







使用 pytorch 的相关神经网络库, 编写循环神经网络的语言模型,并基于本地训练或者预训练的词向量,实现文本情感分类。
实验环境:
数据集:使用比较常用的电影评论数据集IMDB
网络模型:使用LSTM+MLP
环境:pytorch+cuda
实验过程:
1、下载IMDB数据集
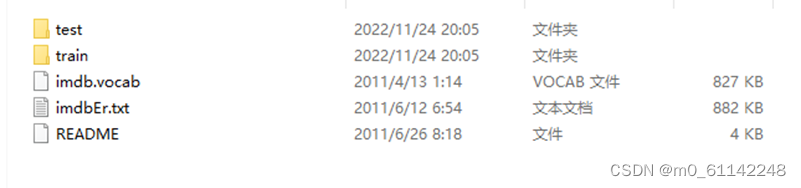
IMDB数据集是一种常用自然语言处理数据集,下载和处理方法自行百度。下载IMDB数据集后,解压后得到包含正负样本的电影评论数据集,具体如下:
2、数据预处理
对下载的数据集中的test和train分别进行预处理从而方便后续模型训练,网上有很多预处理的公开代码,也可以参考本人的代码:PreProcess.py。预处理主要包括:大小写转化、特殊字符处理、stopwords过滤、分词,最后将处理后的数据存储为CSV格式,以方便后续调试。借用了nltk的 stopwords 集,用来将像 i, you, is 之类的对分类效果基本没影响但出现频率比较高的词,从训练集中清除。
3、搭建语言模型
语言模型主要用于获得词向量,可以使用Gensim的Word2Vec 模型的API或者手动搭建语言模型训练得到。这部分可以参考网上公开代码,也可以参考本人的代码:trainbygensim.py(使用Gensim的Word2Vec 模型的API)或者WordsVec.py(手动搭建语言模型)。
这里的语言模型是一种词嵌入模型,主要是将文本中的单词映射为词向量。基本原理就是根据数据集建立一个词典。这个词典是一个集合,集合包含当前数据集中所有经过预处理后的单词(当然是不包含预处理过滤掉的内容的)。
这里稍微总结以下自己对语言模型和词向量的理解:
用单词(或者说字符串)构建的词典并不适合计算机处理,因此需要将单词进行编码,然后用词的编码来组成适合计算机处理的词典。这里单词的编码是用一个高维的矢量来表示,比如可以定义一个3维的矢量(实际中不可能这么小,很可能是100个维度甚至更高纬度的向量)来表示单词。
有了词典、词的编码就可以完成语言模型的工作:将人类认识的字符串映射为计算机认识的高维矢量。其基本过程为根据单词查找该单词在词典中的索引,根据词典索引找到对应的高维矢量,这个高维矢量即为该单词的词嵌入向量。
举个例子比如要获得单词‘man’的词嵌入向量,在词典中查找‘man’的索引,比如索引为5,那么再查找词向量矩阵(所有词向量依据词典顺序构成的矩阵)中索引5对应的词向量,比如为[1, 0 ,2]。那么就得到了单词'man'的词向量[1, 0, 2]。
语言模型的训练过程就是构建一个词向量空间(词向量矩阵),实现单词到词向量的映射。训练的方法就是根据单词间的关系来约束词向量间的距离/相似度,求解当前词典和文本条件下最优的词向量空间。最终建立人类语言空间到机器语言空间的变换关系,实现把单词从人类的语言(单词)翻译为机器的语言(词向量)。
4、搭建情感分类模型
基于上一步训练的语言模型,编写了一个情感分类模型,包含一个循环神经网络模型(LSTM)和一个分类器(MLP)。其主要过程为:首先,将一个句子分词,并将句子去长补短,统一为相同长度的句子,根据词嵌入矩阵将每个单词转换为对应的词向量输入循环神经网络(LSTM),得到句子的向量表征。然后将句向量作为分类器(MLP)的输入,输出二元分类预测,同样进行loss 计算和反向梯度传播训练,这里的 loss 使用交叉熵 loss。可以参考本人的代码:SentimentNet.py。主要步骤及代码段如下:
定义情感分类网络模型:


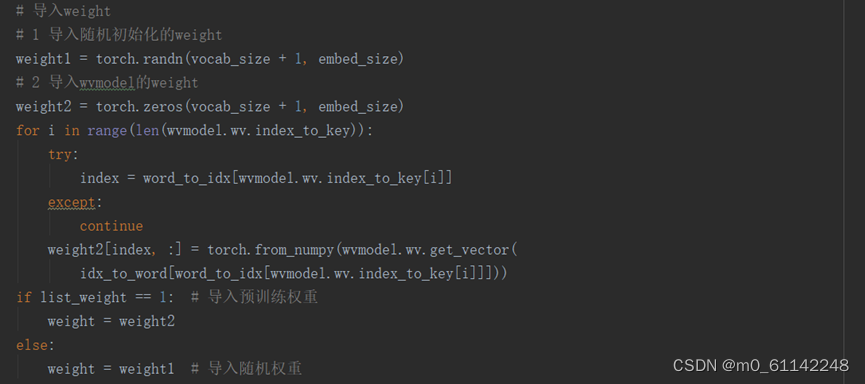
导入预训练参数:
导入wordEmbedding的权重矢量,包括两种方法:意识导入随机初始化weight,二是导入第3节中已经训练好的word2vec模型的weight。当然用第二种方法也可以导入其他预训练参数,比如GloVe等,具体的导入GloVe词向量的方法可以参考网上的公开代码。
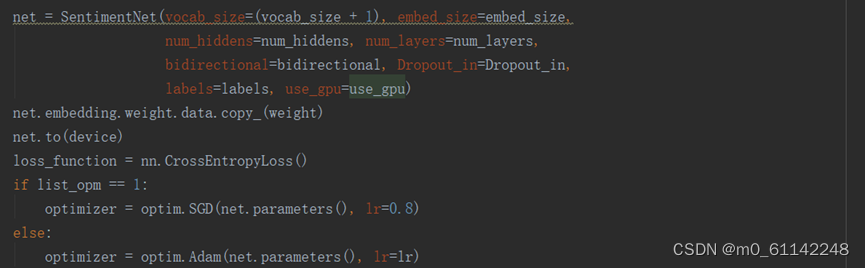
实列化模型:
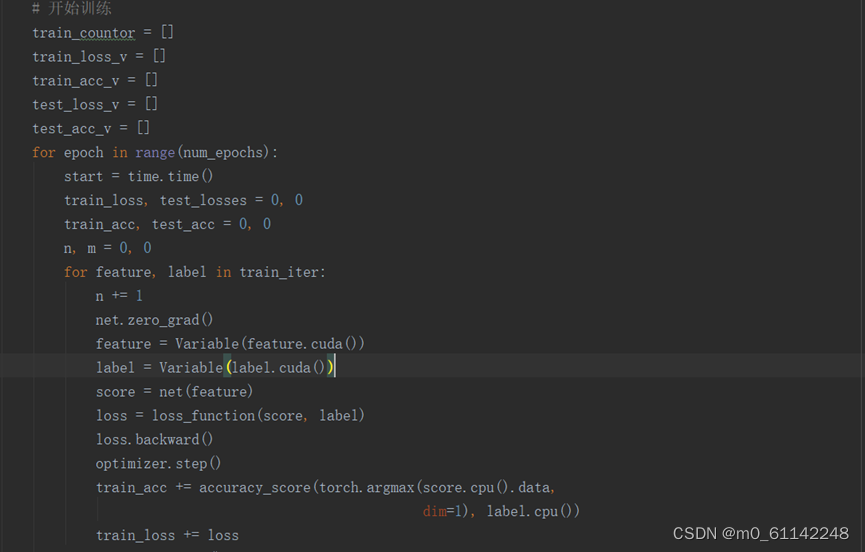
训练模型:
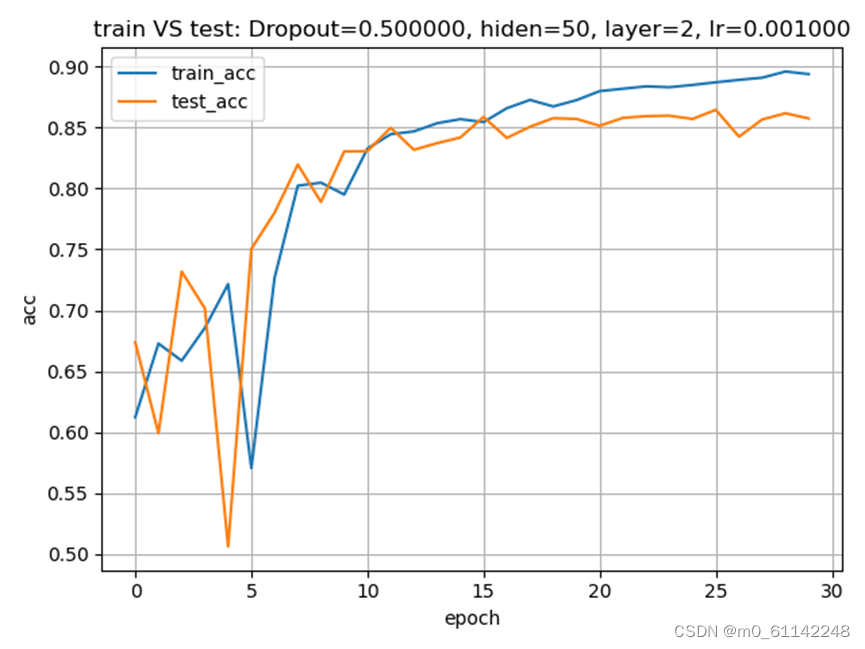
由于采用GPU进行训练,需要将训练数据特征、标签和模型加载到GPU上,然后进行训练。训练过程中记录了训练集和测试集的损失(交叉熵损失)、准确率和耗时并用matplot进行了可视化,以便于调参分析。

最终结果:
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











