







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Python全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。





既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Python知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024c (备注Python)

正文
数据预处理
transform = transforms.Compose([
transforms.Resize((224, 224)),
Cutout(),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])
transform_test = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])
数据读取
然后我们在dataset文件夹下面新建 init.py和dataset.py,在mydatasets.py文件夹写入下面的代码:
说一下代码的核心逻辑。
第一步 建立字典,定义类别对应的ID,用数字代替类别。
第二步 在__init__里面编写获取图片路径的方法。测试集只有一层路径直接读取,训练集在train文件夹下面是类别文件夹,先获取到类别,再获取到具体的图片路径。然后使用sklearn中切分数据集的方法,按照7:3的比例切分训练集和验证集。
第三步 在__getitem__方法中定义读取单个图片和类别的方法,由于图像中有位深度32位的,所以我在读取图像的时候做了转换。
代码如下:
coding:utf8
import os
from PIL import Image
from torch.utils import data
from torchvision import transforms as T
from sklearn.model_selection import train_test_split
Labels = {‘Black-grass’: 0, ‘Charlock’: 1, ‘Cleavers’: 2, ‘Common Chickweed’: 3,
‘Common wheat’: 4, ‘Fat Hen’: 5, ‘Loose Silky-bent’: 6, ‘Maize’: 7, ‘Scentless Mayweed’: 8,
‘Shepherds Purse’: 9, ‘Small-flowered Cranesbill’: 10, ‘Sugar beet’: 11}
class SeedlingData(data.Dataset):
def init(self, root, transforms=None, train=True, test=False):
“”"
主要目标: 获取所有图片的地址,并根据训练,验证,测试划分数据
“”"
self.test = test
self.transforms = transforms
if self.test:
imgs = [os.path.join(root, img) for img in os.listdir(root)]
self.imgs = imgs
else:
imgs_labels = [os.path.join(root, img) for img in os.listdir(root)]
imgs = []
for imglable in imgs_labels:
for imgname in os.listdir(imglable):
imgpath = os.path.join(imglable, imgname)
imgs.append(imgpath)
trainval_files, val_files = train_test_split(imgs, test_size=0.3, random_state=42)
if train:
self.imgs = trainval_files
else:
self.imgs = val_files
def getitem(self, index):
“”"
一次返回一张图片的数据
“”"
img_path = self.imgs[index]
img_path = img_path.replace(“\”, ‘/’)
if self.test:
label = -1
else:
labelname = img_path.split(‘/’)[-2]
label = Labels[labelname]
data = Image.open(img_path).convert(‘RGB’)
data = self.transforms(data)
return data, label
def len(self):
return len(self.imgs)
然后我们在train.py调用SeedlingData读取数据 ,记着导入刚才写的dataset.py(from mydatasets import SeedlingData)
读取数据
dataset_train = SeedlingData(‘data/train’, transforms=transform, train=True)
dataset_test = SeedlingData(“data/train”, transforms=transform_test, train=False)
导入数据
train_loader = torch.utils.data.DataLoader(dataset_train, batch_size=BATCH_SIZE, shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset_test, batch_size=BATCH_SIZE, shuffle=False)
===============================================================
设置loss函数为nn.CrossEntropyLoss()。
-
设置模型为coatnet_0,修改最后一层全连接输出改为12(数据集的类别)。
-
优化器设置为adam。
-
学习率调整策略改为余弦退火
实例化模型并且移动到GPU
criterion = nn.CrossEntropyLoss()
#criterion = SoftTargetCrossEntropy()
model_ft = convnext_tiny(pretrained=True)
num_ftrs = model_ft.head.in_features
model_ft.head = nn.Linear(num_ftrs, 12)
model_ft.to(DEVICE)
print(model_ft)
选择简单暴力的Adam优化器,学习率调低
optimizer = optim.Adam(model_ft.parameters(), lr=modellr)
cosine_schedule = optim.lr_scheduler.CosineAnnealingLR(optimizer=optimizer,T_max=20,eta_min=1e-9)
====================================================================
alpha=0.2 Mixup所需的参数。
定义训练过程
alpha=0.2
def train(model, device, train_loader, optimizer, epoch):
model.train()
sum_loss = 0
total_num = len(train_loader.dataset)
print(total_num, len(train_loader))
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device, non_blocking=True), target.to(device, non_blocking=True)
data, labels_a, labels_b, lam = mixup_data(data, target, alpha)
optimizer.zero_grad()
output = model(data)
loss = mixup_criterion(criterion, output, labels_a, labels_b, lam)
loss.backward()
optimizer.step()
print_loss = loss.data.item()
sum_loss += print_loss
if (batch_idx + 1) % 10 == 0:
print(‘Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}’.format(
epoch, (batch_idx + 1) * len(data), len(train_loader.dataset),
-
- (batch_idx + 1) / len(train_loader), loss.item()))
ave_loss = sum_loss / len(train_loader)
print(‘epoch:{},loss:{}’.format(epoch, ave_loss))
ACC=0
验证过程
def val(model, device, test_loader):
global ACC
model.eval()
test_loss = 0
correct = 0
total_num = len(test_loader.dataset)
print(total_num, len(test_loader))
with torch.no_grad():
for data, target in test_loader:
data, target = Variable(data).to(device), Variable(target).to(device)
output = model(data)
loss = criterion(output, target)
_, pred = torch.max(output.data, 1)
correct += torch.sum(pred == target)
print_loss = loss.data.item()
test_loss += print_loss
correct = correct.data.item()
acc = correct / total_num
avgloss = test_loss / len(test_loader)
print(‘\nVal set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n’.format(
avgloss, correct, len(test_loader.dataset), 100 * acc))
if acc > ACC:
torch.save(model_ft, ‘model_’ + str(epoch) + ‘_’ + str(round(acc, 3)) + ‘.pth’)
ACC = acc
训练
for epoch in range(1, EPOCHS + 1):
train(model_ft, DEVICE, train_loader, optimizer, epoch)
cosine_schedule.step()
val(model_ft, DEVICE, test_loader)
然后就可以开始训练了
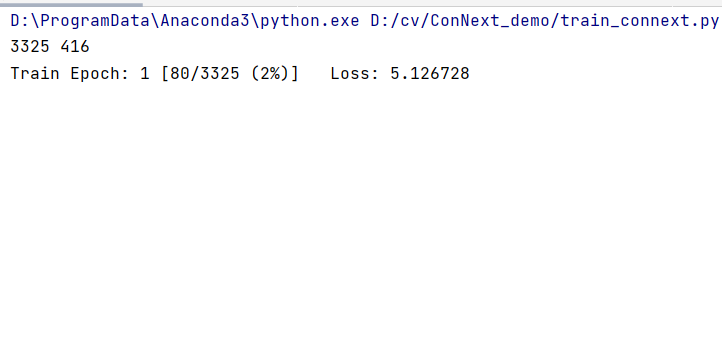
训练10个epoch就能得到不错的结果:
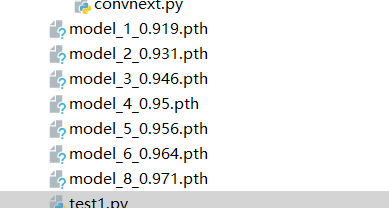
=============================================================
测试集存放的目录如下图:
第一步 定义类别,这个类别的顺序和训练时的类别顺序对应,一定不要改变顺序!!!!
classes = (‘Black-grass’, ‘Charlock’, ‘Cleavers’, ‘Common Chickweed’,
‘Common wheat’, ‘Fat Hen’, ‘Loose Silky-bent’,
‘Maize’, ‘Scentless Mayweed’, ‘Shepherds Purse’, ‘Small-flowered Cranesbill’, ‘Sugar beet’)
第二步 定义transforms,transforms和验证集的transforms一样即可,别做数据增强。
transform_test = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])
第三步 加载model,并将模型放在DEVICE里。
DEVICE = torch.device(“cuda:0” if torch.cuda.is_available() else “cpu”)
model = torch.load(“model_8_0.971.pth”)
model.eval()
model.to(DEVICE)
第四步 读取图片并预测图片的类别,在这里注意,读取图片用PIL库的Image。不要用cv2,transforms不支持。
path = ‘data/test/’
testList = os.listdir(path)
for file in testList:
img = Image.open(path + file)
img = transform_test(img)
img.unsqueeze_(0)
img = Variable(img).to(DEVICE)
out = model(img)
Predict
_, pred = torch.max(out.data, 1)
print(‘Image Name:{},predict:{}’.format(file, classes[pred.data.item()]))
测试完整代码:
import torch.utils.data.distributed
import torchvision.transforms as transforms
from PIL import Image
from torch.autograd import Variable
import os
classes = (‘Black-grass’, ‘Charlock’, ‘Cleavers’, ‘Common Chickweed’,
‘Common wheat’, ‘Fat Hen’, ‘Loose Silky-bent’,
‘Maize’, ‘Scentless Mayweed’, ‘Shepherds Purse’, ‘Small-flowered Cranesbill’, ‘Sugar beet’)
transform_test = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])
DEVICE = torch.device(“cuda:0” if torch.cuda.is_available() else “cpu”)
model = torch.load(“model_8_0.971.pth”)
model.eval()
model.to(DEVICE)
path = ‘data/test/’
testList = os.listdir(path)
for file in testList:
img = Image.open(path + file)
img = transform_test(img)
img.unsqueeze_(0)
img = Variable(img).to(DEVICE)
out = model(img)
Predict
_, pred = torch.max(out.data, 1)
print(‘Image Name:{},predict:{}’.format(file, classes[pred.data.item()]))
运行结果:
================================================================
第二种,使用自定义的Dataset读取图片。前三步同上,差别主要在第四步。读取数据的时候,使用Dataset的SeedlingData读取。
dataset_test =SeedlingData(‘data/test/’, transform_test,test=True)
print(len(dataset_test))
对应文件夹的label
for index in range(len(dataset_test)):
item = dataset_test[index]
img, label = item
img.unsqueeze_(0)
data = Variable(img).to(DEVICE)
output = model(data)
_, pred = torch.max(output.data, 1)
print(‘Image Name:{},predict:{}’.format(dataset_test.imgs[index], classes[pred.data.item()]))
index += 1
最后
Python崛起并且风靡,因为优点多、应用领域广、被大牛们认可。学习 Python 门槛很低,但它的晋级路线很多,通过它你能进入机器学习、数据挖掘、大数据,CS等更加高级的领域。Python可以做网络应用,可以做科学计算,数据分析,可以做网络爬虫,可以做机器学习、自然语言处理、可以写游戏、可以做桌面应用…Python可以做的很多,你需要学好基础,再选择明确的方向。这里给大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
👉Python所有方向的学习路线👈
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

👉Python必备开发工具👈
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

👉Python全套学习视频👈
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。

👉实战案例👈
学python就与学数学一样,是不能只看书不做题的,直接看步骤和答案会让人误以为自己全都掌握了,但是碰到生题的时候还是会一筹莫展。
因此在学习python的过程中一定要记得多动手写代码,教程只需要看一两遍即可。

👉大厂面试真题👈
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024c (备注python)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
b2ffa9c677ac40fc0.png)
👉实战案例👈
学python就与学数学一样,是不能只看书不做题的,直接看步骤和答案会让人误以为自己全都掌握了,但是碰到生题的时候还是会一筹莫展。
因此在学习python的过程中一定要记得多动手写代码,教程只需要看一两遍即可。
👉大厂面试真题👈
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024c (备注python)
[外链图片转存中…(img-Spa5EIoT-1713287367539)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









