







 本文详述了如何在PyTorch环境中搭建基于GPU的实验平台,利用torch_geometric处理Planetoid、PPI数据集,构建GCN模型进行链路预测任务。通过对模型层数、自环、PairNorm、DropEdge等参数的分析,展示了在Cora和Citeseer数据集上的最佳性能配置,如4层GCN、无自环、使用BatchNorm和PairNorm,以及线性激活函数。
本文详述了如何在PyTorch环境中搭建基于GPU的实验平台,利用torch_geometric处理Planetoid、PPI数据集,构建GCN模型进行链路预测任务。通过对模型层数、自环、PairNorm、DropEdge等参数的分析,展示了在Cora和Citeseer数据集上的最佳性能配置,如4层GCN、无自环、使用BatchNorm和PairNorm,以及线性激活函数。
使用pytorch 的相关神经网络库, 手动编写图卷积神经网络模型(GCN), 并在相应的图结构数据集上完成链路预测任务。本次实验的内容如下:
- 实验准备:搭建基于GPU的pytorch实验环境。
- 数据下载与预处理:使用torch_geometric.datasets、torch_geometric.loader所提供的标准数据接口Planetoid、PPI、DataLoader,将原始数据处理为方便模型训练脚本所使用的数据结构。
- 图网络模型:手动搭建GCN模型。
- 链路预测:在给定数据集上按照链路预测任务的需求自行划分训练集、验证集、测试集,并用搭建好的GCN模型进行链路预测。
- 模型训练:在给定数据集上训练模型并分析结果。
对应的源代码下载链接 :
https://download.csdn.net/download/m0_61142248/87657680
1.搭建实验环境
搭建GPU版Pytorch实验环境如下:
| 名称 | 版本 | 备注 |
| Python | 3.8 | |
| Pytorch | 1.12.1 | |
| GPU | RTX2060 | 安装对应版本的cuda |
2.图网络模型搭建
参考GCN论文,GCN的核心原理公式为 。因为邻接矩阵在迭代的每一步都是相同的,可以将上述公式中不变的部分提取出来提前处理,迭代过程中只计算变化部分,从而减少运算量。因此将上述公式分解为两步:
其中, 是图的原始邻接矩阵,D是度矩阵, 的运算在网络模型训练前实现,A是经过处理后的邻接矩阵。
在图数据的处理中实现计算,代码如下:

在网络模型中只实现 ,另外需要定义模型参数W等初始化参数以及forward函数。本次实验要求对自环、层数、 DropEdge、PairNorm、激活函数等因素分析,因此在模型 中加入了这些参数,另外模型中的in_features和out_features分别表示输入特征维度和输出特征维度。代码如下:

子函数reset_parameters代码如下:

forward函数实现计算,其中input为输入特征,adj为输入邻接矩阵(经过 运算处理),bias是偏置项,output为输出。具体代码如下:

此外,参考了PairNorm和DropEdge的论文和代码来实现PairNorm和DropEdge函数。具体代码如下:
PairNorm:

DropEdge:

3.链路预测模型搭建
在链路预测中使用的基础GCN模型与节点分类任务相同,链路预测任务的模型采用了GAE网络模型。GAE网络模型包含一个由多层GCN组成的编码器和一个内积运算组成的解码器,其中GCN基础层与前述节点分类中提到的GCN网络相同。GAE网络模型的具体实现代码如下:
GAE网络初始化部分:
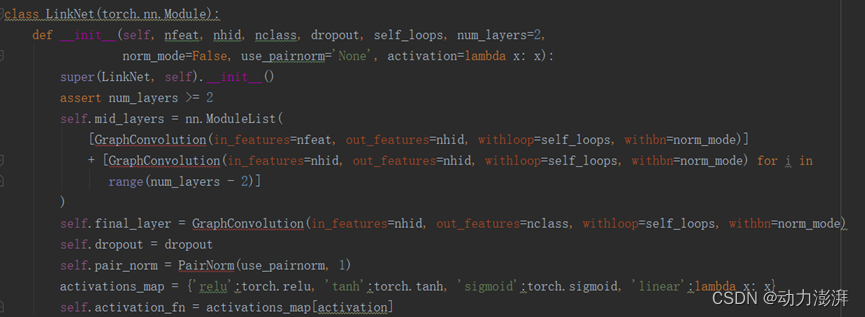
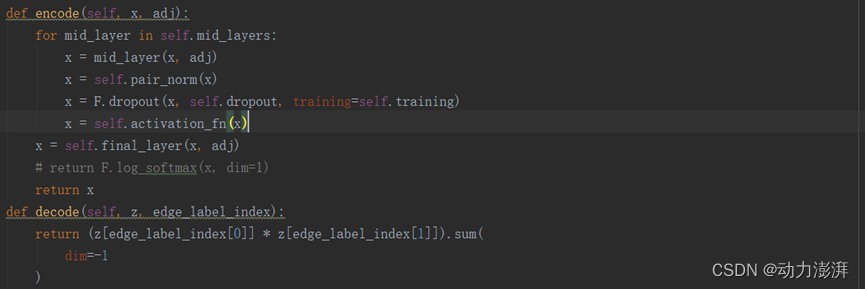
编码器与解码器:
4.Cora、Citeseer数据集预处理
数据读取,根据实验任务参数,分别读取cora和citeseer数据集。

数据集划分,在每个数据集的图中存在的链接数往往都是远小于不存在的链接数的,即图中的正样本数量远小于负样本数量。为了使模型训练较为均衡,通常先将正样本分为训练集、验证集和测试集,然后再分别从三个数据集中采样等同数量的负样本参与训练、验证以及测试。这里使用RandomLinkSplit函数将图随机划分为训练集、验证集和测试集,比例为0.8:0.1:0.1。add_negative_train_samples为False表示不对训练集进行负采样,只对测试集和验证集进行负采样,每个子集的正负样本比例为1:1。训练集的负样本在训练时采集。
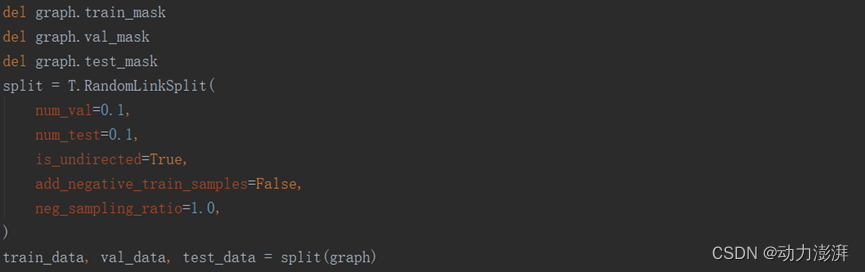
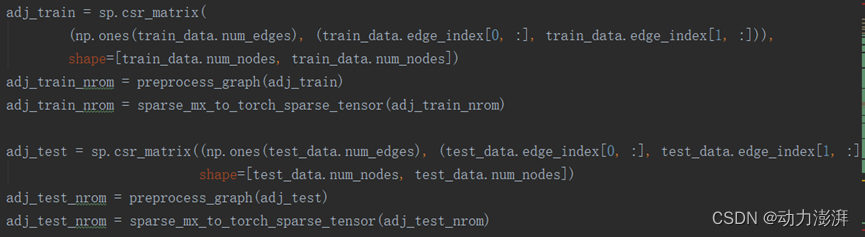
邻接矩阵处理:
5.训练与分析
依据实验要求对不同参数进行了测试分析。虽然不同参数配置下可以通过调整学习率等超参数来提高性能。但为了便于比较,训练时采取了只变动比较项,其余部分参数固定的方法来分析单个因素对模型性能的影响。其中所有测试下都固定不变的参数如下表所示:
固定不变的训练参数
测试了GCN层数为2、4、8、16、32层时图网络模型在Cora、Citeseer和PPI数据集上的分类性能以及自环、batch_norm、PairNorm和激活函数等因素对分类性能的影响。
在Cora数据集和Citeseer数据集的实验中,使用Adam优化器。学习率初始值为0.01,采用了多步衰减策略,参数为“milestones=[150, 250, 350], gamma=0.5”。损失函数使用torch.nn.functional中的nll_loss。性能评价指标为acc。
最终得到的最佳的性能和对应的训练参数如下:
| 名称 | lr | weight_decay | hidden | lradjust | dropout | epochs |
| 数值 | 0.01 | 5e-3 | 256 | Ture | 0.8 | 400 |
测试了GCN层数为2、4、8、16、32层时图网络模型在Cora和Citeseer数据集上的分类性能以及自环、batch_norm、PairNorm和激活函数等因素对分类性能的影响。
在Cora数据集和Citeseer数据集的实验中,使用Adam优化器。学习率初始值为0.01,采用了多步衰减策略,参数为“milestones=[150, 250, 350], gamma=0.5”。损失函数使用“torch.nn.BCEWithLogitsLoss()”。性能评价指标为auc。
对于数据集cora,在测试集上获得的分类acc指标为0.936,设置训练参数如下:
| 名称 | lr | weight_decay | hidden | lradjust | dropout | epochs |
| 数值 | 0.01 | 5e-3 | 256 | Ture | 0.8 | 100 |
| 名称 | num_layers | add_self_loops | add_bn | use_pairnorm | drop_edge | activation |
| 数值 | 4 | FALSE | TRUE | None | 1 | linear |
对于数据集citeseer,在测试集上获得的分类acc指标为0.946,设置训练参数如下:
| 名称 | lr | weight_decay | hidden | lradjust | dropout | epochs |
| 数值 | 0.01 | 5e-3 | 256 | Ture | 0.8 | 100 |
| 名称 | num_layers | add_self_loops | add_bn | use_pairnorm | drop_edge | activation |
| 数值 | 4 | FALSE | TRUE | None | 1 | linear |


















 807
807

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











