






提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
提示:这里可以添加本文要记录的大概内容:
例如:随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。
提示:以下是本篇文章正文内容,下面案例可供参考
一、目的
(1) 调用gensim实现BM25模型。
(2) 使用numpy,jieba实现BM25模型
(3) 使用jieba分词
二、gensim实现BM25模型
三、实验步骤及编码
1.
import jieba
from gensim.summarization import bm25
document_list = ["行政机关强行解除行政协议造成损失,如何索取赔偿?",
"借钱给朋友到期不还得什么时候可以起诉?怎么起诉?",
"我在微信上被骗了,请问被骗多少钱才可以立案?",
"公民对于选举委员会对选民的资格申诉的处理决定不服,能不能去法院起诉吗?",
"有人走私两万元,怎么处置他?",
"法律上餐具、饮具集中消毒服务单位的责任是不是对消毒餐具、饮具进行检验?"]
document_list = [list(jieba.cut(doc)) for doc in document_list]
bm25Model = bm25.BM25(document_list)
query = "走私了两万元,在法律上应该怎么量刑?"
query = list(jieba.cut(query))
scores = bm25Model.get_scores(query)
print(scores)
2.使用numpy,jieba实现BM25模型
代码如下(示例):
2.
import numpy as np
from collections import Counter
import jieba
class BM25_Model(object):
def __init__(self, documents_list, k1=2, k2=1, b=0.5):
self.documents_list = documents_list
self.documents_number = len(documents_list)
self.avg_documents_len = sum([len(document) for document in documents_list]) / self.documents_number
self.f = []
self.idf = {}
self.k1 = k1
self.k2 = k2
self.b = b
self.init()
def init(self):
df = {}
for document in self.documents_list:
temp = {}
for word in document:
temp[word] = temp.get(word, 0) + 1
self.f.append(temp)
for key in temp.keys():
df[key] = df.get(key, 0) + 1
for key, value in df.items():
self.idf[key] = np.log((self.documents_number - value + 0.5) / (value + 0.5))
def get_score(self, index, query):
score = 0.0
document_len = len(self.f[index])
qf = Counter(query)
for q in query:
if q not in self.f[index]:
continue
score += self.idf[q] * (self.f[index][q] * (self.k1 + 1) / (
self.f[index][q] + self.k1 * (1 - self.b + self.b * document_len / self.avg_documents_len))) * (
qf[q] * (self.k2 + 1) / (qf[q] + self.k2))
return score
def get_documents_score(self, query):
score_list = []
for i in range(self.documents_number):
score_list.append(self.get_score(i, query))
return score_list
document_list = ["行政机关强行解除行政协议造成损失,如何索取赔偿?",
"借钱给朋友到期不还得什么时候可以起诉?怎么起诉?",
"我在微信上被骗了,请问被骗多少钱才可以立案?",
"公民对于选举委员会对选民的资格申诉的处理决定不服,能不能去法院起诉吗?",
"有人走私两万元,怎么处置他?",
"法律上餐具、饮具集中消毒服务单位的责任是不是对消毒餐具、饮具进行检验?"]
document_list = [list(jieba.cut(doc)) for doc in document_list]
bm25_model = BM25_Model(document_list)
query = "走私了两万元,在法律上应该怎么量刑?"
query = list(jieba.cut(query))
scores = bm25_model.get_documents_score(query)
print(scores)
输出结果
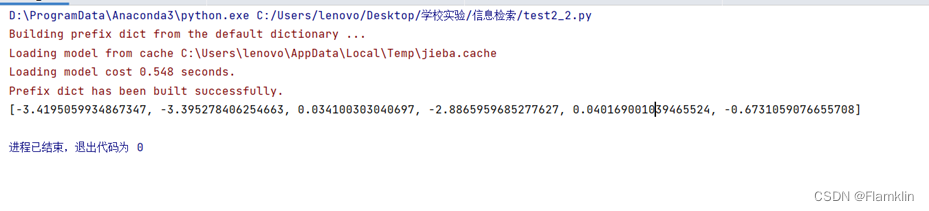















 4145
4145











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









