







最后的话
最近很多小伙伴找我要Linux学习资料,于是我翻箱倒柜,整理了一些优质资源,涵盖视频、电子书、PPT等共享给大家!
资料预览
给大家整理的视频资料:
给大家整理的电子书资料:

如果本文对你有帮助,欢迎点赞、收藏、转发给朋友,让我有持续创作的动力!
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
-
集群创建:ClusterAPI 负责集群的创建,KubeNode 不提供此功能。
-
节点创建:ClusterAPI 和 KubeNode 都可以创建节点。
-
节点组件管理和终态维持:ClusterAPI 没有提供相应的功能,KubeNode 可以管理节点组件并保持终态。
-
节点故障自愈:ClusterAPI 主要提供基于节点健康状态重建节点的自愈能力;KubeNode 提供了更丰富的节点组件自愈功能,能对节点上的各种软硬件故障进行自愈修复。
总的来说,KubeNode 可以和 ClusterAPI 一起配合工作,是对 ClusterAPI 的一个很好补充。
这里提到的节点组件,是指运行在节点上的 kubelet,Docker 的软件,阿里内部使用 Pouch 作为我们的容器运行时。除了 kubelet,Pouch 这些调度必须的组件外,还有用于分布式容器存储、监控采集、安全容器、故障检测等总共十多个组件。
通常安装升级 kubelet,Docker 是通过类似 Ansible 等面向过程的一次性动作来完成的。在长时间运行过程中,软件版本被意外修改或是碰到 bug 不能工作的问题是很常见的,同时这些组件在阿里巴巴的迭代速度非常快,往往一两周就需要发布推平一个版本。为了满足组件快速迭代又能安全升级、版本一致的需求,阿里巴巴自研了 KubeNode,通过将节点以及节点组件通过 K8s CRD 的方式进行描述,并进行面向终态的管理,从而确保版本一致性,配置一致性以及运行态正确性。
2. KubeNode - Machine Operator

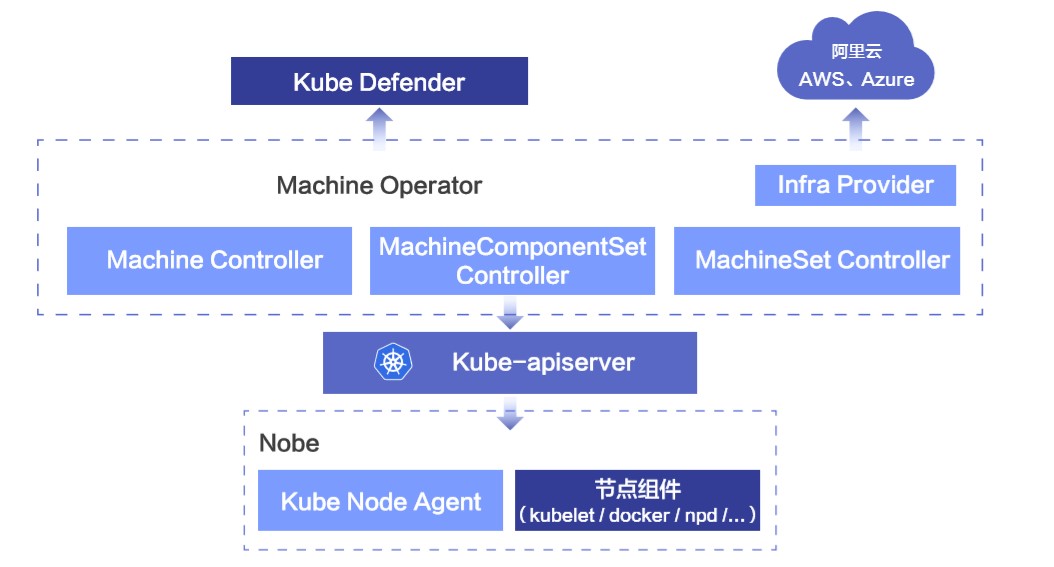
上图是 Machine Operator 的架构,一个标准的 Operator 设计:扩展的一组 CRD 再加上中心的控制器。
CRD 定义包括:跟节点相关的 Machine、MachineSet,以及跟节点组件相关的 MachineComponent、MachineComponentSet。
中心端的控制器包括:Machine Controller、MachineSet Controller、MachineComponentSet Controller,分别用来控制节点的创建、导入,节点组件的安装、升级。
Infra Provider 具有可扩展性,可以对接不同的云厂商,目前只对接了阿里云,但是也可通过实现相应的 Provider 实现对接 AWS、Azure 等不同的云厂商。
单机上的 KubeNode 负责 watch CRD 资源,当发现有新的对象实例时,则进行节点组件的安装升级,定期检查各个组件是否运行正常,并上报组件的运行状态。
1)Use Case:节点导入
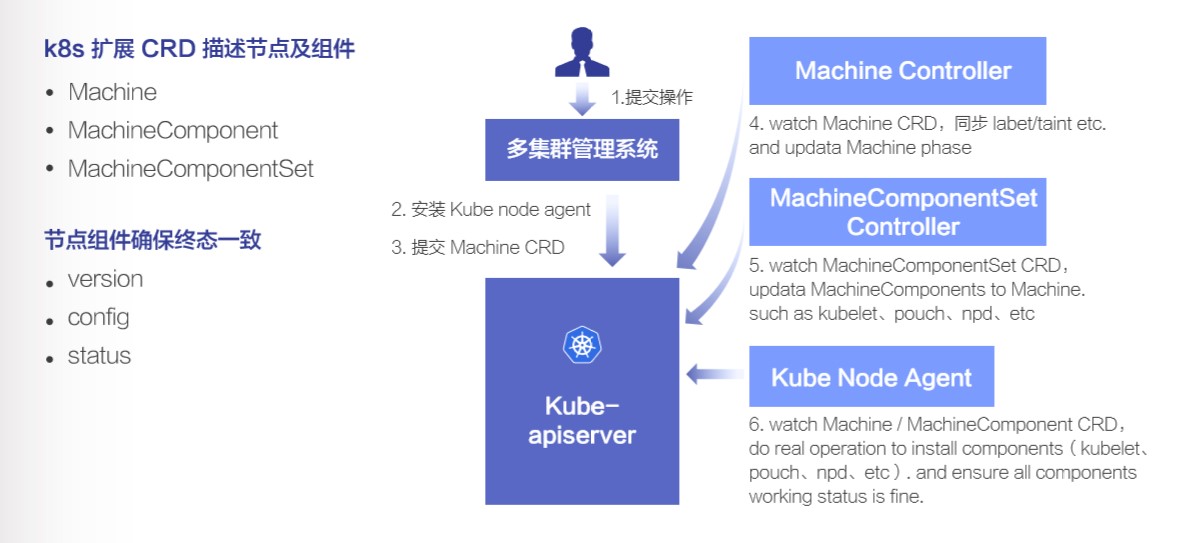
下面分享基于 KubeNode 对已有节点的导入过程。
首先用户会在我们的多集群管理系统中提交一个已有节点的导入操作,接下来系统先下发证书,并安装 KubeNode Agent,等 agent 正常运行并启动之后,第3步会提交 Machine CRD,接下来 Machine Controller 会修改状态为导入 phase,并等 Node ready 之后从 Machine 上同步 label / taint 到 Node。第 5 步是 MachineComponentSet, 根据 Machine 的信息确定要安装的节点组件,并同步到 Machine 上。最后 Kube Node Agent 会 watch 到 Machine、MachineComponent 的信息,完成节点组件的安装,并等所有组件运行正常后,节点导入操作完成。整个过程跟用户提交一个 Deployment 并最终启动一个业务 Pod 是类似的。
节点组件的终态一致主要包含了软件版本、软件配置和运行状态的正确、一致。
2)Use Case:组件升级
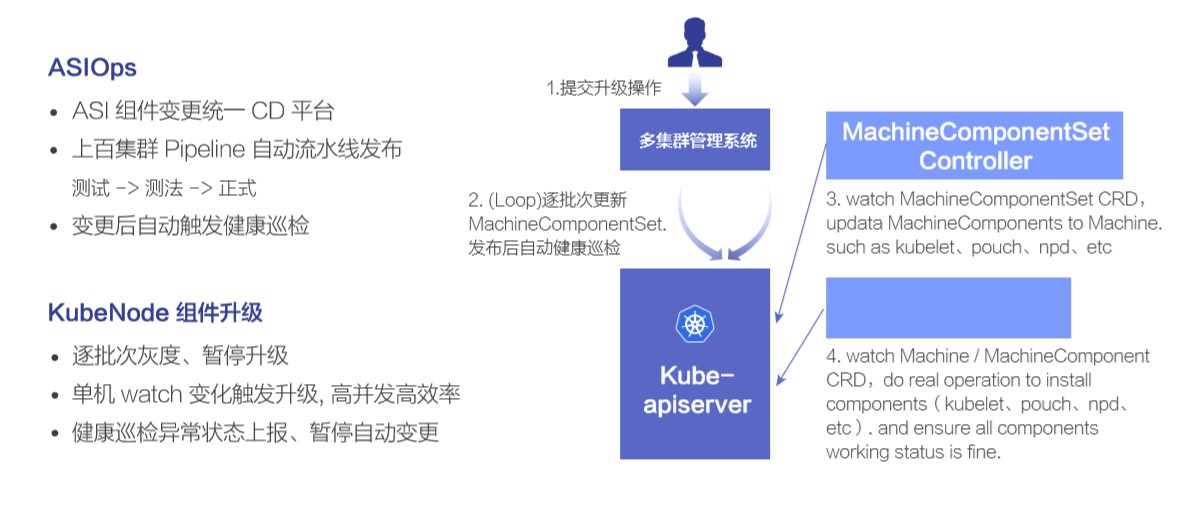
这里介绍下组件的升级过程,主要依赖的是 MachineComponentSet Controller 提供的分批次升级的能力。
首先用户在多集群管理系统上面提交一个组件升级操作,然后就进入一个逐批次循环升级的过程:先更新 MachineComponentSet 一个批次升级的机器数量是多少,之后 MachineComponentSet Controller 会计算并更新相应数量的节点上组件的版本信息。接下来 Kube Node Agent watch 到组件的变化,执行新版本的安装,并检查状态正常后上报组件状态正常。当这个批次所有的组件都升级成功后,再开始下一个批次的升级操作。
上面描述的单集群单个组件的升级流程是比较简单的,但对于线上十多个组件、上百个集群,要在所有的集群都完成版本推平工作就不那么简单了,我们通过 ASIOps 集群统一运维平台进行操作。在 ASIOps 系统中,将上百个集群配置到了有限的几个发布流水线,每条发布流水线都按照:测试 -> 预发 -> 正式 的顺序编排。一次正常的发布流程,就是选定一条发布流水线,按其预先设定好的集群顺序进行发布,在每个集群内部,又按照 1/5/10/50/100/… 的顺序进行自动发布,每一个批次发布完成,会触发健康巡检,如果有问题则暂停自动发布,没问题的话等观察期结束,则自动开始下一个批次的发布。通过这样的方式,做到了既安全又高效的完成一个组件新版本发布上线的过程。


接下来分享 KubeNode 里面的 Remedy Operator,也是一个标准的 Operator,用来做故障自愈修复。
Remedy Operator 也是由一组 CRD 以及对应的控制器组成。CRD 定义包括:NodeRemedier 和 RemedyOperationJob,控制器包括:Remedy Controller、RemedyJob Controller,同时也有故障自愈规则的注册中心,在单机侧有 NPD 和 Kube Node Agent。
Host Doctor 是在中心侧的一个独立的故障诊断系统,对接云厂商获取主动运维事件并转换为节点上的故障 Condition。在阿里云公有云上,ECS 所在的物理机发生的硬件类的故障或是计划中的运维操作,都会通过标准 OpenAPI 的形式获取,对接后就可以提前感知节点的问题,并提前自动迁移节点上的业务来避免故障。
Use Case:夯机自愈
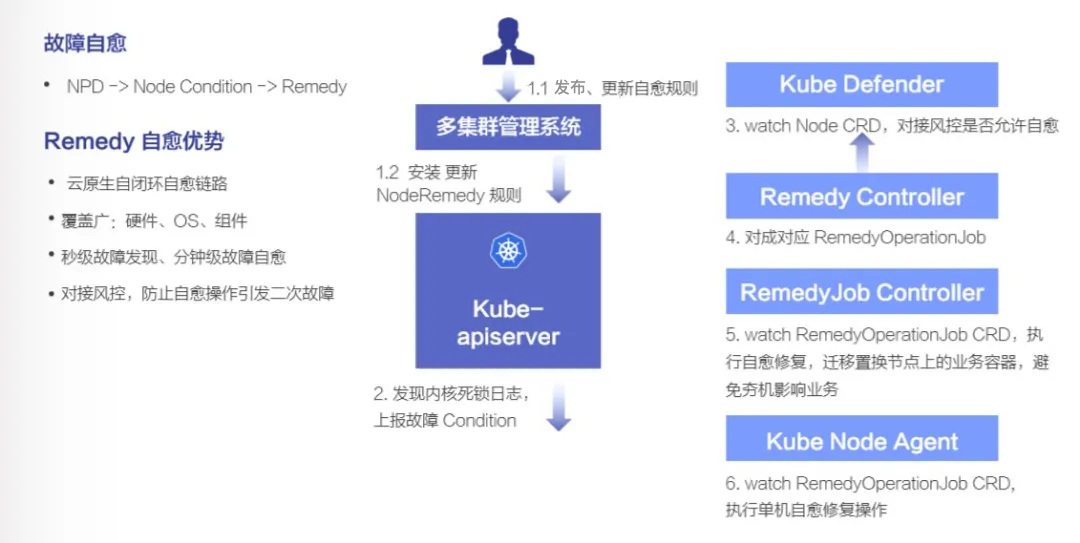
这里以夯机自愈的案例来介绍一个典型的自愈流程。
首先我们会在多集群管理系统 ASI Captain 上配置下发 CRD 描述的自愈规则,并且这些规则是可以灵活动态增加的,针对每一种 Node Condition 都可以配置一条对应的修复操作。
接下来节点上的 NPD 会周期性的检查是否有发生各种类型的故障,当发现内核日志中有出现 “task xxx blocked for more than 120 seconds” 的异常日志之后,判定节点夯机,并给 Node 上报故障 Condition,Remedy Controller watch 到变化后,就触发自愈修复流程:首先会调用 Kube Defender 风控中心接口判断当前自愈操作是否允许执行,通过后就生成 RemedyOperationJob 自愈任务,Kube Node Agent watch 到 job 后执行自愈操作。
可以看到整个自愈流程不依赖于外部第三方系统,通过 NPD 做故障检测,Remedy Operator 执行自愈修复,以云原生的方式完成了整个的自愈修复流程,最快可以做到分钟级的故障发现并修复。同时,通过对 NPD 检测规则的增强,处理的故障范围覆盖了从硬件故障、OS 内核故障、到组件故障的全链路修复。值得强调的是,所有的自愈操作都会对接 Kube Defender 统一风控中心,进行分钟级、小时级、天级别的自愈修复流控,防止当出现 Region / Zone 级别断网、大规模 io hang、或是其他大面积软件 bug 的情况下,触发对整个 Region 所有节点的故障自愈,引发更严重的二次故障。
==================================================================================
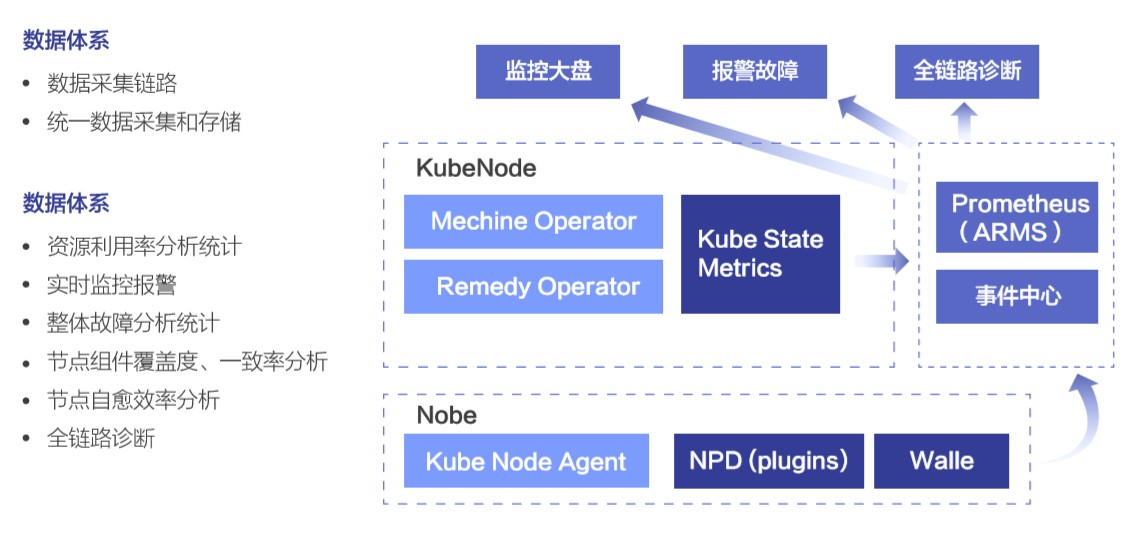
KubeNode 数据体系建设的好坏对整体度量并提升 SLO 起着非常重要的作用。
在节点侧,NPD 会检测故障并上报事件中心,同时 walle 是单机侧的指标采集组件,会采集节点以及容器的各种指标项信息,包括像 CPU / Memory / IO / Network 等常见的指标,以及很多其他的像内核、安全容器等的指标项。中心侧 Promethes (阿里云公有云上的 ARMS 产品) 会采集所有节点的指标并进行存储,同时也采集扩展过的 Kube State Metrics 的数据,获取 Machine Operator 和 Remedy Operator 的关键指标信息。在获取到这些数据的基础之上,再在上层面向用户,配置监控大盘、故障报警、以及全链路诊断的能力。
通过数据体系的建设,我们就可以用来做资源利用率的分析统计,可以提供实时的监控报警,进行故障分析统计,也可以分析整体 KubeNode 中的节点以及节点组件的覆盖率、一致率、节点自愈的效率,并提供针对节点的全链路诊断功能,当排查节点问题时,可以查看该节点上历史发生过的所有的事件,从而帮助用户快速定位原因。

最全的Linux教程,Linux从入门到精通
======================
-
linux从入门到精通(第2版)
-
Linux系统移植
-
Linux驱动开发入门与实战
-
LINUX 系统移植 第2版
-
Linux开源网络全栈详解 从DPDK到OpenFlow

第一份《Linux从入门到精通》466页
====================
内容简介
====
本书是获得了很多读者好评的Linux经典畅销书**《Linux从入门到精通》的第2版**。本书第1版出版后曾经多次印刷,并被51CTO读书频道评为“最受读者喜爱的原创IT技术图书奖”。本书第﹖版以最新的Ubuntu 12.04为版本,循序渐进地向读者介绍了Linux 的基础应用、系统管理、网络应用、娱乐和办公、程序开发、服务器配置、系统安全等。本书附带1张光盘,内容为本书配套多媒体教学视频。另外,本书还为读者提供了大量的Linux学习资料和Ubuntu安装镜像文件,供读者免费下载。

本书适合广大Linux初中级用户、开源软件爱好者和大专院校的学生阅读,同时也非常适合准备从事Linux平台开发的各类人员。
需要《Linux入门到精通》、《linux系统移植》、《Linux驱动开发入门实战》、《Linux开源网络全栈》电子书籍及教程的工程师朋友们劳烦您转发+评论
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 188
188

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









