| 论文标题:Evolving from Single-modal to Multi-modal Facial Deepfake Detection: A Survey | | 发表时间:[v1] 2024 年 6 月 11 日星期二 05:48:04 UTC
[v2] 2024 年 7 月 14 日星期日 20:27:56 UTC
[v3] 2024 年 8 月 14 日星期三 15:38:49 UTC | | 作者单位:
- Ping Liu: 美国内华达大学里诺分校(University of Nevada, Reno),计算机科学与工程系。
联系方式:pino.pingliu@gmail.com - Qiqi Tao 和 Joey Tianyi Zhou: 新加坡科学技术研究局(Agency for Science, Technology and Research,A*STAR),高性能计算研究所(Institute of High Performance Computing,IHPC)以及前沿人工智能研究中心(Centre for Frontier AI Research,CFAR)。
同时,两人也隶属于新加坡的在线安全先进技术中心(Centre for Advanced Technologies in Online Safety,CATOS)。Joey Tianyi Zhou 是通讯作者。
联系方式: - Qiqi Tao: tao.qiqi@outlook.com
- Joey Tianyi Zhou: zhouty@cfar.a-star.edu.sg
| | https://arxiv.org/abs/2406.06965 |
Abstract 这篇综述文章探讨了在人工智能快速发展背景下面临的面部深度伪造(Deepfake)检测的关键挑战。随着人工智能生成的媒体(包括视频、音频和文本)变得更加逼真,利用这些技术传播错误信息或实施身份欺诈的风险不断增加。本文聚焦于与人脸相关的深度伪造,梳理了从传统单模态检测方法到应对音视频及文本-视觉场景的复杂多模态检测方法的演变过程。文章提供了全面的检测技术分类,回顾了生成方法从自编码器(Auto-Encoders, AEs)和生成对抗网络(GANs)到扩散模型(Diffusion Models)的发展,并根据它们的独特特性进行了技术分类。 这是首个专门针对从单模态到多模态面部伪造检测的综述。文章还探讨了适应新型生成模型的检测方法所面临的挑战,以及提升深度伪造检测器可靠性和鲁棒性的方向,并提出了未来的研究建议。该综述为研究人员提供了一个详细的研究路线图,支持针对AI在媒体创作中欺骗性使用(尤其是面部伪造)的对抗性技术的开发。 关键词包括:生成对抗网络(GANs)、扩散模型(Diffusion Models)、深度伪造(Deepfake)、面部伪造(Facial Forgery)、多模态(Multi-modality)。 INTRODUCTION 以下是论文《Evolving from Single-modal to Multi-modal Facial Deepfake Detection: A Survey》中INTRODUCTION部分的详细结构化解析:
1. 深度伪造技术的背景和重要性
-
- 深度伪造技术利用人工智能生成视频、音频和文本,创造高度逼真的虚拟内容。
- 主要技术包括:
-
-
- 变分自编码器(VAEs)
- 生成对抗网络(GANs)
- 扩散模型(DMs)
-
- 这些技术显著提升了伪造内容的真实性,使得深度伪造的检测变得更加困难。
-
- 面部深度伪造(Facial Deepfake)是深度伪造的重要分支,涉及面部交换、属性编辑和面部重现。
- 其潜在的积极用途:
-
-
- 个性化数字互动(如社交媒体)。
- 娱乐行业的创新(如虚拟演员、历史人物的数字化复现)。
2. 深度伪造生成技术的演变
-
- 从早期的简单生成方法(如GANs)到最新的扩散模型(DMs)。
- 生成技术的复杂性增加,使得伪造内容更加难以与真实内容区分。
- 模态范围扩展:
-
-
- 从单模态(如仅视频或仅音频)扩展到多模态(音视频结合,甚至包含文本)。
3. 深度伪造检测的挑战
-
- 检测难度增加: 随着生成技术的发展,伪造内容的真实性提升,使得人类和检测器都难以识别。
- 多模态的复杂性:
-
-
- 同时伪造视频、音频和文本的能力提升。
- 多模态伪造需要综合处理不同模态之间的特征联系和不一致性。
-
- 生成方法的快速迭代: 检测方法需要不断适应新型的生成技术(如扩散模型)。
-
- 从单一依赖被动检测伪造的内容,转向主动增强检测的可靠性和鲁棒性。
4. 本文的贡献
- 本文的独特价值在于全面综述了从单模态到多模态的深度伪造检测方法,填补了现有研究中的重要空白。
- 主要贡献:
-
- 提供最新技术的全面分类,涵盖从GAN到DM的生成方法及检测技术。
- 着重探讨多模态深度伪造的检测方法,这是面向真实世界场景的重要研究方向。
- 分析最新研究成果(截至2024年),尤其是对扩散模型和多模态伪造检测的讨论。
- 提出未来研究方向,包括适应新生成模型的检测方法和提高检测器鲁棒性。
5. 本文的结构
-
- 背景知识:介绍相关术语、数据集和评估指标。
- 深度伪造检测方法:从单模态到多模态,涵盖被动和主动检测方法。
- 当前挑战与未来方向:分析领域内的主要瓶颈及发展建议。
- 总结:总结关键发现与本文贡献。
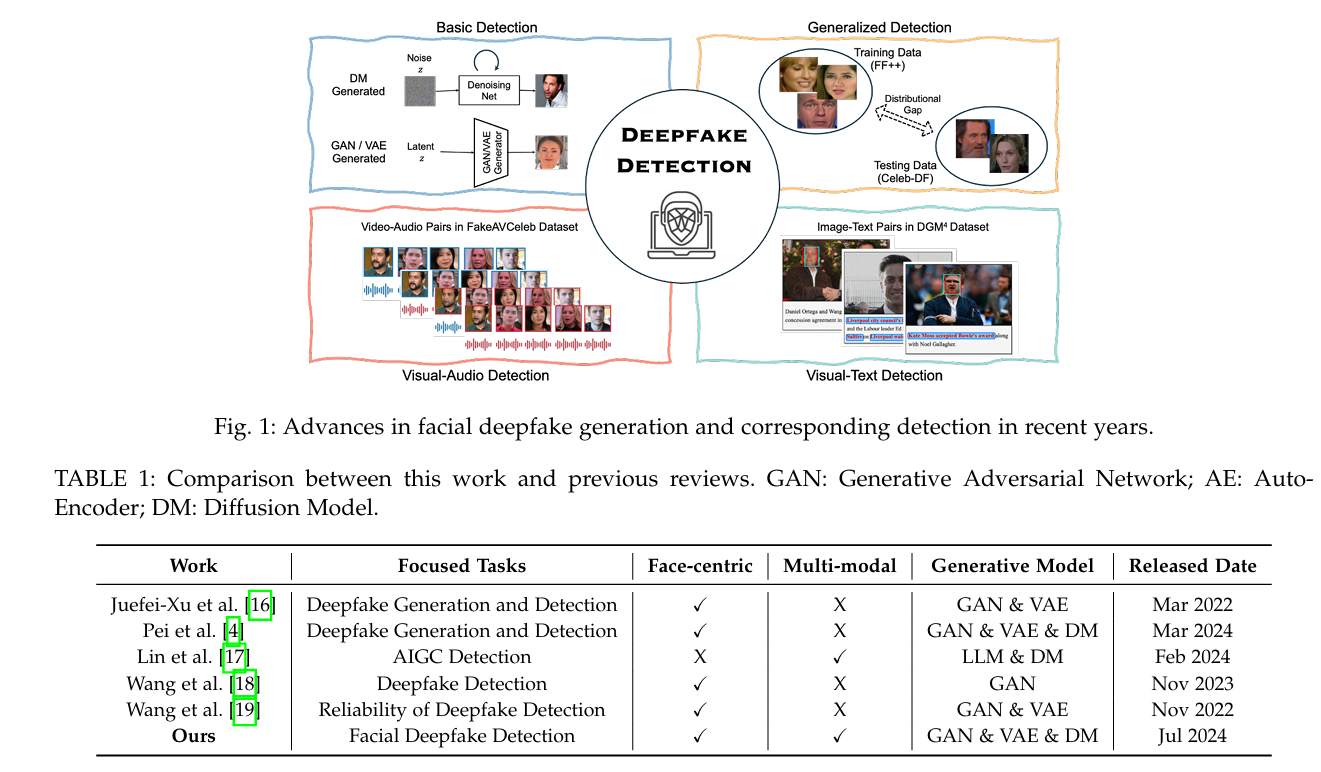
2 BACKGROUND
### **2.1 Task Formulation (任务形式化)**
#### **1. 单模态检测 (Single-modal Detection)** - **定义:**
- 针对单一模态(如视觉视频)的深度伪造检测。
- 数据集表示形式:
$ D = \{(X^v_i, Y_i)\}^N_{i=1} $
- $ X^v_i $:表示一个视频,其中 $ X^v_i \in \mathbb{R}^{T \times 3 \times H \times W} $,包含 $ T $ 帧,且每帧是一个 $ H \times W $ 的三通道图像。
- $ Y_i $:标签,指示视频是真实 (real) 还是伪造 (fake)。
- 检测器:
$ F_\theta: \mathbb{R}^{T \times 3 \times H \times W} \to \{real, fake\} $
- $ \theta $:检测器的参数,通过优化损失函数(例如交叉熵损失)来进行训练。 - **任务目标:**
- 优化检测器的参数 $ \theta $: $$
\theta = \arg\min_{\theta'} E_{D} \mathcal{L}(F_{\theta'}(X^v), Y)
$$ - 其中 $ \mathcal{L} $ 是损失函数,用于衡量检测器预测与真实标签的差距。 - **进一步细化任务:**
- **空间定位 (Spatial Localization):**
- 针对图像或视频,预测被操纵的区域的掩码 (mask)。
- **时间定位 (Temporal Localization):**
- 针对视频,输出一个时间掩码,标识被操纵的时间段。 --- #### **2. 多模态音视频检测 (Multi-modal Audio-Visual Detection)** - **定义:**
- 当输入是视频和音频流的组合时,同时检测这两种模态中的伪造内容。
- 数据集表示形式:
$ D = \{(X^v_i, X^a_i, Y_i)\}^N_{i=1} $
- $ X^v_i $:视频输入,与单模态检测的定义相同。
- $ X^a_i $:音频输入,其中 $ X^a_i \in \mathbb{R}^{M \times c} $,包含 $ c $ 个音频通道,每个通道有 $ M $ 个采样点。
- $ Y_i $:二分类标签,指示音视频组合的真实性。 - **检测器:**
- $ F_\theta: \mathbb{R}^{T \times 3 \times H \times W} \times \mathbb{R}^{M \times c} \to \{real, fake\} $
- 同时结合视频和音频的特征进行预测。 - **任务目标:**
- 优化检测器参数 $ \theta $: $$
\theta = \arg\min_{\theta'} E_{D} \mathcal{L}(F_{\theta'}(X^v, X^a), Y)
$$ - **细化任务:**
- **模态级分类:**
- 针对每个模态,分别预测真实性:
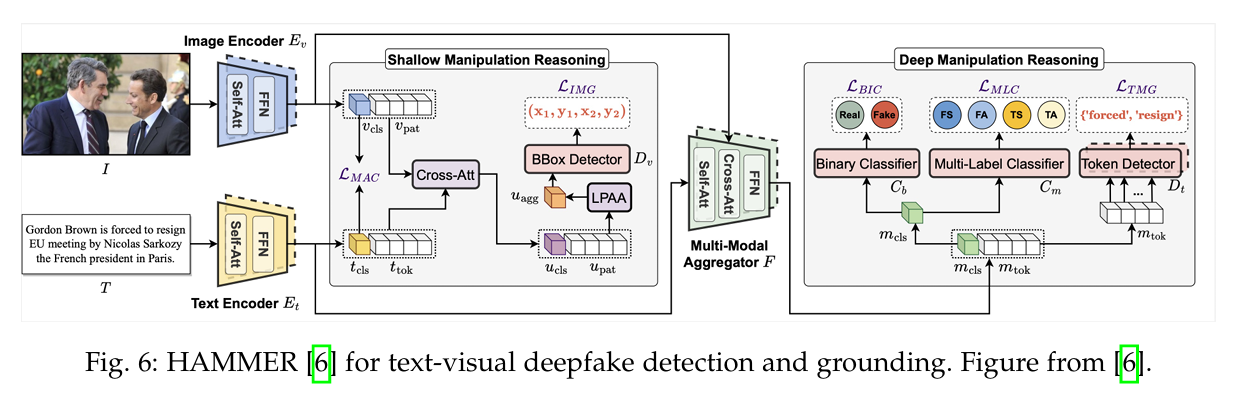
$ F_\theta \to (Y^v, Y^a) $,其中 $ Y^v $ 是视频的真实性,$ Y^a $ 是音频的真实性。 --- #### **3. 多模态文本-视觉检测 (Multi-modal Text-Visual Detection and Grounding)** - **定义:**
- 分析图像和文本对的真实性,特别是文本内容是否与图像内容一致。
- 数据集表示形式:
$ D = \{(X^v_i, X^t_i, Y^v_i, Y^t_i, B^v_i, M^t_i, Y_i)\}^N_{i=1} $
- $ X^v_i $:图像输入,$ X^v_i \in \mathbb{R}^{3 \times H \times W} $。
- $ X^t_i $:文本输入,包含 $ L $ 个标记 (tokens),每个标记的维度为 $ d $,即 $ X^t_i \in \mathbb{R}^{L \times d} $。
- $ Y^v_i $:图像模态的真实性标签。
- $ Y^t_i $:文本模态的真实性标签。
- $ B^v_i $:操纵区域的边界框(bounding box)。
- $ M^t_i $:文本模态的操纵掩码。
- $ Y_i $:整体真实性标签。 - **检测器:**
- $ F_\theta(X^v, X^t) \to (Y^v, Y^t, B^v, M^t, Y) $
- 检测器需要同时预测图像真实性、文本真实性、操纵区域,以及整体配对真实性。 - **任务目标:**
- 优化检测器参数 $ \theta $:
$$
\theta = \arg\min_{\theta'} E_{D} \mathcal{L}(F_{\theta'}(X^v, X^t), Y, Y^v, Y^t, B^v, M^t)
$$ --- ### **总结**
本部分明确界定了三类主要的深度伪造检测任务:
1. **单模态检测**专注于视频内容的真实性分析。
2. **音视频多模态检测**要求综合视频和音频的特征。
3. **文本-视觉多模态检测**进一步增加了文本和图像之间关联性的分析。
以下是论文《Evolving from Single-modal to Multi-modal Facial Deepfake Detection: A Survey》中2.2 Datasets for Facial Forgery Detection部分的详细解析:
2.2 Datasets for Facial Forgery Detection (面部伪造检测数据集) 在深度伪造检测的研究中,数据集的构建和评估方法是至关重要的。数据集的设计不仅决定了检测算法的表现,还对训练深度伪造检测模型的有效性至关重要。面部伪造检测数据集可大致分为单模态和多模态数据集,以下分别介绍这两类数据集。 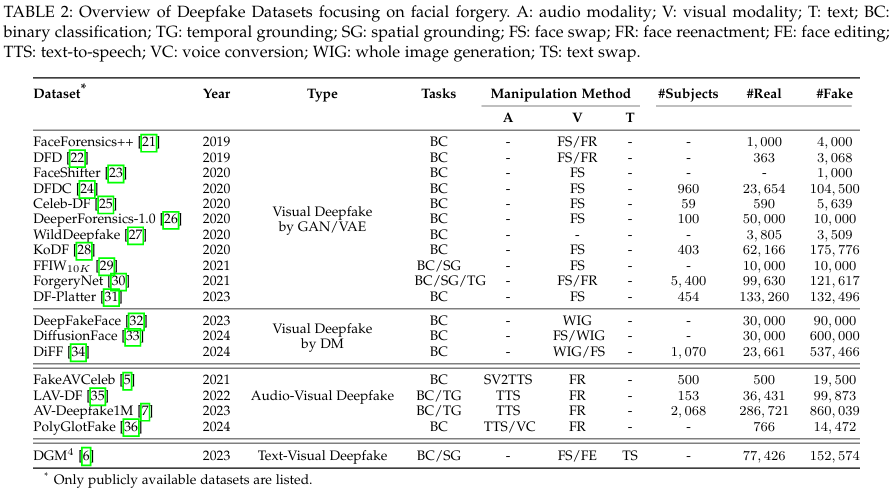
1. 单模态(视觉)深度伪造数据集 (Single-modal (Visual) Deepfake Datasets) 单模态数据集专注于基于单一类型的数据(如视觉信息)进行深度伪造检测。最初,计算机图形技术被广泛应用于深度伪造数据集的构建,但随着生成式AI技术的进步,使用生成对抗网络(GAN)、**变分自编码器(VAE)和扩散模型(DM)**等方法来生成伪造数据的技术逐渐成为主流。
-
- FaceForensics++ (FF++)(2019):该数据集是深度伪造检测领域的基准之一,涵盖了多种伪造技术(如人脸交换、面部重现等)。它使用GAN和VAE技术生成多种不同类型的伪造面部图像。
- DeepFake Detection Challenge (DFDC)(2019):该数据集包含了来自不同伪造技术的视频,尤其关注GAN生成的伪造内容,是挑战检测算法的标准数据集之一。
- Celeb-DF(2020):利用VAE生成伪造图像,通过复制面部表情进行人脸交换,提升了面部伪造的视觉真实性。
- DeeperForensics-1.0(2020):采用VAE框架进行面部交换,生成大量伪造视频样本,帮助检测算法应对不同伪造技巧的挑战。
- WildDeepfake(2020):该数据集聚焦于从互联网中收集真实世界的伪造样本,提供了更加复杂的检测场景。
- KoDF (Korean Deep-Fake Detection Dataset)(2020):此数据集特别关注亚洲人群中的伪造样本,解决了前期数据集中对亚洲面孔的代表性不足问题。
-
- 提供了各种面部伪造技术的广泛样本,覆盖了诸如面部交换、面部重现、面部编辑等多种伪造方法。
- 包含了高质量和高分辨率的视频和图像,可以测试不同伪造技术的检测能力。
2. 基于扩散模型(Diffusion Models)生成的伪造数据集 (DMs-based Generated Datasets) 扩散模型的出现显著提高了伪造内容的质量,这使得基于扩散模型生成的数据集成为深度伪造检测中的重要组成部分。扩散模型能够生成更加细致且自然的伪造内容,甚至能够模仿面部的细节和表情。
- DeepFakeFace(2023):利用稳定扩散模型(Stable Diffusion)、稳定扩散内插(Stable Diffusion Inpainting)等方法生成大规模伪造图像,旨在为深度伪造检测提供新的挑战。
- DiffusionFace(2024):这是第一个专注于扩散模型生成面部伪造的数据集,涵盖了从无条件生成到更复杂的面部交换技术。该数据集利用了多达11种不同的扩散模型,显著提升了伪造图像的质量。
- DiFF(2024):该数据集包含超过500,000张图像,由13种生成方法生成,涵盖了大量的面部伪造技巧,为检测算法提供了多样化的训练和测试数据。
- 扩散模型数据集的优势:
-
- 生成的伪造内容非常真实,能够在面部细节、表情等方面迷惑检测器。
- 覆盖多种生成方法,为研究人员提供了丰富的伪造样本,推动了检测技术的进步。
3. 多模态深度伪造数据集 (Multi-modal Deepfake Datasets) 多模态数据集集成了多种模态的数据,如图像、音频和文本,以便模拟更复杂的伪造情况。随着技术的发展,伪造不仅限于视觉内容,还扩展到了音频和文本领域,尤其是在视频伪造中,音视频的伪造和文本与图像的伪造成为常见的挑战。
-
- FakeAVCeleb(2021):这是一个音视频伪造数据集,主要包含伪造的视频和同步生成的虚假音频,尤其适用于音视频伪造的检测。
- LAV-DF(2022):此数据集专注于音视频的伪造检测,涵盖文本到语音(TTS)转换、语音转换(VC)等伪造方法。
- AV-Deepfake1M(2023):该数据集包含百万级的音视频伪造样本,适合大规模深度伪造检测任务。
-
- DGM4(2024):该数据集聚焦于图像和文本对的伪造内容,任务不仅包括二分类检测,还包括标记图像和文本中的伪造区域,增强了检测任务的复杂性。
-
- 真实世界中,伪造内容往往是多模态的,例如伪造视频中可能包括伪造的音频或与图像不一致的文本。
- 提供了更复杂、更符合实际应用的伪造样本,能够训练更强大的检测模型。
4. 数据集的挑战与发展方向
- 数据集多样性: 当前数据集主要集中在视觉伪造上,但随着伪造技术的发展,音频、文本和视频结合的多模态伪造将成为未来的重点。因此,开发多模态的数据集将是未来研究的重要方向。
- 扩展到真实场景: 当前数据集大多来自特定场景或技术生成,而真实世界中的伪造内容可能受到压缩、后处理等操作的影响。因此,跨数据集、跨操作的检测评估将是挑战。
2.3 Evaluation (评估) 在深度伪造检测的研究中,评估是至关重要的,它不仅衡量了检测模型的性能,还为方法的改进提供了方向。评估指标通常包括准确率、召回率等传统分类指标,但由于深度伪造的检测任务具有高度的复杂性,尤其是在多模态环境下,评估的方式和标准也更加多样化。 1. 评估指标 (Evaluation Metrics)
- 二分类任务的评估指标: 在传统的深度伪造检测任务中,通常将其视为一个二分类问题。常见的评估指标包括:
-
- 准确率(ACC, Accuracy):检测模型预测正确的比例。适用于评估模型在标准数据集上的整体表现。
- AUC(Area Under Curve):ROC曲线下的面积,用于衡量模型在不同阈值下的分类性能,尤其适用于处理不平衡数据集。
- F1-Score:综合考虑精确率(Precision)和召回率(Recall)的指标,尤其在数据不平衡时,比准确率更能反映检测效果。
- 平均精度(AP, Average Precision):在多个分类阈值下,计算精度-召回率曲线的平均精度,广泛用于物体检测和伪造检测等任务。
- EER(Equal Error Rate):假正率(FPR)和假负率(FNR)相等时的错误率,用于评估模型在检测伪造内容的平衡能力。
- 多模态任务的评估指标: 当深度伪造检测任务扩展到多模态情境(例如,音频与视频、文本与图像的结合),除了传统的二分类指标外,还需要使用更细致的评估标准:
-
- mAP(mean Average Precision):该指标用于多标签任务,尤其是在多模态检测中,评估模型在多个类别上同时进行预测的效果。
- mIoU(mean Intersection over Union):用于评估目标区域的精确匹配度,特别是在检测伪造区域(如图像中的面部伪造)时。
- IoU50, IoU75:分别代表50%和75%的交并比,表示预测区域与真实区域之间的重叠度。IoU用于物体检测任务,尤其是在空间定位任务中。
- 文本模态评估: 对于文本模态的深度伪造检测,主要使用分类精度、召回率等标准,此外,针对每个文本标记的真实性的预测,评估标准也会包括分类的精度和召回率。
2. 评估设置 (Evaluation Settings) 在进行深度伪造检测时,通常会按照数据集的分布差异进行两类主要的评估设置:内域评估和跨域评估。
- 内域评估 (In-domain Evaluation):
-
- 内域评估指的是在训练和测试使用相同的数据集时进行的评估,即训练数据和测试数据来自相同的数据分布,通常是非重叠的数据。
- 这种设置下,评估的目的是测试模型在“理想环境”下的表现,评估模型在已知伪造方法上的有效性。
- 例如,使用FF++数据集训练,在DFDC上测试。
- 跨域评估 (Cross-domain Evaluation):
-
- 跨域评估指的是训练数据和测试数据来自不同的数据分布,测试模型在未知伪造方法或新型伪造样本上的泛化能力。
- 跨域评估有三种主要类型:
-
-
- 跨数据集评估(Cross-dataset Evaluation):训练和测试数据来自不同的数据集,测试模型的泛化能力。
- 跨伪造方法评估(Cross-manipulation Evaluation):训练和测试使用同一数据集,但伪造方法不同。例如,在FF++数据集上,训练使用FaceSwap,测试使用NeuralTextures。
- 跨后处理评估(Cross-postprocessing Evaluation):评估模型在深度伪造内容经过后处理(如视频压缩、JPEG压缩等)后的表现,模拟伪造内容在实际传播中的可能变化。
3. 评估挑战
- 真实世界的复杂性: 现实中的伪造内容往往经过压缩、剪辑、后处理等多种变换,因此,评估检测模型不仅要考虑原始高质量数据,还要考虑检测模型在低质量、压缩或改变格式后的表现。
- 跨模态伪造: 随着深度伪造技术的发展,单一模态的伪造检测已无法应对复杂的多模态伪造(如音视频伪造、文本-图像伪造)。因此,评估多模态检测能力成为新的挑战,如何有效整合来自不同模态的信息,并在多个模态之间建立关联,是评估的一大难点。
- 数据集的多样性: 数据集的多样性对评估至关重要。不同的数据集往往聚焦于不同的伪造方法或应用场景,因此在评估时,需要确保测试数据的多样性和代表性,以更好地模拟真实世界的伪造情况。
以下是论文《Evolving from Single-modal to Multi-modal Facial Deepfake Detection: A Survey》中2.4 History and Challenges of Deepfake Datasets部分的详细解析:
2.4 History and Challenges of Deepfake Datasets (深度伪造数据集的历史与挑战) 在深度伪造检测领域,数据集的历史发展和挑战性问题是推动检测技术进步的关键。随着生成技术的不断演化,数据集的设计、使用和评估也在不断变化,并面临新的挑战。以下是该部分的详细讨论。 1. 深度伪造生成方法的演变 深度伪造技术的发展经历了多个阶段,尤其是在生成模型的技术演进方面,深度伪造数据集的设计和内容也在不断变化。
-
- **GAN(生成对抗网络)和VAE(变分自编码器)**是最早期的深度伪造生成方法。它们通过生成器和判别器的对抗训练生成伪造的面部图像或视频。
- 这些方法在早期的伪造检测数据集中占主导地位,尤其是在生成面部交换和面部重现等伪造样本时。
-
- 随着技术的进步,生成方法变得更加复杂,特别是**扩散模型(DMs)**的出现,它们在生成伪造内容时达到了前所未有的真实性,尤其在面部伪造图像的细节和连贯性方面。
- 扩散模型的引入使得生成的伪造内容更加自然且难以与真实内容区分,因此,新的数据集需要能够应对这种新的生成技术。
2. 数据集的演变 随着生成技术的不断进步,深度伪造检测数据集也经历了不断演化的过程,从最初的单一模态数据集到如今的多模态数据集。
-
- 早期的数据集主要专注于视觉数据,尤其是面部图像和视频。这些数据集主要由GAN和VAE生成伪造样本,用于训练和评估单模态的深度伪造检测方法。
- 例如,FaceForensics++和DFDC数据集都主要关注视觉伪造,且其生成的伪造样本相对容易被早期的检测方法识别。
-
- 随着深度伪造技术向多模态伪造(如音频-视频和文本-图像结合)转变,新的多模态数据集应运而生。这些数据集不仅包括视频和图像伪造,还涵盖了音频和文本的伪造,模拟了现实世界中伪造内容可能存在的组合。
- 例如,FakeAVCeleb和DGM4数据集就包括了音频与视频、图像与文本的多模态伪造内容,它们为多模态深度伪造检测提供了训练和评估的基础。
-
- 早期的数据集大多基于少数几种伪造生成技术,而现代数据集则需要涵盖更多的生成技术,包括GAN、VAE、以及扩散模型等。这要求检测方法必须能够处理来自不同生成方法的数据。
3. 数据集面临的挑战 随着深度伪造技术和数据集的演变,深度伪造检测面临着一系列新的挑战。以下是当前面临的主要挑战:
-
- 随着生成方法的多样化,特别是扩散模型和其他新兴技术的应用,现有的数据集需要能够涵盖这些新技术生成的伪造内容。新的数据集需要在面对不同生成方法时具有更强的适应性。
-
- 真实世界中的伪造内容通常不是单一模态的,而是音频、视频和文本的组合。例如,一个伪造的视频可能伴随着伪造的音频或误导性的文本。因此,数据集需要能够涵盖多模态伪造,支持跨模态检测任务。
- 目前,多模态伪造的数据集还处于相对早期的阶段,尚未完全满足现实世界中复杂伪造检测的需求。
-
- 跨数据集评估、跨伪造方法评估和跨后处理评估是当前深度伪造检测中的重要挑战。数据集中的伪造样本通常来自于不同的伪造技术和生成方法,这就要求检测方法具备较强的泛化能力。
- 例如,一些检测算法可能只在特定伪造方法或数据集上表现良好,而在不同伪造方法或者经过压缩后的数据上,检测效果可能大打折扣。因此,跨域评估变得越来越重要。
-
- 许多现有的数据集虽然提供了大量的伪造样本,但这些样本往往来自于特定的生成方法或操作环境。现实中,伪造内容可能会经过压缩、剪辑、后处理等操作,这些因素尚未在大多数现有数据集中得到充分体现。
- 为了应对这一挑战,研究人员需要开发更加多样化的数据集,模拟伪造内容在实际传播过程中的各种变化。
4. 未来方向
-
- 为了应对多模态伪造检测的挑战,未来需要构建更加完善和多样化的多模态数据集。这些数据集不仅要涵盖不同生成方法,还要考虑现实世界中伪造内容的多样性和复杂性。
-
- 检测方法需要增强跨域泛化能力,能够适应不同伪造方法和数据集之间的差异。为此,跨数据集、跨伪造方法的评估变得尤为重要。
-
- 数据集的多样性和代表性将成为未来研究的重点。尤其是需要更好地代表现实世界中的伪造情况,包括各种后处理、压缩和低质量伪造内容的挑战。
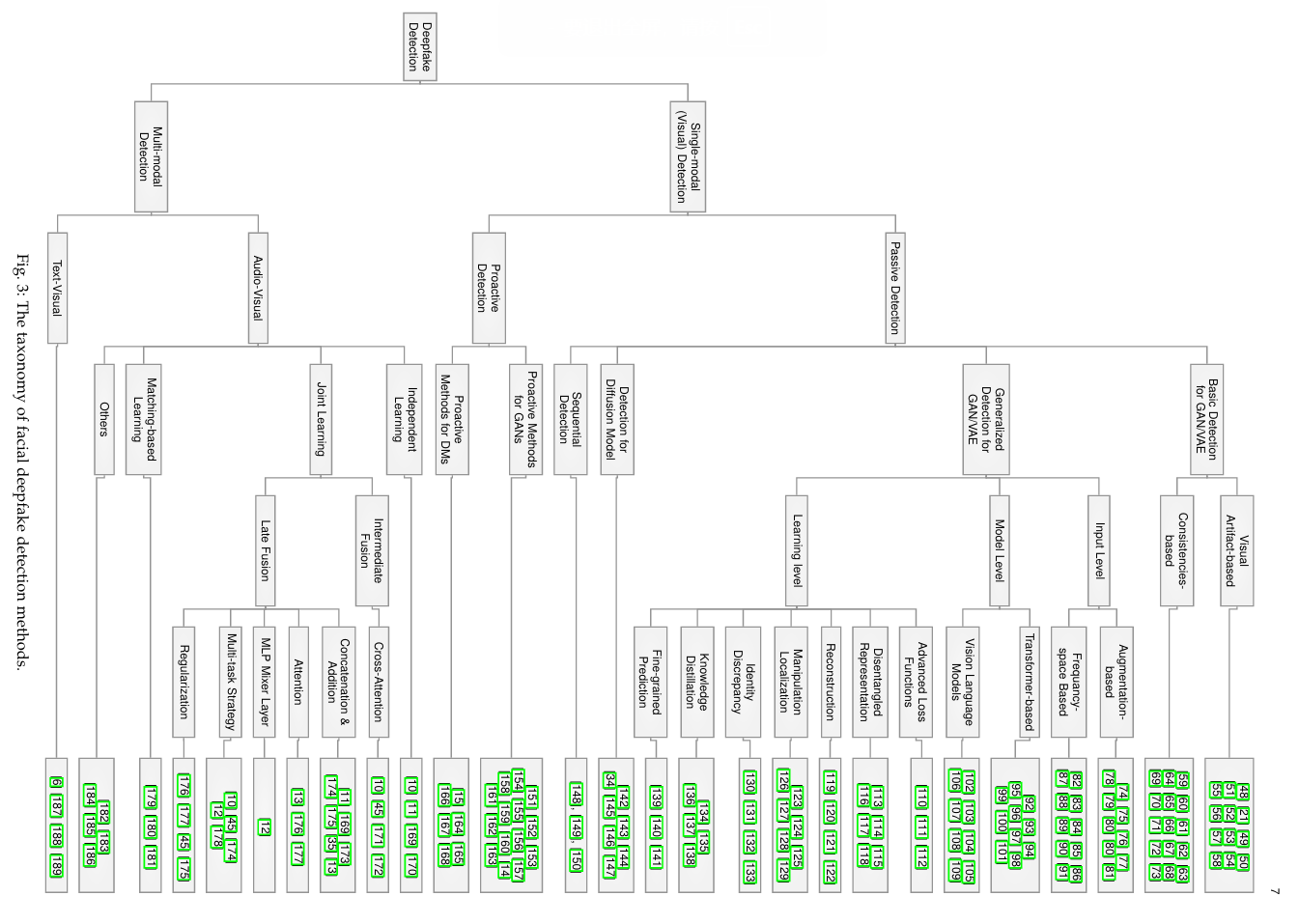
3 METHOD (方法) 本文对面部深度伪造检测方法进行了详细综述,主要分为以下几个领域:
- 单模态检测方法(Single-modal Detection Methods)
-
- 包括基于视觉的伪造检测方法。
- 方法进一步划分为被动检测和主动检测。
- 多模态检测方法(Multi-modal Detection Methods)
- 跨领域的未来方向
-
- 探讨了如何结合多种检测策略,提高检测的鲁棒性和泛化能力。
以下逐部分详细展开。 
3.1 单模态检测方法 (Single-modal Detection Methods) 3.1.1 被动检测方法 (Passive Detection Methods) 被动检测方法指的是通过分析现有数据中的伪造痕迹,提取伪造特征以识别伪造内容。这种方法无需在生成内容时主动干预,完全基于内容本身的特性来检测伪造。 (1) 基础检测方法(Basic Detection Methods for GAN/VAE-based Fakes) 基础检测方法主要针对GAN和VAE生成的伪造内容。这些方法通过发现生成内容中的伪造痕迹(artifacts),如像素级、纹理或频率特征的不一致性,来进行检测。
- 基于视觉伪造特征的方法(Visual Artifact-based Methods):
-
-
- Afchar等提出的MesoNet模型通过分析图像的中尺度特征,检测GAN生成的伪造痕迹。
- Rossler等利用XceptionNet框架捕捉细微的伪造纹理特征,识别面部伪造。
-
-
- Liu等提出Gram-Net,利用全局图像纹理特征检测GAN生成图像中的伪造区域。
- Zhao等提出了多注意力机制框架,专注于深度伪造的纹理特征,提高检测的准确性。
- 基于一致性的方法(Consistency-based Methods):
-
-
- Li等研究了视频中的眨眼频率不一致问题,利用时序一致性检测伪造内容。
- Qi等提出了基于心率节律(DeepRhythm)的伪造检测方法。
-
-
- Haliassos等设计了一个时空网络,用于检测伪造视频中嘴唇运动的语义不一致性。
-
-
- Wang等研究了伪造样本中面部区域与背景噪声之间的不一致性。
(2) 广义检测方法(Generalized Detection Methods for GAN/VAE-based Fakes) 为了应对新型伪造生成技术的挑战,广义检测方法专注于提升模型的泛化能力。
- 输入级增强方法(Input-level Augmentation-based Methods):
-
-
- Wang等提出了一种基于注意力的伪造样本生成方法,通过增强伪造特征训练模型。
-
-
- Luo等提出了一种专注于高频信息的伪造增强方法,用以提高检测能力。
- 模型级增强方法(Model-level Approaches):
-
-
- Bai等引入了“动作单元关系Transformer”(Action Units Relation Transformer),通过捕获面部动作单元之间的关系,检测伪造内容。
-
-
- Lai等提出了通用多场景深度伪造检测框架(GM-DF),利用视觉-文本对齐特性提高模型的泛化能力。
Model level: Vision-Language Models (视觉-语言模型)部分的详细拆解和讲解。
背景:Vision-Language Models 的崛起 Vision-Language Models (VLMs) 是近年来在深度学习领域迅速发展的技术,主要用于处理图像和文本的跨模态任务。它们通过联合训练视觉和语言特征,使得模型能够理解和关联图像与文本内容。例如,OpenAI 的 CLIP (Contrastive Language-Image Pretraining) 模型是一个典型的 VLM,它将图像和文本映射到一个共享的特征空间,从而实现对两种模态的有效融合。 在深度伪造检测中,VLMs 的能力被用于以下两个核心任务:
- 通用检测(Universal Detection): 利用 VLMs 强大的跨模态表示能力,检测伪造内容。
- 推理与解释(Reasoning and Explainability): 提升伪造检测模型的可解释性和推理能力。
1. 通用检测 (Universal Detection) 通用检测的目标是利用 VLMs 的通用表示能力,对各种模态的伪造内容进行检测,而无需对每种伪造技术单独优化。 核心方法与框架
- CLIP-based Models:
-
-
- CLIP 是一个联合训练图像和文本的模型,它将图像特征和文本特征映射到一个共享的特征空间中。研究者利用 CLIP 的强大能力来进行深度伪造检测。
-
-
- Han 等提出了一种基于 CLIP 的检测框架,该框架使用 CLIP 的图像编码器来提取图像特征,同时引入了一个自定义的解码器来检测视频中的时序伪造特征。
- 通过为 CLIP 提供设计好的伪造相关文本标签(如“真实图像”和“伪造图像”),可以显著提高检测精度。
- 多场景检测 (Generalized Multi-Scenario Detection):
-
- Lai 等提出了**GM-DF (Generalized Multi-Scenario Deepfake Detection)**框架,该框架利用 CLIP 的特性对多种伪造内容进行检测。
- 关键技术:
-
-
- 视觉-文本对齐: 通过 CLIP 学习图像与文本之间的语义一致性。
- 领域专家建模 (Domain Expert Modeling): 针对不同伪造类型(如GAN、扩散模型)训练领域特定的检测模块。
- 图像掩码重建机制: 用于捕获图像的局部伪造区域,从而提升细粒度检测能力。
优点:
- CLIP 的预训练知识可以在多种伪造任务中复用,减少对大量伪造数据的依赖。
- 模型具有较强的跨模态和跨领域泛化能力,能够适应不同的伪造场景。
局限性:
- CLIP 的性能受限于其预训练语料,可能对一些新型伪造方法的检测能力不足。
- 在处理多模态数据时,特征对齐的复杂性增加。
2. 推理与解释 (Reasoning and Explainability) Vision-Language Models 不仅能进行伪造检测,还能通过跨模态推理和解释来增强检测的透明性和可信度。 核心方法与框架
- 解释性评估 (Explainability Evaluation Framework):
-
- Tsigos 等提出了一种框架,用于评估 VLM 模型在深度伪造检测任务中的解释性。
- 方法描述:
-
-
- 通过对输入图像的关键区域进行修改(例如遮挡、噪声注入),观察模型预测的变化。
- 测试模型是否能够正确解释哪些图像区域对伪造检测最为重要。
- 视觉-语言推理 (Visual-Linguistic Reasoning):
-
- Sun 等提出了**VLFFD (Visual-Linguistic Face Forgery Detection)**框架,使用 CLIP 进行面部伪造检测,同时结合视觉-语言知识提供伪造区域的详细解释。
- 技术细节:
-
-
- Coarse-and-Fine Co-training(粗粒度与细粒度联合训练):
-
-
-
- 通过训练模型在全局(粗粒度)识别伪造内容,同时在局部(细粒度)定位伪造区域。
-
-
- 文本标签扩展: 增强训练过程中图像-文本的语义匹配,例如“这是一张被伪造的面部图像”这样的文本标签。
- 多模态大语言模型 (Multimodal Large Language Models, MLLMs):
-
- 最近,MLLM 被用于伪造检测任务中,例如 ChatGPT 与 CLIP 结合的模型。
- SHIELD 基准测试:
-
-
- 引入了一个新的基准测试 SHIELD,评估多模态模型在面部伪造检测任务中的表现。
- SHIELD 测试了 MLLM 的多模态推理能力和可解释性,发现其在多模态伪造检测中表现出色。
-
-
- MLLM 的性能很大程度上依赖于提示工程(Prompt Engineering)。
- 合理的提示设计能够显著提升伪造检测的准确性和解释能力。
- 视觉问答任务 (Visual Question Answering, VQA):
-
- Zhang 等将深度伪造检测问题重新定义为视觉问答任务,模型不仅需要判断图像的真实性,还需要生成对伪造内容的解释。
- 技术实现:
-
-
- 设计一个基于视觉-语言 Transformer 的框架。
- 通过文本提示(如“这张图片是否被伪造?”)指导模型生成伪造检测的解释。
优点:
- 推理与解释能力能够提升检测结果的可信度,有助于模型的实际部署和用户理解。
- 多模态能力为伪造检测的进一步扩展(如音频-视频、图像-文本的综合检测)提供了可能。
局限性:
- 推理任务对计算资源要求较高,特别是在处理大规模多模态数据时。
- 生成的解释可能缺乏深度,难以完全满足实际应用中的需求。
3. VLM 在深度伪造检测中的应用与挑战
- 应用:
-
- 跨模态伪造检测: 检测图像和文本组合中的伪造内容(例如,图像与说明文本是否一致)。
- 新型伪造方法适配: 借助预训练模型适应不同的伪造技术。
- 检测结果的可解释性: 提供伪造内容的推理依据和区域定位。
- 挑战:
-
- 模型适配性: 当前的 VLMs(如 CLIP)可能未针对伪造检测进行专门优化,需要更多的领域特定微调。
- 数据依赖性: 多模态检测任务需要高质量的跨模态标注数据,但获取这样的数据成本较高。
- 推理复杂性: 多模态推理增加了系统复杂性,尤其在实时检测场景中性能可能受到限制。
总结 Vision-Language Models 的引入为深度伪造检测开辟了新的方向。通过通用检测和推理解释能力,VLMs 能够增强伪造检测的准确性和透明性。然而,它们也面临着性能优化和实际应用中的挑战。未来,随着更多多模态预训练模型的出现,VLMs 在深度伪造检测中的作用将更加重要。 如果需要更深入的具体技术实现细节,或相关代码/算法的拆解分析,请告诉我!
- 学习级增强方法(Learning-level Approaches):
-
-
- Yin等提出通过在角度和欧几里得空间中引入额外的边界惩罚,增强特征分离能力。
-
-
- Liang等提出通过多任务学习将内容特征与伪造特征解耦,从而提升模型的泛化能力。
(3) 针对扩散模型的检测方法(Detection for Diffusion Model-based Fakes) 扩散模型生成的伪造内容更加逼真,因此检测方法需要更加精细化:
- Ricker等研究了GAN检测方法在扩散模型中的适用性,并提出重新训练GAN检测器以适应扩散模型。
- Cheng等提出了基于边缘图的正则化方法,通过捕捉细微边缘特征提高检测性能。
(4) 序列化伪造检测(Sequential Detection Methods) 面对多步骤操纵的深度伪造,研究者提出了序列化检测方法:
- Shao等提出了SeqFakeFormer,用于识别序列伪造的顺序和对应的操纵区域。
3.1.2 主动检测方法 (Proactive Detection Methods) 主动检测方法通过在内容创建阶段加入可追踪的信号(如对抗扰动或水印)来增强检测的鲁棒性。 (1) 针对GAN的主动方法:
-
- Huang等通过设计对抗扰动,在GAN生成过程中破坏伪造内容的真实性。
-
- Yu等提出了通过嵌入生成器参数指纹的方式,使伪造内容能够被追溯到其生成源。
(2) 针对扩散模型的主动方法:
-
- Cui等提出DiffusionShield,将水印嵌入到扩散模型生成的内容中,提高其检测和追踪能力。
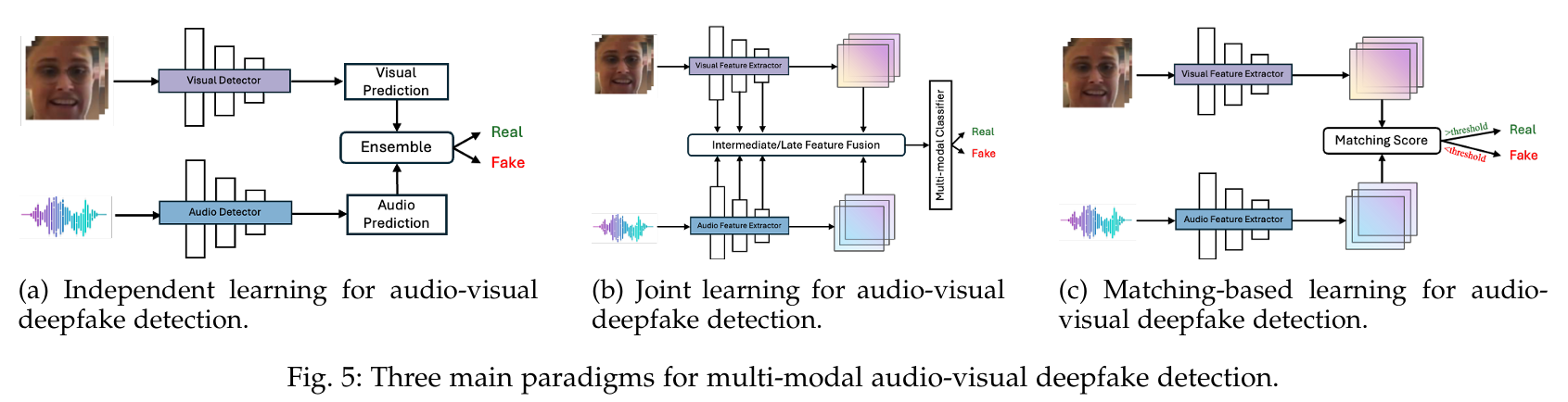
3.2 多模态检测方法 (Multi-modal Detection Methods) 多模态检测方法旨在同时检测多个模态(如音频与视频)的伪造。 (1) 音视频伪造检测:
- 独立学习(Independent Learning):
-
- 通过跨模态融合(如注意力机制)增强音视频特征的整合。
- 匹配学习(Matching-based Learning):
(2) 文本-图像伪造检测:
-
- 通过分析文本描述与图像内容之间的语义一致性,识别伪造内容。
以下是论文中 4 CHALLENGES AND FUTURE DIRECTIONS (挑战与未来方向) 部分的详细解析。这部分对当前深度伪造检测领域面临的主要挑战进行了深入探讨,同时提出了未来发展的潜在方向。
4.1 当前面临的挑战 (Challenges) 深度伪造技术和检测技术的发展是相互促进的,但这也导致检测技术面临以下几大挑战: 1. 生成技术的快速演化
-
- 新型生成技术(如扩散模型 Diffusion Models)使伪造内容的质量显著提高,难以与真实内容区分。
- 扩散模型生成的伪造样本在细节、纹理和整体一致性方面已经接近人类感知的极限。
-
- 扩散模型能够生成极其逼真的静态图像,甚至可以通过视频建模生成高质量的动态伪造内容。
-
- 检测器需要不断适应这些新兴技术,而现有检测方法可能无法泛化到未见过的新型生成方法。
2. 多模态伪造的复杂性
-
- 深度伪造已经从单模态(如仅视频伪造)扩展到多模态(如音频-视频结合、文本-视觉结合等)场景。
- 多模态伪造内容通过整合多个模态,进一步增强伪造的欺骗性。
-
- 在视频中伪造面部动作,同时生成与之同步的伪造语音内容,甚至伴随误导性的文本描述。
-
- 现有方法很难同时处理多种模态之间的交互与不一致性,需要设计能够充分利用跨模态特征的方法。
3. 数据集的不足
-
-
- 生成方法单一: 大部分数据集主要依赖 GAN 和 VAE,缺乏基于扩散模型生成的伪造样本。
- 多模态覆盖不足: 许多数据集仅关注单模态内容(如视频),而忽视了多模态伪造的挑战。
- 真实场景模拟欠缺: 数据集中样本的分辨率通常较高,而现实中许多伪造内容经过压缩或后处理后会变得低质量。
-
- 检测器在训练时容易过拟合于特定的数据集和伪造方法,缺乏应对真实场景的泛化能力。
4. 检测器的鲁棒性
-
- 伪造内容在传播中常常会经过视频压缩、图像模糊或分辨率降低等后处理操作,这些操作会削弱伪造特征,从而降低检测器的准确性。
-
- 高压缩的视频可能掩盖伪造区域的细节,使得检测器难以提取相关伪造特征。
-
- 检测模型需要对各种后处理操作具有鲁棒性,能够在多种环境中保持稳定的检测性能。
5. 可解释性与公平性
-
- 检测模型的预测结果往往缺乏解释性(Why it’s fake?),用户难以信任检测结果。
- 数据集和检测器可能存在偏差,例如对某些性别、种族或特定特征的样本检测效果较差。
-
- 某些模型在亚裔面孔伪造的检测上表现较差,可能是由于训练数据中该类别样本不足。
-
- 检测器不仅需要准确检测伪造,还需提供伪造区域和特征的解释,同时保证不同群体的公平性。
4.2 未来方向 (Future Directions) 为了克服上述挑战,论文提出了以下潜在的发展方向: 1. 应对新型生成技术
-
- 开发能够适应新型生成方法(如扩散模型)的检测方法,提升模型的泛化能力。
-
- 利用生成模型的内部特性(如扩散过程中的中间状态)来设计检测方法。
- 例如,基于重构误差的检测器能够通过分析扩散模型生成的还原细节来捕获伪造痕迹。
2. 多模态伪造检测
-
- 构建针对多模态伪造内容的统一检测框架,同时综合利用音频、视频和文本模态的特征。
-
- 设计多模态融合模块(如基于注意力机制的跨模态特征融合)以提高检测效果。
- 利用大型多模态模型(如 CLIP 或 Vision-Language Transformers)来处理复杂的多模态伪造任务。
3. 数据集的改进
-
- 构建多样化、高质量的深度伪造检测数据集,以覆盖更多伪造方法和场景。
-
- 引入基于扩散模型生成的伪造样本,同时涵盖更多后处理操作(如压缩、降噪)。
- 开发多模态数据集,例如音视频伪造数据集、文本-图像伪造数据集。
4. 提升检测模型的鲁棒性
-
- 设计对后处理操作(如压缩、模糊、分辨率变化)具有鲁棒性的检测方法。
-
- 利用频域特征检测压缩伪造内容中的伪造痕迹。
- 通过对抗训练增强模型对各种后处理操作的适应能力。
5. 提高检测的可解释性与公平性
-
- 开发可解释性更强的检测模型,同时保证不同种族、性别的检测公平性。
-
- 引入解释性模块(如基于注意力的可视化工具)来标记伪造区域并解释预测依据。
- 在训练数据中加入更多样化的样本,减少数据偏差,提升模型的公平性。
6. 主动检测方法
-
- 开发主动检测机制,通过在内容中嵌入可追踪信号(如水印、对抗扰动)来阻止伪造行为。
-
- 设计通用对抗扰动生成器,以破坏伪造模型的生成能力。
- 嵌入数字水印,确保伪造内容能够被溯源。
7. 实时检测能力
-
- 提高检测模型的实时处理能力,使其能够在动态场景(如实时视频流)中应用。
-
- 设计轻量化模型,降低计算复杂度。
- 利用边缘计算和分布式架构实现实时检测。
5.1 论文总结 (Summary of the Paper) 这篇论文系统性地回顾了从单模态到多模态深度伪造检测的技术发展,并对现有的检测方法、数据集和未来方向提供了全面的分析。
- 研究背景:
-
- 深度伪造(Deepfake)技术的快速发展正在挑战社会信任和信息真实性,尤其是多模态伪造(如音频、视频和文本的结合)正变得越来越普遍。
- 伪造检测技术的目标是有效识别虚假内容,阻止其潜在的负面影响。
- 论文的主要贡献:
-
- 系统回顾了深度伪造检测领域的发展历史,尤其是检测方法从单模态扩展到多模态的技术演进。
- 提出了对现有数据集、生成技术和检测挑战的分类和分析。
- 总结了领域内的主要挑战,包括生成技术的快速演化、数据集的局限性和多模态伪造的复杂性。
- 展望了未来的发展方向,提出了应对新型生成技术、构建多模态数据集、提升鲁棒性与公平性等具体建议。
5.2 深度伪造检测的现状 (State of Deepfake Detection)
-
- 单模态检测方法在早期伪造技术(如GAN和VAE生成的伪造)中表现良好,但对多模态复杂伪造和新型生成技术(如扩散模型)表现不足。
- 多模态检测方法正在崛起,能够更全面地处理真实世界中的伪造场景,但仍处于早期阶段,面临高复杂度和跨模态对齐难题。
-
- 随着扩散模型的兴起,伪造内容的真实感显著提升,这对传统检测方法提出了新的挑战。
-
- 现有数据集主要针对特定类型的伪造方法,缺乏对多模态内容的覆盖,也无法充分模拟真实世界中压缩、低分辨率等伪造特性。
5.3 深度伪造检测的未来方向 (Future Directions) 论文强调了未来发展方向对提升伪造检测性能的重要性,并指出了以下重点领域:
- 适应新生成技术:
-
- 需要开发能够泛化到未见生成方法(如扩散模型)的检测器。
- 利用生成过程中的中间状态或模型特性捕获伪造痕迹。
- 多模态检测:
-
- 跨模态伪造检测是未来的重要方向,要求能够联合分析音频、视频和文本的特征。
- 数据集建设:
-
- 构建更全面、更高质量的多模态数据集,特别是包含扩散模型生成内容的伪造样本。
- 鲁棒性与公平性:
-
- 提升检测器在真实世界场景(如压缩、噪声和后处理等条件下)的鲁棒性。
- 保证检测方法对不同性别、种族和年龄的公平性。
- 实时检测能力:
-
- 优化模型结构,提高伪造检测的实时处理能力,适应动态视频和实时流媒体的需求。
- 主动检测机制:
-
- 开发主动防御机制(如水印嵌入或对抗扰动),从生成内容的源头上阻止伪造。
5.4 对社会的意义 (Implications for Society) 深度伪造技术虽然在娱乐、教育和创意产业中具有潜在的积极用途,但其滥用会对社会信任、隐私和信息安全造成严重威胁。因此,发展强大的伪造检测技术不仅是技术问题,也是社会问题。
- 防止信息污染:
-
- 伪造内容可能用于传播虚假信息、政治宣传或恶意攻击。检测技术可以帮助维护信息的真实性。
- 保护个人隐私:
- 促进技术的透明性:
-
- 提供可解释的伪造检测模型,有助于提高用户对检测技术的信任。
| 

























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









