finetune_XrayGLM.cpython-310.pyc
│ └── lora_mixin.cpython-310.pyc
├── assets
│ ├── images
│ └── train_cli.txt
├── checkpoints
│ ├── README.md
│ └── finetune-XrayGLM-04-20-20-57
├── cli_demo.py
├── data
│ ├── Xray
│ ├── build_ch_prompt-random.py
│ ├── build_ch_prompt.py
│ ├── build_images_data.py
│ ├── demo
│ ├── from_xml_get_images_id.py
│ ├── json2md.py
│ ├── merge_ch2json.py
│ ├── openi-ch-random.json
│ ├── openi-en.json
│ ├── openi-zh-prompt.json
│ └── translation_en2zh.py
├── finetune_XrayGLM.py
├── finetune_XrayGLM.sh
├── lora_mixin.py
├── model
│ ├── __init__.py
│ ├── __pycache__
│ ├── blip2.py
│ ├── chat.py
│ ├── infer_util.py
│ └── visualglm.py
├── requirements.txt
├── requirements_wo_ds.txt
├── runs
│ ├── finetune-XrayGLM-04-17-17-00
│ ├── finetune-XrayGLM-04-17-17-21
│ ├── finetune-XrayGLM-04-18-23-22
│ ├── finetune-XrayGLM-04-19-19-41
│ └── finetune-XrayGLM-04-20-20-57
└── web_demo.py
2. Lora 技术
Lora 技术旨在通过定制的线性变换来加速和优化神经网络模型,这里用LoraMixin 和 LoraLinear 类来实现。
LoraLinear 是一个自定义的层,结合了原始的线性变换和特定的矩阵乘法,以实现模型加速和优化。LoraMixin 是一个混合类,用于在给定的模型层上替换线性层为 LoraLinear 层,并提供一个方法用于将 LoraLinear 层合并回普通线性层。
if args.use_lora:
# If you use lora on other "normal" Transformer, just use it with head_first=False (by default)
self.add_mixin("lora", LoraMixin(args.num_layers, args.lora_rank, head_first=True, num_attention_heads=args.num_attention_heads, hidden_size_per_attention_head=args.hidden_size // args.num_attention_heads, layer_range=list(range(0, 28, 14))), reinit=True)
# self.get_mixin("eva").model.glm_proj = replace_linear_with_lora(self.get_mixin("eva").model.glm_proj, LoraLinear, args.lora_rank)3. finetune
- finetune_XrayGLM.py文件将命令行传入的参数与模型微调和训练过程结合起来,以便配置模型和训练过程,并执行模型的微调和训练。
1. 解析参数:参数解析器py_parser,用于解析脚本执行时传入的参数。
py_parser = argparse.ArgumentParser(add_help=False)
py_parser.add_argument('--max_source_length', type=int)
py_parser.add_argument('--max_target_length', type=int)
py_parser.add_argument('--ignore_pad_token_for_loss', type=bool, default=True)
py_parser.add_argument('--source_prefix', type=str, default="")
py_parser = FineTuneVisualGLMModel.add_model_specific_args(py_parser)
known, args_list = py_parser.parse_known_args()
args = get_args(args_list)
args = argparse.Namespace(**vars(args), **vars(known))
args.device = 'cpu'
2. 添加模型特定参数:调用`FineTuneVisualGLMModel.add_model_specific_args(py_parser)`方法向参数解析器中添加特定于模型的参数。
class FineTuneVisualGLMModel(VisualGLMModel):
@classmethod
def add_model_specific_args(cls, parser):
group = parser.add_argument_group('VisualGLM-finetune', 'VisualGLM finetune Configurations')
group.add_argument('--pre_seq_len', type=int, default=8)
group.add_argument('--lora_rank', type=int, default=10)
group.add_argument('--use_ptuning', action="store_true")
group.add_argument('--use_lora', action="store_true")
group.add_argument('--use_qlora', action="store_true")
return super().add_model_specific_args(parser)
3. 解析和合并参数:parse_known_args()方法解析命令行参数,并将结果与已知参数进行合并,生成最终的参数对象,用于配置模型和训练过程中的各种选项。
known, args_list = py_parser.parse_known_args()
args = get_args(args_list)
args = argparse.Namespace(**vars(args), **vars(known))
args.device = 'cpu'
4. 加载预训练模型:根据指定的模型类型,使用FineTuneVisualGLMModel.from_pretrained(model_type, args)方法加载预训练模型。
model_type = 'visualglm-6b'
model, args = FineTuneVisualGLMModel.from_pretrained(model_type, args)
if torch.cuda.is_available():
model = model.to('cuda')
5. 准备数据:create_dataset_function函数用于创建数据集。使用自定义的FewShotDataset类从文件中加载数据并进行预处理,以准备模型训练所需的输入数据格式。
tokenizer = get_tokenizer(args)
image_processor = BlipImageEvalProcessor(224)
dataset = FewShotDataset(path, image_processor, tokenizer, args)
6. 数据处理和训练:data_collator函数用于对数据进行处理和组合,准备模型训练所需的输入数据格式。然后调用training_main函数开始模型的微调和训练过程。在训练过程中,会调用forward_step_function函数执行前向传播,并计算损失。
def data_collator(examples):
# Data collation logic
...
training_main(args, model_cls=model, forward_step_function=forward_step, create_dataset_function=create_dataset_function, collate_fn=data_collator)
- finetune_XrayGLM.sh脚本的作用是启动模型微调和训练过程,将指定的参数和选项传递给模型训练脚本,并使用 DeepSpeed 进行模型并行训练。
1. 定义参数和路径
NUM_WORKERS=1
NUM_GPUS_PER_WORKER=4
MP_SIZE=1
script_path=$(realpath \$0)
script_dir=$(dirname $script_path)
main_dir=$(dirname $script_dir)
MODEL_TYPE="XrayGLM"
MODEL_ARGS="--max_source_length 64 \
--max_target_length 256 \
--lora_rank 10\
--pre_seq_len 4"
train_data="./data/openi-ch-random.json"
eval_data="./data/openi-ch-random.json"
2. 设置运行选项
OPTIONS_NCCL="NCCL_DEBUG=info NCCL_IB_DISABLE=0 NCCL_NET_GDR_LEVEL=2"
HOST_FILE_PATH="hostfile"
HOST_FILE_PATH="hostfile_single"
3. 构建模型训练选项,这里使用了 Lora 技术 (--use_lora)。
gpt_options=" \
--experiment-name finetune-$MODEL_TYPE \
--model-parallel-size ${MP_SIZE} \
--mode finetune \
--train-iters 3000 \
--resume-dataloader \
$MODEL_ARGS \
--train-data ${train_data} \
--valid-data ${eval_data} \
--distributed-backend nccl \
--lr-decay-style cosine \
--warmup .02 \
--checkpoint-activations \
--save-interval 3000 \
--eval-interval 1000 \
--save "./checkpoints" \
--split 1 \
--eval-iters 10 \
--eval-batch-size 8 \
--zero-stage 1 \
--lr 0.0001 \
--batch-size 8 \
--skip-init \
--fp16 \
--use_lora
"
4. 运行命令,使用deepspeed进行模型并行训练,最后通过 eval执行。
run_cmd="${OPTIONS_NCCL} ${OPTIONS_SAT} deepspeed --master_port 16666 --hostfile ${HOST_FILE_PATH} finetune_XrayGLM.py ${gpt_options}"
echo ${run_cmd}
eval ${run_cmd}
set +x
4. cli推理
使用命令行参数来配置模型的运行参数,包括最大序列长度、采样时的概率分布控制参数、输出语言选择、预训练模型路径等,可以根据实际需求调整模型的行为。
1. 参数解析
代码首先解析命令行参数,并根据这些参数加载和配置预训练模型。
parser = argparse.ArgumentParser()
# ...
args = parser.parse_args()2. 模型加载
使用AutoModel.from_pretrained方法加载预训练模型,并根据参数(如是否使用GPU,是否使用16位浮点数等)来初始化模型。之后将模型设置为评估模式(eval模式),在这种模式下,模型的某些层(如dropout层)的行为会发生变化,以进行更准确的推理。
model, model_args = AutoModel.from_pretrained(
args.from_pretrained,
args=argparse.Namespace(
fp16=True,
skip_init=True,
use_gpu_initialization=True if (torch.cuda.is_available() and args.quant is None) else False,
device='cuda' if (torch.cuda.is_available() and args.quant is None) else 'cpu',
)
)
model = model.eval()3. 模型量化
如果指定了量化参数,还会对模型的transformer部分进行量化处理,以提高运行效率。
if args.quant:
quantize(model.transformer, args.quant)模型加载完成后设置为评估模式,并添加自动回归混合模块,以支持对话功能。
使用AutoTokenizer加载与模型匹配的分词器,并根据用户是否选择英文模式输出不同的欢迎信息。然后程序进入一个无限循环,等待用户输入。用户可以通过输入图像URL或本地路径来启动对话,程序会加载图像到缓存中,并使用模型和分词器与用户进行交互。
5. 微调实践
在踩了很多坑后,我们成功完成了训练,为了及时地观察到模型的训练进展和性能变化,在调试模型过程中重新设置参数使之更频繁的保存模型检查点和进行评估,同时保持 --train-iters的值不变,这样可以更快地发现问题或者调整模型参数。
--save-interval 300 \
--eval-interval 300 \训练过程:
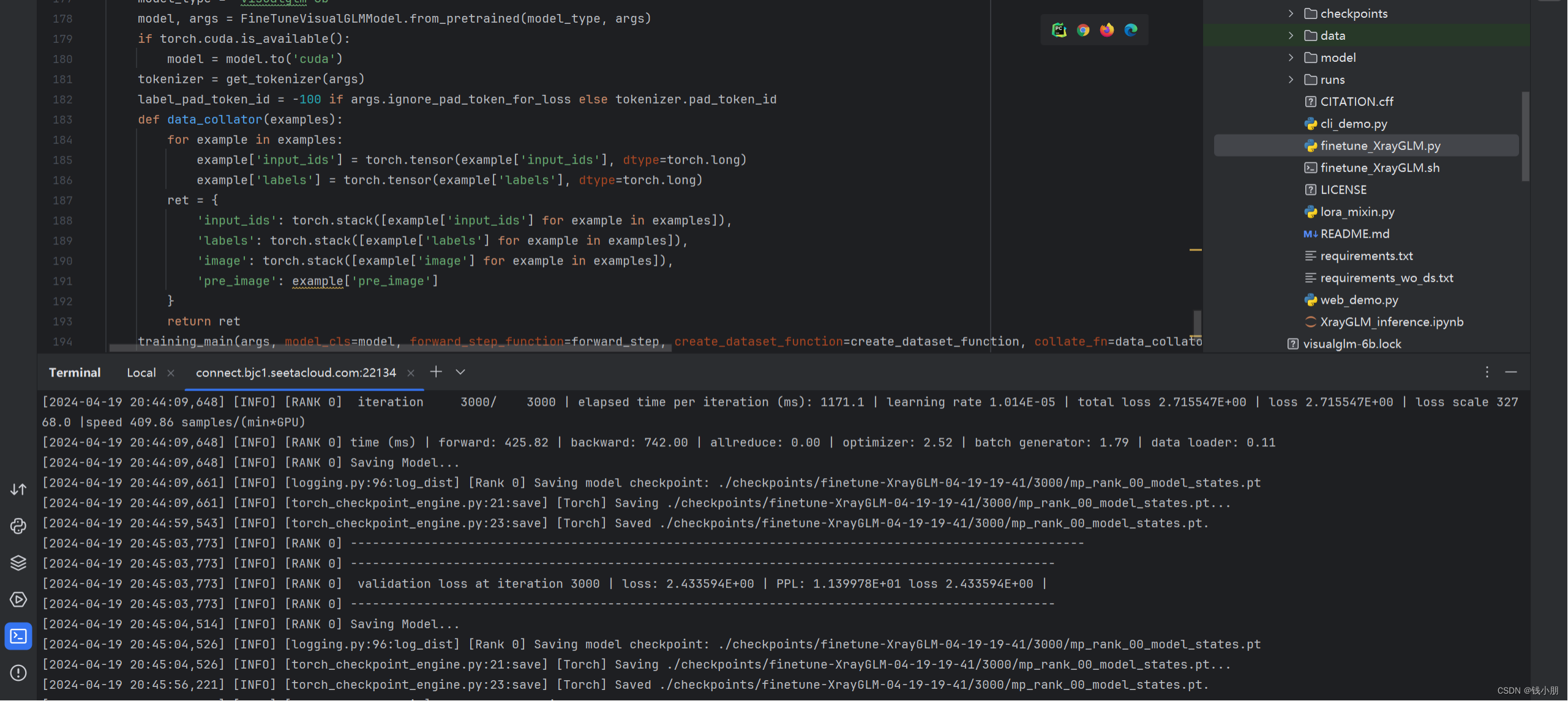
训练结果保存到./runs文件夹,可使用tensorlfow网络模型可视化:
activate tensorflow
tensorboard --logdir=./runs可视化结果:
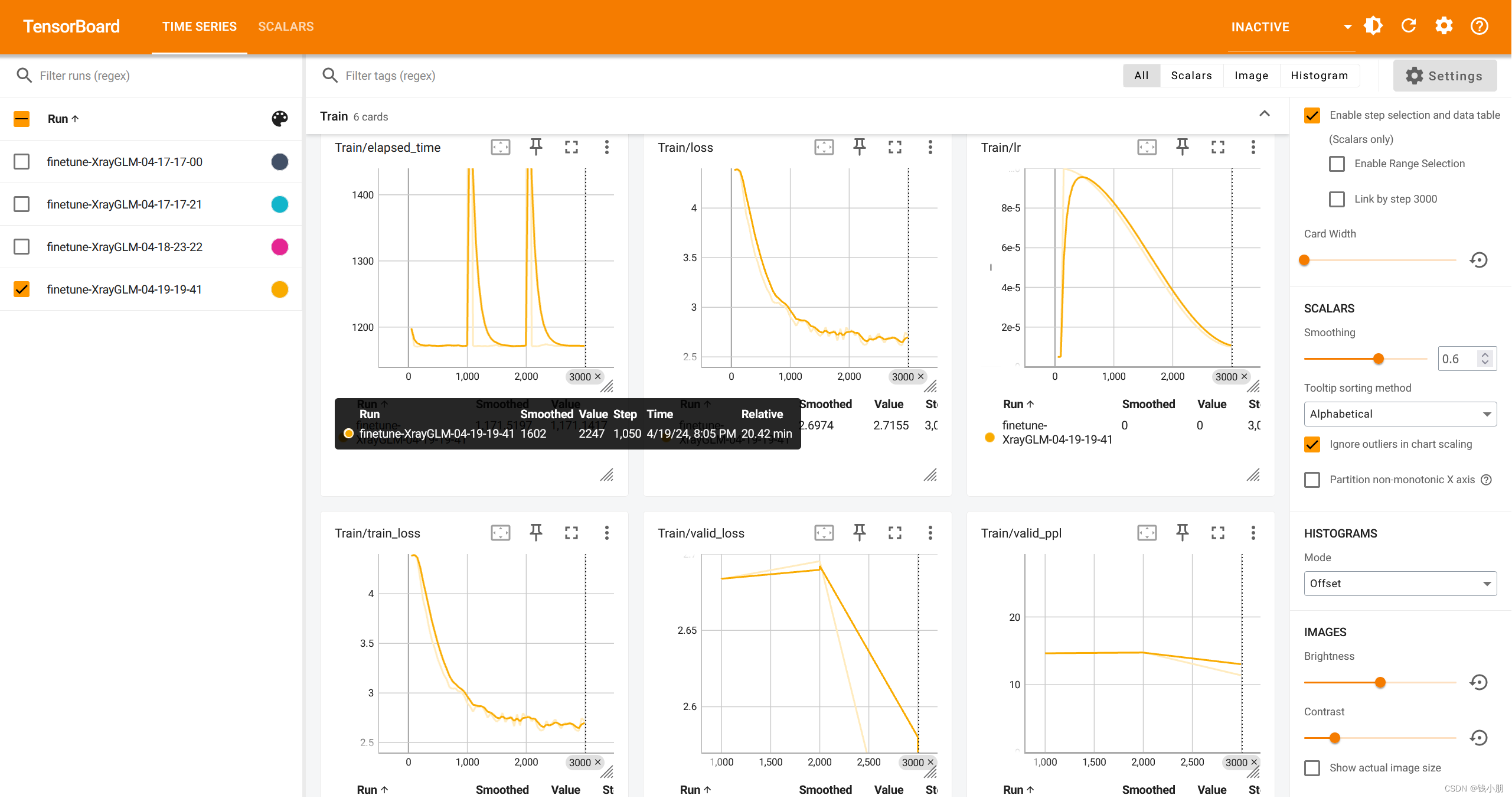
6. 总结
通过这些实践经验,我能够更好地理解和应用 XrayGLM 模型,同时也能够在实践中获得更多启示,更深入地理解整个项目的组织结构和模型的工作原理,为未来的工作打下坚实基础。在过程中思考如何进一步探索模型在医疗问答系统中的应用,并思考如何持续优化和改进模型性能,为医疗健康领域提供更智能化的支持和服务。
















 914
914











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









