







MC和TD都是无模型策略模型,直接从episode experience中学习,第一次看的话会有些模棱两可。

接下来,我会展示MC(Monte Carlo) 和 TD(Temporal Difference)这两种算法之间的差异以及如何计算。如果你感兴趣的话,往下看吧!!!
MC On Policy Evaluation
Frist-Visit MC
import numpy as np
def back_Reward(t, S, R, gamma):
if t == S.size-1:
e = S[t]
return R[e]
else:
e = S[t]
return R[e]+gamma*back_Reward(t+1, S, R, gamma)
# initialize N, G
N = np.zeros(7)
G = np.zeros(7)
visit = np.zeros(7)
# a sample episode S, A, R
S = np.array([0, 1, 2, 3, 4]) # 访问顺序0-1-2-3-4-5
R = np.array([0, 0, 0, 0, 5]) # 对应reward
# 首次迭代
for t in range(0, 5):
e = S[t]
if visit[e]==0:
N[e] += 1
G[e] += back_Reward(t, S, R, gamma)
visit[e] = 1
V = np.true_divide(G, N, out=np.zeros_like(G), where=N!=0)
对于MC来说,frist visit并没有做太多的操作。如果是第一次访问
s
s
s,就将
G
(
s
)
G(s)
G(s)做一个累加和,最后再除以
N
(
s
)
N(s)
N(s)以求平均。
V
π
=
G
(
s
)
/
N
(
s
)
V^\pi = G(s)/N(s)
Vπ=G(s)/N(s)
当sample episode足够多时,
V
π
V^\pi
Vπ就无限接近于真实值,即具有无偏性。
当你运行程序时,会得到如下结果:
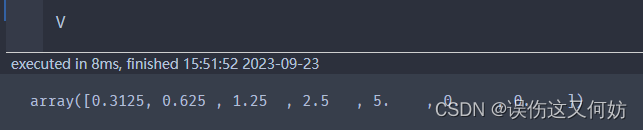
在这里我们能调的超参数只有一个:
γ
\gamma
γ。
γ
\gamma
γ 与 V 的对应关系如下:
| γ \gamma γ | V(s) |
|---|---|
| 0 | [0. 0. 0. 0. 5. 0. 0.] |
| 0.25 | [0.0195 0.0781 0.3125 1.25 5. 0. 0. ] |
| 0.5 | [0.3125 0.625 1.25 2.5 5. 0. 0. ] |
| 0.75 | [1.5820 2.1093 2.8125 3.75 5. 0. 0. ] |
| 1 | [5. 5. 5. 5. 5. 0. 0.] |
随着 γ \gamma γ的不断增大,模型会越来越重视长期收益,实验结果符合预期。
Every-Visit MC
Every-Visit 与 Frist-Visit 的算法逻辑几乎是一模一样,其区别也正是Every和Frist的区别。
对于Every-Visit而言,他不管之前是否访问过该状态,都会加和求平均。
此时,我们可以简化公式:
N
n
e
w
(
s
)
=
N
o
l
d
(
s
)
+
1
V
n
e
w
π
(
s
)
=
V
o
l
d
π
∗
N
o
l
d
+
G
i
,
t
N
n
e
w
=
V
o
l
d
π
∗
(
N
n
e
w
−
1
)
+
G
i
,
t
N
n
e
w
=
V
o
l
d
π
+
1
N
(
s
)
(
G
i
,
t
−
V
o
l
d
π
(
s
)
)
N_{new}(s) = N_{old}(s)+1\\ V_{new}^\pi(s) = {V_{old}^\pi*N_{old}+G_{i, t}\over N_{new}}={V^\pi_{old}*(N_{new}-1)+G_{i, t}\over N_{new}}\\=V_{old}^\pi+{1\over N(s)}(G_{i, t}-V_{old}^\pi(s))
Nnew(s)=Nold(s)+1Vnewπ(s)=NnewVoldπ∗Nold+Gi,t=NnewVoldπ∗(Nnew−1)+Gi,t=Voldπ+N(s)1(Gi,t−Voldπ(s))
用
α
\alpha
α代替得到更加具有普遍性的V(s)计算方法。
N
n
e
w
(
s
)
=
V
o
l
d
π
+
α
(
G
i
,
t
−
V
o
l
d
π
(
s
)
)
N_{new}(s)=V^\pi_{old}+\alpha(G_{i, t}-V^\pi_{old}(s))
Nnew(s)=Voldπ+α(Gi,t−Voldπ(s))
当
α
=
1
N
(
s
)
\alpha={1\over N(s)}
α=N(s)1时,为Every-Visit MC。当
α
>
1
N
(
s
)
\alpha > {1\over N(s)}
α>N(s)1时,适用于非静态环境。
代码实现如下:
import numpy as np
def back_Reward(t, S, R, gamma):
if t == S.size-1:
e = S[t]
return R[e]
else:
e = S[t]
return R[e]+gamma*back_Reward(t+1, S, R, gamma)
gammas = np.array([0, 0.25, 0.5, 0.75, 1])
# a sample episode S, A, R
S = np.array([0, 1, 2, 3, 4])
R = np.array([0, 0, 0, 0, 5])
# 迭代
for gamma in gammas:
# initialize N, G
N = np.zeros(7)
G = np.zeros(7)
V = np.zeros(7)
for t in range(0, 5):
e = S[t]
N[e] += 1
G[e] += back_Reward(t, S, R, gamma)
V = V+N*(G-V)
print(V)
由于该sample episode无重复状态,因此结果和Frist-Visit MC一样。
无偏性讨论
在静态环境(符合马尔可夫链环境)下,Frist-Visit MC和every-Visit都可以保证状态相对独立,因此都具有无偏性;在非静态情况下,随着环境的动态变化,Every-Visitd MC的准确性可能会受到影响,而Frist-Visit MC仅仅计算第一次访问时的收益,因此每个时刻的状态相互独立,仍然具有无偏性。
注:无偏性指期望与真实值相等。
TD for Estimating V
TD (Temporal Difference)将MC(Monte Carlo)和DP(Dynamic programming)结合起来,可以更加快速简便地计算
V
π
V^\pi
Vπ。
DP中对
G
t
G_{t}
Gt的定义为:
G
t
=
r
t
+
γ
V
π
(
s
′
)
G_t = r_t + \gamma V^\pi(s')
Gt=rt+γVπ(s′)
将其加入到MC中,就得到了下面这个公式。
V
π
(
s
t
)
=
V
π
(
s
t
)
+
α
(
[
r
t
+
γ
V
π
(
s
t
+
1
)
]
−
V
π
(
s
t
)
)
V^\pi(s_t) = V^\pi(s_t)+\alpha([r_t+\gamma V^\pi(s_{t+1})]-V^\pi(s_t))
Vπ(st)=Vπ(st)+α([rt+γVπ(st+1)]−Vπ(st))
相较于Every-Visit MC而言,TD不用计算
G
t
G_t
Gt,减轻了计算负担;同时,TD可以在过程中同步计算V,不必等到过程结束才开始计算,因此TD的计算速度会比Every-Visit MC快很多。此外,TD不必设置episode,即适用于连续性任务。有这么多优点,那有什么缺点吗?

计算速度快通常意味着精度低,TD毫不例外。TD并不具有无偏性,这从公式中就能看出。
δ
t
=
α
(
[
r
t
+
γ
V
π
(
s
t
+
1
)
]
−
V
π
(
s
t
)
)
\delta_t = \alpha([r_t+\gamma V^\pi(s_{t+1})]-V^\pi(s_t))
δt=α([rt+γVπ(st+1)]−Vπ(st))
注:代码就不展示了,和MC大差不差,偷个懒ing
总结
| \ | MC | TD |
|---|---|---|
| no models | Y | Y |
| 一致性 | frist Y but every N | Y |
| 无偏性 | Y | N |
















 676
676











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











