







仅作记录学习使用,侵删
摘要
设计出来的加速器的缺陷
为一组共享相似的计算模式的神经网络技术设计,采用复杂的、信息丰富的指令。
指令集缺乏灵活性,使得这种加速器无法以足够的灵活性和效率支持各种不同的神经网络技术。
论文所提出的新指令集相较于之前的优势
强描述能力
提供更高的代码密度
产生的延迟/功耗/面积开销可以忽略不计
覆盖了10个不同的神经网络基准
使用到的技术
TSMC 65nm技术
官网:https://www.tsmc.com/schinese/dedicatedFoundry/technology/logic/l_65nm
引言
Cambricon的设计(概述)
Cambricon是一个负载存储体系结构,其指令都是64位的,包含64个32位用于标量的通用寄存器(GPRs),主要用于控制和寻址。
Cambricon不使用任何向量寄存器文件,将向量/矩阵数据保存在芯片上的便签存储器中,这对程序员/编译器都是可见的。
与SIMD的性能受到寄存器文件有限宽度的限制不同,Cambricon有效地支持更大的、可变的数据宽度,因为片上的便签内存库可以很容易地比寄存器文件更宽。
scratchpad memory(抓取板存储器)
可以点击这里了解更多内容
工作的主要内容
1)提出了一种新颖的轻量级的ISA,具有强大的描述能力;
2)对现有神经网络技术的计算模式进行了全面的研究;
3)使用TSMC 65nm技术实现第一个基于Cambricon的加速器来评估Cambricon的有效性。
拟议的ISA概述
设计指南
数据级并行性
在大多数神经网络技术中,神经元和突触数据被组织成层,然后以均匀/对称的方式进行操作(这两篇文章可以帮助了解更多神经网络的处理流程和神经网络的基本原理)。
当适应这些操作时,由向量/矩阵指令启用的数据级并行可以比传统标量指令的指令级并行更有效,并且对应于更高的代码密度(点击这里了解更多数据集并行的内容)。
Cambricon设计的重点就是数据级的并行性。
定制的向量/矩阵指令
全面定制一组小而又具有代表性的向量/矩阵指令,而不是简单地从现有的线性代数库中重新实现向量/矩阵操作,解决传统的线性代数库指令冗余问题和不涵盖许多神经网络技术常见操作的问题。
使用芯片上的抓取板存储器
用芯片上的抓取板存储器代替矢量寄存器文件,为每个数据访问提供灵活的宽度。这通常是对神经网络中的数据级并行性的一种高效选择,因为神经网络中的突触数据通常很大,很少被重用,从而减少了向量寄存器文件带来的性能增益。
Cambricon的概述
Cambricon是一种负载存储架构,只允许通过load/store指令访问主存。
Cambricon包含64个32位通用寄存器(GPRs),可用于芯片上刮刮板内存的寄存器间接寻址,以及临时保持标量数据。
指令类型
包含四种类型的指令:计算、逻辑、控制和数据传输指令。
指令长度被固定为64位,但是其有效位的数量可能不同。
这一节只介绍控制和数据传输指令,它们类似于相应的MIPS指令。
计算指令和逻辑指令的细节在下一节提供。
下图是论文中对Cambricon指令的概述。
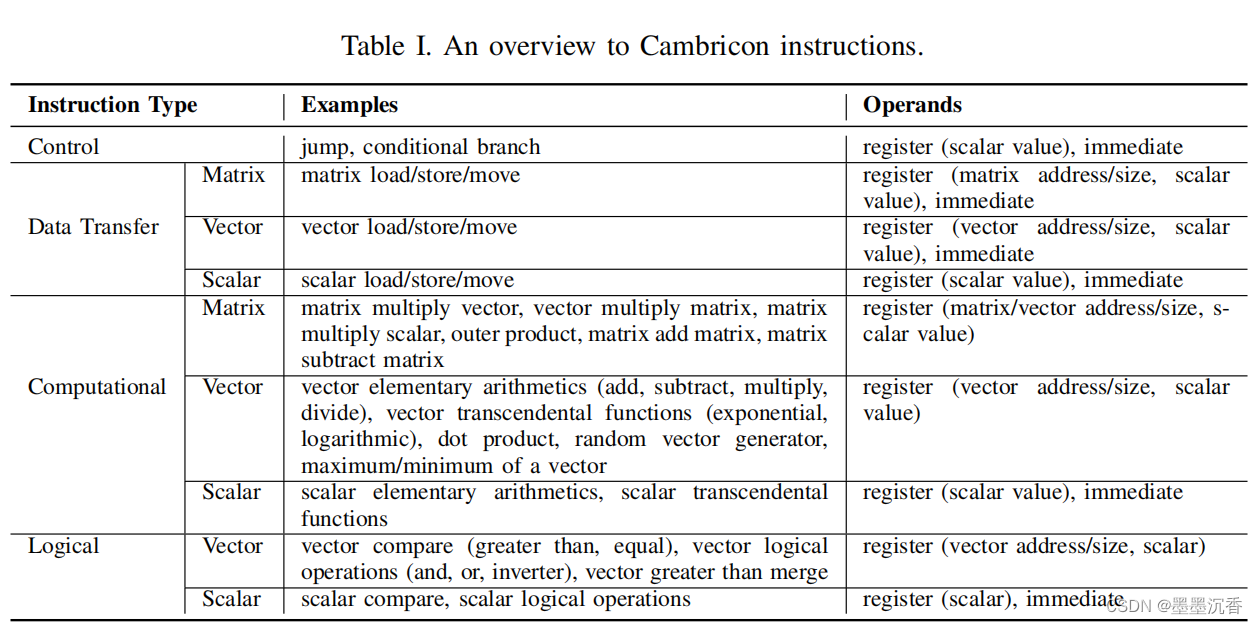
控制指令
包含两个控制指令:跳转和条件分支指令。
数据传输指令
这些指令可以从芯片上加载/存储可变大小的数据块(由数据传输指令中的数据宽度操作数指定)到主存储器,或者在芯片上刮刮板存储器和标量GPRs之间移动数据。
芯片上的抓取板内存
Cambricon不直接将数据保存在芯片上的抓取板内存中,使矢量操作数的大小不再受固定宽度的矢量寄存器文件的限制。
在Cambricon指令中,向量/矩阵的大小是可变的,唯一显著的限制是同一指令中的向量/矩阵操作数不能超过抓取板内存的容量。
Cambricon将向量指令的内存容量固定为64KB,将矩阵指令的内存容量固定为768KB。
Cambricon并没有对抓取板内存的bank数量施加特定的限制,这给微架构级的实现留下了巨大的自由。
计算/逻辑指令
参考翻译
文章中最重要的部分,仔细阅读原文结合翻译理解。
一个原型加速器
原型加速器的设计包含了七个主要的指令管道阶段:获取、解码、发出、寄存器读取、执行、回写和提交。
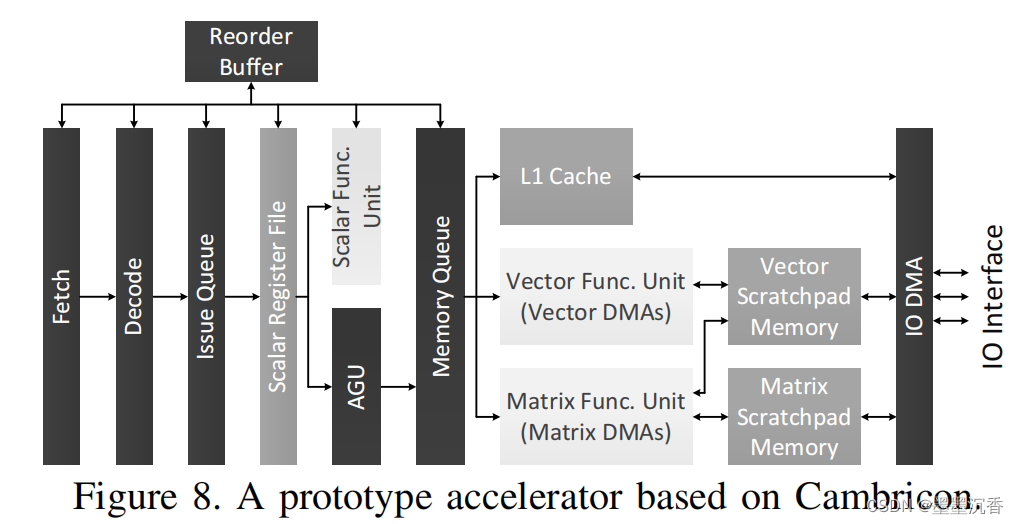
这个设计没有寻求探索新兴技术(如3d叠加和非易失性内存)。
在获取和解码阶段之后,一条指令被注入到一个按顺序排列的问题队列中。
在成功地从标量寄存器文件中获取操作数(标量数据,或向量/矩阵数据的地址/大小)后,将根据指令类型将指令被发送到不同的单位。
控制指令和标量计算/逻辑指令将被发送到标量功能单元进行直接执行。
在写回标量寄存器文件之后,这样的指令可以从重排序缓冲器中提交,只要它已经成为尚未执行的最古老的未提交指令。
数据传输指令、矢量/矩阵计算指令和矢量逻辑指令,可以访问L1高速缓存或抓取板存储器,将被发送到地址生成单元(AGU)。
这样的指令需要在顺序内存队列中等待,以使用内存队列中的早期指令解析潜在的内存依赖项。之后,标量数据传输指令的加载/存储请求将被发送到L1缓存,向量的数据传输/计算/逻辑指令将被发送到向量功能单元,矩阵的数据传输/计算指令将被发送到矩阵功能单元。
在执行后,这样的指令可以从重排序缓冲器中提交,只要它已经成为尚未执行的最古老的未提交指令。
该加速器同时实现了向量和矩阵的功能单元。该矢量单元包含32个16位加法器,32个16位乘法器,并配备了一个64KB的抓取板内存。矩阵单元包含1024个乘法器和1024个加法器,它们被分为32个独立的计算块,以避免长距离数据移动时的过度拥塞和功耗。每个计算块都配备了一个单独的24KB的抓取板。32个计算块通过h树总线连接,该总线用于向每个块广播输入值,并从每个块收集输出值。
为了有效地访问抓取板存储器,原型加速器的矢量/矩阵功能单元集成了三个DMA,每个DMA对应一个指令的矢量/矩阵输入/输出。此外,抓取板内存配备了一个IO DMA。但是,每个抓取板内存本身只为每个bank提供一个端口,但可能需要处理最多4个并发读/写请求。我们为抓取板内存设计了一个特定的结构来解决这个问题。
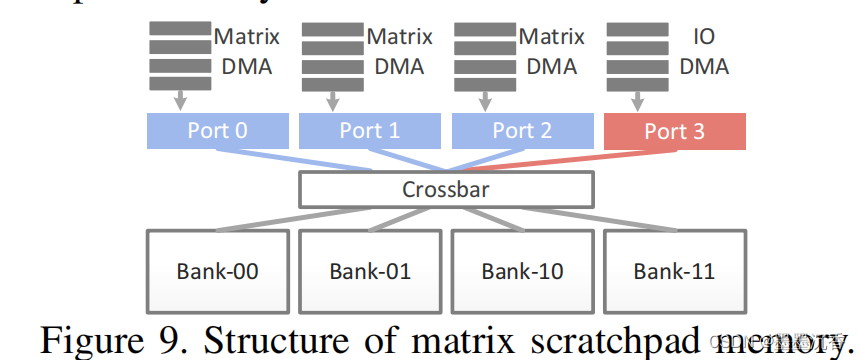
具体地说,我们根据地址的低阶两位将内存分解为四个bank,通过crossbar将它们与四个读写端口连接,保证bank不会被同时访问。由于专用的硬件支持,Cambricon不需要昂贵的多端口向量寄存器文件,并可以灵活和有效地支持不同的数据宽度使用片上抓取板内存。















 601
601











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









