









GenImage:用于检测人工智能生成图像的百万尺度基准
Mingjian Zhu等
华为诺亚方舟实验室 Huawei Noah’s Ark Lab
https://arxiv.org/abs/2306.08571
https://genimage-dataset.github.io/
Abstract
生成模型生成照片图像的非凡能力加剧了人们对虚假信息传播的担忧,从而导致对能够区分人工智能生成的假图像和真实图像的探测器的需求。然而,缺乏包含来自最先进图像生成器的图像的大型数据集,对这种探测器的发展构成了障碍。本文介绍了GenImage数据集,该数据集具有以下优点:
- 大量的图像,包括超过100万对人工智能生成的假图像和收集的真实图像。
- 丰富的图像内容,包含广泛的图像类。
- 最先进的生成器,使用先进的扩散模型和gan合成图像。
上述优点允许在GenImage上训练的检测器进行彻底的评估,并显示出对不同图像的强大适用性。我们对数据集进行了全面的分析,并提出了两个任务来评估类似于现实世界场景的检测方法。
- 跨生成器图像分类任务衡量在一个生成器上训练的检测器在其他生成器上测试时的性能。
- 降级图像分类任务评估检测器处理降级图像(如低分辨率、模糊和压缩图像)的能力。
有了GenImage数据集,与主流方法相比,研究人员可以有效地加快人工智能生成图像检测器的开发和评估。
Introduction
生成模型的进步在合成逼真图像方面取得了显著进展,大大减少了生成假图像所需的专业知识和努力。这种前所未有的可访问性引发了人们对无处不在的虚假信息传播的担忧。由于视觉上的可理解性,假图像特别具有说服力。因此,他们通过操纵舆论,对政治和经济等社会领域产生负面影响。例如,人工智能生成的五角大楼着火的照片在推特[1]上被广泛分享。这一形象愚弄了几家主要新闻媒体,并导致美国股市大幅下跌。目前最先进的(SOTA)生成模型已经展示了生成图像的能力,这些图像对人类的感知和歧视构成了重大挑战。人类在区分真实图像和人工智能生成的假图像[2]时,准确率仅为61.3%。为此,当务之急是优先开发一种有效的检测器,能够准确识别由这些先进的生成模型生成的假图像。
为了帮助检测器的开发,早期的假图像检测数据集[4,5]主要集中在人脸伪造上,利用生成模型来操纵人脸,从而取代一个人的身份或修改面部属性。UADFV[3]提供了一个小规模的人脸伪造数据集,仅包含241张真实图像和252张假图像。一个更大的数据集,即ForgeryNet[7],引入了一个更全面的数据集,包含超过100万个面部伪造图像实例。然而,这些数据集的适用性是有限的,因为它们只关注面部图像,使得它们对更广泛的图像类别不太有效。一般人工智能生成图像的早期数据集建立在生成对抗网络(GAN)上,如CNNSpot[9]。CNNSpot仅使用ProGAN[13]生成训练集,并在各种基于gan的测试集上评估检测器的性能。这些生成器生成的图像与真实图像非常相似,尽管人类经常可以检测到它们的合成性质。除了GAN,最近出现的替代生成器,如扩散模型,显著提高了生成图像的质量,使得区分真假图像的任务越来越具有挑战性。因此,对扩散模型生成的图像进行研究是非常必要的。IEEE VIP Cup[10]和DE-FAKE[11]采用扩散模型生成更通用的图像。基于Cifar10小尺度数据集[14],CiFAKE[12]仅使用Stable Diffusion V1.4生成假图像。然而,现有的扩散模型数据集存在数据有限的问题。

在本文中,我们利用当前最先进的扩散和GAN模型生成了广泛的通用图像集合,随后构建了我们的数据集,即GenImage。我们的目标是在完整和全面的人工智能生成的图像检测器训练和验证方面,与像ImageNet[15]这样令人敬畏的百万级数据集相提并论。我们使用ImageNet中的1000个类标签生成了130万张假图像,这相当于ImageNet中真实图像的数量。在表1中,我们将GenImage与其他数据集进行比较。与人脸伪造数据集相比,GenImage涵盖了更广泛的图像内容,如篮球和吉他。此外,GenImage采用最先进的扩散发生器,如Midjourney[16]和Stable diffusion[17]。更丰富的图像内容和生成器类别确保了GenImage中图像的多样性。与一般假图像检测数据集相比,GenImage还展示了数据集规模的优势。我们使用现有的SOTA检测方法对GenImage进行了全面的分析,然后提出了两个类似于现实世界检测问题的任务:(1)跨生成器图像分类:在一个生成器生成的图像上训练检测器,并在其他生成器生成的图像上评估检测器。(2)退化图像分类:对退化图像(如低分辨率、JPEG压缩、高斯模糊)上的检测器进行评价。GenImage有望为专门设计用于检测人工智能生成图像的检测器的进步做出重大贡献。
2 Dataset Construction
2.1 Dataset Details 数据集详细信息
为了准确评估探测器识别人工智能生成的图像和真实图像的能力,我们构建了一个数据集,GenImage,包含超过一百万对真实和虚假图像。考虑到ImageNet是一个很棒的数据集,我们想要与之相提并论,GenImage使用ImageNet中的所有真实图像。GenImage中的图像生成利用ImageNet中的1000个不同标签,确保在每个类中真实图像和生成图像的分布几乎相等。我们的数据集GenImage包含2,681,167张图像,分为1,331,167张真实图像和1,350,000张假图像。真实图像被细分为1,281,167张用于训练和50,000张用于测试。ImageNet[15]提供了1000个不同的图像类,我们为每个类生成1350个图像,其中1300个用于训练,其余50个用于测试。
为了解决SOTA生成器生成的图像检测问题,我们采用了BigGAN[18]、GLIDE[19]、VQDM[20]、Stable Diffusion V1.4[17]、Stable Diffusion V1.5[17]、ADM[21]、Midjourney[16]和Wukong[22] 8个生成模型进行图像生成。每个生成器为每个类生成几乎相同数量的图像,其中162张用于训练,6张用于测试,但Stable Diffusion V1.5除外,它生成166张用于训练,8张用于测试。由生成器生成的假图像与其对应的真实图像的组合可以被认为是一个子集,例如Stable Diffusion V1.4子集。真实的图像不会跨子集共享。生成的图像数量近似于整个数据集和每个子集的真实图像数量。该数据集中每个生成器生成的图像数量几乎相等,这使得在开发检测模型时可以充分探索每个生成器的属性,而不会受到数量不平衡的影响。我们的模型输入句子遵循模板“photo of class”,其中“class”被ImageNet标签取代。对悟空来说,中文句子的生成质量往往更好。因此,这些句子被翻译成中文用于web API。对于ADM和BIGGAN,我们在ImageNet上使用它们的预训练模型,输入标签来生成图像。

生成的图像如图1所示。在补充资料中提供了更多的可视化图像。可以观察到,总的来说,在ImageNet中生成的图像与真实图像相似。对具有相同标签的图像进行更详细的分析。动物和植物成功地保持目标物体的外观一致,例如,具有相似外观的samoyed,它们在运动,视角和背景方面有所不同。目标的外观也因蜡烛和灯塔等物体而异。因此,生成的图像具有高度的可变性和合理性。
2.2 Fake Image Generators 伪图像生成器
近年来,扩散模型在图像合成中取得了令人瞩目的成绩。Midjourney[16]是最著名的商业软件程序之一,以其卓越的图像生成性能而闻名。我们利用Midjourney V5进行图像生成,与以前的版本相比,它提供了更复杂的细节,从而产生与现实世界照片非常相似的图像。Midjourney生成的图像分辨率为1024 × 1024。悟空[22]是一个基于扩散模型的大规模文本到图像生成模型。该模型是在最大的中文开源多模态数据集——悟空数据集上训练的,使其特别适合中文语言处理。图像分辨率为512 × 512。稳定扩散[17]是一种先进的文本到图像扩散模型,能够根据任何给定的文本输入生成高度逼真的图像。Stable Diffusion V1.4从Stable Diffusion V1.2检查点进行预训练,并在Laion-Aesthetics V2 5+数据集上以512x512分辨率在225k步上进行微调,并减少10%的文本条件作用。Stable Diffusion V1.5的训练设置与Stable Diffusion V1.4相同,不同之处在于Stable Diffusion V1.5对595,000步进行了微调。稳定扩散V1.4和稳定扩散V1.5生成的图像分辨率为512 × 512。ADM[21]提出了一种比gan更好的扩散模型。我们使用带有分类器引导的模型,该模型在ImageNet上进行预训练。GLIDE[19]是一个用于文本条件图像合成的扩散模型。GLIDE使用一个文本编码器来训练一个35亿的扩散模型。我们使用无分类器引导生成图像。其分辨率为256×256。VQDM[20]提出了一种潜在空间方法,消除了之前方法的单向偏差,并结合了掩码替换扩散机制来减轻误差的积累。决议是256×256。
在过去的几十年里,GAN在图像生成方面带来了显著的质量改进。BigGAN[18]是GAN族中具有代表性的方法。BigGAN做出了三个贡献,包括架构变更、采样技术和减少不稳定性技术。我们使用在ImageNet上预训练的BigGAN模型。图像分辨率为128×128。
3 GenImage Benchmark
3.1 Fake Image Detectors 假图像探测器
为了评估我们的数据集,我们研究并选择了一些现有的假图像检测方法。
骨干网络模型(Backbone Model)可以直接用作真假图像二值分类的检测器。我们使用ResNet-50 [23], DeiT-S[24]和swan - t[25]作为假图像检测器。ResNet[23]是基于卷积神经网络的。DeiT-S[24]和swing - t[25]是基于Transformer的。如果没有针对假图像检测任务的具体设计,骨干模型可以被认为是基线方法。
假脸检测器(Fake Face Detector)已经发展了很长时间。F3Net[26]提出同时探索真假图像的频率分量划分和频率统计差异,用于人脸伪造检测。GramNet[27]使用全局纹理特征使假人脸检测更加鲁棒的和可泛化。这些方法在人脸图像上训练模型。这些模型很难直接很好地处理人脸域以外的图像。然而,这些方法仍然可以启发一般图像检测器的设计。
通用假图像检测器(General Fake Image Detector)采用特殊的设计对一般图像进行分类,摆脱了人脸内容的限制。Spec[28]以频谱作为输入,在真实图像中合成GAN伪影,而不需要特定的GAN模型来生成假图像作为训练数据。CNNSpot[9]使用ResNet-50作为二值分类器,具有特定的预处理和后处理以及数据增强功能。然而,现有方法在包含GAN和扩散生成图像组合的数据集上的性能需要进一步改进。因此,开发适合混合GAN和扩散数据的独特特性的探测器变得势在必行。
3.2 Task 1: Cross-Generator Image Classification 任务1:跨生成器图像分类
我们首先在同一生成器生成的图像上进行训练和测试时评估检测器的性能。我们使用最常用的Resnet-50[23]进行分析。我们的GenImage数据集由八个不同的子集组成,每个子集对应于一个特定的生成器。在每个子集中,我们进一步将数据分为训练集和测试集,每个集包含1000类图像。如表2所示,每个子集内的训练和测试始终产生超过98.5%的准确率。值得注意的是,Stable DiffusionV1.4和Stable DiffusionV1.5子集达到了99.9%的优异精度。然而,我们观察到,当使用不同的生成器进行训练和测试时,性能会有很大的下降。例如,当ResNet-50在Stable Diffusion V1.4上进行训练并在Midjourney上进行测试时,二元分类准确率下降到54.9%。
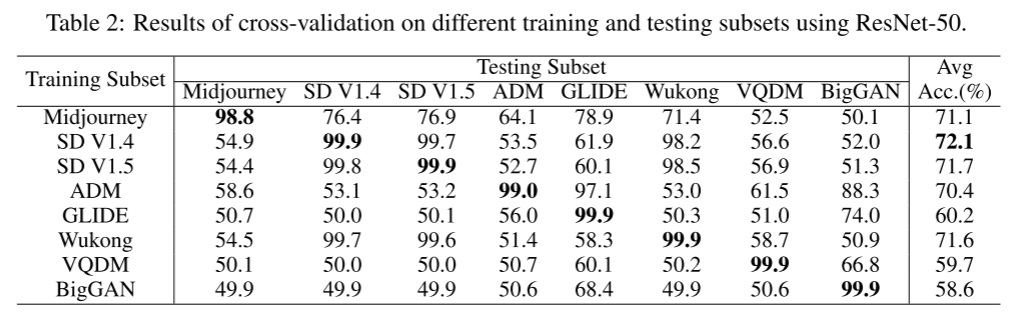
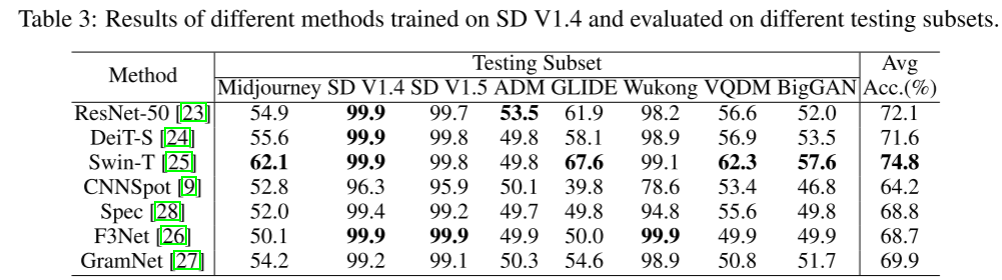
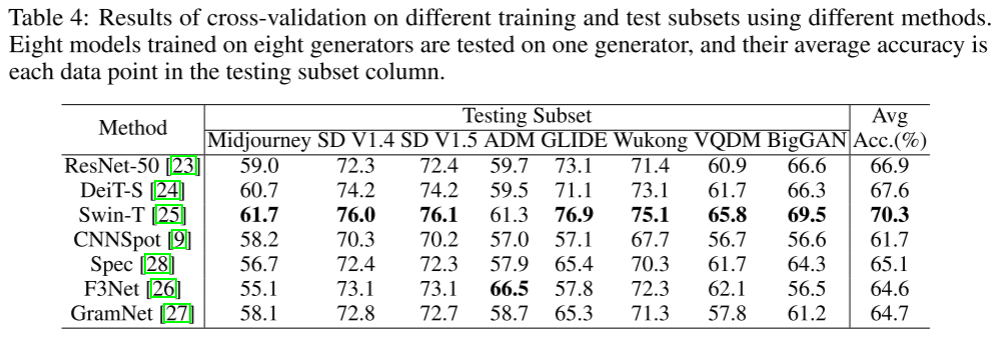
基于这种观察,检测由特定生成器合成的假图像相对简单,只需在由真实图像和假图像组成的数据集上训练二值分类器即可。然而,这种方法很可能与这个生成器绑定在一起,并且在未知的生成器上不能很好地执行。在现实世界的场景中,生成器在训练时通常是未知的。在这项工作中,我们希望能够有效地评估检测器的泛化能力,即独立于所使用的生成器区分真假图像的能力。我们提出了跨生成器图像分类任务来评估人工智能生成器检测器的识别能力。在表2中,Stable Diffusion V1.4的训练效果最好。为此,我们在Stable Diffusion V1.4上训练模型,并随后在来自不同生成器的测试子集上对其进行测试。然后我们计算各个测试子集的平均准确度,如表3所示。在表3中,对于每种方法,我们在一个生成器上训练一个模型,并在八个生成器上对该模型进行评估。我们对一种方法取8个结果的平均值。在表4中,对于每种方法,我们分别在8个生成器上训练8个模型。我们在8个生成器上对每个模型进行了评估。一种方法平均得到64个结果。例如,我们分别使用8个生成器训练了8个ResNet-50模型,并在Midjourney上对其评估结果进行平均,准确率为59.0%。对其他生成器(如Stable Diffusion V1.4)也进行了评估,得出了另外56个评估结果。然后将所有64个测试结果取平均值,达到66.9%。我们的评估为探测器的能力提供了全面的见解。我们对数据集上的各种骨干架构进行了全面的评估,包括基于cnn的ResNet50[23],以及基于transformer的DeiT-S[24]和swing - t[25]。本评估旨在评估这些架构在人工智能生成的图像检测任务中的性能和有效性。此外,我们还评估了现有的人工智能生成的图像检测器的性能,如CNNSpot[9]和Spec[28]。
在表3和表4中,当前基于cnn的模型(如ResNet)的性能与基于transformer的模型(如DeiT-S和swing - t)相似。这些骨干模型具有相似的计算成本和参数,通常用于ImageNet上的1000类图像分类。对于ImageNet 1000类图像分类,骨干模型更倾向于关注图像内容的分类。对于GenImage来说,重点更多地放在区分真假图像的模式上。我们从零开始训练它们进行二分类。在跨生成器图像分类任务中,Swin-T的分类效果最好,其他两种方法的分类准确率接近。在我们的数据集中,改进基于transformer的方法是一个有前途的方向。我们还评估了现有的人工智能生成的图像检测器,例如CNNSpot[9]和Spec[28]。我们在我们的数据集上训练这些模型并对它们进行评估。CNNSpot提出可以通过增强训练数据来提高识别性能:
- 图像以50%的概率被σ ~ Uniform[0,3]模糊。
- 图像为jpeg格式的概率为50%。GAN通常会在上采样组件中产生独特的伪影。
结果表明,这些伪影在频域中表现为谱的复制。因此,Spec将光谱而不是像素作为分类的输入。CNNSpot和Spec在基于gan的数据集上工作得很好。然而,它们的表现甚至比我们数据集上的基线主干模型还要差,主干模型主要由扩散模型生成的图像组成。F3Net[26]包含两个分支,即频率感知图像分解(FAD)和局部频率统计(LFS)。FAD通过频率感知图像分解研究操纵模式。LFS提取本地频率统计信息。此外,还利用混合块进行协同特征交互。GramNet[27]观察了假脸和真脸之间的区别。然后利用全局纹理特征来增强鲁棒性和泛化。这两种方法都不如直接用二分类骨干神经网络模型进行训练。考虑到所有这些方法的优点,为GenImage设计一个特殊的骨干网络可能是一个很有前途的解决方案。
3.3 Task 2: Degraded Image Classification 任务2:退化图像分类
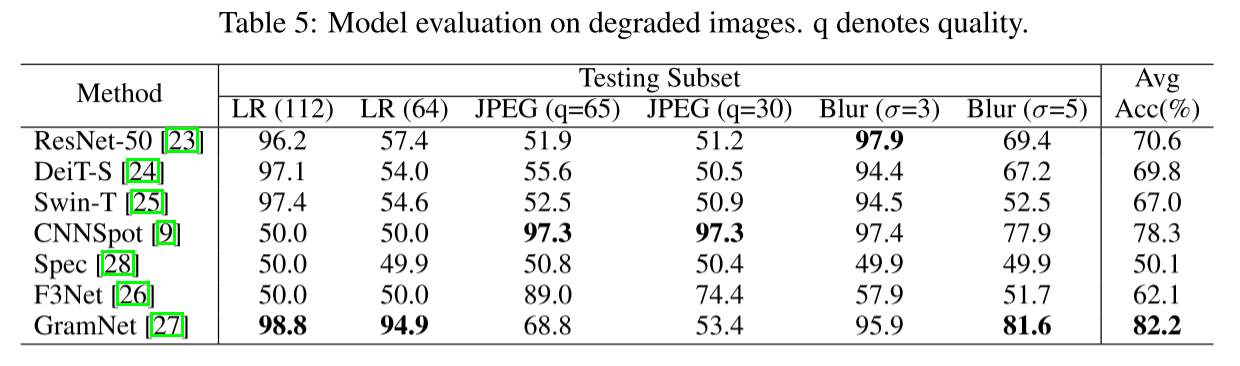
图像在传播过程中经常遇到退化问题,例如低分辨率、压缩和噪声干扰。探测器应该对这些挑战具有鲁棒的。为了解决这个问题,我们建议评估探测器在这些退化图像上的性能,这更准确地模拟了实际情况,如表5所示。在我们的Stable Diffusion V1.4子集上训练检测器之后,我们使用一系列方法只降级测试集图像。具体来说,我们只在测试集中将图像降采样到分辨率为112和64。此外,我们使用质量比为65和30的JPEG压缩,引入了压缩伪影。为了引入模糊效果,我们引入了高斯模糊。作为基线模型,ResNet-50、DeiT-S和swwin - t都显示出类似的结果。它们都能很好地检测低分辨率为112 × 112的图像。然而,对于64 × 64的较低分辨率,它们呈现较差的结果。实验结果表明,这些模型对分辨率更敏感。对于高斯模糊,这些模型也表现出类似的性能。JPEG压缩对这些骨干模型有重大影响。值得注意的是,CNNSpot对JPEG压缩和高斯模糊都具有鲁棒的,这基本上是由于CNNSpot在训练过程中使用了JPEG压缩和高斯模糊作为额外的数据预处理。因此,设计一种合理的预处理方法是解决我们数据集中退化图像分类问题的一种很有希望的方法。通过将这些检测器应用于退化的图像,我们获得了它们在各种具有挑战性条件下的性能的宝贵见解。这个评估提供了一个更全面的理解检测器处理实际图像退化的能力。
4 GenImage Analysis
在本节中,我们进行了广泛的实验来研究GenImage的特征,以及该数据集的有效性。
4.1 增加图像数量的效果 Effect of Increasing the Number of Images
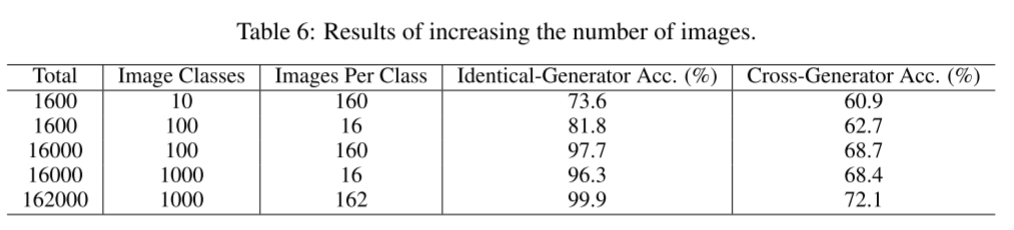
一般来说,增加数据集的规模通常被认为可以提高分类模型的性能。然而,这一观察结果在假图像检测任务中并没有得到充分的探索。为了协助评估所需数据量,我们进行了综合实验,如表6所示。我们使用Stable Diffusion V1.4生成的图像进行初步实验。特别是,我们的训练集完全由Stable Diffusion V1.4生成。在测试集中引入了两种不同的设置。在同发生器设置下,测试集由6000张假图像组成。(aigc检测任务,对数据集大小不敏感)
另一方面,在交叉生成器设置中,测试集包含来自8个不同生成器的50000张假图像。从ImageNet[15]收集相同数量的真实图像。首先,我们在一个由10个类组成的数据集上训练ResNet-50,每个类包含160张假图像。真实图像的数量与假图像的数量相同。同一发电机组测试集的准确率仅为73.6%,跨发电机组测试集的准确率更低。我们从两个方面进一步扩展我们的训练集:通过增加类的数量和增加每个类内的图像数量。令人鼓舞的是,我们观察到两种方法的性能都有了很大的提高。这个观察结果强调了增加训练集的重要性。(数据集图片多样性的重要)
4.2 Frequency Analysis 频率分析
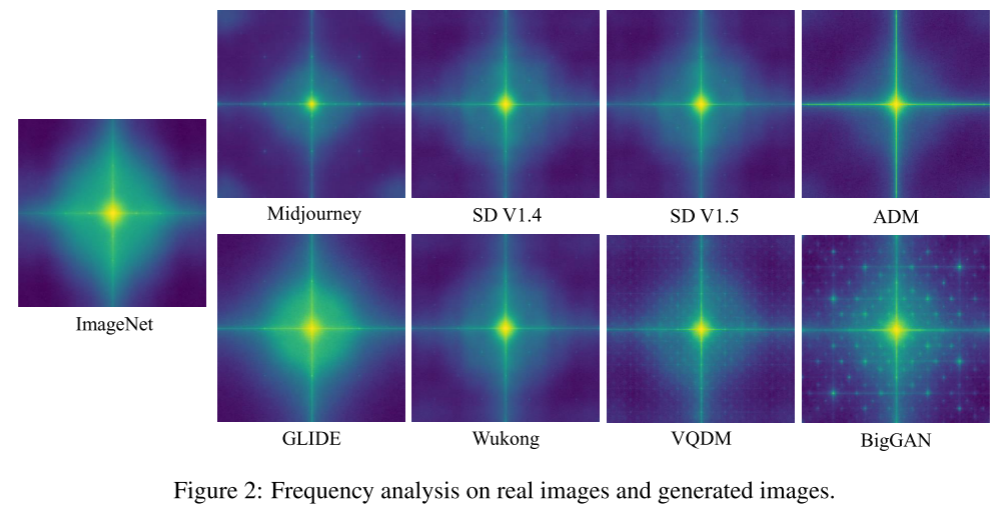
在图2中,我们可视化了来自不同生成器的真实图像和假图像的平均光谱。在CNNSpot[9]之后,我们使用离散傅里叶变换来研究由生成模型生成的伪影。对于每个图像源,我们对1000个随机选择的图像的噪声残差进行平均,并使用结果的傅里叶变换进行光谱分析。将实际图像、GAN生成的图像和扩散模型生成的图像进行比较,可以发现一些有趣的结果。结果表明,对于GAN,伪影以规则网格的形式显示。来自ImageNet的真实图像包含很少的伪影以及扩散模型。这些结果反映了扩散模型的图像比BigGAN更接近真实图像,因此扩散模型对检测提出了更大的挑战。(在频率角度gan有明显特征,扩散模型和真实图像更像,所以更难区分)
4.3 图像类泛化 Image Class Generalization

为了验证在我们的数据集上训练的检测器可以很好地泛化到图像的不同内容,我们采样了三个类子集,即10、50和100,用于训练ResNet-50。可以看出,仅使用1000个类中的一个子集就可以很好地泛化到其他类别的图像,并且子集中的类越多,泛化性能越好。我们使用所有的发电机进行训练和测试。我们首先保持训练数据的数量不变,即生成12800张图像。测试集包含1000个图像类,每个类生成50个图像。训练集和测试集包含八个生成器生成的图像。每个类中真实图像的数量与假图像的数量相同。如表7所示,仅对图像类的一个子集进行训练,在1000类图像上也可以取得很好的效果,并且更多的图像类可以获得更高的准确率。
这个结果验证了我们的数据集在图像类上的泛化性能,这也意味着1000个类的训练可以在未见过的图像上获得更好的结果。我们还比较了两种设置下的准确性:100类图像,每类128张图像和100类图像,每类1300张图像。可以看出,增加每个类别的图像数量可以提高准确率。
4.4 Generator Correlation Analysis 生成器相关分析
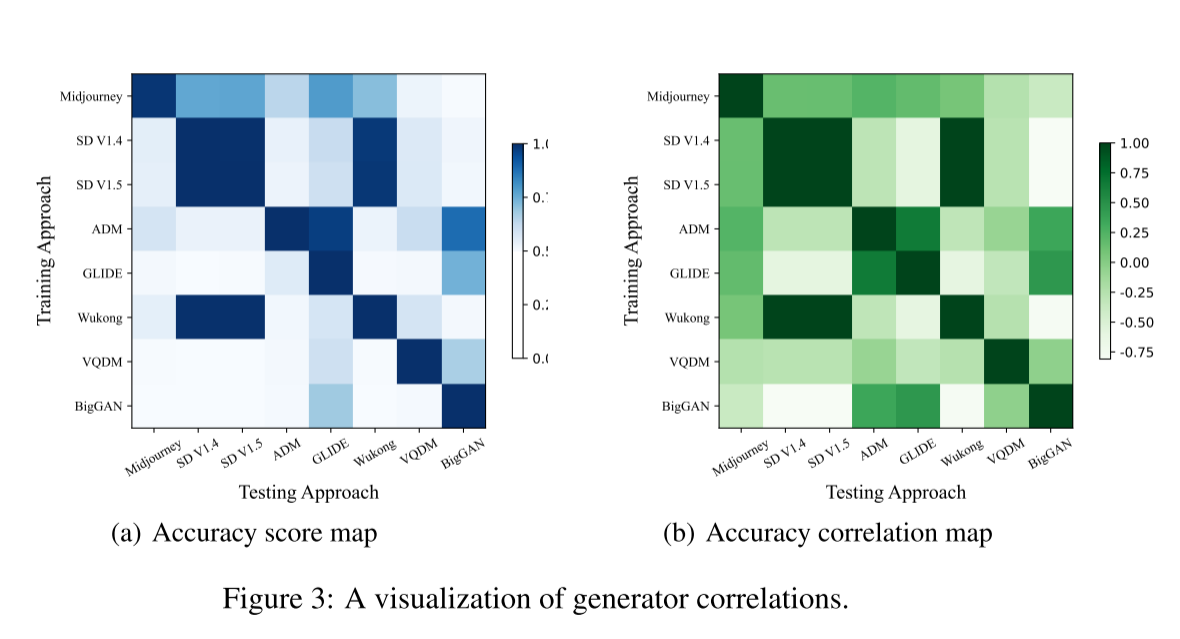
由于生成器类别通常不作为先验知识可用,我们对跨生成器图像分类任务进行了广泛的评估,包括八种不同的生成方法,如图3所示。ResNet-50是检测器。可以看出,同一个生成器在训练和测试中都达到了最优的性能。具有较高相似性的生成器倾向于产生更好的跨生成器性能。例如,Stable DiffusionV1.4和Stable DiffusionV1.5,共享相似的架构,在前者上训练,在后者上测试时,显示出良好的分类结果。同样,在稳定扩散模型上训练的检测模型可以有效地推广到悟空。从图3 (a)中可以看出,在Stable Diffusion V1.4、Stable Diffusion V1.5和悟空上进行训练,整体泛化性能最好。《中途旅行》在泛化方面提出了最大的挑战。此外,图3 (b)强调了具有相似架构的模型往往具有更高的相关性,例如Stable Diffusion V1.4, Stable Diffusion V1.5和Wukong。
4.5 Image Content Generalization 图像内容泛化

我们的数据集涵盖了广泛的图像类别,超越了人脸和艺术(art)图像的传统限制。如表8所示,我们的数据集显示出显著的内容泛化能力。具体来说,在我们的数据集上训练的ResNet-50可以有效地处理人脸和艺术图像。LFW[29]是一个为人脸识别问题设计的公开可用的人脸图像数据库。我们从LFW数据集中收集了10,000张人脸图像,并使用相同数据集中的人脸标签生成了相同数量的图像。Laion-Art是Laion-5B[30]的一个子集。几个轻量级模型估计人们将如何根据美学对Laion-5B中的每张图像进行评分,得分高的图像将保留给Laion-Art。DiffusionDB[31]是一个大型画廊数据集,拥有180万个唯一提示。
我们已经积累了来自Laion-Art的10,000张艺术图像,以及使用来自DiffusionDB的提示生成的10,000张艺术图像,如图4所示。对于训练,我们使用GenImage的Stable Diffusion V1.4子集。稳定扩散V1.4也用于生成人脸和艺术假图像。我们直接在测试数据集上评估我们的模型,而不需要进行微调。如表所示,我们的数据集显示出值得称赞的泛化能力,在识别人脸和艺术图像方面达到了95.0%以上的准确率。
- 数据集的特点:该数据集涵盖了广泛的图像类别,突破了传统仅包含人脸或艺术图像的局限。
- 实验数据来源:
- 人脸图像来自 LFW 数据集(10,000 张),并用其标签生成了相同数量的合成图像。
- 艺术图像来自 Laion-Art 和 DiffusionDB(分别收集了 10,000 张高评分艺术图像及 10,000 张通过提示生成的图像)。
- 训练模型:训练使用了 Stable Diffusion V1.4 的子集,并用于生成合成人脸和艺术图像。
- 评估结果:在未经微调的情况下,模型在测试数据集上表现出优秀的泛化能力,识别人脸和艺术图像的准确率超过 95%。
5 Conclusion
本文介绍了GenImage,这是一个专门用于检测生成模型生成的假图像的数据集。GenImage作为百万级基准,在图像数量、图像内容和生成器选择方面超过了以前的数据集和基准。我们提出了两个任务,即交叉生成器图像分类和退化图像分类,以评估现有检测器在GenImage上的检测性能。此外,还提供了对数据集的详细分析,使我们能够深入了解GenImage如何为实际应用的检测器开发做出贡献。


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









