






在工作流中deepseek-r1的think标签内部的内容,很容易让工作流其他的llm产生幻觉,导致不能良好的生成目标效果。
我们通过代码的方式让deepseek-r1既有think思考链的效果,又不传递思考链。

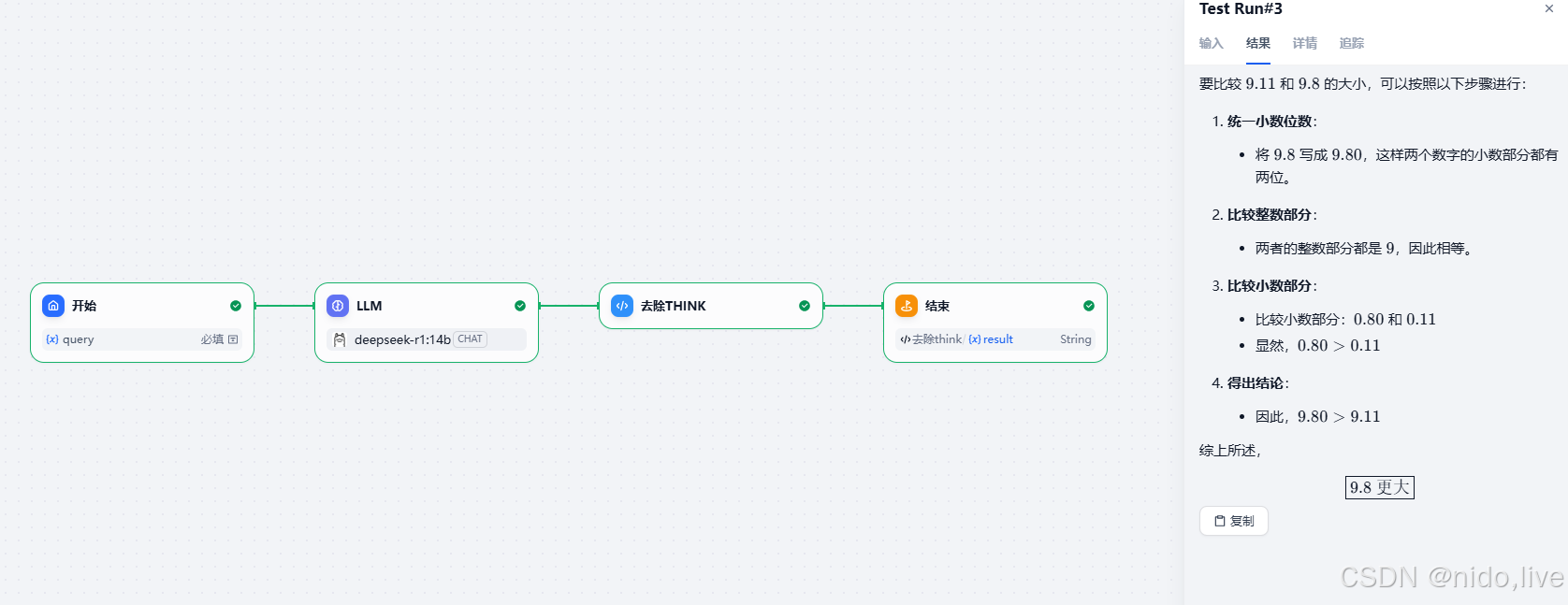
工作流的逻辑为上图
去除think中的代码为
import re
def main(answer: str) -> dict:
cleaned_text = re.sub(r'<think[^>]*>.*?</think>', '', answer, flags=re.DOTALL)
# 移除清理后可能在开头的多余换行符
final_text = re.sub(r'^\n+', '', cleaned_text)
return {
"result": final_text,
}这样子生成的效果就将think内容替换了
整个工作流的代码为
app:
description: ''
icon: 🤖
icon_background: '#FFEAD5'
mode: workflow
name: outThink
use_icon_as_answer_icon: false
dependencies:
- current_identifier: null
type: marketplace
value:
marketplace_plugin_unique_identifier: langgenius/ollama:0.0.3@9ded90ac00e8510119a24be7396ba77191c9610d5e1e29f59d68fa1229822fc7
kind: app
version: 0.1.5
workflow:
conversation_variables: []
environment_variables: []
features:
file_upload:
allowed_file_extensions:
- .JPG
- .JPEG
- .PNG
- .GIF
- .WEBP
- .SVG
allowed_file_types:
- image
allowed_file_upload_methods:
- local_file
- remote_url
enabled: false
fileUploadConfig:
audio_file_size_limit: 50
batch_count_limit: 5
file_size_limit: 15
image_file_size_limit: 10
video_file_size_limit: 100
workflow_file_upload_limit: 10
image:
enabled: false
number_limits: 3
transfer_methods:
- local_file
- remote_url
number_limits: 3
opening_statement: ''
retriever_resource:
enabled: true
sensitive_word_avoidance:
enabled: false
speech_to_text:
enabled: false
suggested_questions: []
suggested_questions_after_answer:
enabled: false
text_to_speech:
enabled: false
language: ''
voice: ''
graph:
edges:
- data:
isInIteration: false
isInLoop: false
sourceType: start
targetType: llm
id: 1743671825415-source-1743671830921-target
source: '1743671825415'
sourceHandle: source
target: '1743671830921'
targetHandle: target
type: custom
zIndex: 0
- data:
isInIteration: false
isInLoop: false
sourceType: llm
targetType: code
id: 1743671830921-source-1743671844725-target
source: '1743671830921'
sourceHandle: source
target: '1743671844725'
targetHandle: target
type: custom
zIndex: 0
- data:
isInIteration: false
isInLoop: false
sourceType: code
targetType: end
id: 1743671844725-source-1743671861862-target
source: '1743671844725'
sourceHandle: source
target: '1743671861862'
targetHandle: target
type: custom
zIndex: 0
nodes:
- data:
desc: ''
selected: false
title: 开始
type: start
variables:
- label: query
max_length: 48
options: []
required: true
type: text-input
variable: query
height: 90
id: '1743671825415'
position:
x: 80
y: 282
positionAbsolute:
x: 80
y: 282
selected: false
sourcePosition: right
targetPosition: left
type: custom
width: 244
- data:
context:
enabled: false
variable_selector: []
desc: ''
model:
completion_params:
temperature: 0.7
mode: chat
name: deepseek-r1:14b
provider: langgenius/ollama/ollama
prompt_template:
- id: bf6b98c6-75dd-4513-b87f-21d6087490ef
role: system
text: 回答问题{{#1743671825415.query#}}
selected: false
title: LLM
type: llm
variables: []
vision:
enabled: false
height: 90
id: '1743671830921'
position:
x: 384
y: 282
positionAbsolute:
x: 384
y: 282
selected: false
sourcePosition: right
targetPosition: left
type: custom
width: 244
- data:
code: "import re\ndef main(answer: str) -> dict:\n cleaned_text = re.sub(r'<think[^>]*>.*?</think>',\
\ '', answer, flags=re.DOTALL)\n # 移除清理后可能在开头的多余换行符\n final_text =\
\ re.sub(r'^\\n+', '', cleaned_text)\n return {\n \"result\":\
\ final_text,\n }"
code_language: python3
desc: ''
outputs:
result:
children: null
type: string
selected: false
title: 去除think
type: code
variables:
- value_selector:
- '1743671830921'
- text
variable: answer
height: 54
id: '1743671844725'
position:
x: 688
y: 282
positionAbsolute:
x: 688
y: 282
selected: true
sourcePosition: right
targetPosition: left
type: custom
width: 244
- data:
desc: ''
outputs:
- value_selector:
- '1743671844725'
- result
variable: result
selected: false
title: 结束
type: end
height: 90
id: '1743671861862'
position:
x: 992
y: 282
positionAbsolute:
x: 992
y: 282
selected: false
sourcePosition: right
targetPosition: left
type: custom
width: 244
viewport:
x: -39
y: 94
zoom: 1


















 1554
1554

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









