







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Web前端全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上前端开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024c (备注前端)

正文
-
首先,你需要下载 nodejs,这个应该没啥问题吧
-
原文要求下载 webstrom,我电脑上本来就有,但其实不用下载,完全在命令行里面操作就行
准备工作做完了,下面就开始创建工程了
-
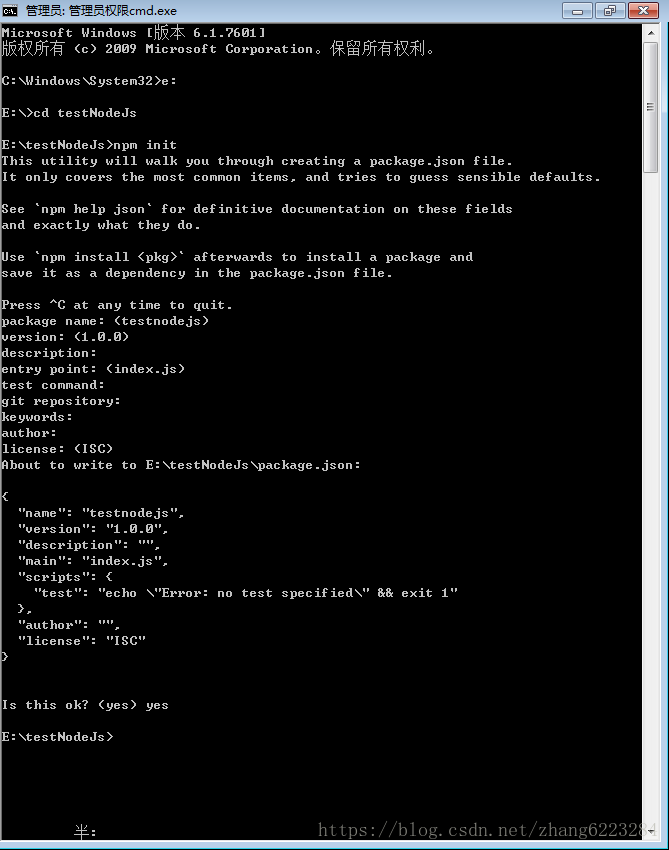
首先,在你想要放资源的地方创建文件夹,比如我在 E 盘里面创建了一个 myStudyNodejs 的文件夹
-
在命令行里面进入你创建的文件夹 如图
进入 e 盘:E:
进入文件夹:cd myStudyNodejs(你创建的文件夹的名字)
注意全是英文符号
- 初始化项目,在你创建的文件夹下面运行 npm init 初始化项目
一路回车,最后输个 yes 就行
-
运行完以后,会在文件夹里面生成一个 package.json 的文件,里面包含了项目的一些基本信息。
-
安装所需要的包
在所创建的文件夹的目录下运行
npm install cheerio –save
npm install request -save
爬武大的话,这两个包就够了,如果想爬草榴需要额外的转换编码的包,windows 上面是
npm install iconv-lite -save
Mac 上面是 npm install iconv -save
运行结果应该第二幅图这样,中间手滑少写了个字母
- 创建文件
在你所创建的文件夹下面创建一个 data 文件夹用于保存爬到的文本数据。
创建一个 image 文件夹用于保存图片数据。
创建一个 js 文件用来写程序。比如 study.js。(创建一个记事本文件将 .txt 改为 .js)
说明 –save 的目的是将项目对该包的依赖写入到 package.json 文件中。

武大计算机学院新闻爬虫代码
下面就是武大计算机学院新闻的爬虫代码了,复制到创建的 .js 文件中,保存。
var http = require(‘http’);
var fs = require(‘fs’);
var cheerio = require(‘cheerio’);
var request = require(‘request’);
var i = 0;
//初始url
var url = “http://cs.whu.edu.cn/a/xinwendongtaifabu/2018/0428/7053.html”;
function fetchPage(x) { //封装了一层函数
startRequest(x);
}
function startRequest(x) {
//采用http模块向服务器发起一次get请求
http.get(x, function (res) {
var html = ‘’; //用来存储请求网页的整个html内容
var titles = [];
res.setEncoding(‘utf-8’); //防止中文乱码
//监听data事件,每次取一块数据
res.on(‘data’, function (chunk) {
html += chunk;
});
//监听end事件,如果整个网页内容的html都获取完毕,就执行回调函数
res.on(‘end’, function () {
var $ = cheerio.load(html); //采用cheerio模块解析html
var news_item = {
//获取文章的标题
title: $(‘div#container dt’).text().trim(),
i: i = i + 1,
};
console.log(news_item); //打印新闻信息
var news_title = $(‘div#container dt’).text().trim();
savedContent($,news_title); //存储每篇文章的内容及文章标题
savedImg($,news_title); //存储每篇文章的图片及图片标题
//下一篇文章的url
var nextLink=“http://cs.whu.edu.cn” + $(“dd.Paging a”).attr(‘href’);
str1 = nextLink.split(‘-’); //去除掉url后面的中文
str = encodeURI(str1[0]);
//这是亮点之一,通过控制I,可以控制爬取多少篇文章.武大只有8篇,所以设置为8
if (i <= 8) {
fetchPage(str);
}
});
}).on(‘error’, function (err) {
console.log(err);
});
}
//该函数的作用:在本地存储所爬取的新闻内容资源
function savedContent($, news_title) {
$(‘dd.info’).each(function (index, item) {
var x = $(this).text();
var y = x.substring(0, 2).trim();
if (y == ‘’) {
x = x + ‘\n’;
//将新闻文本内容一段一段添加到/data文件夹下,并用新闻的标题来命名文件
fs.appendFile(‘./data/’ + news_title + ‘.txt’, x, ‘utf-8’, function (err) {
if (err) {
console.log(err);
}
});
}
})
}
//该函数的作用:在本地存储所爬取到的图片资源
function savedImg($,news_title) {
$(‘dd.info img’).each(function (index, item) {
var img_title = $(this).parent().next().text().trim(); //获取图片的标题
if(img_title.length>35||img_title==“”){
img_title=“Null”;
}
var img_filename = img_title + ‘.jpg’;
var img_src = ‘http://cs.whu.edu.cn’ + $(this).attr(‘src’); //获取图片的url
//采用request模块,向服务器发起一次请求,获取图片资源
request.head(img_src,function(err,res,body){
if(err){
console.log(err);
}
});
request(img_src).pipe(fs.createWriteStream(‘./image/’+news_title + ‘—’ + img_filename)); //通过流的方式,把图片写到本地/image目录下,并用新闻的标题和图片的标题作为图片的名称。
})
}
fetchPage(url); //主程序开始运行
下面就是激动人心的时刻了,在当前文件夹下面,运行创建的 js 文件,比如我的是 news.js。
npm news.js

文本资源:

图片资源:

草榴技术讨论区爬虫
爬完武大的新闻并不过瘾,于是尝试了一波爬草榴的技术讨论区(当然也能爬一些你懂的)。其中遇到了一些问题。
爬草榴的时候,发送 http 请求报文头里面需要包含 User-Agent 字段,于是需要把 初始url 做如下改变
var url = {
hostname: ‘cl.5fy.xyz’,
path: ‘/thread0806.php?fid=7’,
headers: {
‘Content-Type’: ‘text/html’,
//没有这个字段的话访问不了
‘User-Agent’: ‘Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.86 Safari/537.36’,
}};
其次,nodejs 只支持 抓取 utf-8 字符编码的网站,所以需要安装额外的包来转换编码,所以修改代码如下
/*
-
@Author: user
-
@Date: 2018-04-28 19:34:50
-
@Last Modified by: user
-
@Last Modified time: 2018-04-30 21:35:26
*/
var http = require(‘http’);
var fs = require(‘fs’);
var cheerio = require(‘cheerio’);
var request = require(‘request’);
var iconv=require(‘iconv-lite’);
var i = 0;
//用来判断存储还是访问
var temp=0;
let startPage=3;//从哪一页开始爬
let page=startPage;
let endPage=5;//爬到哪一页
let searchText=‘’;//爬取的关键字,默认全部爬取,根据自己需要
//初始url
var url = {
hostname: ‘1024liuyouba.tk’,
path: ‘/thread0806.php?fid=16’+‘&search=&page=’+startPage,
headers: {
‘Content-Type’: ‘text/html’,
//没有这个字段的话访问不了
‘User-Agent’: ‘Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.86 Safari/537.36’,
}};
//存储首页url
urlList=[];
//封装了一层函数
function fetchPage(x) {
setTimeout(function(){
startRequest(x); },5000)
}
//首先存储要访问界面的url
function getUrl(x){
temp++;
http.get(x,function(res){
var html = ‘’;
res.setEncoding(‘binary’);
res.on(‘data’, function (chunk) {
html += chunk;
});
res.on(‘end’, function () {
var buf=new Buffer(html,‘binary’);
var str=iconv.decode(buf,‘GBK’);
var $ = cheerio.load(str); //采用cheerio模块解析html
$(‘tr.tr3 td.tal h3 a’).each(function(){
var search=$(this).text();
if(search.indexOf(searchText)>=0){
var nextLink=“http://cl.5fy.xyz/” + $(this).attr(‘href’);
str1 = nextLink.split(‘-’); //去除掉url后面的中文
str = encodeURI(str1[0]);
urlList.push(str); }
})
JavaScript
-
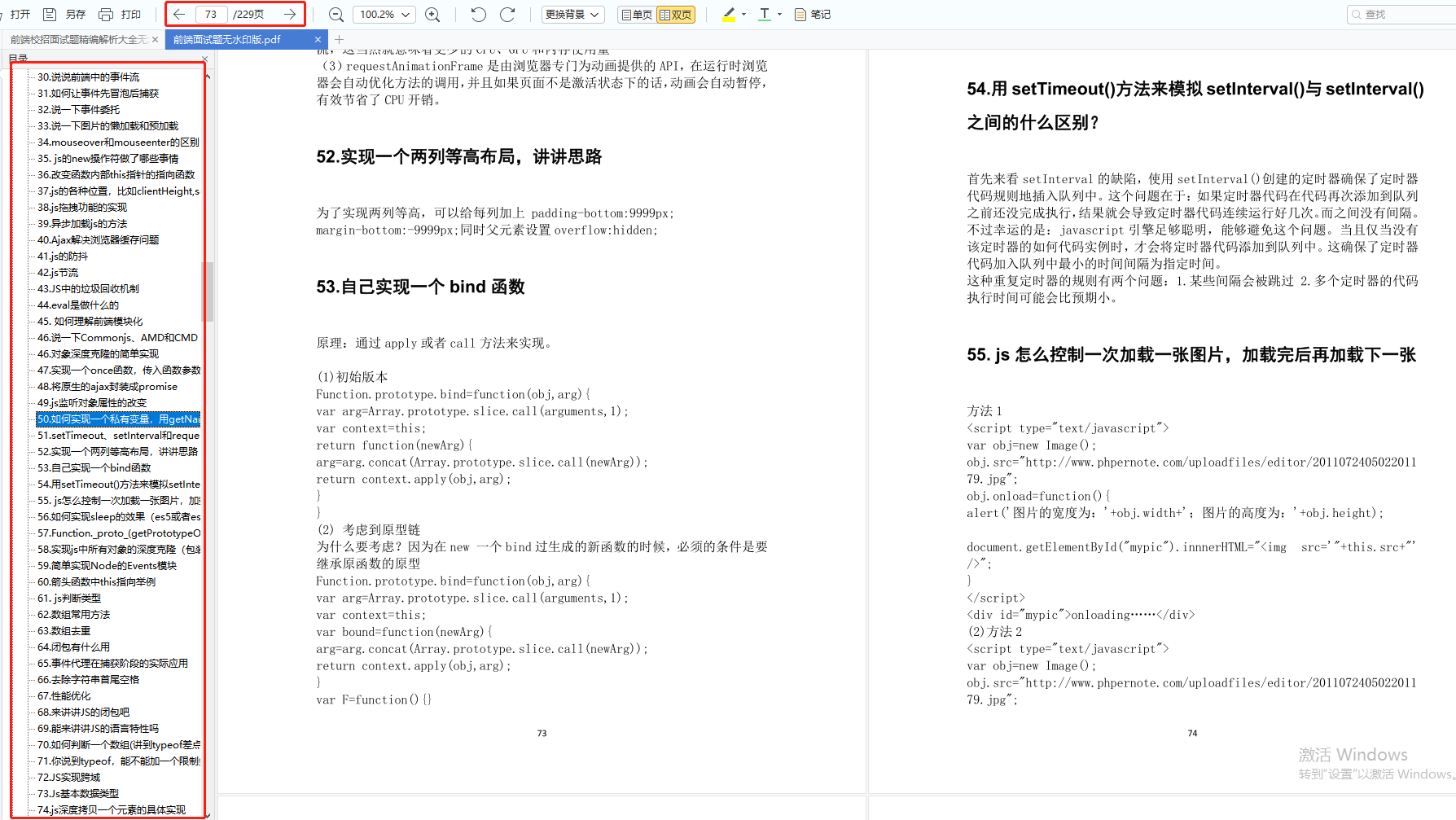
js的基本类型有哪些?引用类型有哪些?null和undefined的区别。
-
如何判断一个变量是Array类型?如何判断一个变量是Number类型?(都不止一种)
-
Object是引用类型嘛?引用类型和基本类型有什么区别?哪个是存在堆哪一个是存在栈上面的?
-
JS常见的dom操作api
-
解释一下事件冒泡和事件捕获
-
事件委托(手写例子),事件冒泡和捕获,如何阻止冒泡?如何组织默认事件?
-
对闭包的理解?什么时候构成闭包?闭包的实现方法?闭包的优缺点?
-
this有哪些使用场景?跟C,Java中的this有什么区别?如何改变this的值?
-
call,apply,bind
-
显示原型和隐式原型,手绘原型链,原型链是什么?为什么要有原型链
-
创建对象的多种方式
-
实现继承的多种方式和优缺点
-
new 一个对象具体做了什么
-
手写Ajax,XMLHttpRequest
-
变量提升
-
举例说明一个匿名函数的典型用例
-
指出JS的宿主对象和原生对象的区别,为什么扩展JS内置对象不是好的做法?有哪些内置对象和内置函数?
-
attribute和property的区别
-
document load和document DOMContentLoaded两个事件的区别
-
JS代码调试
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024c (备注前端)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
变量提升
-
举例说明一个匿名函数的典型用例
-
指出JS的宿主对象和原生对象的区别,为什么扩展JS内置对象不是好的做法?有哪些内置对象和内置函数?
-
attribute和property的区别
-
document load和document DOMContentLoaded两个事件的区别
-
JS代码调试
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024c (备注前端)
[外链图片转存中…(img-IeW1bSLU-1713327933986)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









