






提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
一、用给定语料进行Bigram建模训练,并且计算给定句子的概率, 给定词组,返回最大概率组合的句子
二、用两个语料 做Bigram建模训练,并根据给定首字(词)进行文本生成,比较不同语料的训练结果差异。
提示:以下是本篇文章正文内容,下面案例可供参考
一、计算给定句子的概率, 给定词组,返回最大概率组合的句子
from collections import Counter
import numpy as np
corpus = '''她的菜很好 她的菜很香 她的他很好 他的菜很香 他的她很好
很香的菜 很好的她 很菜的他 她的好 菜的香 他的菜 她很好 他很菜 菜很好'''.split()
counter = Counter() # 词频统计
for sentence in corpus:
for word in sentence:
counter[word] += 1
counter = counter.most_common()
lec = len(counter)
word2id = {counter[i][0]: i for i in range(lec)}
id2word = {i: w for w, i in word2id.items()}
unigram = np.array([i[1] for i in counter]) / sum(i[1] for i in counter)
bigram = np.zeros((lec, lec)) + 1e-8
for sentence in corpus:
sentence = [word2id[w] for w in sentence]
for i in range(1, len(sentence)):
bigram[[sentence[i - 1]], [sentence[i]]] += 1
for i in range(lec):
bigram[i] /= bigram[i].sum()
def prob(sentence):
s = [word2id[w] for w in sentence]
les = len(s)
if les < 1:
return 0
p = unigram[s[0]]
if les < 2:
return p
for i in range(1, les):
p *= bigram[s[i - 1], s[i]]
return p
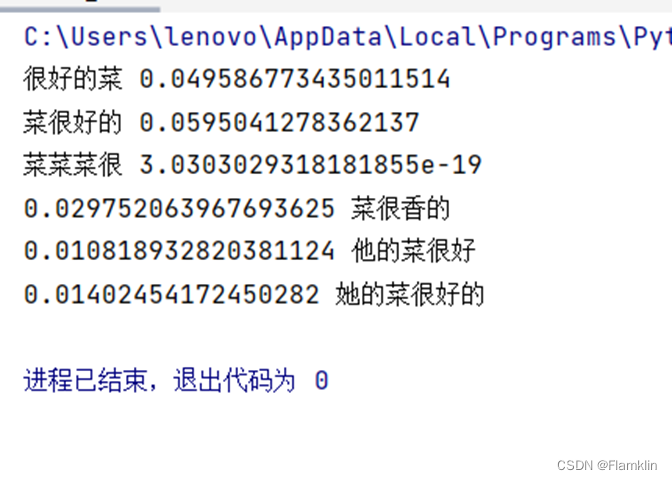
print('很好的菜', prob('很好的菜'))
print('菜很好的', prob('菜很好的'))
print('菜菜菜很', prob('菜菜菜很'))
def permutation_and_combination(ls_ori, ls_all=None):
ls_all = ls_all or [[]]
le = len(ls_ori)
if le == 1:
ls_all[-1].append(ls_ori[0])
ls_all.append(ls_all[-1][: -2])
return ls_all
for i in range(le):
ls, lsi = ls_ori[:i] + ls_ori[i + 1:], ls_ori[i]
ls_all[-1].append(lsi)
ls_all = permutation_and_combination(ls, ls_all)
if ls_all[-1]:
ls_all[-1].pop()
else:
ls_all.pop()
return ls_all
def max_prob(words):
pc = permutation_and_combination(words)
p, w = max((prob(s), s) for s in pc)
return p, ''.join(w)
print(*max_prob(list('香很的菜')))
print(*max_prob(list('好很的他菜')))
print(*max_prob(list('好很的的她菜')))
二、并根据给定首字(词)进行文本生成,比较不同语料的训练结果差异。
from collections import Counter
from random import choice
from jieba import lcut
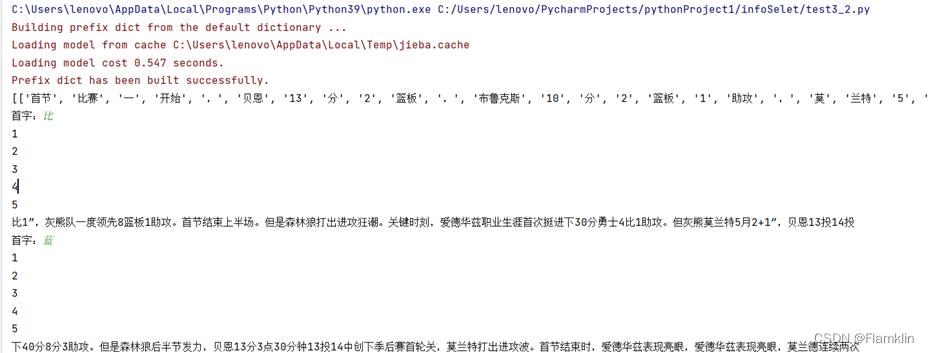
with open('nba解说.txt', encoding='gbk') as f:
corpus = [lcut(line) for line in f.read().strip().split()]
print(corpus)
counter = Counter(word for words in corpus for word in words)
bigram = {w: Counter() for w in counter.keys()}
for words in corpus:
for i in range(1, len(words)):
bigram[words[i - 1]][words[i]] += 1
for k, v in bigram.items():
total2 = sum(v.values())
v = {w: c / total2 for w, c in v.items()}
bigram[k] = v
n = 5
while True:
first = input('首字:').strip()
if first not in counter:
first = choice(list(counter))
print(1)
next_words = sorted(bigram[first], key=lambda w: bigram[first][w])[:n]
print(2)
next_word = choice(next_words) if next_words else ''
print(3)
sentence = first + next_word
print(4)
numx = 0
while bigram[next_word]:
next_word = choice(sorted(bigram[next_word], key=lambda w: bigram[next_word][w])[:n])
sentence += next_word
numx += 1
if (numx >= 50):
break
print(5)
print(sentence)
输出结果

















 5218
5218











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









