






本文包含了《深度强化学习与机器人实战》实验三和实验四创建环境以及运行qlearning算法的部分代码。
教程视频链接:【一起写作业】强化学习|机器人吃金币|机器人走迷宫_哔哩哔哩_bilibili
Qleaning代码原作者仓库:项目文件预览 - reinforcement-learning-code - GitCode
本文参考:《深入浅出强化学习原理入门》学习笔记(三)机器人找金币应用实例-CSDN博客
【动手学强化学习】gym 0.18.3 安装教程_gym0.18-CSDN博客
1.实验三、实验四所构建的网格预览
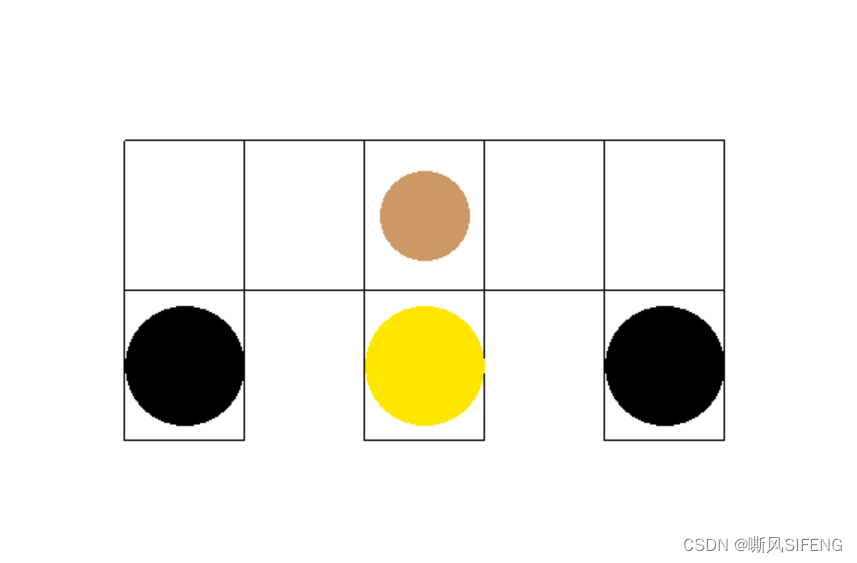

2.conda构建gym0.18.3环境
终端完成:
conda create -n newgymlab python=3.8
conda activate newgymlab
pip install --upgrade pip setuptools==57.5.0
上面第三行代码报错也可以尝试重新运行是下面的这行代码
python.exe -m pip install --upgrade pip setuptools==57.5.0pip install --upgrade pip wheel==0.37.0pip install gym==0.18.33.实验三
grid_mdp.py——添加到newgymlab环境中,文章开头视频教程链接里有讲
import logging
import numpy
import random
from gym import spaces
import gym
logger = logging.getLogger(__name__)
class GridEnv(gym.Env):
metadata = {
'render.modes': ['human', 'rgb_array'],
'video.frames_per_second': 2
}
def __init__(self):
self.states = [1,2,3,4,5,6,7,8] #状态空间
self.x=[140,220,300,380,460,140,300,460]
self.y=[250,250,250,250,250,150,150,150]
self.terminate_states = dict() #终止状态为字典格式
self.terminate_states[6] = 1
self.terminate_states[7] = 1
self.terminate_states[8] = 1
self.actions = ['n','e','s','w']
self.rewards = dict(); #回报的数据结构为字典
self.rewards['1_s'] = -1.0
self.rewards['3_s'] = 1.0
self.rewards['5_s'] = -1.0
self.t = dict(); #状态转移的数据格式为字典
self.t['1_s'] = 6
self.t['1_e'] = 2
self.t['2_w'] = 1
self.t['2_e'] = 3
self.t['3_s'] = 7
self.t['3_w'] = 2
self.t['3_e'] = 4
self.t['4_w'] = 3
self.t['4_e'] = 5
self.t['5_s'] = 8
self.t['5_w'] = 4
self.gamma = 0.8 #折扣因子
self.viewer = None
self.state = None
def getTerminal(self):
return self.terminate_states
def getGamma(self):
return self.gamma
def getStates(self):
return self.states
def getAction(self):
return self.actions
def getTerminate_states(self):
return self.terminate_states
def setAction(self,s):
self.state=s
def _step(self, action):
#系统当前状态
state = self.state
if state in self.terminate_states:
return state, 0, True, {}
key = "%d_%s"%(state, action) #将状态和动作组成字典的键值
#状态转移
if key in self.t:
next_state = self.t[key]
else:
next_state = state
self.state = next_state
is_terminal = False
if next_state in self.terminate_states:
is_terminal = True
if key not in self.rewards:
r = 0.0
else:
r = self.rewards[key]
return next_state, r,is_terminal,{}
def _reset(self):
self.state = self.states[int(random.random() * len(self.states))]
return self.state
def _seed(self, seed=None):
self.np_random, seed = seeding.np_random(seed)
return [seed]
def render(self, mode='human', close=False):
if close:
if self.viewer is not None:
self.viewer.close()
self.viewer = None
return
screen_width = 600
screen_height = 400
if self.viewer is None:
from gym.envs.classic_control import rendering
self.viewer = rendering.Viewer(screen_width, screen_height)
#创建网格世界
self.line1 = rendering.Line((100,300),(500,300))
self.line2 = rendering.Line((100, 200), (500, 200))
self.line3 = rendering.Line((100, 300), (100, 100))
self.line4 = rendering.Line((180, 300), (180, 100))
self.line5 = rendering.Line((260, 300), (260, 100))
self.line6 = rendering.Line((340, 300), (340, 100))
self.line7 = rendering.Line((420, 300), (420, 100))
self.line8 = rendering.Line((500, 300), (500, 100))
self.line9 = rendering.Line((100, 100), (180, 100))
self.line10 = rendering.Line((260, 100), (340, 100))
self.line11 = rendering.Line((420, 100), (500, 100))
#创建第一个骷髅
self.kulo1 = rendering.make_circle(40)
self.circletrans = rendering.Transform(translation=(140,150))
self.kulo1.add_attr(self.circletrans)
self.kulo1.set_color(0,0,0)
#创建第二个骷髅
self.kulo2 = rendering.make_circle(40)
self.circletrans = rendering.Transform(translation=(460, 150))
self.kulo2.add_attr(self.circletrans)
self.kulo2.set_color(0, 0, 0)
#创建金条
self.gold = rendering.make_circle(40)
self.circletrans = rendering.Transform(translation=(300, 150))
self.gold.add_attr(self.circletrans)
self.gold.set_color(1, 0.9, 0)
#创建机器人
self.robot= rendering.make_circle(30)
self.robotrans = rendering.Transform()
self.robot.add_attr(self.robotrans)
self.robot.set_color(0.8, 0.6, 0.4)
self.line1.set_color(0, 0, 0)
self.line2.set_color(0, 0, 0)
self.line3.set_color(0, 0, 0)
self.line4.set_color(0, 0, 0)
self.line5.set_color(0, 0, 0)
self.line6.set_color(0, 0, 0)
self.line7.set_color(0, 0, 0)
self.line8.set_color(0, 0, 0)
self.line9.set_color(0, 0, 0)
self.line10.set_color(0, 0, 0)
self.line11.set_color(0, 0, 0)
self.viewer.add_geom(self.line1)
self.viewer.add_geom(self.line2)
self.viewer.add_geom(self.line3)
self.viewer.add_geom(self.line4)
self.viewer.add_geom(self.line5)
self.viewer.add_geom(self.line6)
self.viewer.add_geom(self.line7)
self.viewer.add_geom(self.line8)
self.viewer.add_geom(self.line9)
self.viewer.add_geom(self.line10)
self.viewer.add_geom(self.line11)
self.viewer.add_geom(self.kulo1)
self.viewer.add_geom(self.kulo2)
self.viewer.add_geom(self.gold)
self.viewer.add_geom(self.robot)
if self.state is None: return None
#self.robotrans.set_translation(self.x[self.state-1],self.y[self.state-1])
self.robotrans.set_translation(self.x[self.state-1], self.y[self.state- 1])
return self.viewer.render(return_rgb_array=mode == 'rgb_array')
grid_mdp.py同一个文件夹的__init__文件需要添加
from gym.envs.classic_control.grid_mdp import GridEnvgrid_mdp.py上一层文件夹__init__文件需要添加
register (
id= 'GridWorld-v0',
entry_point='gym.envs.classic_control:GridEnv',
max_episode_steps=200, reward_threshold=100.0,
)grid_mdp.py上一层文件夹registration文件
import re
import copy
import importlib
import warnings
from gym import error, logger
# This format is true today, but it's *not* an official spec.
# [username/](env-name)-v(version) env-name is group 1, version is group 2
#
# 2016-10-31: We're experimentally expanding the environment ID format
# to include an optional username.
env_id_re = re.compile(r'^(?:[\w:-]+\/)?([\w:.-]+)-v(\d+)$')
def load(name):
mod_name, attr_name = name.split(":")
mod = importlib.import_module(mod_name)
fn = getattr(mod, attr_name)
return fn
class EnvSpec(object):
"""A specification for a particular instance of the environment. Used
to register the parameters for official evaluations.
Args:
id (str): The official environment ID
entry_point (Optional[str]): The Python entrypoint of the environment class (e.g. module.name:Class)
reward_threshold (Optional[int]): The reward threshold before the task is considered solved
nondeterministic (bool): Whether this environment is non-deterministic even after seeding
max_episode_steps (Optional[int]): The maximum number of steps that an episode can consist of
kwargs (dict): The kwargs to pass to the environment class
"""
def __init__(self, id, entry_point=None, reward_threshold=None, nondeterministic=False, max_episode_steps=None, kwargs=None):
self.id = id
self.entry_point = entry_point
self.reward_threshold = reward_threshold
self.nondeterministic = nondeterministic
self.max_episode_steps = max_episode_steps
self._kwargs = {} if kwargs is None else kwargs
match = env_id_re.search(id)
if not match:
raise error.Error('Attempted to register malformed environment ID: {}. (Currently all IDs must be of the form {}.)'.format(id, env_id_re.pattern))
self._env_name = match.group(1)
def make(self, **kwargs):
"""Instantiates an instance of the environment with appropriate kwargs"""
if self.entry_point is None:
raise error.Error('Attempting to make deprecated env {}. (HINT: is there a newer registered version of this env?)'.format(self.id))
_kwargs = self._kwargs.copy()
_kwargs.update(kwargs)
if callable(self.entry_point):
env = self.entry_point(**_kwargs)
else:
cls = load(self.entry_point)
env = cls(**_kwargs)
# Make the environment aware of which spec it came from.
spec = copy.deepcopy(self)
spec._kwargs = _kwargs
env.unwrapped.spec = spec
return env
def __repr__(self):
return "EnvSpec({})".format(self.id)
class EnvRegistry(object):
"""Register an env by ID. IDs remain stable over time and are
guaranteed to resolve to the same environment dynamics (or be
desupported). The goal is that results on a particular environment
should always be comparable, and not depend on the version of the
code that was running.
"""
def __init__(self):
self.env_specs = {}
def make(self, path, **kwargs):
if len(kwargs) > 0:
logger.info('Making new env: %s (%s)', path, kwargs)
else:
logger.info('Making new env: %s', path)
spec = self.spec(path)
env = spec.make(**kwargs)
# We used to have people override _reset/_step rather than
# reset/step. Set _gym_disable_underscore_compat = True on
# your environment if you use these methods and don't want
# compatibility code to be invoked.
if hasattr(env, "_reset") and hasattr(env, "_step") and not getattr(env, "_gym_disable_underscore_compat", False):
patch_deprecated_methods(env)
if env.spec.max_episode_steps is not None:
from gym.wrappers.time_limit import TimeLimit
env = TimeLimit(env, max_episode_steps=env.spec.max_episode_steps)
return env
def all(self):
return self.env_specs.values()
def spec(self, path):
if ':' in path:
mod_name, _sep, id = path.partition(':')
try:
importlib.import_module(mod_name)
# catch ImportError for python2.7 compatibility
except ImportError:
raise error.Error('A module ({}) was specified for the environment but was not found, make sure the package is installed with `pip install` before calling `gym.make()`'.format(mod_name))
else:
id = path
match = env_id_re.search(id)
if not match:
raise error.Error('Attempted to look up malformed environment ID: {}. (Currently all IDs must be of the form {}.)'.format(id.encode('utf-8'), env_id_re.pattern))
try:
return self.env_specs[id]
except KeyError:
# Parse the env name and check to see if it matches the non-version
# part of a valid env (could also check the exact number here)
env_name = match.group(1)
matching_envs = [valid_env_name for valid_env_name, valid_env_spec in self.env_specs.items()
if env_name == valid_env_spec._env_name]
if matching_envs:
raise error.DeprecatedEnv('Env {} not found (valid versions include {})'.format(id, matching_envs))
else:
raise error.UnregisteredEnv('No registered env with id: {}'.format(id))
def register(self, id, **kwargs):
if id in self.env_specs:
raise error.Error('Cannot re-register id: {}'.format(id))
self.env_specs[id] = EnvSpec(id, **kwargs)
# Have a global registry
registry = EnvRegistry()
def register(id, **kwargs):
return registry.register(id, **kwargs)
def make(id, **kwargs):
return registry.make(id, **kwargs)
def spec(id):
return registry.spec(id)
warn_once = True
def patch_deprecated_methods(env):
"""
Methods renamed from '_method' to 'method', render() no longer has 'close' parameter, close is a separate method.
For backward compatibility, this makes it possible to work with unmodified environments.
"""
global warn_once
if warn_once:
logger.warn("Environment '%s' has deprecated methods '_step' and '_reset' rather than 'step' and 'reset'. Compatibility code invoked. Set _gym_disable_underscore_compat = True to disable this behavior." % str(type(env)))
warn_once = False
env.reset = env._reset
env.step = env._step
env.seed = env._seed
def _render(mode):
return env._render(mode, close=False)
def close():
env._render("human", close=True)
env._render = _render
env.close = close
测试文件:
import gym
import time
# 创建 GridWorld 环境
env = gym.make('GridWorld-v0')
# 渲染初始状态
env.reset()
# 渲染新状态
env.render()
time.sleep(10)
qlearning.py
import sys
import gym
import random
random.seed(0)
import time
import matplotlib.pyplot as plt
grid = gym.make('GridWorld-v0')
# grid=env.env #创建网格世界
states = grid.env.getStates() #获得网格世界的状态空间
actions = grid.env.getAction() #获得网格世界的动作空间
gamma = grid.env.getGamma() #获得折扣因子
#计算当前策略和最优策略之间的差
best = dict() #储存最优行为值函数
def read_best():
f = open("best_qfunc")
for line in f:
line = line.strip()
if len(line) == 0: continue
eles = line.split(":")
best[eles[0]] = float(eles[1])
#计算值函数的误差
def compute_error(qfunc):
sum1 = 0.0
for key in qfunc:
error = qfunc[key] -best[key]
sum1 += error *error
return sum1
# 贪婪策略
def greedy(qfunc, state):
amax = 0
key = "%d_%s" % (state, actions[0])
qmax = qfunc[key]
for i in range(len(actions)): # 扫描动作空间得到最大动作值函数
key = "%d_%s" % (state, actions[i])
q = qfunc[key]
if qmax < q:
qmax = q
amax = i
return actions[amax]
#######epsilon贪婪策略
def epsilon_greedy(qfunc, state, epsilon):
amax = 0
key = "%d_%s"%(state, actions[0])
qmax = qfunc[key]
for i in range(len(actions)): #扫描动作空间得到最大动作值函数
key = "%d_%s"%(state, actions[i])
q = qfunc[key]
if qmax < q:
qmax = q
amax = i
#概率部分
pro = [0.0 for i in range(len(actions))]
pro[amax] += 1-epsilon
for i in range(len(actions)):
pro[i] += epsilon/len(actions)
##选择动作
r = random.random()
s = 0.0
for i in range(len(actions)):
s += pro[i]
if s>= r: return actions[i]
return actions[len(actions)-1]
def qlearning(num_iter1, alpha, epsilon):
x = []
y = []
qfunc = dict() #行为值函数为字典
#初始化行为值函数为0
for s in states:
for a in actions:
key = "%d_%s"%(s,a)
qfunc[key] = 0.0
for iter1 in range(num_iter1):
x.append(iter1)
y.append(compute_error(qfunc))
#初始化初始状态
s = grid.reset()
a = actions[int(random.random()*len(actions))]
t = False
count = 0
while False == t and count <100:
key = "%d_%s"%(s, a)
#与环境进行一次交互,从环境中得到新的状态及回报
s1, r, t1, i =grid.step(a)
key1 = ""
#s1处的最大动作
a1 = greedy(qfunc, s1)
key1 = "%d_%s"%(s1, a1)
#利用qlearning方法更新值函数
qfunc[key] = qfunc[key] + alpha*(r + gamma * qfunc[key1]-qfunc[key])
#转到下一个状态
s = s1;
a = epsilon_greedy(qfunc, s1, epsilon)
count += 1
plt.plot(x,y,"-.,",label ="q alpha=%2.1f epsilon=%2.1f"%(alpha,epsilon))
return qfunclearning_and_test.py
import sys
import gym
from qlearning import *
import time
from gym import wrappers
#main函数
if __name__ == "__main__":
# grid = grid_mdp.Grid_Mdp() # 创建网格世界
states = grid.getStates() # 获得网格世界的状态空间
actions = grid.getAction() # 获得网格世界的动作空间
sleeptime = 0.1
terminate_states= grid.env.getTerminate_states()
#读入最优值函数
read_best()
# plt.figure(figsize=(12,6))
#训练
qfunc = dict()
qfunc = qlearning(num_iter1=500, alpha=0.2, epsilon=0.2)
#画图
plt.xlabel("number of iterations")
plt.ylabel("square errors")
plt.legend()
# 显示误差图像
plt.show()
time.sleep(sleeptime)
#学到的值函数
for s in states:
for a in actions:
key = "%d_%s"%(s,a)
print("the qfunc of key (%s) is %f" %(key, qfunc[key]) )
qfunc[key]
#学到的策略为:
print("the learned policy is:")
for i in range(len(states)):
if states[i] in terminate_states:
print("the state %d is terminate_states"%(states[i]))
else:
print("the policy of state %d is (%s)" % (states[i], greedy(qfunc, states[i])))
# 设置系统初始状态
s0 = 1
grid.env.setAction(s0)
# 对训练好的策略进行测试
#grid = wrappers.Monitor(grid, './robotfindgold', force=True) # 记录回放动画
#随机初始化,寻找金币的路径
for i in range(20):
#随机初始化
s0 = grid.reset()
grid.render()
time.sleep(sleeptime)
t = False
count = 0
#判断随机状态是否在终止状态中
if s0 in terminate_states:
print("reach the terminate state %d" % (s0))
else:
while False == t and count < 100:
a1 = greedy(qfunc, s0)
print(s0, a1)
grid.render()
time.sleep(sleeptime)
key = "%d_%s" % (s0, a)
# 与环境进行一次交互,从环境中得到新的状态及回报
s1, r, t, i = grid.step(a1)
if True == t:
#打印终止状态
print(s1)
grid.render()
time.sleep(sleeptime)
print("reach the terminate state %d" % (s1))
# s1处的最大动作
s0 = s1
count += 1best_qfunc文件需要去作者原仓库下载,链接在文章开头
4.实验四
grid_mdp2.py同一个文件夹的__init__文件需要添加
from gym.envs.classic_control.grid_mdp2 import NewGridEnvgrid_mdp2.py上一层文件夹__init__文件需要添加
register (
id= 'GridWorld-v1',
entry_point='gym.envs.classic_control:NewGridEnv',
max_episode_steps=200, reward_threshold=100.0,
)grid_mdp2.py中的5*5网格按照下图自行构建。例如;
import logging
import numpy
import random
from gym import spaces
import gym
logger = logging.getLogger(__name__)
class NewGridEnv(gym.Env):
metadata = {
'render.modes': ['human', 'rgb_array'],
'video.frames_per_second': 2
}
def __init__(self):
self.states = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25]
self.x=[150,250,350,450,550, 150,250,350,450,550, 150,250,350,450,550, 150,250,350,450,550, 150,250,350,450,550]
self.y=[550,550,550,550,550, 450,450,450,450,450, 350,350,350,350,350, 250,250,250,250,250, 150,150,150,150,150]
# 终止状态字典
self.terminate_states = dict()
self.terminate_states[4] = 1
self.terminate_states[9] = 1
self.terminate_states[11] = 1
self.terminate_states[12] = 1
self.terminate_states[23] = 1
self.terminate_states[24] = 1
self.terminate_states[25] = 1
self.terminate_states[15] = 1 # 金币位置
self.actions = ['n', 'e', 's', 'w']#上 右 下 左
# 回报的数据结构为字典
self.rewards = dict();
self.rewards['3_e'] = -100.0
self.rewards['5_w'] = -100.0
self.rewards['6_s'] = -100.0
self.rewards['7_s'] = -100.0
self.rewards['8_e'] = -100.0
self.rewards['10_w'] = -100.0
self.rewards['13_w'] = -100.0
self.rewards['14_n'] = -100.0
self.rewards['16_n'] = -100.0
self.rewards['17_n'] = -100.0
self.rewards['18_s'] = -100.0
self.rewards['19_s'] = -100.0
self.rewards['20_s'] = -100.0
self.rewards['22_e'] = -100.0
self.rewards['10_s'] = 100.0
self.rewards['20_n'] = 100.0
self.rewards['14_e'] = 100.0
# 撞墙
self.rewards['1_w'] = -10.0
self.rewards['1_n'] = -10.0
self.rewards['2_n'] = -10.0
self.rewards['3_n'] = -10.0
self.rewards['5_n'] = -10.0
self.rewards['5_e'] = -10.0
self.rewards['6_w'] = -10.0
self.rewards['10_e'] = -10.0
self.rewards['16_w'] = -10.0
self.rewards['20_e'] = -10.0
self.rewards['21_w'] = -10.0
self.rewards['21_s'] = -10.0
self.rewards['22_s'] = -10.0
# 状态转移的数据格式为字典
self.t = dict();
self.t['1_e'] = 2
self.t['1_s'] = 6
self.t['2_e'] = 3
self.t['2_s'] = 7
self.t['2_w'] = 1
self.t['3_e'] = 4
self.t['3_s'] = 8
self.t['3_w'] = 2
self.t['5_s'] = 10
self.t['5_w'] = 4
self.t['6_n'] = 1
self.t['6_e'] = 7
self.t['6_s'] = 11
self.t['7_n'] = 2
self.t['7_e'] = 8
self.t['7_s'] = 12
self.t['7_w'] = 6
self.t['8_n'] = 3
self.t['8_e'] = 9
self.t['8_s'] = 13
self.t['8_w'] = 7
self.t['10_n'] = 5
self.t['10_s'] = 15
self.t['10_w'] = 9
self.t['13_n'] = 8
self.t['13_e'] = 14
self.t['13_s'] = 18
self.t['13_w'] = 12
self.t['14_n'] = 9
self.t['14_e'] = 15
self.t['14_s'] = 19
self.t['14_w'] = 13
self.t['16_n'] = 11
self.t['16_e'] = 17
self.t['16_s'] = 21
self.t['17_n'] = 12
self.t['17_e'] = 18
self.t['17_s'] = 22
self.t['17_w'] = 16
self.t['18_n'] = 13
self.t['18_e'] = 19
self.t['18_s'] = 23
self.t['18_w'] = 17
self.t['19_n'] = 14
self.t['19_e'] = 20
self.t['19_s'] = 24
self.t['19_w'] = 18
self.t['20_n'] = 15
self.t['20_s'] = 25
self.t['20_w'] = 19
self.t['21_n'] = 16
self.t['21_e'] = 22
self.t['22_n'] = 17
self.t['22_e'] = 23
self.t['22_w'] = 21
# 折扣因子
self.gamma = 0.8
self.viewer = None
self.state = None
def getTerminal(self):
return self.terminate_states
def getGamma(self):
return self.gamma
def getStates(self):
return self.states
def getAction(self):
return self.actions
def getTerminate_states(self):
return self.terminate_states
def setAction(self,s):
self.state=s
def _step(self, action):
# 系统当前状态
state = self.state
if state in self.terminate_states:
return state, 0, True, {}
key = "%d_%s" % (state, action)
#状态转移
if key in self.t:
next_state = self.t[key]
else:
next_state = state
self.state = next_state
is_terminal = False
if next_state in self.terminate_states:
is_terminal = True
if key not in self.rewards:
r = -1.0
else:
r = self.rewards[key]
return next_state, r,is_terminal,{}
def _reset(self):
self.state = self.states[int(random.random() * len(self.states))]
return self.state
def _seed(self, seed=None):
self.np_random, seed = seeding.np_random(seed)
return [seed]
def render(self, mode='human', close=False):
if close:
if self.viewer is not None:
self.viewer.close()
self.viewer = None
return
screen_width = 700
screen_height = 700
if self.viewer is None:
from gym.envs.classic_control import rendering
self.viewer = rendering.Viewer(screen_width, screen_height)
# 创建网格世界
# 更新网格线的位置
line1_start = (100, 100)
line1_end = (600, 100)
line2_start = (100, 200)
line2_end = (600, 200)
line3_start = (100, 300)
line3_end = (600, 300)
line4_start = (100, 400)
line4_end = (600, 400)
line5_start = (100, 500)
line5_end = (600, 500)
line6_start = (100, 600)
line6_end = (600, 600)
line7_start = (100, 100)
line7_end = (100, 600)
line8_start = (200, 100)
line8_end = (200, 600)
line9_start = (300, 100)
line9_end = (300, 600)
line10_start = (400, 100)
line10_end = (400, 600)
line11_start = (500, 100)
line11_end = (500, 600)
line12_start = (600, 100)
line12_end = (600, 600)
self.line1 = rendering.Line(line1_start, line1_end)
self.line2 = rendering.Line(line2_start, line2_end)
self.line3 = rendering.Line(line3_start, line3_end)
self.line4 = rendering.Line(line4_start, line4_end)
self.line5 = rendering.Line(line5_start, line5_end)
self.line6 = rendering.Line(line6_start, line6_end)
self.line7 = rendering.Line(line7_start, line7_end)
self.line8 = rendering.Line(line8_start, line8_end)
self.line9 = rendering.Line(line9_start, line9_end)
self.line10 = rendering.Line(line10_start, line10_end)
self.line11 = rendering.Line(line11_start, line11_end)
self.line12 = rendering.Line(line12_start, line12_end)
#创建骷髅
self.kulo1 = rendering.make_circle(40)
self.circletrans = rendering.Transform(translation=(450, 550))
self.kulo1.add_attr(self.circletrans)
self.kulo1.set_color(0,0,0)
self.kulo2 = rendering.make_circle(40)
self.circletrans = rendering.Transform(translation=(450, 450))
self.kulo2.add_attr(self.circletrans)
self.kulo2.set_color(0,0,0)
self.kulo3 = rendering.make_circle(40)
self.circletrans = rendering.Transform(translation=(150, 350))
self.kulo3.add_attr(self.circletrans)
self.kulo3.set_color(0,0,0)
self.kulo4 = rendering.make_circle(40)
self.circletrans = rendering.Transform(translation=(250, 350))
self.kulo4.add_attr(self.circletrans)
self.kulo4.set_color(0,0,0)
self.kulo5 = rendering.make_circle(40)
self.circletrans = rendering.Transform(translation=(350, 150))
self.kulo5.add_attr(self.circletrans)
self.kulo5.set_color(0,0,0)
self.kulo6 = rendering.make_circle(40)
self.circletrans = rendering.Transform(translation=(450, 150))
self.kulo6.add_attr(self.circletrans)
self.kulo6.set_color(0,0,0)
self.kulo7 = rendering.make_circle(40)
self.circletrans = rendering.Transform(translation=(550, 150))
self.kulo7.add_attr(self.circletrans)
self.kulo7.set_color(0,0,0)
#创建金条
self.gold = rendering.make_circle(40)
self.circletrans = rendering.Transform(translation=(550, 350))
self.gold.add_attr(self.circletrans)
self.gold.set_color(1, 0.9, 0)
#创建机器人
self.robot= rendering.make_circle(30)
self.robotrans = rendering.Transform()
self.robot.add_attr(self.robotrans)
self.robot.set_color(0.8,0.6,0.4)
self.line1.set_color(0, 0, 0)
self.line2.set_color(0, 0, 0)
self.line3.set_color(0, 0, 0)
self.line4.set_color(0, 0, 0)
self.line5.set_color(0, 0, 0)
self.line6.set_color(0, 0, 0)
self.line7.set_color(0, 0, 0)
self.line8.set_color(0, 0, 0)
self.line9.set_color(0, 0, 0)
self.line10.set_color(0, 0, 0)
self.line11.set_color(0, 0, 0)
self.line12.set_color(0, 0, 0)
self.viewer.add_geom(self.line1)
self.viewer.add_geom(self.line2)
self.viewer.add_geom(self.line3)
self.viewer.add_geom(self.line4)
self.viewer.add_geom(self.line5)
self.viewer.add_geom(self.line6)
self.viewer.add_geom(self.line7)
self.viewer.add_geom(self.line8)
self.viewer.add_geom(self.line9)
self.viewer.add_geom(self.line10)
self.viewer.add_geom(self.line11)
self.viewer.add_geom(self.line12)
self.viewer.add_geom(self.kulo1)
self.viewer.add_geom(self.kulo2)
self.viewer.add_geom(self.kulo3)
self.viewer.add_geom(self.kulo4)
self.viewer.add_geom(self.kulo5)
self.viewer.add_geom(self.kulo6)
self.viewer.add_geom(self.kulo7)
self.viewer.add_geom(self.gold)
self.viewer.add_geom(self.robot)
if self.state is None: return None
self.robotrans.set_translation(self.x[self.state-1], self.y[self.state- 1])
return self.viewer.render(return_rgb_array=mode == 'rgb_array')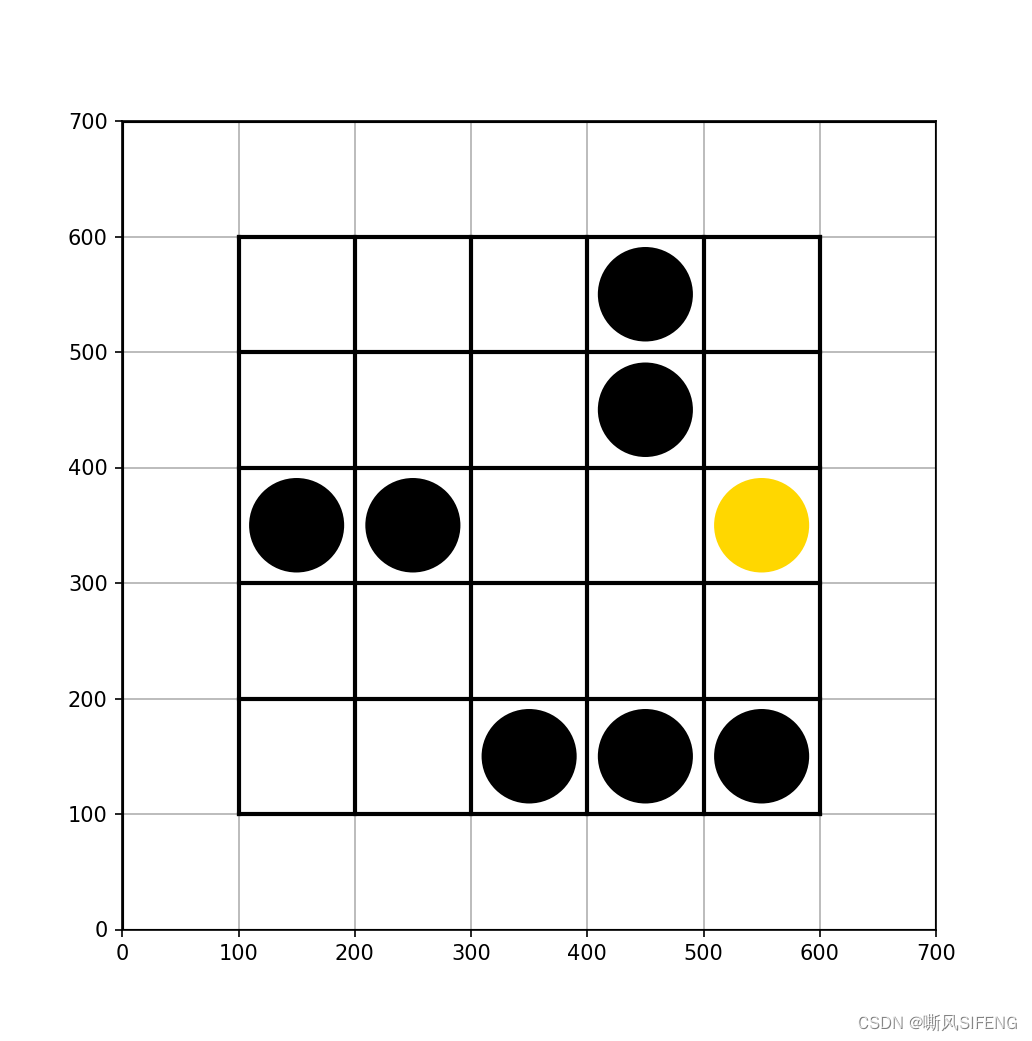
如若需要绘制5x5新环境的q值与bestQ值之间的误差曲线,首先需要在qlearning.py中添加新代码来保存学习过程中找到的最优Q值(即bestQ值)到本地,以.txt文本格式存储。随后,在计算误差时,程序应重新加载这个保存的最佳Q值文件。最后,基于这些q值和bestQ值,程序将输出相应的误差曲线图像。
















 4552
4552











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









