









【人工智能与深度学习】不确定性下的预测和政策学习(PPUU)
简介和问题设置
让我们去以一个完全没有强化学习的方式来学习。很多时候,我们训练模型,都是以一个不停犯错同时又由错误中学习的强化学习方式来学习。但这不是最好的方法,因为很容易偏离原先的轨道。
所以,让我们用一些更自认的方式来学习驾驶一辆车。以转弯来说说吧。比如有辆车时速100公里每小时,就是差不多一秒走30米吧,所以如果我们看30 米前方,就等于观察并预测未来1秒会发生的事。
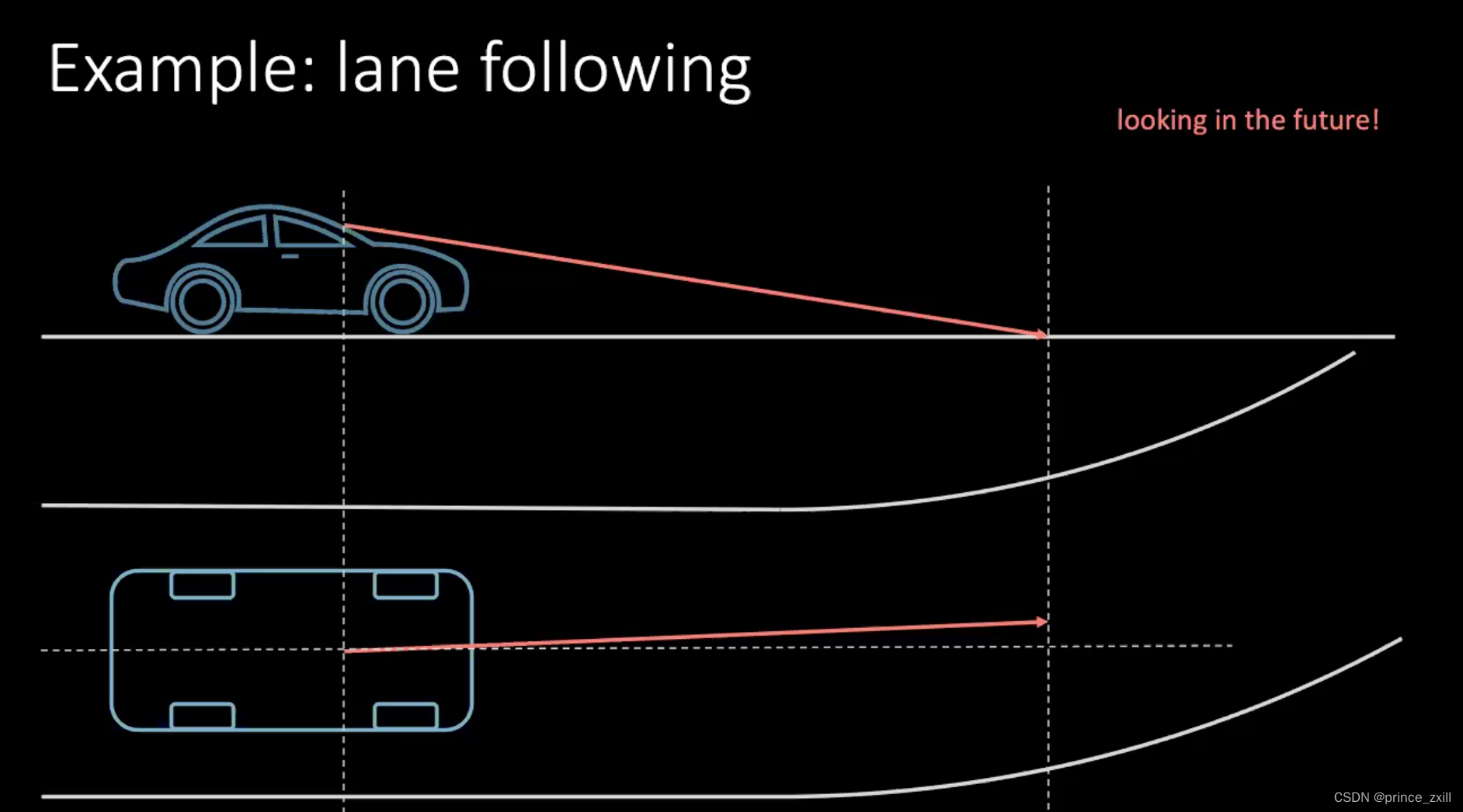
图 1: 驾驶的同时也观察未来
如果我们想要转弯,那我们就要以未来会发生什么来作出决定。为了在数秒后做一个转向,我们要现在就要去作出行动,也就是要现在去转动方向盘,现在我们就正在转方向盘了。驾驶时下决定,不单单是基于你如何驾驶,也要看交通中的周围的车辆。因为周围的每一个人都不是那么确定性的,所以是十分困难来去用所有车的可能性来考虑。
现在就让我们来一步一步来解说如何运作。我们有一个代理人(以一个大脑来代表),它以 s t

 订阅专栏 解锁全文
订阅专栏 解锁全文
















 2814
2814











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











