







01 SVM是什么
一句话看本质:支持向量机(Support Vector Machine,SVM)是一种机器学习算法,其本质在于通过找到数据集中的支持向量,构建一个最优的决策边界或超平面,以在不同类别之间实现最大间隔,实现分类。
决策边界:是一条线或超平面(二维空间中是一条线,在高维空间中是一个超平面或曲面),用于将数据集划分为多个类别。
支持向量:是训练数据集中与决策边界最近的数据点。SVM旨在最大化间隔,即超平面与每个类别的最近数据点之间的距离。
间隔:是超平面与最近数据点之间的距离。SVM的目标是找到具有最大间隔的超平面。支持向量机通过优化问题来选择最佳的决策边界,使得所有的支持向量到决策边界的距离最大化。间隔的大小直接影响到SVM的性能,较大的间隔意味着更强的分类能力和更好的泛化性能。
SVM模型训练过程:在初始阶段,超平面是随机初始化的,随着训练的进行,优化算法会不断调整超平面的位置和参数,以寻找最优的分类边界。支持向量在训练优化过程起到了关键的作用,优化算法根据支持向量的位置和类别标签,来调整超平面的参数,以获得更好的分类性能。支持向量还可以用于计算核函数,即将原始特征向量映射到高维空间中。
02 SVM有哪些应用场景
支持向量机(SVM)广泛应用于(线性和非线性多)分类问题,是主要的使用场景,而在回归问题中的应用相对较少。今天主要探讨分类应用。
| 应用领域 | 具体应用场景 |
| 分类 | 1. 文本分类 |
| 2. 图像分类 | |
| 3. 生物医学数据分类 | |
| 4. 金融欺诈检测 | |
| 5. 信用评分 | |
| 异常检测 | 1. 网络入侵检测 |
| 2. 信用卡欺诈检测 | |
| 3. 工业设备故障检测 |
03 SVM与核函数
核函数在支持向量机(SVM)中扮演着重要的角色,使其能够处理非线性问题,并在高维空间中学习复杂的决策边界。
-
核函数之所以与SVM强相关主要表现在以下方面:
-
处理非线性关系:SVM 最初是设计用于处理线性可分的问题,但许多实际问题中的数据并非总是线性可分的。通过使用核函数,SVM可以在原始特征空间中学习非线性关系。
-
映射到高维空间:核函数通过将输入特征映射到更高维的空间,使得原始特征空间中的非线性问题在高维空间中变为线性可分。
-
避免计算高维空间:核函数的设计允许在原始特征空间中计算高维空间的内积,避免了直接进行高维计算的复杂性。
-
通过特征工程手工增加一个非线性特征的案例,实现低维空间不可分到映射到高维空间可分的原理可视化
下面通过可视化来理解核函数的原理和作用。以二分类场景为例,这是一个二维不可分的数据集的可视化:
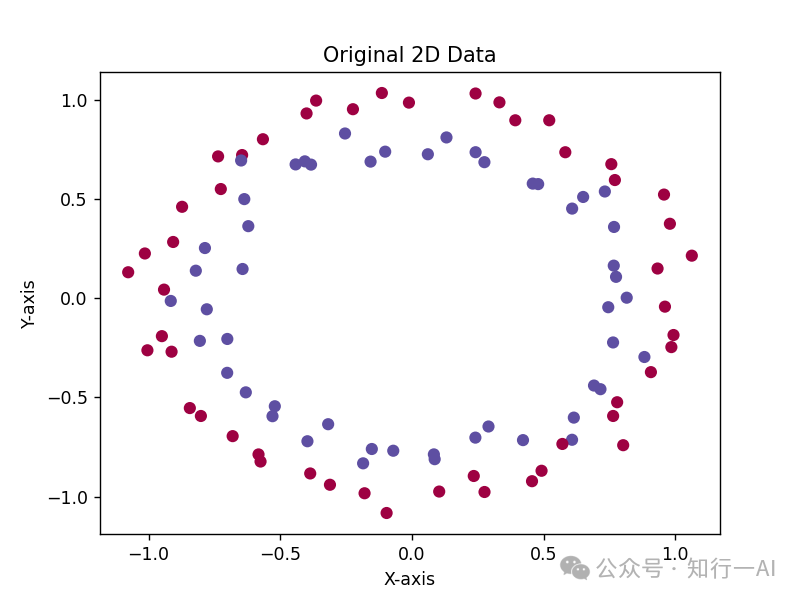
通过特征工程添加一个非线性特征X[:, 0]**2 + X[:, 1]**2,该特征(表示二维特征的平方和),与原始特征组成三维特征空间,实现二维到三维空间的映射:
# 添加一个新的非线性特征,实现升维
new_feature = X[:, 0]**2 + X[:, 1]**2
X_3d = np.column_stack((X[:, 0], X[:, 1], new_feature))
# 使用SVM进行分类
svm_clf = SVC(kernel='linear')
svm_clf.fit(X_3d, y)
# 可视化升维后的数据和决策边界
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')映射到三维空间可视化如下:
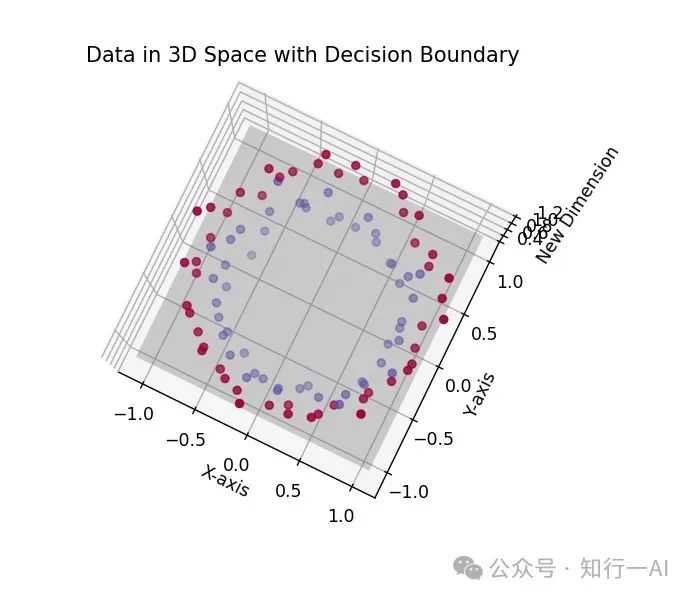
决策边界可视化,灰色部分为三维空间中实现线性分类的平面:
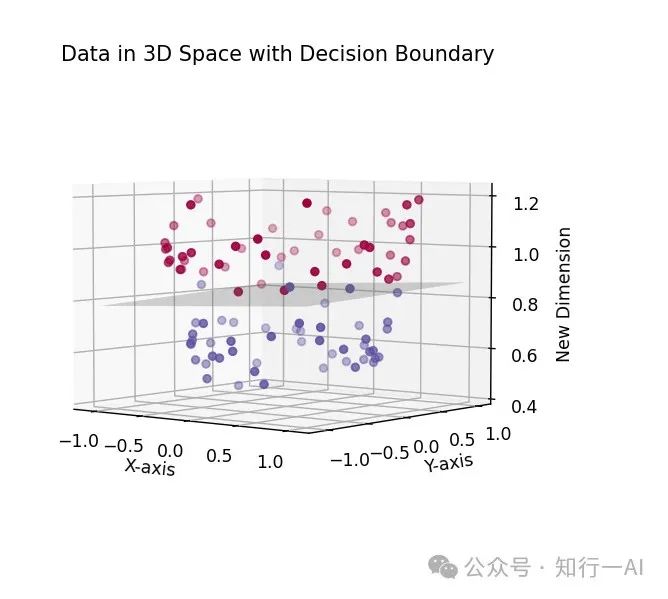
由上图知,通过在二维数据上引入一个非线性特征,将数据映射到三维空间,实现了在高维空间的线性可分。在这个三维空间中,使用线性核,SVM模型学到的线性决策边界(分割边界)是一个平面。
这种映射到高维空间的技巧帮助我们处理原始数据在低维空间中不可分的情况,通过引入更多的维度,使得数据在新的高维空间中变得线性可分。这与核函数在SVM中的工作原理是类似的,区别在于核函数并没有显式增加特征空间维度,只是做了隐式的空间映射。
理论上手动添加一个非线性特征与使用RBF核函数的作用是相似的,都是为了实现高维空间中的可分。具体来说,RBF核函数通过映射到无穷维的高维空间中,而手动添加一个非线性特征则将数据映射到一个更高维度。
# 特征工程:手动添加一个非线性特征
X_manual = np.column_stack((X, X[:, 0]**2 + X[:, 1]**2))
# 使用SVM进行分类(线性核)
clf_linear = SVC(kernel='linear')
clf_linear.fit(X, y)
# 使用SVM进行分类(RBF核)
clf_rbf = SVC(kernel='rbf', gamma=1)
clf_rbf.fit(X, y)
# 使用SVM进行分类(手动添加非线性特征后的数据)
clf_manual = SVC(kernel='linear')
clf_manual.fit(X_manual, y)然后对RBF核函数和手工添加非线性特征的线性核函数模型的决策边界进行可视化。添加非线性特征的模型是通过在三维空间中学习的,而在二维空间中进行可视化时,将三维中的决策边界(平面)在二维平面上的投影。

在两者的可视化中,它们产生的效果是相似的,都能成功地将原始数据在高维空间中划分开。不过,因为核函数使用隐式的映射,而不需要显式地计算高维特征,在计算效率和避免手工特征工程方面具有优势,RBF核函数在实际计算中更加高效。
-
常用核函数
| 核函数 | 表达式K(xi,xj) | 映射运算 | 问题类型 | 决策边界特点 |
|---|---|---|---|---|
| 线性核函数 | Xi·Xj,特征内积运算 | 无显式映射,直接在原始特征空间进行内积运算 | 线性可分或近似线性可分问题 | 超平面(直线或平面) |
| 多项式核函数 | (Xi·Xj+c)^d | 将特征映射到更高次幂的多项式空间 | 非线性问题 | 决策边界为多项式的曲面,阶数由 d 决定 |
| RBF(径向基函数)核函数 | exp(−γ∥Xi-Xj∥^2),其中γ为高斯函数的宽度参数 | 将特征映射到无穷维的高斯分布函数空间 | 非线性问题 | 决策边界为圆形或椭圆形,具有局部性和全局性影响 |
| Sigmoid核函数 | tanh(γXi·Xj+c),其中γ和c是sigmoid函数的参数 | 将特征映射到(-1,1)之间,类似于双曲正切函数 | 适用于神经网络等应用 | 决策边界为 S 形曲线,类似于神经网络的激活函数 |
-
如何选择合适的核函数?
我们希望样本在特征空间内线性可分,因此特征空间的好坏对支持向量机的性能至关重要。需注意的是,在不知道特征映射的形式时,我们并不知道什么样的核函数是合适的,而核函数也仅是隐式地定义了这个特征空间。于是核函数选择成为了支持向量机的最大变数。若核函数选择不合适,则意味着将样本映射到了一个不合适的特征空间,很可能导致性能不佳。
这方面有一些基本的经验,例如文本数据通常采用线性核,情况不明时可先采用高斯核。
周志华《机器学习》
04 逻辑回归处理的分类问题如何通过SVM来实现线性分类
动手学机器学习:一文弄懂逻辑回归前文中的Breast Cancer数据集,原始数据可视化如下:
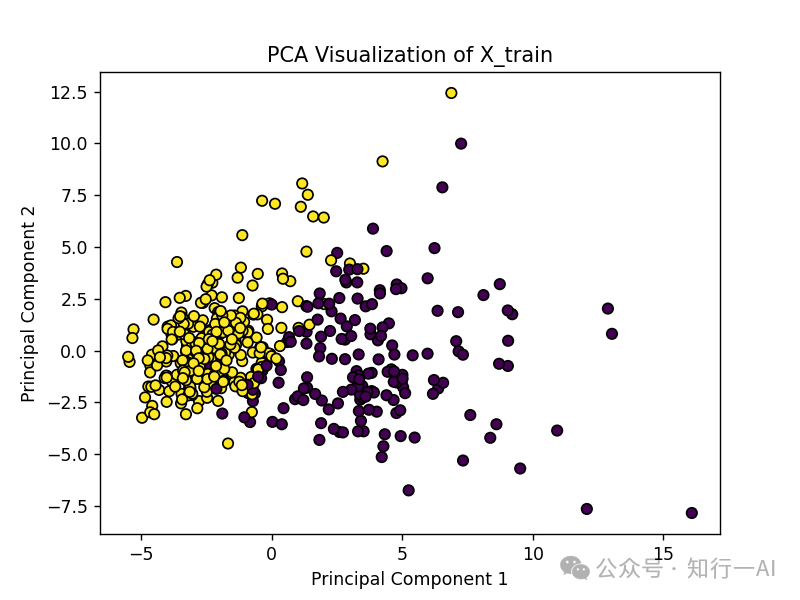
数据是线性可分的,使用线性核的SVM进行分类,模型训练代码:
# 使用线性核的SVM进行分类svm_model = SVC(kernel='linear', random_state=42)svm_model.fit(X_train_pca, y_train)
性能指标如下:
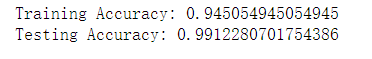

可视化决策边界(直线)如下:

(与逻辑回归的效果比对,查看动手学机器学习:一文弄懂逻辑回归 )
-
引申一下,什么情况下使用逻辑回归什么情况下使用SVM?
| 情况 | 逻辑回归 | SVM |
|---|---|---|
| 数据线性可分 | 适用,但可能欠拟合 | 适用,选择线性核函数 |
| 数据非线性 | 通常不适用,除非引入高次项 | 适用,可使用核函数(如RBF) |
| 特征数量相对较小 | 适用,计算开销较小 | 适用,但计算开销可能较大 |
| 大规模数据集 | 适用,训练速度相对较快 | 适用,但可能较慢,需要优化 |
| 需要概率估计 | 直接输出概率 | 可以估计概率,但额外计算复杂 |
| 噪声敏感性 | 相对较低 | 相对较高 |
| 可解释性 | 模型参数直接解释 | 较难解释,特别是在高维空间 |
| 复杂度 | 较简单 | 复杂,特别是使用非线性核 |
05 代码来动手完成一个实际应用
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm
from sklearn.datasets import make_circles
from sklearn.model_selection import GridSearchCV, train_test_split
from sklearn.metrics import accuracy_score
# 生成示例数据,make_circles生成一个在二维空间中不可分的数据集
X, y = make_circles(n_samples=100, noise=0.05, random_state=42)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
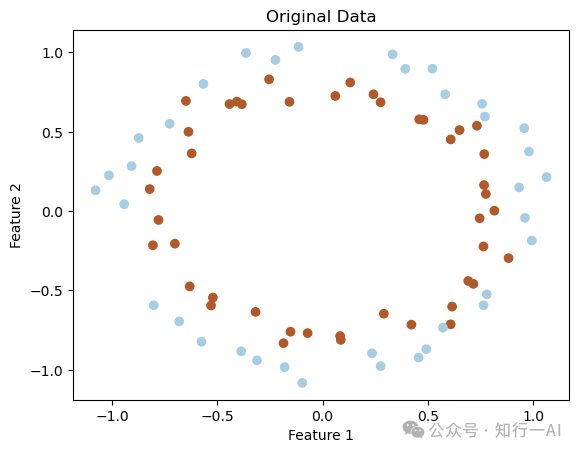
# 原始数据可视化
plt.scatter(X_train[:, 0], X_train[:, 1], c=y_train, cmap=plt.cm.Paired) # Use y_train instead of y
plt.title('Original Data')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.show()
# 使用多项式核的SVM进行分类
#使用网格搜索(GridSearchCV)来寻找最佳的C和degree参数
param_grid = {'C': [0.001, 0.01, 0.1, 1, 10, 100], 'degree': [2]}
clf_poly = svm.SVC(kernel='poly')
grid_search = GridSearchCV(clf_poly, param_grid, cv=5)
grid_search.fit(X_train, y_train)
# 获取最优的模型
best_clf = grid_search.best_estimator_
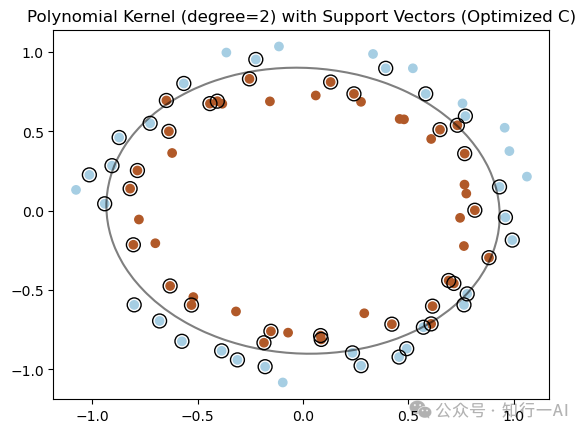
# 绘制决策边界
plt.scatter(X_train[:, 0], X_train[:, 1], c=y_train, cmap=plt.cm.Paired)
ax = plt.gca()
xlim = ax.get_xlim()
ylim = ax.get_ylim()
xx, yy = np.meshgrid(np.linspace(xlim[0], xlim[1], 50), np.linspace(ylim[0], ylim[1], 50))
Z = best_clf.decision_function(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contour(xx, yy, Z, colors='k', levels=[0], alpha=0.5, linestyles=['-'])
# 绘制支持向量
plt.scatter(best_clf.support_vectors_[:, 0], best_clf.support_vectors_[:, 1],
s=100, facecolors='none', edgecolors='k', marker='o')
plt.title('Polynomial Kernel (degree=2) with Support Vectors (Optimized C)')
plt.show()
# 输出模型参数
print("Best Parameters: ", grid_search.best_params_)
# 在训练集上的准确度
y_train_pred = best_clf.predict(X_train)
accuracy_train = accuracy_score(y_train, y_train_pred)
print(f'Training Accuracy: {accuracy_train}')
# 在测试集上的准确度
y_test_pred = best_clf.predict(X_test)
accuracy_test = accuracy_score(y_test, y_test_pred)
print(f'Testing Accuracy: {accuracy_test}')原始数据可视化,线性不可分:
SVM使用多项式核函数,其中黑色椭圆线为决策边界,实现分类如下:
调优部分使用网格搜索(GridSearchCV)来寻找最佳的C和degree参数。C是SVM中的正则化参数,控制误分类的惩罚程度。degree是多项式核函数的阶数。使用交叉验证(cv=5表示5折交叉验证)来评估每个参数组合的性能。网格搜索遍历param_grid中定义的每个参数组合,使用训练数据(X_train和y_train)来拟合模型,并评估其性能,得到模型最佳的参数组合。

在训练过程中,SVM 通过最小化损失函数(包括正则项)来找到合适的决策边界。具体来说,它通过对拉格朗日乘子进行优化,找到最大间隔的超平面。实际应用中,有些数据集可能需要进行预处理,例如文本清洗、分词,后期将对一个实际数据集进行完整的预处理和模型训练预测建模。
06 总结
SVM(支持向量机)是一种强大的机器学习模型,广泛应用于分类和回归问题。本文详细介绍了SVM的原理,特别是核函数及其在SVM中的应用。探讨了核函数的概念和作用,通过可视化核函数映射的原理,可以更直观地理解SVM如何通过非线性映射将原始数据空间映射到高维特征空间,从而实现复杂数据的分类。通过一个实际的例子,演示了如何使用Scikit-learn库进行SVM建模。本文提供了一个从理论到实践的完整视角,有助于深入理解SVM的工作原理和应用。
如有疑问或建议欢迎多交流:

07 参考文献
周志华《机器学习》















 16万+
16万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









