







大模型微调实战:一文带你从零开始微调大模型
引言
在人工智能技术飞速发展的今天,大模型已成为解决复杂任务的核心工具。然而,通用大模型往往难以直接满足垂直领域或特定场景的需求。微调技术正是打破这一瓶颈的关键——通过注入领域知识、优化输出逻辑,让模型真正“懂行业、会表达”。本文以“手把手”为核心理念,从理论基础到实战操作,系统讲解如何利用线上平台与LLaMA-Factory高效完成数据准备、模型训练与部署优化。无论你是零基础新手还是希望进阶的技术人员,都能通过案例驱动的学习,快速掌握微调精髓,打造出属于自己的专属AI助手。
数据集准备
常用数据集
预训练数据集- Wiki Demo (en)
- RefinedWeb (en)
- RedPajama V2 (en)
- Wikipedia (en)
- Wikipedia (zh)
- Pile (en)
- SkyPile (zh)
- FineWeb (en)
- FineWeb-Edu (en)
- The Stack (en)
- StarCoder (en)
- Identity (en&zh)
- Stanford Alpaca (en)
- Stanford Alpaca (zh)
- Alpaca GPT4 (en&zh)
- Glaive Function Calling V2 (en&zh)
- LIMA (en)
- Guanaco Dataset (multilingual)
- BELLE 2M (zh)
- BELLE 1M (zh)
- BELLE 0.5M (zh)
- BELLE Dialogue 0.4M (zh)
- BELLE School Math 0.25M (zh)
- BELLE Multiturn Chat 0.8M (zh)
- UltraChat (en)
- OpenPlatypus (en)
- CodeAlpaca 20k (en)
- Alpaca CoT (multilingual)
- OpenOrca (en)
- SlimOrca (en)
- MathInstruct (en)
- Firefly 1.1M (zh)
- Wiki QA (en)
- Web QA (zh)
- WebNovel (zh)
- Nectar (en)
- deepctrl (en&zh)
- Advertise Generating (zh)
- ShareGPT Hyperfiltered (en)
- ShareGPT4 (en&zh)
- UltraChat 200k (en)
- AgentInstruct (en)
- LMSYS Chat 1M (en)
- Evol Instruct V2 (en)
- Cosmopedia (en)
- STEM (zh)
- Ruozhiba (zh)
- Neo-sft (zh)
- Magpie-Pro-300K-Filtered (en)
- Magpie-ultra-v0.1 (en)
- WebInstructSub (en)
- OpenO1-SFT (en&zh)
- Open-Thoughts (en)
- Open-R1-Math (en)
- Chinese-DeepSeek-R1-Distill (zh)
- LLaVA mixed (en&zh)
- Pokemon-gpt4o-captions (en&zh)
- Open Assistant (de)
- Dolly 15k (de)
- Alpaca GPT4 (de)
- OpenSchnabeltier (de)
- Evol Instruct (de)
- Dolphin (de)
- Booksum (de)
- Airoboros (de)
- Ultrachat (de)
- DPO mixed (en&zh)
- UltraFeedback (en)
- COIG-P (en&zh)
- RLHF-V (en)
- VLFeedback (en)
- Orca DPO Pairs (en)
- HH-RLHF (en)
- Nectar (en)
- Orca DPO (de)
- KTO mixed (en)
自定义数据集
在大模型微调中,我们一般使用Alpaca 和 ShareGPT和两种格式的数据集。
Alpaca
Alpaca 是基于 Meta 开源的 LLaMA 模型构建的一种微调数据集格式,特别用于 instruction-tuning,即指令微调。其数据格式的特点是提供了一个明确的任务描述(instruction)、输入(input)和输出(output)三部分。
Alpaca 数据集格式要求:
[
{
"instruction": "人类指令(必填)",
"input": "人类输入(选填)",
"output": "模型回答(必填)",
"system": "系统提示词(选填)",
"history": [
["第一轮指令(选填)", "第一轮回答(选填)"],
["第二轮指令(选填)", "第二轮回答(选填)"]
]
}
]
Alpaca 数据集格式——单轮对话示例:
[
{
"instruction": "这是什么",
"input": "",
"output": "服务器繁忙,请稍后再试",
"system": "你是一个人工智能助手。",
"history": []
}
]
Alpaca 数据集格式——多轮对话示例:
[
{
"instruction": "这是什么",
"input": "",
"output": "服务器繁忙,请稍后再试",
"system": "你是一个人工智能助手。",
"history": [
["这是什么", "服务器繁忙,请稍后再试"]
]
},
{
"instruction": "那是什么",
"input": "",
"output": "我不知道",
"system": "你是一个人工智能助手。",
"history": [
["这是什么", "服务器繁忙,请稍后再试"]
["那是什么", "我不知道"]
]
}
]
说明:
- instruction: 任务的指令,告诉模型需要完成什么操作。
- input: 任务所需的输入。如果任务是开放式的或者不需要明确的输入,这一字段可以为空字符串。
- output: 任务的期望输出,也就是模型在给定指令和输入情况下需要生成的内容。
特点:
- 结构简单,易于理解。
- 明确分离任务指令和输入内容,适合各种自然语言处理任务,如文本生成、翻译、总结等。
ShareGPT
ShareGPT 格式来源于通过记录 ChatGPT 与用户对话的数据集,主要用于对话系统的训练。它更侧重于多轮对话数据的收集和组织,模拟用户与 AI 之间的交互。
ShareGPT 数据集格式:
{
"conversations": [
{
"role": "user",
"content": "What is the capital of France?"
},
{
"role": "assistant",
"content": "The capital of France is Paris."
},
{
"role": "user",
"content": "Can you tell me more about Paris?"
},
{
"role": "assistant",
"content": "Paris is the largest city and the capital of France. "
}
]
}
线上微调——硅基流动
进入硅基流动官网后,选择模型微调,进入如下页面。

目前有以下模型支持微调:
- Qwen/Qwen2.5-7B-Instruct
- Qwen/Qwen2.5-14B-Instruct
- Qwen/Qwen2.5-32B-Instruct
- Qwen/Qwen2.5-72B-Instruct
硅基流动的数据集有特殊要求:
仅支持 .jsonl 文件,且需符合以下要求:
- 每行是一个独立的 JSON 对象;
- 每个对象必须包含键名为
messages的数组,数组不能为空; messages中每个元素必须包含role和content两个字段;role只能是system、user或assistant;- 如果有
system角色消息,必须在数组首位; - 第一条非
system消息必须是user角色; user和assistant角色的消息应当交替、成对出现,不少于 1 对
以下为数据示例:
{"messages": [{"role": "system", "content": "你是客服助手"}, {"role": "user", "content": "如何修改收货地址?"}, {"role": "assistant", "content": "您可以按以下步骤修改:\n1. 进入订单详情\n2. 点击'修改地址'\n3. 输入新地址信息\n4. 保存修改"}]}
{"messages": [{"role": "system", "content": "你是客服助手"}, {"role": "user", "content": "如何指定收获时间"}, {"role": "assistant", "content": "您可以按以下步骤修改:\n1. 进入订单详情\n2. 点击'修改送货时间'\n3. 输入新收获时间\n4. 保存修改"}]}
新建并配置微调任务
选择对话模型微调:
- 填写任务名称,如“test”
- 选择基础模型,如“Qwen/Qwen2.5-32B-Instruct”
- 上传或选取已上传的训练数据
- 设置验证数据,支持训练集按比例切分(默认 10%),或单独选定验证集
- 配置训练参数,如果无特殊需求的话可以直接使用默认的参数
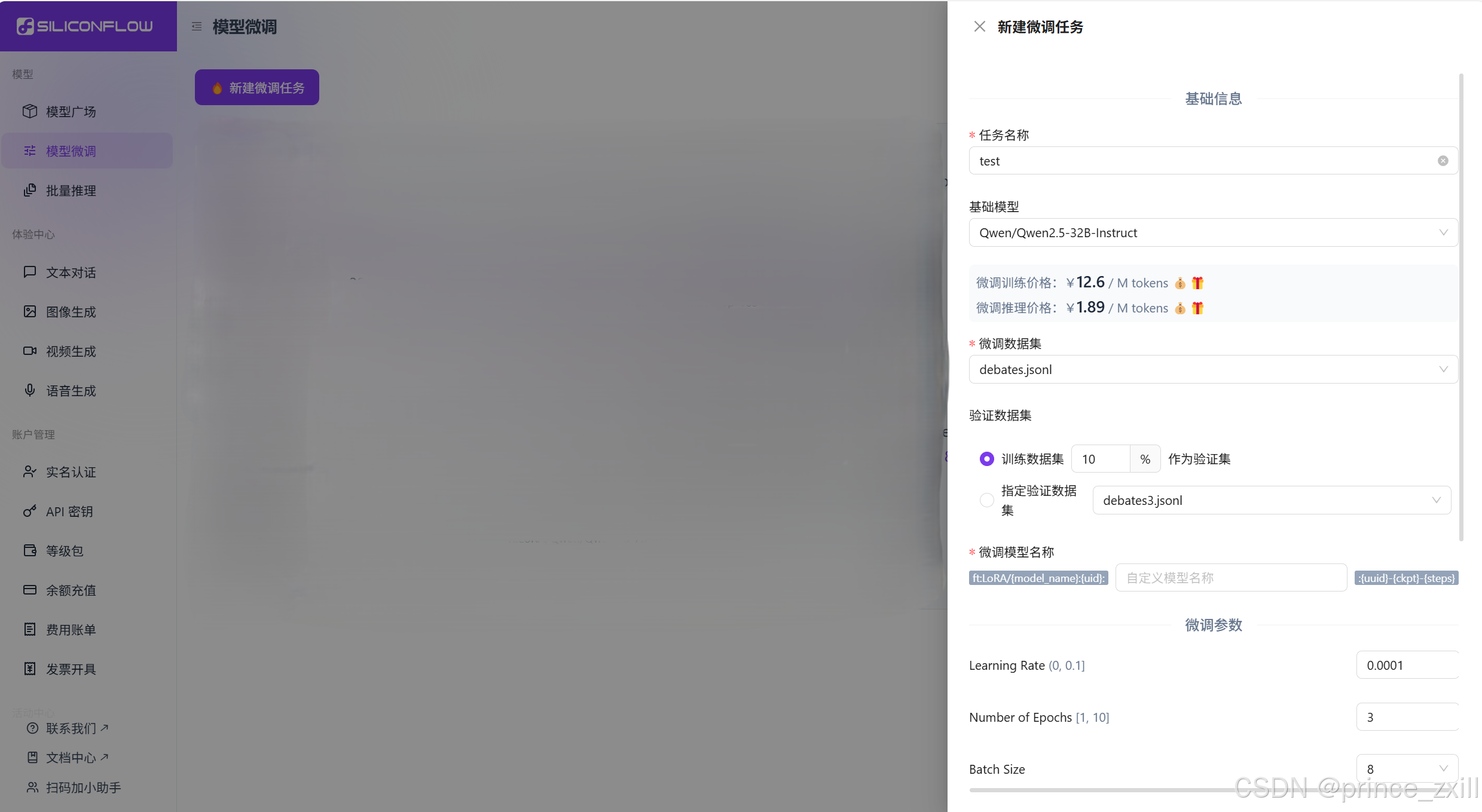
参数配置详解
基础训练参数
| 参数名 | 说明 | 取值范围 | 建议值 | 使用建议 |
|---|---|---|---|---|
| Learning Rate | 学习速率 | 0-0.1 | 0.0001 | |
| Number of Epochs | 训练轮数 | 0-0.11-10 | 3 | |
| Batch Size | 批次大小 | 1-32 | 8 | |
| Max Tokens | 最大标记数 | 0-4096 | 4096 | 根据实际对话长度需求设置 |
LoRA参数
| 参数名 | 说明 | 取值范围 | 建议值 |
|---|---|---|---|
| LoRA Rank | 矩阵秩 | 1-64 | 8 |
| LoRA Alpha | 缩放因子 | 1-128 | 32 |
| LoRA Dropout | 随机丢弃率 | 0-1.0 | 0.05 |
场景化配置方案
对话模型
| 场景 | Learning Rate Epochs | Batch Size | LoRA Rank | LoRA Alpha | Dropout |
|---|---|---|---|---|---|
| 标准方案 | 0.0001 | 3 | 8 | 8 | 32 |
| 效果优先 | 0.0001 | 5 | 16 | 16 | 64 |
| 轻量快速 | 0.0001 | 2 | 8 | 4 | 16 |
开始训练
- 点击”开始微调”
- 等待任务完成
- 获取模型标识符,也就是“微调模型”下方的三个可复制序列号,其中,从上往下数第一个为最终模型,后面的step_xxx模型为中间检查点模型。

调用模型
- 复制模型标识符
- 通过 /chat/completions API 即可直接调用微调后的模型
下面是基于 OpenAI的chat.completions 接口访问微调后模型的例子:
from openai import OpenAI
client = OpenAI(
api_key="您的 APIKEY", # 从https://cloud.siliconflow.cn/account/ak获取
base_url="https://api.siliconflow.cn/v1"
)
messages = [
{"role": "user", "content": "用当前语言解释微调模型流程"},
]
response = client.chat.completions.create(
model="您的微调模型名",
messages=messages,
stream=True,
max_tokens=4096
)
for chunk in response:
print(chunk.choices[0].delta.content, end='')
本地微调——LLaMA Factory
支持的模型
| 模型名 | 参数量 | Template |
|---|---|---|
| Baichuan 2 | 7B/13B | baichuan2 |
| BLOOM/BLOOMZ | 560M/1.1B/1.7B/3B/7.1B/176B | - |
| ChatGLM3 | 6B | chatglm3 |
| Command R | 35B/104B | cohere |
| DeepSeek (Code/MoE) | 7B/16B/67B/236B | deepseek |
| DeepSeek 2.5/3 | 236B/671B | deepseek3 |
| DeepSeek R1 (Distill) | 1.5B/7B/8B/14B/32B/70B/671B | deepseekr1 |
| Falcon | 7B/11B/40B/180B | falcon |
| Gemma/Gemma 2/CodeGemma | 2B/7B/9B/27B | gemma |
| Gemma 3 | 1B/4B/12B/27B | gemma3/gemma (1B) |
| GLM-4/GLM-4-0414/GLM-Z1 | 9B/32B | glm4/glmz1 |
| GPT-2 | 0.1B/0.4B/0.8B/1.5B | - |
| Granite 3.0-3.3 | 1B/2B/3B/8B | granite3 |
| Hunyuan | 7B | hunyuan |
| Index | 1.9B | index |
| InternLM 2-3 | 7B/8B/20B | intern2 |
| InternVL 2.5-3* | 1B/2B/8B/14B/38B/78B | intern_vl |
| Kimi-VL | 16B | kimi_vl |
| Llama | 7B/13B/33B/65B | - |
| Llama 2 | 7B/13B/70B | llama2 |
| Llama 3-3.3 | 1B/3B/8B/70B | llama3 |
| Llama 4 | 109B/402B | llama4 |
| Llama 3.2 Vision | 11B/90B | mllama |
| LLaVA-1.5 | 7B/13B | llava |
| LLaVA-NeXT | 7B/8B/13B/34B/72B/110B | llava_next |
| LLaVA-NeXT-Video | 7B/34B | llava_next_video |
| MiniCPM | 1B/2B/4B | cpm/cpm3 |
| MiniCPM-o-2.6/MiniCPM-V-2.6 | 8B | minicpm_o/minicpm_v |
| Ministral/Mistral-Nemo | 8B/12B | ministral |
| Mistral/Mixtral | 7B/8x7B/8x22B | mistral |
| Mistral Small | 24B | mistral_small |
| OLMo | 1B/7B | - |
| PaliGemma/PaliGemma2 | 3B/10B/28B | paligemma |
| Phi-1.5/Phi-2 | 1.3B/2.7B | - |
| Phi-3/Phi-3.5 | 4B/14B | phi |
| Phi-3-small | 7B | phi_small |
| Phi-4 | 14B | phi4 |
| Pixtral | 12B | pixtral |
| Qwen (1-2.5) (Code/Math/MoE/QwQ) | 0.5B/1.5B/3B/7B/14B/32B/72B/110B | qwen |
| Qwen3 (MoE) | 0.6B/1.7B/4B/8B/14B/32B/235B | qwen3 |
| Qwen2-Audio | 7B | qwen2_audio |
| Qwen2.5-Omni** | 3B/7B | qwen2_omni |
| Qwen2-VL/Qwen2.5-VL/QVQ | 2B/3B/7B/32B/72B | qwen2_vl |
| Skywork o1 | 8B | skywork_o1 |
| StarCoder 2 | 3B/7B/15B | - |
| TeleChat2 | 3B/7B/35B/115B | telechat2 |
| XVERSE | 7B/13B/65B | xverse |
| Yi/Yi-1.5 (Code) | 1.5B/6B/9B/34B | yi |
| Yi-VL | 6B/34B | yi_vl |
| Yuan 2 | 2B/51B/102B | yuan |
NOTE
对于所有“基座”(Base)模型,template参数可以是default,alpaca,vicuna等任意值。但“对话”(Instruct/Chat)模型请务必使用对应的模板。请务必在训练和推理时采用完全一致的模板。
*:您需要从 main 分支安装
transformers并使用DISABLE_VERSION_CHECK=1来跳过版本检查。**:您需要安装特定版本的
transformers以使用该模型。
项目所支持模型的完整列表请参阅 constants.py。
您也可以在 template.py 中添加自己的对话模板。
训练方法
| 方法 | 全参数训练 | 部分参数训练 | LoRA | QLoRA |
|---|---|---|---|---|
| 预训练 | ✅ | ✅ | ✅ | ✅ |
| 指令监督微调 | ✅ | ✅ | ✅ | ✅ |
| 奖励模型训练 | ✅ | ✅ | ✅ | ✅ |
| PPO 训练 | ✅ | ✅ | ✅ | ✅ |
| DPO 训练 | ✅ | ✅ | ✅ | ✅ |
| KTO 训练 | ✅ | ✅ | ✅ | ✅ |
| ORPO 训练 | ✅ | ✅ | ✅ | ✅ |
| SimPO 训练 | ✅ | ✅ | ✅ | ✅ |
!TIP
有关 PPO 的实现细节,请参考此博客。
软硬件依赖
| 必需项 | 至少 | 推荐 |
|---|---|---|
| python | 3.9 | 3.10 |
| torch | 2.0.0 | 2.6.0 |
| transformers | 4.45.0 | 4.50.0 |
| datasets | 2.16.0 | 3.2.0 |
| accelerate | 0.34.0 | 1.2.1 |
| peft | 0.14.0 | 0.15.1 |
| trl | 0.8.6 | 0.9.6 |
| 可选项 | 至少 | 推荐 |
|---|---|---|
| CUDA | 11.6 | 12.2 |
| deepspeed | 0.10.0 | 0.16.4 |
| bitsandbytes | 0.39.0 | 0.43.1 |
| vllm | 0.4.3 | 0.8.2 |
| flash-attn | 2.5.6 | 2.7.2 |
硬件依赖
* 估算值
| 方法 | 精度 | 7B | 14B | 30B | 70B | xB |
|---|---|---|---|---|---|---|
Full (bf16 or fp16) | 32 | 120GB | 240GB | 600GB | 1200GB | 18xGB |
Full (pure_bf16) | 16 | 60GB | 120GB | 300GB | 600GB | 8xGB |
| Freeze/LoRA/GaLore/APOLLO/BAdam | 16 | 16GB | 32GB | 64GB | 160GB | 2xGB |
| QLoRA | 8 | 10GB | 20GB | 40GB | 80GB | xGB |
| QLoRA | 4 | 6GB | 12GB | 24GB | 48GB | x/2GB |
| QLoRA | 2 | 4GB | 8GB | 16GB | 24GB | x/4GB |
安装与配置
安装 LLaMA Factory
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".[torch,metrics]"
可选的额外依赖项:torch、torch-npu、metrics、deepspeed、liger-kernel、bitsandbytes、hqq、eetq、gptq、aqlm、vllm、sglang、galore、apollo、badam、adam-mini、qwen、minicpm_v、modelscope、openmind、swanlab、quality
遇到包冲突时,可使用
pip install --no-deps -e .解决。
使用Anaconda构建虚拟环境
使用Anaconda创建虚拟环境:
conda create -n training python=3.10
在环境中使用 LLaMA-Factory:
conda activate training
cd your_path_to_LLaMA-Factory
针对Windows 用户
安装 BitsAndBytes
如果要在 Windows 平台上开启量化 LoRA(QLoRA),需要安装预编译的 bitsandbytes 库, 支持 CUDA 11.1 到 12.2, 请根据您的 CUDA 版本情况选择适合的发布版本。
pip install https://github.com/jllllll/bitsandbytes-windows-webui/releases/
download/wheels/bitsandbytes-0.41.2.post2-py3-none-win_amd64.whl
安装 Flash Attention-2
如果要在 Windows 平台上开启 FlashAttention-2,请使用 flash-attention-windows-wheel 中的脚本自行编译与安装。
昇腾 NPU 用户指南
在昇腾 NPU 设备上安装 LLaMA Factory 时,请升级 Python 到 3.10 及以上,并需要指定额外依赖项,使用 pip install -e ".[torch-npu,metrics]" 命令安装。此外,还需要安装 Ascend CANN Toolkit 与 Kernels,安装方法请参考安装教程或使用以下命令:
# 请替换 URL 为 CANN 版本和设备型号对应的 URL
# 安装 CANN Toolkit
wget https://ascend-repo.obs.cn-east-2.myhuaweicloud.com/Milan-ASL/Milan-ASL%20V100R001C17SPC701/Ascend-cann-toolkit_8.0.RC1.alpha001_linux-"$(uname -i)".run
bash Ascend-cann-toolkit_8.0.RC1.alpha001_linux-"$(uname -i)".run --install
# 安装 CANN Kernels
wget https://ascend-repo.obs.cn-east-2.myhuaweicloud.com/Milan-ASL/Milan-ASL%20V100R001C17SPC701/Ascend-cann-kernels-910b_8.0.RC1.alpha001_linux.run
bash Ascend-cann-kernels-910b_8.0.RC1.alpha001_linux.run --install
# 设置环境变量
source /usr/local/Ascend/ascend-toolkit/set_env.sh
| 依赖项 | 至少 | 推荐 |
|---|---|---|
| CANN | 8.0.RC1 | 8.0.0.alpha002 |
| torch | 2.1.0 | 2.4.0 |
| torch-npu | 2.1.0 | 2.4.0.post2 |
| deepspeed | 0.13.2 | 0.13.2 |
| vllm-ascend | - | 0.7.3 |
请使用 ASCEND_RT_VISIBLE_DEVICES 而非 CUDA_VISIBLE_DEVICES 来指定运算设备。
如果遇到无法正常推理的情况,请尝试设置 do_sample: false。
安装 BitsAndBytes
如果要在 Ascend NPU 上进行基于 bitsandbytes 的 QLoRA 量化微调,请执行如下步骤:
- 手动编译 bitsandbytes:请参考安装文档完成 NPU 版的 bitsandbytes 安装,编译要求环境 cmake 版本不低于 3.22.1,g++ 版本不低于 12.x。
# 从源码安装 bitsandbytes
# 克隆 bitsandbytes 仓库, Ascend NPU 目前在 multi-backend-refactor 中支持
git clone -b multi-backend-refactor https://github.com/bitsandbytes-foundation/bitsandbytes.git
cd bitsandbytes/
# 安装依赖
pip install -r requirements-dev.txt
# 安装编译工具依赖,该步骤在不同系统上命令有所不同,供参考
apt-get install -y build-essential cmake
# 编译 & 安装
cmake -DCOMPUTE_BACKEND=npu -S .
make
pip install .
- 安装 transformers 的 main 分支版本。
git clone -b main https://github.com/huggingface/transformers.git
cd transformers
pip install .
- 在训练参数中设置
double_quantization: false,可参考示例。
数据准备
使用自定义数据集时,请更新
data/dataset_info.json文件。
对于 alpaca 格式的数据集,其 dataset_info.json 文件中的列应为:
"dataset_name": {
"file_name": "dataset_name.json",
"columns": {
"prompt": "instruction",
"query": "input",
"response": "output",
"system": "system",
"history": "history"
}
}
对于 shareGPT 格式的数据集,其 dataset_info.json 文件中的列应为:
"dataset_name": {
"file_name": "data.json",
"formatting": "sharegpt",
"columns": {
"messages": "conversations",
"system": "system",
"tools": "tools"
}
}
# system和tools是可选的,可以不添加
安装模型
设置完自定义数据集后稍微调整参数,开始微调,注意微调时本地无模型时会先下载模型,速度很慢,建议先下载到本地。
国内可以使用hf-mirror,这个比hugging face会快很多:
启动WebUI——LLaMA Board
llamafactory-cli webui
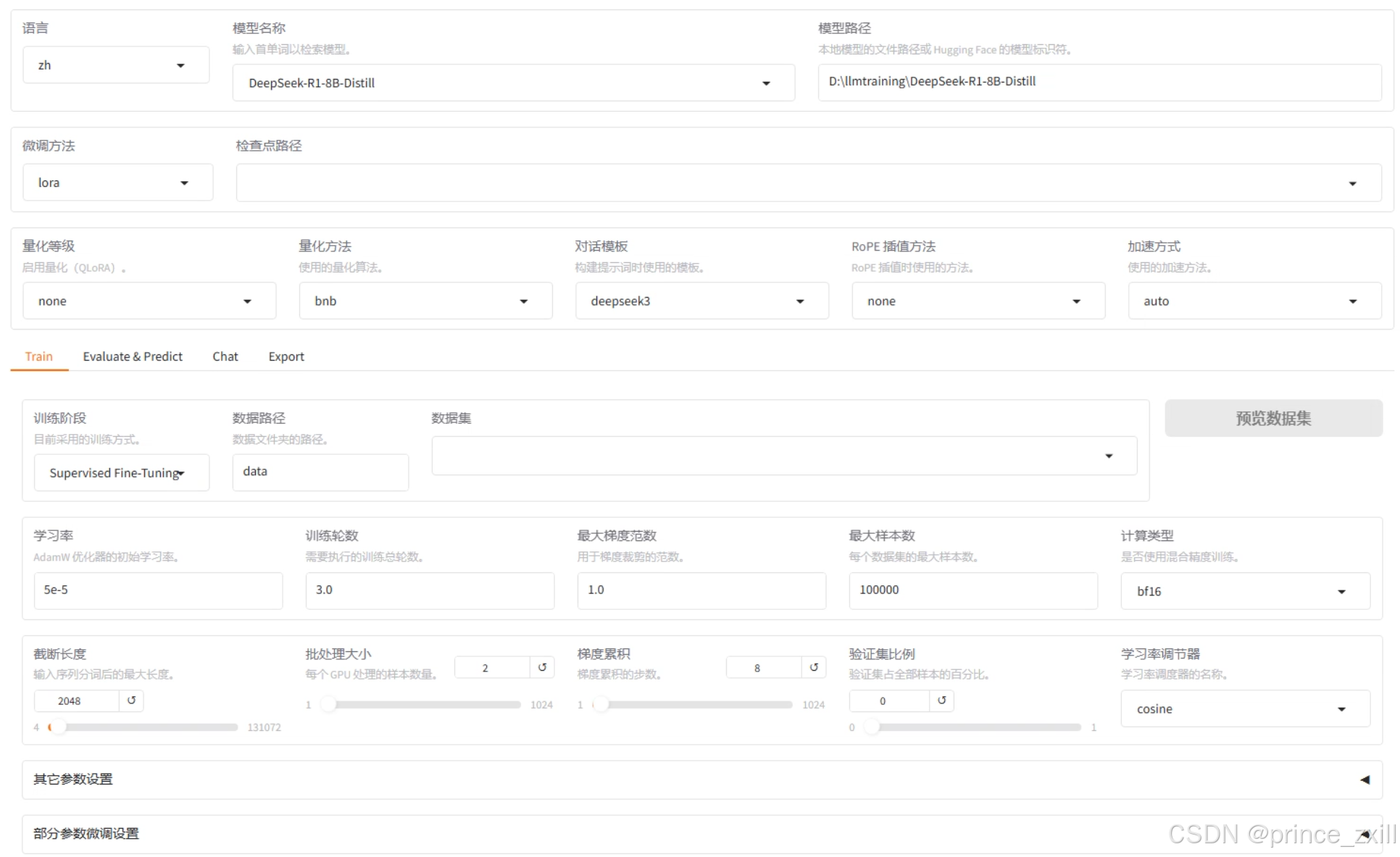
参数选择
参数内容
基本参数
| 参数名称 | 类型 | 介绍 | 默认值 |
|---|---|---|---|
| pure_bf16 | bool | 是否以纯bf16精度训练模型(不使用AMP)。 | False |
| stage | Literal[“pt”,“sft”, “rm”,“ppo”,“dpo”,“kto”] | 训练阶段。 | sft |
| finetuning_type | Literal[“lora”, “freeze”,“full”] | 微调方法。 | lora |
| use_llama_pro | bool | 是否仅训练扩展块中的参数(LLaMA Pro模式)。 | False |
| use_adam_mini | bool | 是否使用Adam-mini优化器。 | False |
| freeze_vision_tower | bool | MLLM训练时是否冻结视觉塔。 | True |
| freeze_multi_modal_projector | bool | MLLM训练时是否冻结多模态投影器。 | True |
| train_mm_proj_only | bool | 是否仅训练多模态投影器。 | False |
| compute_accuracy | bool | 是否在评估时计算token级别的准确率。 | False |
| disable_shuffling | bool | 是否禁用训练集的随机打乱。 | False |
| plot_loss | bool | 是否保存训练过程中的损失曲线。 | False |
| include_effective_tokens_per_second | bool | 是否计算有效的每秒token数。 | False |
LoRA
| 参数名称 | 类型 | 介绍 | 默认值 |
|---|---|---|---|
| additional_target | Optional[str] | 除 LoRA 层之外设置为可训练并保存在最终检查点中的模块名称。使用逗号分隔多个模块。 | None |
| lora_alpha | Optional[int] | LoRA 缩放系数。一般情况下为 lora_rank * 2。 | None |
| lora_dropout | float | LoRA 微调中的 dropout 率。 | 0 |
| lora_rank | int | LoRA 微调的本征维数 r,r 越大可训练的参数越多。 | 8 |
| lora_target | str | 应用 LoRA 方法的模块名称。使用逗号分隔多个模块,使用 all 指定所有模块。 | all |
| loraplus_lr_ratio | Optional[float] | LoRA+ 学习率比例(λ = nB/nA)。nA,nB 分别是 adapter matrices A 与 B 的学习率。 | None |
| loraplus_lr_embedding | Optional[float] | LoRA+ 嵌入层的学习率。 | 1e-6 |
| use_rslora | bool | 是否使用秩稳定 LoRA (Rank-Stabilized LoRA)。 | False |
| use_dora | bool | 是否使用权重分解 LoRA(Weight-Decomposed LoRA)。 | False |
| pissa_init | bool | 是否初始化 PiSSA 适配器。 | False |
| pissa_iter | Optional[int] | PiSSA 中 FSVD 执行的迭代步数。使用 -1 将其禁用。 | 16 |
| pissa_convert | bool | 是否将 PiSSA 适配器转换为正常的 LoRA 适配器。 | False |
| create_new_adapter | bool | 是否创建一个具有随机初始化权重的新适配器。 | False |
DPO/PPO/KTO
| 参数名称 | 类型 | 介绍 | 默认值 |
|---|---|---|---|
| pref_beta | float | 偏好损失中的 beta 参数。 | 0.1 |
| pref_ftx | float | DPO 训练中的 sft loss 系数。 | 0.0 |
| pref_loss | Literal[“sigmoid”, “hinge”, “ipo”, “kto_pair”, “orpo”, “simpo”] | DPO 训练中使用的偏好损失类型。可选值为:sigmoid, hinge, ipo, kto_pair, orpo, simpo。 | sigmoid |
| dpo_label_smoothing | float | 标签平滑系数,取值范围为 [0,0.5]。 | 0.0 |
| kto_chosen_weight | float | KTO 训练中 chosen 标签 loss 的权重。 | 1.0 |
| kto_rejected_weight | float | KTO 训练中 rejected 标签 loss 的权重。 | 1.0 |
| simpo_gamma | float | SimPO 损失中的 reward margin。 | 0.5 |
| ppo_buffer_size | int | PPO 训练中的 mini-batch 大小。 | 1 |
| ppo_epochs | int | PPO 训练迭代次数。 | 4 |
| ppo_score_norm | bool | 是否在 PPO 训练中使用归一化分数。 | False |
| ppo_target | float | PPO 训练中自适应 KL 控制的目标 KL 值。 | 6.0 |
| ppo_whiten_rewards | bool | PPO 训练中是否对奖励进行归一化。 | False |
| ref_model | Optional[str] | PPO 或 DPO 训练中使用的参考模型路径。 | None |
| ref_model_adapters | Optional[str] | 参考模型的适配器路径。 | None |
| ref_model_quantization_bit | Optional[int] | 参考模型的量化位数,支持 4 位或 8 位量化。 | None |
| reward_model | Optional[str] | PPO 训练中使用的奖励模型路径。 | None |
| reward_model_adapters | Optional[str] | 奖励模型的适配器路径。 | None |
| reward_model_quantization_bit | Optional[int] | 奖励模型的量化位数。 | None |
| reward_model_type | Literal[“lora”, “full”, “api”] | PPO 训练中使用的奖励模型类型。可选值为:lora, full, api。 | lora |
Freeze
| 参数名称 | 类型 | 介绍 | 默认值 |
|---|---|---|---|
| freeze_trainable_layers | int | 可训练层的数量。正数表示最后 n 层被设置为可训练的,负数表示前 n 层被设置为可训练的。 | - |
| freeze_trainable_modules | str | 可训练层的名称。使用 all 来指定所有模块。 | - |
| freeze_extra_modules | Optional[str] | 除了隐藏层外可以被训练的模块名称,被指定的模块将会被设置为可训练的。使用逗号分隔多个模块。 | - |
Apollo
| 参数名称 | 类型 | 介绍 | 默认值 |
|---|---|---|---|
| use_apollo | bool | 是否使用 APOLLO 优化器。 | False |
| apollo_target | str | 适用 APOLLO 的模块名称。使用逗号分隔多个模块,使用 all 指定所有线性模块。 | all |
| apollo_rank | int | APOLLO 梯度的秩。 | 16 |
| apollo_update_interval | int | 更新 APOLLO 投影的步数间隔。 | 200 |
| apollo_scale | float | APOLLO 缩放系数。 | 32.0 |
| apollo_proj | Literal[“svd”, “random”] | APOLLO 低秩投影算法类型(svd 或 random)。 | random |
| apollo_proj_type | Literal[“std”, “right”, “left”] | APOLLO 投影类型。 | std |
| apollo_scale_type | Literal[“channel”, “tensor”] | APOLLO 缩放类型(channel 或 tensor)。 | channel |
| apollo_layerwise | bool | 是否启用层级更新以进一步节省内存。 | False |
| apollo_scale_front | bool | 是否在梯度缩放前使用范数增长限制器。 | False |
BAdam
| 参数名称 | 类型 | 介绍 | 默认值 |
|---|---|---|---|
| use_badam | bool | 是否使用 BAdam 优化器。 | False |
| badam_mode | Literal[“layer”, “ratio”] | BAdam 的使用模式,可选值为 layer 或 ratio。 | layer |
| badam_start_block | Optional[int] | layer-wise BAdam 的起始块索引。 | None |
| badam_switch_mode | Optional[Literal[“ascending”, “descending”, “random”, “fixed”]] | layer-wise BAdam 中块更新策略,可选值有: ascending, descending, random, fixed。 | ascending |
| badam_switch_interval | Optional[int] | layer-wise BAdam 中块更新步数间隔。使用 -1 禁用块更新。 | 50 |
| badam_update_ratio | float | ratio-wise BAdam 中的更新比例。 | 0.05 |
| badam_mask_mode | Literal[“adjacent”, “scatter”] | BAdam 优化器的掩码模式,可选值为 adjacent 或 scatter。 | adjacent |
| badam_verbose | int | BAdam 优化器的详细输出级别,0 表示无输出,1 表示输出块前缀,2 表示输出可训练参数。 | 0 |
GaLore
| 参数名称 | 类型 | 介绍 | 默认值 |
|---|---|---|---|
| use_galore | bool | 是否使用 GaLore 算法。 | False |
| galore_target | str | 应用 GaLore 的模块名称。使用逗号分隔多个模块,使用 all 指定所有线性模块。 | all |
| galore_rank | int | GaLore 梯度的秩。 | 16 |
| galore_update_interval | int | 更新 GaLore 投影的步数间隔。 | 200 |
| galore_scale | float | GaLore 的缩放系数。 | 0.25 |
| galore_proj_type | Literal[“std”, “reverse_std”, “right”, “left”, “full”] | GaLore 投影的类型,可选值有: std, reverse_std, right, left, full。 | std |
| galore_layerwise | bool | 是否启用逐层更新以进一步节省内存。 | False |
数据参数
| 参数名称 | 类型 | 介绍 | 默认值 |
|---|---|---|---|
| template | Optional[str] | 训练和推理时构造 prompt 的模板。 | None |
| dataset | Optional[str] | 用于训练的数据集名称。使用逗号分隔多个数据集。 | None |
| eval_dataset | Optional[str] | 用于评估的数据集名称。使用逗号分隔多个数据集。 | None |
| dataset_dir | str | 存储数据集的文件夹路径。 | “data” |
| media_dir | Optional[str] | 存储图像、视频或音频的文件夹路径。如果未指定,默认为 dataset_dir。 | None |
| cutoff_len | int | 输入的最大 token 数,超过该长度会被截断。 | 2048 |
| train_on_prompt | bool | 是否在输入 prompt 上进行训练。 | False |
| mask_history | bool | 是否仅使用当前对话轮次进行训练。 | False |
| streaming | bool | 是否启用数据流模式。 | False |
| buffer_size | int | 启用 streaming 时用于随机选择样本的 buffer 大小。 | 16384 |
| mix_strategy | Literal[“concat”, “interleave_under”, “interleave_over”] | 数据集混合策略,支持 concat、interleave_under、interleave_over。 | concat |
| interleave_probs | Optional[str] | 使用 interleave 策略时,指定从多个数据集中采样的概率。多个数据集的概率用逗号分隔。 | None |
| overwrite_cache | bool | 是否覆盖缓存的训练和评估数据集。 | False |
| preprocessing_batch_size | int | 预处理时每批次的示例数量。 | 1000 |
| preprocessing_num_workers | Optional[int] | 预处理时使用的进程数量。 | None |
| max_samples | Optional[int] | 每个数据集的最大样本数:设置后,每个数据集的样本数将被截断至指定的 max_samples。 | None |
| eval_num_beams | Optional[int] | 模型评估时的 num_beams 参数。 | None |
| ignore_pad_token_for_loss | bool | 计算 loss 时是否忽略 pad token。 | True |
| val_size | float | 验证结果对所使用的训练数据集的大小。取值在 [0,1] 之间。启用 streaming 时 val_size 应是整数。 | 0.0 |
| packing | Optional[bool] | 是否启用 sequences packing。预测结束时默认启用。 | None |
| neat_packing | bool | 是否启用不使用 cross-attention 的 sequences packing。 | False |
| tool_format | Optional[str] | 用于构造函数调用示例的格式。 | None |
| tokenized_path | Optional[str] | Tokenized datasets 的保存或加载路径。如果路径存在,会加载已有的 tokenized datasets;如果路径不存在,则会在分词后将 tokenized datasets 保存在此路径中。 | None |
微调方法:
这里有三种,full全参数微调, Freeze(冻结部分参数) LoRA(Low-Rank Adaptation),还有 QLoRA 等。
全参数微调可以最大的模型适应性,可以全面调整模型以适应新任务。通常能达到最佳性能。
-
Freeze:训练速度比全参数微调快,会降低计算资源需求。
-
LoRA :显著减少了可训练参数数量,降低内存需求,训练速度快,计算效率高。还可以为不同任务保存多个小型适配器,减少了过拟合风险。
-
QLoRA:训练速度跟 LoRA 差不多,基本保持了 LoRa 的优势,会进一步减少内存使用。
综合速度,灵活性考虑 选择LoRA或者QLorRA。调整参数后开始训练即可(推荐使用默认参数),训练后得到.safetensors文件,即为微调后的模型。
量化
量化等级有8位量化( INT8)和4位量化( INT4 ),QLoRA 它允许在使用低位量化(如4位)的同时,通过 LoRA 方法进行高效的微调。
量化方法
bitsandbytes 与 hqq:
-
Bitsandbytes:内存效率高,可以显著减少 GPU 内存使用
-
Hqq: 提供更多的量化选项和更细粒度的控制,使用可能稍微复杂一些,需要更多的配置。
加速方式:auto,unsloth,flashattn2
auto自动模式会根据你的硬件配置和当前的训练任务自动选择最适合的加速技术。这是最简单的一种方式,不需要用户进行任何额外配置。
FlashAttention2 是一种优化的注意力机制,旨在加速 Transformer 模型的训练。它通过优化内存访问和计算流程来提高训练速度。
Unsloth 是一种特定的优化技术,用于减少训练过程中的计算冗余和内存占用,从而加快训练速度。unsloth需要单独安装。
学习率
学习率通常在1e-5 到 3e-5之间,于大型语言模型(如 BERT、GPT 等)的微调,常用的学习率范围是 2e-5 到5e-5,从一个相对较小的值开始,如 2e-5 。
如果训练不稳定或损失波动很大,可以尝试降低学习率,如果训练进展太慢,可以尝试略微增加学习率。
训练轮数
对于大语言模型的微调,通常在2到10个epoch之间, 轮数过多可能导致过拟合,特别是在小数据集上。
最大梯度范数
(Max Gradient Norm)是一种用于防止梯度爆炸的技术,也称为梯度裁剪(Gradient Clipping)。这个参数设置了梯度的最大允许值,如果梯度超过这个值,就会被缩放到这个最大值。
通常在 0.1 到 10 之间,太小:可能会限制模型学习,太大:可能无法有效防止梯度爆炸。
最大样本数
它决定了每个数据集中使用多少样本进行训练‘’
如果原始数据集很大,设置一个合理的最大样本数可以减少训练时间,如果计算资源有限,较小的样本数可以加快训练速度。
计算类型
有 bf16 fp16 fp32 purebf16,如果你的硬件支持 bfloat16,且你希望最大化内存效率和计算速度,可以选择 bf16 或 purebf16。
如果你的硬件支持 fp16,你希望加速训练过程且能够接受较低的数值精度,可以选择 fp16。
如果你不确定你的硬件支持哪些类型,或你需要高精度计算,可以选择 fp32。
批处理大小:
批处理大小是指在每次迭代中输入到模型中的样本数量。
在深度学习训练过程中,数据通常会被分成多个批次(batch)进行处理,每个批次包含一组样本。
较大的批处理大小会占用更多的内存(显存)。
如果批处理大小过大,可能导致显存不足,训练无法进行。
合理的批处理大小可以提高计算效率,大批量的数据可以更有效地利用 GPU 进行并行计算。
截断长度:
截断长度是指在处理输入序列时,模型所能接受的最大标记(token)数量。
如果输入序列超过了这个长度,多余的部分将被截断,以确保输入序列长度不会超出模型的处理能力。
对于文本分类任务,通常截断到128或256个标记可能就足够了;而对于更复杂的任务,如文本生成或翻译,可能需要更长的长度。
验证集比例:
是指在机器学习和深度学习模型训练过程中,从训练数据集中划分出来的一部分数据,用于评估模型的性能。
验证集的数据不参与模型的训练,仅用于在训练过程中监控模型的表现,以防止过拟合和调整模型的超参数,常见的比例有10%、20%等,具体选择取决于数据集的大小和具体的应用场景。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











