









| 论文标题:DF40: Toward Next-Generation Deepfake Detection |
| Published at NeurIPS 2024 |
| 发表时间:v1:2024年6月19日12:35:02 UTC |
| 作者单位:1. 北京大学 电子与计算机工程学院 2. 腾讯优图实验室 |
这篇论文《DF40: Toward Next-Generation Deepfake Detection》提出了一个新的深度伪造检测基准——DF40,旨在解决当前深度伪造检测领域中存在的多个问题。作者指出,目前大多数深度伪造检测方法是基于某个特定数据集(例如FF++)进行训练和评估的,这导致这些模型在应对真实世界中多样且日益逼真的深度伪造时效果不佳。
Abstract and Introduction
- 当前数据集的局限性:
-
- 现有数据集主要集中在有限的伪造技术(如换脸和面部重演)上,无法覆盖当前深度伪造技术的多样性和复杂性。
- 目前使用的数据集大多过时,且仅针对面部伪造,限制了模型在应对当前最先进的深度伪造时的能力。
- 现有检测系统通常在某些伪造类型上表现良好,但在新型深度伪造方法上却无法有效检测。
- DF40的贡献:
-
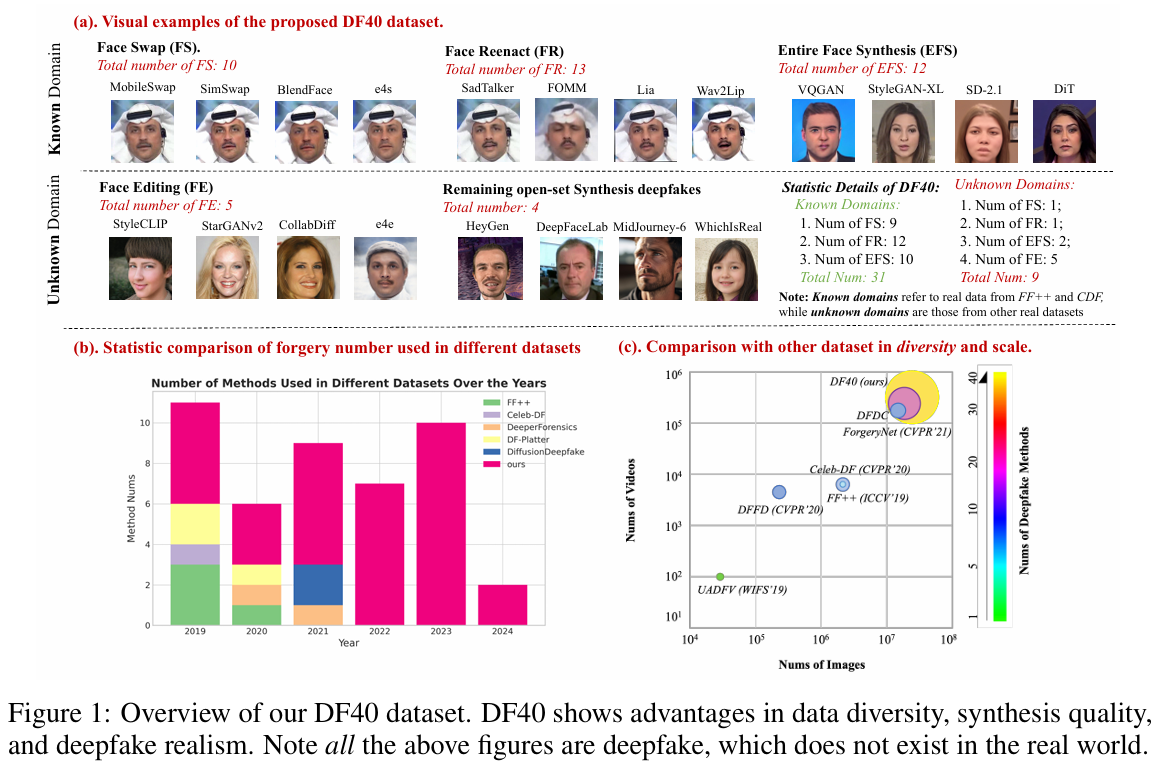
- DF40是一个全新的数据集,包含了40种不同的深度伪造技术,涵盖了面部交换、面部重演、整脸合成和面部编辑等多个类别,规模是FF++数据集的10倍大。
- 这个数据集的目标是通过提供更丰富、更真实的深度伪造技术,帮助提升模型对多种伪造类型的泛化能力,弥补现有数据集的不足。
- DF40的评估:
-
- 论文通过8种检测方法和4个标准评估协议,进行了大量评估,分析了在DF40数据集上训练的模型表现。
- 通过超过2000次的评估,作者提出了7个关键发现,并提出了4个未来研究问题。
- 主要发现:
-
- 观察到当模型从特定类型的伪造(如面部交换)迁移到其他类型(如面部重演或整脸合成)时,性能下降显著。
- 传统的最先进模型,如使用Xception的模型,在DF40数据集上与基线模型相比并未显示出显著的提升。
- CLIP模型的表现优于其他检测方法,说明了在大规模数据集上进行预训练的重要性。
- 研究还发现了分辨率差距问题,即真实图像与伪造图像之间的分辨率差异可能引入模型偏差。
- DF40的影响:
-
- DF40通过提供更具多样性和真实性的数据集,为开发能够在多种深度伪造类型上表现良好的通用深度伪造检测模型提供了一个重要工具。
- 作者认为,DF40基准的推出将有助于保护社会信任,提高深度伪造检测系统在现实应用中的可靠性。
这篇论文强调了数据集的多样性和规模对于深度伪造检测系统训练的重要性,并全面分析了现有检测模型在多种深度伪造类型上的表现。
换脸假设
这个假设指的是许多现有的深度伪造检测方法在面对换脸(face-swapping)伪造时,依赖于一个假设:现有的换脸伪造通常会涉及将生成的伪造面部与原始背景图像进行“融合”,即“blending”【v.
(使)混合,调和;(使)协调,融合;调制,配制(blend 的现在分词)】。具体来说,"blending"是指将生成的伪造面部图像与原始背景图像合成在一起,通常会留下某些伪造的痕迹或不自然的过渡区域,这些痕迹可以被检测算法用来识别伪造。
- Blending的概念:
-
- 在传统的换脸伪造方法中,通常会先从源图像中提取出目标人物的面部特征,并将其合成到目标图像中。这一过程包括两部分:一部分是生成伪造的面部,另一部分是将这些伪造的面部无缝地合成到背景图像中。在合成过程中,伪造的面部通常会与背景图像的其他部分进行“融合”,例如将伪造面部与原始背景中的眼睛、嘴巴等部位对齐,这样生成的图像看起来尽量真实。
- 这个融合过程通常会留下某些不自然的过渡痕迹,特别是在脸部边缘、光照、纹理以及与背景的接缝处,这些伪造的痕迹可以作为深度伪造检测的线索。
- 为什么许多检测方法依赖这个假设:
-
- 由于许多现有的深度伪造方法(如FF++数据集中的换脸伪造)都基于“融合”步骤,传统的深度伪造检测方法通常会通过寻找这些特征(例如,融合边缘、色彩不匹配、光照不一致等)来识别伪造图像。这些检测算法假设换脸伪造会使用一定的图像合成技巧,从而产生某些特定的伪造痕迹。
- 这些检测方法通常会关注像素级的细节,如脸部与背景的融合区域,甚至通过检测细微的光照和纹理变化来识别伪造。这些假设在过去的伪造技术中是有效的,因为大多数伪造面部都会被“融合”到背景中,留下了可以被算法捕捉到的特征。
- 问题:新型深度伪造方法的挑战:
-
- 然而,近年来出现了许多新的换脸技术(如SimSwap、FaceDancer等),这些方法不再使用传统的“融合”步骤。相反,它们通过生成完整的伪造图像,包括背景,直接合成整个场景。这意味着新型的换脸伪造可能不会在面部与背景的接缝处留下任何明显的融合痕迹。
- 这些新方法的出现挑战了传统检测方法的假设,因为检测算法可能无法捕捉到这些没有“融合”痕迹的伪造图像。这使得基于“融合”假设的检测方法在面对这些新型深度伪造时,效果大打折扣。
2 Background
2.1Deepfake Generation
在论文《DF40: Toward Next-Generation Deepfake Detection》的 Background 部分,特别是 Deepfake Generation 这一小节中,作者介绍了当前深度伪造(deepfake)生成技术的主要类型,并对这些技术进行了分类。以下是对该部分内容的详细解释:
1. 深度伪造生成技术的分类
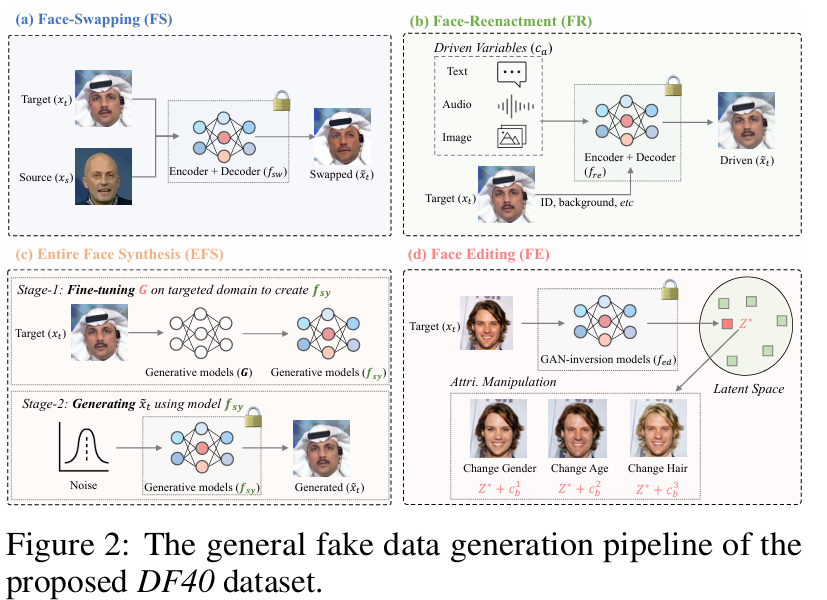
该部分将深度伪造的生成技术分为四类,分别是:
- 面部交换(Face-Swapping,FS):
-
- 面部交换技术主要是将一个人的面部特征替换到另一个人的身体或背景中。这种方法常见于电影特效或者社交媒体中的伪造。
- 在FS中,生成的伪造面部与原背景图像通常会进行“融合”(blending)。也就是说,伪造的面部会被裁剪出来,并通过一定的算法将其拼接到新的背景中。大多数早期的深度伪造方法(如DF-family和FS-family)都属于这种方法。
- FS技术通常通过“遮罩”(masking)方法来处理面部和背景的合成,生成伪造图像时,会用一个面部区域的遮罩来将新生成的面部与背景融合。
- 面部重演(Face-Reenactment,FR):
-
- 面部重演技术用于改变一个人的面部表情或动作,通常通过模仿另一个人的面部动作或表情来改变原始人物的面部特征。
- 与面部交换不同,面部重演技术并不改变整个面部的内容,而是基于一个源面部的姿势或表情,通过一些算法将其转移到目标人物的面部。这种方法常用于将某人的面部表情或动作“映射”到另一个人脸上。
- 例如,技术如Face2Face和NeuralTextures可以实现面部的实时重演,将一个人的面部表情“转移”到另一个人的脸上。
- 整脸合成(Entire Face Synthesis,EFS):
-
- 整脸合成技术生成一个完全合成的面部图像,不仅是面部特征的替换,而是整个面部的合成。这些生成的面部可能并不存在于现实中。
- 这类技术通常利用生成对抗网络(GAN)或扩散模型(diffusion models)来生成面部图像。例如,VQGAN、StyleGAN2和StableDiffusion等技术就属于这一类。
- EFS生成的面部不仅仅是重演某个真实面孔,而是全新的面孔,通常会使用噪声输入通过模型生成完全虚构的面部图像。
- 面部编辑(Face Editing,FE):
-
- 面部编辑技术通过修改给定面部图像的某些属性(如年龄、性别、发型等)来生成伪造图像。这类技术通常基于一些潜在空间变换(例如GAN反向变换),修改图像的特定特征。
- 这些方法通常基于已有的面部图像,通过编辑面部的某些属性,而不需要完全重建整个面孔。
- 例如,StyleGAN模型可以在潜在空间中操作图像的各种特征,允许对面部的特定属性(如年龄、性别、表情等)进行修改。
2. 不同生成技术的特点
- 面部交换(FS)和面部重演(FR)通常关注对现有面部图像的修改,分别侧重于面部特征的“交换”和“重演”。
- 整脸合成(EFS)是一个更加彻底的伪造方法,它不仅仅交换或重演面部,而是完全生成新的面部图像。
- 面部编辑(FE)则在现有面部的基础上进行修改和编辑,常用于生成具有特定属性(如性别或年龄变化)的图像。
3. 面临的挑战
- 论文指出,随着技术的发展,新的生成方法越来越逼真,且生成伪造面部的技术正在变得更加多样化和复杂。例如,使用GAN和扩散模型生成的整脸合成图像通常更加自然和难以检测。
- 对于检测模型来说,传统的训练方法可能难以应对当前日益多样化和高质量的深度伪造。尤其是现有的检测方法通常假设伪造图像会在面部和背景之间留下明显的“融合”痕迹,但新型技术生成的伪造图像可能没有这些明显的伪造痕迹。
2.2 Existing Deepfake Datasets.
作者讨论了当前存在的深度伪造数据集及其局限性,特别是这些数据集如何影响深度伪造检测方法的泛化能力。以下是对该部分内容的详细解释:
1. 现有数据集的主要问题
- 数据集的单一性和过时性:
-
- 现有的深度伪造数据集主要集中于传统的深度伪造技术,尤其是面部交换(Face-Swapping)方法,并且往往只使用几种特定的伪造技术(通常不超过4种)。这些数据集生成的伪造图像或视频大多使用的是比较旧的生成技术,这使得这些数据集不适用于当前更加多样化和先进的深度伪造技术。
- 例如,FF++(FaceForensics++)数据集包含了基于过时技术的伪造方法,这些技术可能无法代表当前最先进的伪造方法(如基于扩散模型或深度生成对抗网络的技术)。因此,这些数据集训练出来的检测模型在面对当前的伪造技术时,可能会表现不佳。
- 伪造类型的限制:
-
- 许多现有数据集只专注于某一类伪造,例如,FF++数据集主要集中在面部交换(Face-Swapping)和面部重演(Face-Reenactment)类型,而对**整脸合成(EFS)和面部编辑(FE)**等伪造类型的覆盖很少。这使得训练出来的模型只能处理有限类型的伪造,难以应对多样化和更复杂的伪造形式。
- 训练和测试数据集的分离:
-
- 目前大多数检测模型在特定数据集上训练,然后在不同的伪造数据集上进行测试。这种方法虽然帮助评估检测算法的有效性,但也存在一定的局限性,因为它无法评估模型在真实世界中的泛化能力,尤其是在面对不同类型、不同技术生成的伪造时,模型的表现可能大相径庭。
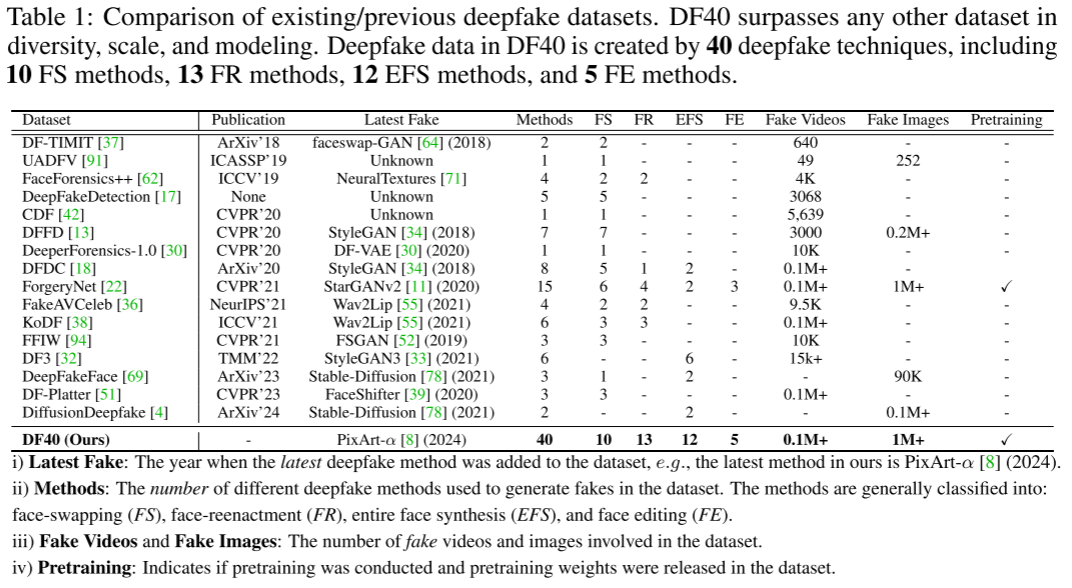
2. 现有主要数据集的比较
作者对几种主要的现有深度伪造数据集进行了对比,重点关注其包含的伪造方法种类和数据规模。以下是几种重要数据集的简要介绍:
- DF-TIMIT (2018):
-
- 该数据集使用了Faceswap-GAN进行伪造生成,包含了2种面部交换方法(Face-Swapping)和2种面部重演方法(Face-Reenactment)。数据集规模较小,包含640个视频数据。
- UADFV (2019):
-
- UADFV数据集包含1种面部交换方法和1种面部重演方法,数据集的规模较小,仅包含49个视频和252个图像。
- FaceForensics++ (FF++) (2019):
-
- 该数据集是目前最为常用的深度伪造数据集之一,包含了多种伪造方法,其中包括4种面部交换方法、2种面部重演方法以及2种整脸合成方法。数据集包含约4,000个视频数据。
- DeepFakeDetection (2019):
-
- 该数据集包含5种面部交换方法和5种面部重演方法,数据量较大,但也存在与FF++类似的局限性,集中在有限的伪造方法上。
- DFDC (2020):
-
- 该数据集通过7种伪造方法生成伪造数据,数据规模大,超过100,000个视频,但依然主要集中在面部交换和重演类型。
- ForgeryNet (2021):
-
- 该数据集引入了15种伪造方法,数据规模也在百万级别,但同样存在与FF++类似的问题,过于依赖传统的面部交换和重演伪造。
- DeepFakeFace (2023):
-
- 该数据集加入了一些较新的生成技术,但仍然以传统的伪造类型为主。
- DF40 (2024)(该论文的贡献):
-
- DF40数据集相比其他数据集有着显著的优势,涵盖了40种深度伪造技术,包括10种面部交换(FS)方法、13种面部重演(FR)方法、12种整脸合成(EFS)方法和5种面部编辑(FE)方法。这些伪造方法包括了当前最先进的生成技术(如PixArt-α、DeepFaceLab和HeyGen等)。
- DF40的数据量也更为庞大,包含超过100,000个视频和超过1百万张图像。
3. DF40数据集的优势
- 更大的数据集规模:DF40的数据规模是现有数据集的10倍以上,涵盖了更多类型的伪造技术,提供了更具代表性和多样性的训练和测试数据。
- 更高的伪造技术多样性:DF40包含了更为丰富的伪造类型,不仅仅是面部交换,还包括面部重演、整脸合成和面部编辑等,能够更好地模拟真实世界中深度伪造的多样性。
- 更真实的伪造方法:DF40包含了当前最先进的深度伪造技术,使得训练出来的模型能够适应更加复杂和逼真的伪造。
3 DF40 Benchmark
3. DF40 Benchmark 部分,作者介绍了他们提出的DF40数据集的详细情况,并说明了如何利用这个数据集进行深度伪造检测的评估。以下是这一部分的详细解释:
1. DF40基准的研究范围和概述
- DF40数据集是一个多样化且大规模的深度伪造数据集,专门用于面部深度伪造检测,涵盖了四种主要的伪造类型:
-
- 面部交换(Face-Swapping, FS)
- 面部重演(Face-Reenactment, FR)
- 整脸合成(Entire Face Synthesis, EFS)
- 面部编辑(Face Editing, FE)
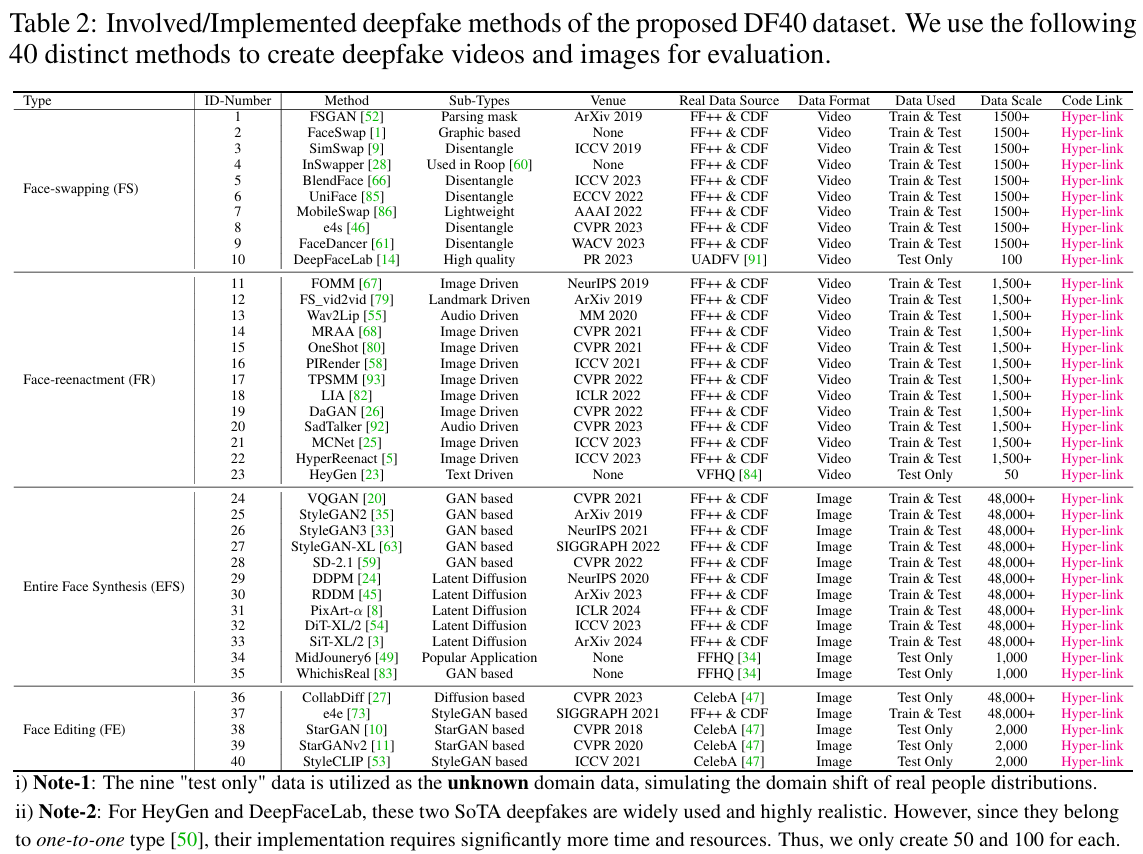
- DF40数据集提供了超过 40种不同的伪造技术,其中包括10种面部交换方法、13种面部重演方法、12种整脸合成方法和5种面部编辑方法。相比于现有的伪造数据集(如FF++),DF40的数据集规模更大,伪造类型更加多样,覆盖了当前最先进的深度伪造技术。
2. 数据来源与生成方法
- 真实数据:DF40使用了来自两种主流数据集(FF++和CDF)的真实数据作为训练和评估的基础。这两种数据集被广泛用于当前的深度伪造检测研究,因此作者选择使用它们来验证现有方法的有效性,并进行跨数据集的比较。
- 伪造数据:为了确保数据集的多样性,DF40采用了40种不同的伪造生成技术来创建伪造数据。这些技术覆盖了面部交换、面部重演、整脸合成和面部编辑等不同类型的伪造。
-
- 例如,PixArt-α(2024年最新的伪造技术)和DeepFaceLab(广泛使用的换脸工具)就被包含在内。
- DF40还包括一些经典和代表性的方法,如FOMM(First Order Motion Model)和StyleGAN2等。
3. 数据集的特点和优势
- 数据多样性:DF40数据集不仅包含了多种伪造类型,而且涵盖了多种不同的生成技术。这使得它能够应对各种现实世界中可能遇到的深度伪造类型,而不像现有的数据集仅专注于某一类伪造(例如仅包含面部交换伪造)。例如,DF40不仅包括传统的面部交换技术,还包括最新的基于扩散模型的整脸合成伪造方法。
- 大规模数据集:DF40的数据量非常庞大,视频数据超过10万条,图像数据超过100万张。相比于其他数据集(如FF++),DF40的规模至少大了10倍,能够为训练更为准确、泛化能力更强的深度伪造检测模型提供更丰富的资源。
- 真实世界模拟:DF40的数据生成方法注重模拟现实世界中的深度伪造情况,包含了当前最新的生成技术(如PixArt-α和DeepFaceLab),这些方法能够生成极为逼真的伪造图像和视频,进一步提高了该数据集的现实意义。
4. DF40的评估协议
- 作者提出了4个标准的评估协议来评估检测模型的表现:
-
- 跨伪造类型评估(Cross-forgery evaluation, Protocol-1):在这种评估协议中,训练数据和测试数据来自不同的伪造类型。这可以帮助测试模型在处理多种伪造类型时的泛化能力。
- 跨数据域评估(Cross-domain evaluation, Protocol-2):评估模型在训练和测试时,数据来源不同的情况。例如,训练数据来自FF++,而测试数据来自CDF。这个协议考察了不同数据域对模型检测效果的影响。
- 面向未知伪造类型或数据域的评估(Towards unknown forgery or domain evaluation, Protocol-3):在这种评估中,模型测试的数据包含了训练数据中未出现的伪造类型或数据域。这个协议测试了模型的开放集检测能力,即在面对未知类型的伪造时,模型是否能够有效地识别。
- 一对多评估(One-Verse-All, OvA evaluation, Protocol-4):训练模型时使用一个伪造类型的数据,然后在不同伪造类型的数据上进行测试。这个协议帮助评估模型在应对多种伪造类型时的表现。
-
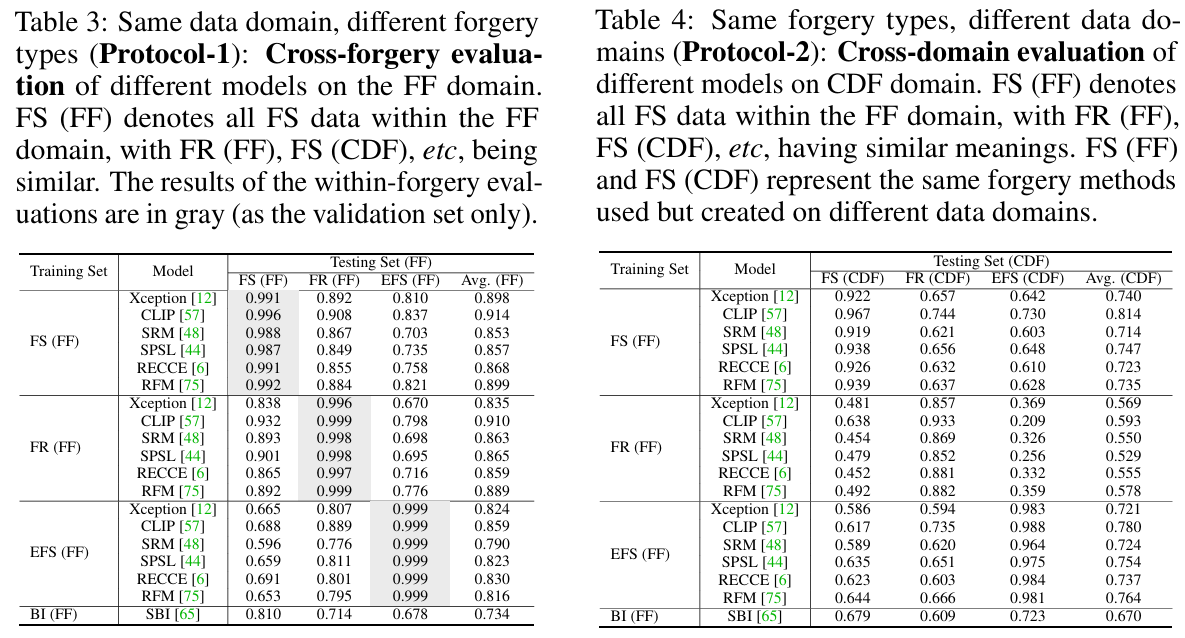
通过这些标准评估协议,作者能够全面分析检测方法在不同情况下的表现,揭示当前检测方法的优缺点,并为未来的研究提供有价值的参考。
5. DF40对未来研究的启示
- 通过对DF40数据集的综合评估,作者得出了一些新的洞察和结论,揭示了当前深度伪造检测方法的局限性。例如,很多现有的检测方法在跨伪造类型和跨数据域的测试中表现不佳,无法有效应对现实世界中多样化的伪造类型。
- DF40不仅为现有的深度伪造检测方法提供了一个挑战,也提出了一些未来研究的重要问题。例如,如何设计能够应对多种伪造类型和数据域的通用检测器,以及如何更好地利用大规模多样化数据集来训练高效的检测模型。
4 Evaluations and Analysis
4.1 Experimental Setup
4.1 Experimental Setup 部分,作者详细描述了他们在进行深度伪造检测评估时所使用的实验设置和方法。以下是这一部分的详细解释:
1. 实验设置的目标
- 这一部分的目的是介绍作者如何配置实验环境,以便能够对不同的检测方法进行公平和一致的评估。具体来说,实验设置包括数据集的准备、所选用的检测方法以及训练和测试的细节,确保评估结果具有较高的可信度。
2. 数据集配置
- 训练数据集:作者使用了DF40数据集作为实验中的核心训练数据集。DF40数据集包含了40种不同的伪造技术,涵盖了面部交换(FS)、面部重演(FR)、整脸合成(EFS)和面部编辑(FE)等四种伪造类型。数据集提供了大规模的视频和图像数据,确保训练数据的多样性和代表性。
- 测试数据集:除了DF40数据集,作者还使用了其他一些流行的数据集(如FF++和CDF)进行测试。这些数据集提供了现有检测方法的标准评估基准,帮助评估模型在跨数据集情况下的泛化能力。作者特别选择了跨伪造类型和跨数据域的测试方法,确保模型在多种现实世界场景下的表现。
3. 检测方法的选择
- 在实验中,作者选择了多种深度伪造检测方法进行对比和评估,包括:
-
- Xception:一种经典的基线模型,使用深度卷积网络进行图像分类。Xception已经被广泛应用于许多深度伪造检测任务,因此它作为基线方法提供了一个比较基础的性能指标。
- 四种最先进的检测方法(SoTA):包括SRM(Swin Transformer for Face Recognition)、SPSL(Spatial Pyramid Spatial Layer)、RECCE(Reciprocal Encoding for Classification and Encoding)和RFM(Robust Face Manipulation)。这些方法在许多现有数据集上已展示了良好的表现,并被认为是当前最先进的深度伪造检测方法。
- Blending-based Detector:这种检测方法利用图像“融合”技术(即将伪造的面部合成到背景图像中)来生成伪造样本并用于训练。虽然这类方法在某些传统伪造技术中有效,但它的泛化能力可能不如其他基于学习的检测方法。
4. 实验环境与框架
- DeepfakeBench框架:为了确保实验的标准化,作者使用了DeepfakeBench框架进行所有模型的训练和评估。DeepfakeBench是一个开放的深度伪造检测框架,它提供了统一的数据预处理、模型训练、评估以及结果统计的工具,确保了实验过程的一致性和结果的可重复性。
- 所有实验都遵循统一的设置,包括数据预处理、模型初始化、训练轮次等,确保不同模型之间的公平比较。
5. 评估指标
- AUC(Area Under the Curve):作者使用了AUC指标来衡量不同模型在分类任务中的性能。AUC越高,表示模型对伪造图像和真实图像的区分能力越强。
- 准确率(Accuracy):除了AUC外,作者还使用了准确率来评估模型的整体分类效果。准确率衡量了模型预测正确的样本比例。
- 召回率(Recall)和精确度(Precision):这些指标也会用来进一步评估模型在不同伪造类型和数据域上的表现,特别是在不平衡数据集上的效果。
6. 训练细节
- 训练设置:所有模型在训练时都遵循相同的参数设置,包括学习率、优化器选择和训练轮次等。模型训练的目标是使得检测器能够学会从深度伪造图像和真实图像中提取有效的特征。
- 预训练:一些深度学习模型,如Xception和其他SoTA模型,已经在大规模图像分类数据集(如ImageNet)上进行了预训练。在这些模型的基础上,作者对其进行了微调,以适应深度伪造检测任务。
7. 实验目标
- 主要目标是评估不同检测方法在DF40数据集上的表现,并通过比较它们在跨伪造类型和跨数据域上的检测效果,来揭示现有方法的优势和局限。
- 作者还试图通过这些实验,探讨如何在实际应用中开发一个通用的深度伪造检测系统,能够有效应对各种类型和技术生成的伪造。
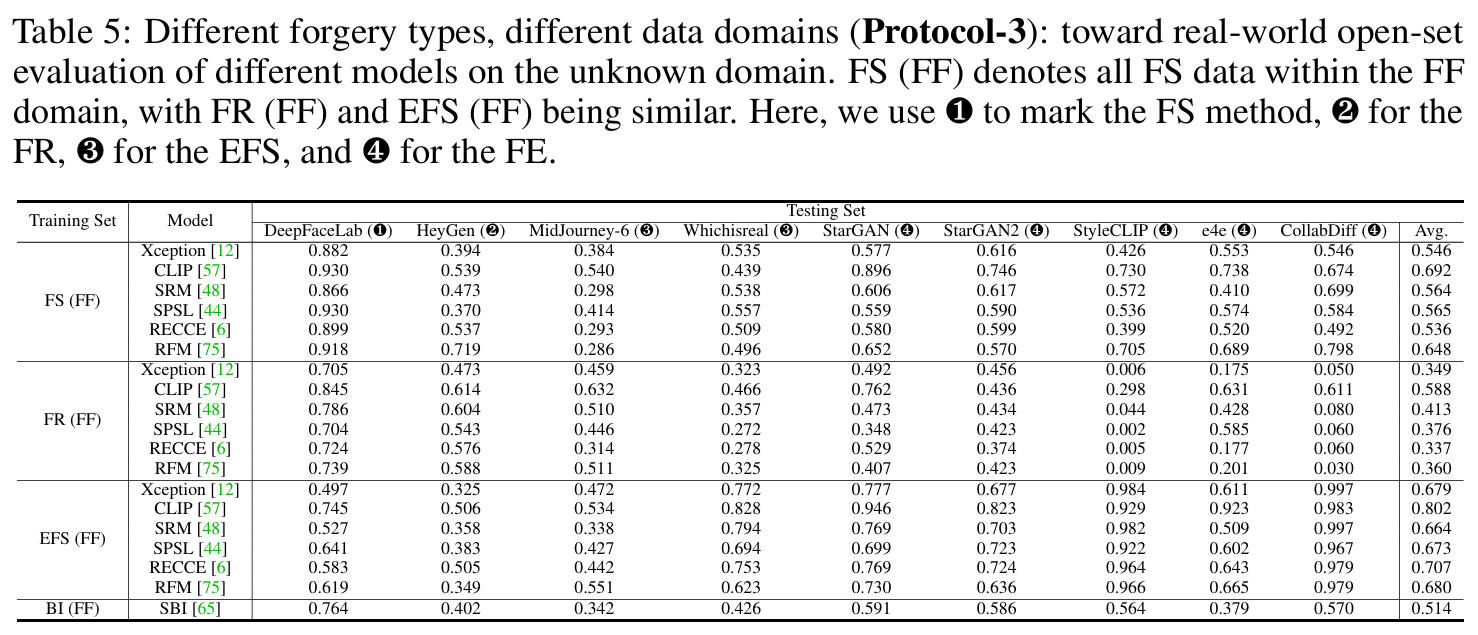
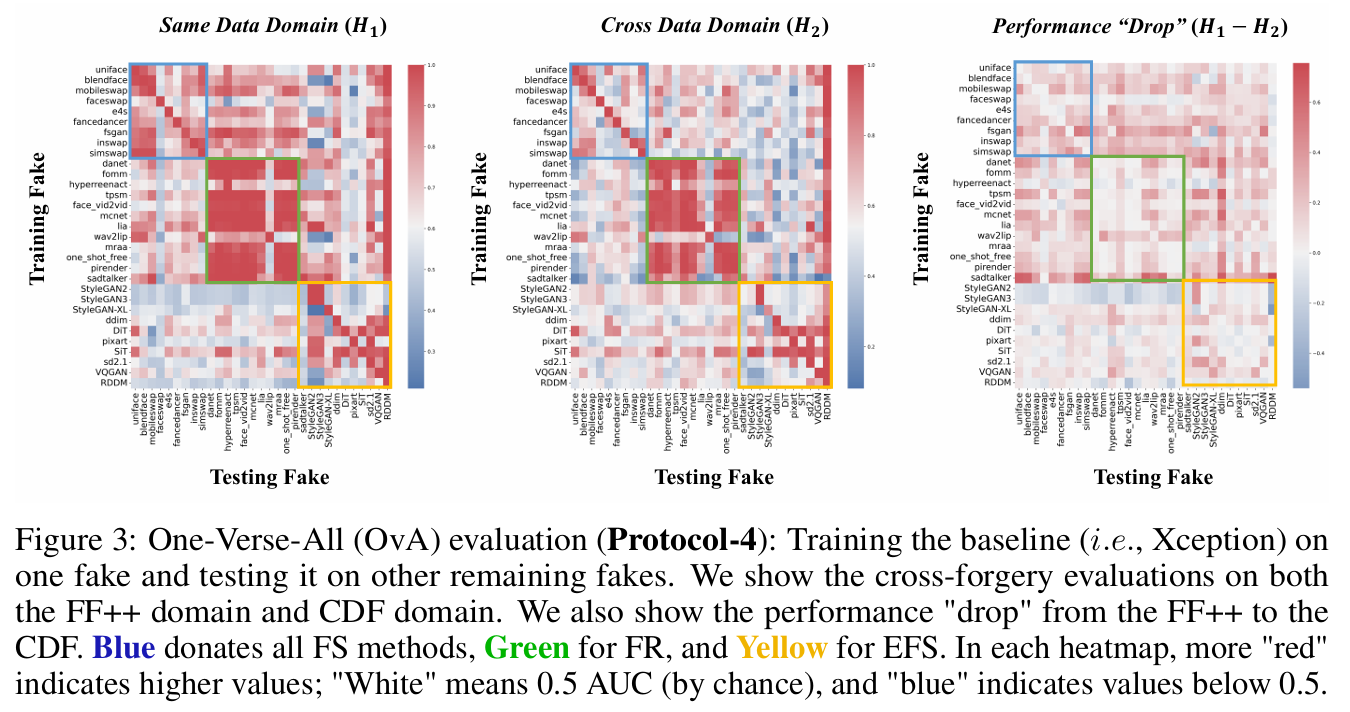
4.2 Evaluations,Findings,and Analysis
4.2 Evaluations, Findings, and Analysis 部分,作者根据对DF40数据集进行的广泛评估,提出了7个关键发现(Findings),并进行了深入分析。这些发现和分析为深度伪造检测领域提供了有价值的洞察,帮助揭示现有检测方法的优缺点,并为未来的研究提供了新的思路。
1. 发现 1:不同伪造类型之间的性能差异(假冒区域的重要性)
- 主要发现:当训练模型时,面部交换(FS)伪造数据通常比面部重演(FR)和整脸合成(EFS)伪造数据表现得更好。在不同伪造类型之间,性能的下降更明显,尤其是在从FS迁移到FR或EFS时。具体来说,模型在FS类型上的训练通常能更好地处理EFS类型的数据,而EFS类型的训练对FS类型的检测效果较差。
- 原因分析:这种性能差异可以归因于伪造区域的不同。面部交换通常只会影响面部区域,伪造特征相对集中,而整脸合成伪造则涉及整个面部或图像的合成,伪造区域更广泛。FS伪造包含局部伪造(如面部区域),而EFS伪造则是全局伪造,涉及整个图像,模型可能会偏向于识别全局伪造的伪造痕迹,但无法有效识别仅局部伪造的图像。

2. 发现 2:现有的最先进的检测方法与基线模型的差距较小
- 主要发现:尽管许多最先进(SoTA)的检测方法,如SRM、SPSL、RECCE和RFM,与基线模型Xception相比表现稍好,但其提升幅度并不显著。
- 原因分析:这些现有的最先进检测方法可能过度依赖于特定的伪造特征,而忽略了伪造数据的多样性。尽管这些方法在某些传统数据集上(如DFDC)表现良好,但它们在面对DF40数据集的多样化伪造类型时,未能充分展示出其优势。因此,这些方法可能仍存在泛化性问题,无法应对新的伪造技术。
3. 发现 3:CLIP表现优于其他基线模型
- 主要发现:在所有实验中,CLIP(Contrastive Language-Image Pre-training)模型的表现优于其他检测方法,尤其是在跨伪造类型和跨数据域的评估中。
- 原因分析:CLIP模型在预训练时使用了大量的图像和文本数据,这使得它能够学到更丰富的特征表示。CLIP的优势在于它能够在多种不同类型的深度伪造中识别出更多的可区分特征,而不像其他基于卷积神经网络(CNN)的模型那样过度依赖于某些特定的伪造痕迹。CLIP的跨模态学习能力使得它能够更好地适应各种伪造技术和数据域。
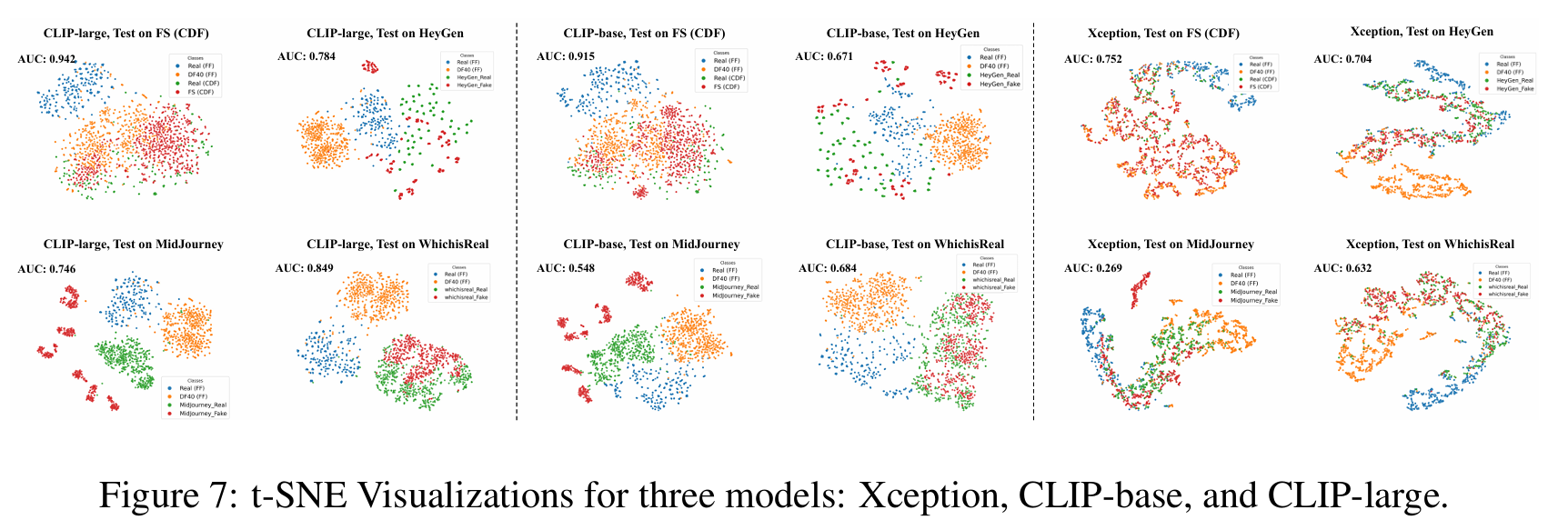
4. 发现 4:伪造方法和数据域共同影响伪造伪迹的区分性
- 主要发现:当伪造方法和数据域同时变化时,性能下降更为明显。例如,Xception模型在训练时使用FS(FF)数据,测试时使用FR(CDF)或EFS(CDF)数据时,性能下降约20%。
- 原因分析:这表明伪造方法和数据域共同影响伪造伪迹的区分性。当伪造方法发生变化时,伪造图像的特征也会变化,因此现有模型需要能够适应这种多样性。另外,数据域的不同可能导致伪造图像在不同数据集之间的特征差异,使得模型难以识别。
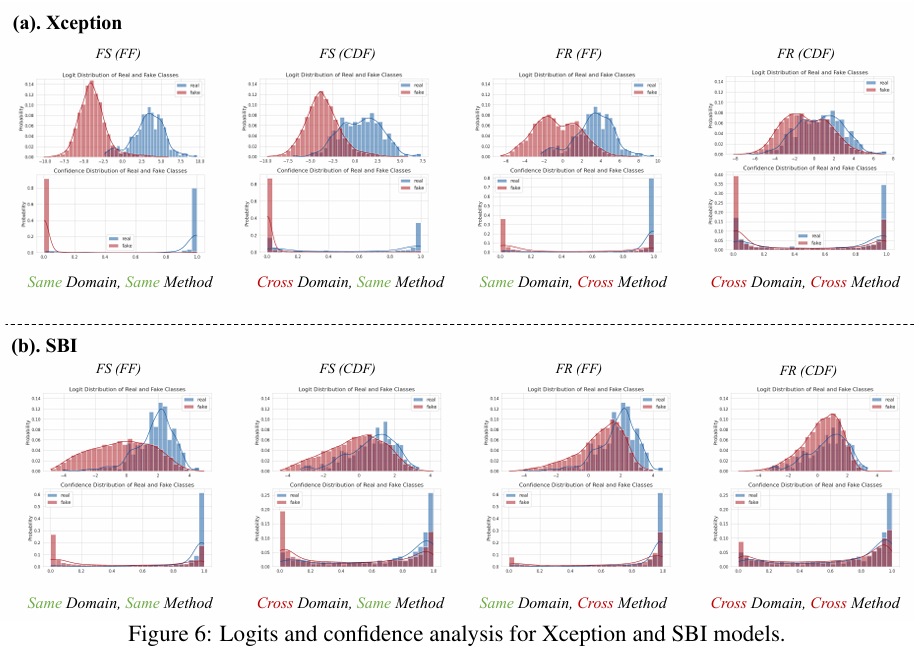
5. 发现 5:面部重演伪造方法可能共享可转移的特征
- 主要发现:许多面部重演(FR)伪造方法(如Wav2Lip)在不同数据域之间表现出较好的可转移性。也就是说,某些面部重演方法在不同的伪造数据集和数据域之间具有较强的区分能力。
- 原因分析:面部重演技术通常涉及到面部表情和动作的转换,伪造的面部特征通常会显得比较一致,因此这些方法可能能够共享一些通用的伪造特征。然而,某些特定的面部重演方法(如Wav2Lip)只会影响嘴部区域,这使得它与其他面部重演技术的伪造特征有所不同,从而导致了其在某些数据集上的表现较差。
6. 发现 6:SBI作为“异常检测”模型表现不佳
- 主要发现:SBI(Blending-based Detection)方法表现较差,尤其是在面对复杂伪造技术时。SBI模型更多依赖于将伪造图像和真实图像的特征进行对比,判断其是否为异常。
- 原因分析:SBI方法通过创建伪造样本并与真实样本进行比较,可能在伪造特征与真实样本之间找到较大的差异。然而,随着生成技术的进步,伪造样本和真实样本之间的差距变得越来越难以辨别,导致SBI方法在处理复杂伪造时的效果变差。
7. 发现 7:CLIP-large模型在非面部深度伪造上也展现了潜力
- 主要发现:CLIP-large模型不仅在面部深度伪造上表现优异,在非面部深度伪造(如艺术品生成等)方面也显示出了较强的检测能力。
- 原因分析:CLIP通过预训练学习了大量跨模态的信息,使得它能够捕捉到更通用的特征,不仅适用于面部图像的伪造检测,还能在其他类型的伪造(如生成艺术图像)中发现伪造特征。因此,CLIP-large展现出了较强的跨领域适应能力。
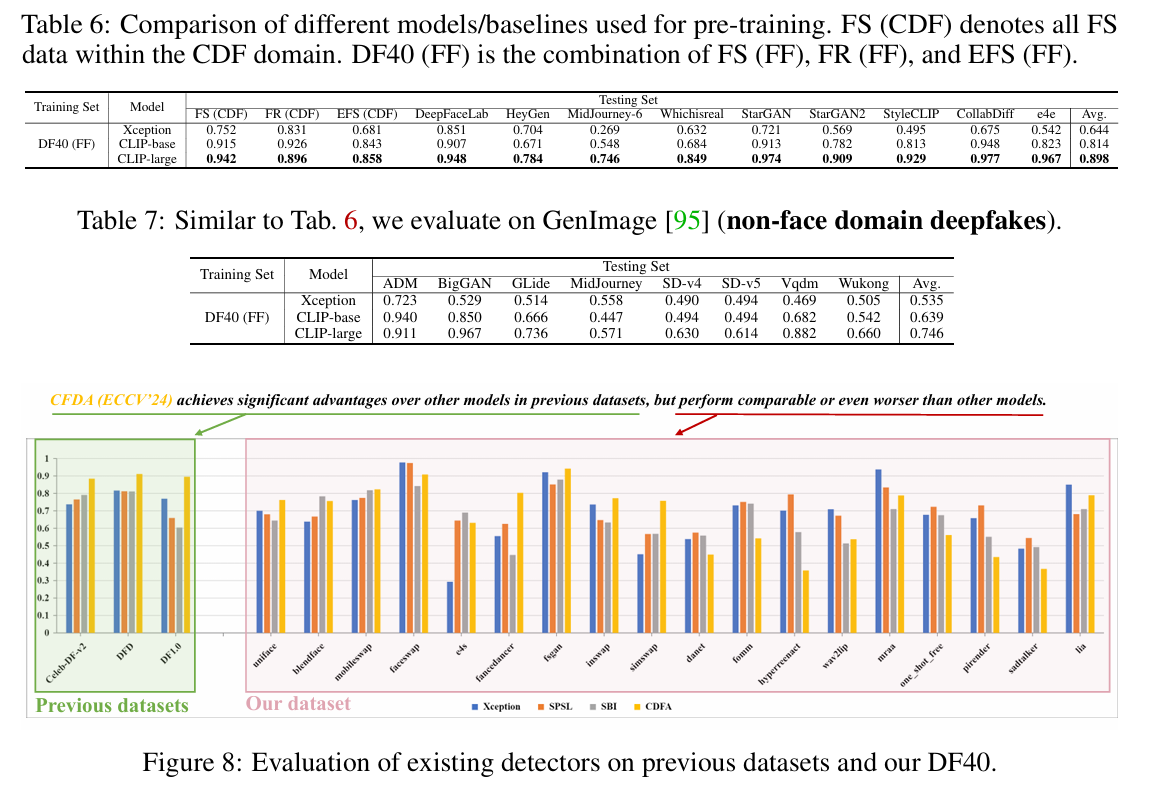
4.3 Discussion & FurtherAnalysis
在论文《DF40: Toward Next-Generation Deepfake Detection》的 Discussion & Further Analysis 部分,作者讨论了他们的发现对深度伪造检测领域的影响,并提出了一些重要的问题和未来研究的方向。以下是该部分的详细解读:
1. 为何更具多样性的深度伪造数据集至关重要
- 现有数据集的局限性:
-
- 作者强调,当前大多数深度伪造检测方法通常在一个较为有限的伪造类型上进行训练和测试,这些数据集可能仅包含几种特定的伪造类型(如面部交换或面部重演)。这些数据集虽然对传统伪造技术有效,但面对更为多样和复杂的伪造方法时,效果会大打折扣。
- DF40的优势:DF40数据集的提出,正是为了填补这一空白。DF40包含了40种深度伪造技术,涵盖了面部交换、面部重演、整脸合成和面部编辑等多种伪造类型,能够更全面地评估检测方法的能力。通过使用DF40数据集,研究人员可以测试模型在处理不同伪造类型时的表现,从而避免训练模型时过度拟合某一种特定的伪造方法。
- 影响深度伪造检测的因素:
-
- 数据集的多样性和规模对检测方法的泛化能力至关重要。如果一个检测模型仅在某一类伪造数据上训练,它可能无法有效应对现实世界中不同的伪造方式。通过使用包含广泛伪造类型和多样数据源的DF40数据集,可以提高检测方法的适应性,使其更好地应对真实环境中的各种深度伪造。
2. 深度伪造检测的泛化问题
- 现有模型的泛化能力:
-
- 通过对DF40数据集进行的评估,作者发现许多最先进的检测方法在跨伪造类型和跨数据域的测试中表现不如预期。这表明,尽管这些方法在传统的数据集上有较好的表现,但它们在应对新型伪造技术时的泛化能力有限。
- 例如,使用基于Xception的检测方法,在训练时使用面部交换伪造数据,而在测试时使用面部重演或整脸合成伪造数据时,性能大幅下降。这种“迁移学习”的问题使得这些方法在跨数据集的应用中难以获得一致的性能。
- 解决泛化问题的潜在方法:
-
- 为了提升模型的泛化能力,作者提出了通过多样化训练数据来增强模型的适应性。例如,可以通过在训练过程中引入不同伪造类型、数据域和生成方法的伪造数据,来使模型学会更加通用的特征。这样,模型在遇到新的伪造类型时,能够更好地进行识别。
3. 超分辨率(Super-Resolution)图像是否为伪造?
- 超分辨率与伪造检测的关系:
-
- 作者提出了一个有趣的问题:当一个伪造图像经过超分辨率(SR)处理后,它是否会被深度伪造检测器识别为伪造?超分辨率技术常常用于提高图像的分辨率,这在许多伪造工具中都有应用,例如FaceFusion和其他深度伪造软件。
- 超分辨率可能会对伪造图像的检测造成影响,特别是在面部交换和整脸合成伪造图像中。作者通过实验发现,当将超分辨率应用于伪造图像时,检测模型的表现得到显著提升,尤其是在面部交换(FS)和整脸合成(EFS)伪造类型中。这表明,超分辨率操作可能引入一些明显的伪造伪迹,使得检测器能够更容易识别。
- 未来研究的方向:
-
- 研究如何利用超分辨率技术来增强伪造检测。虽然超分辨率可以提升伪造图像的质量,但它也可能在图像中引入一些可检测的伪造伪迹。因此,未来的研究可以探索如何结合超分辨率和深度伪造检测模型,以提高检测精度。
4. 频率域中的伪造特征
- 频率域分析:
-
- 论文还讨论了不同类型深度伪造在频率域中的特征。研究表明,尽管伪造方法不同,深度伪造图像在频率域中可能会显示出一些共同的伪造特征。例如,面部交换伪造(FS)和整脸合成伪造(EFS)常常在高频区域产生类似的“棋盘”模式,这种模式可以被用于伪造检测。
- 通过对图像进行频率分析,研究人员可以识别出伪造图像中常见的伪造特征,尤其是在高频区域。这一发现为伪造检测提供了一个新的视角,尤其是在面对复杂的深度伪造时。
- 进一步的研究问题:
-
- 未来的研究可以深入探讨不同类型伪造图像在频率域中的表现,尤其是如何利用频率域中的伪造伪迹来提高检测性能。这可能需要开发新的检测方法,能够在图像的频率域中捕捉到更细微的伪造特征。
5. 模型分辨率偏差问题
- 分辨率差距引发的偏差:
-
- 研究还发现,检测模型在处理高分辨率伪造图像时可能会产生分辨率偏差。特别是,当训练数据集中的真实图像通常具有较高的分辨率,而伪造图像的分辨率较低时,模型可能会倾向于认为低分辨率图像更可能是伪造的。这种偏差可能会影响模型的准确性,导致模型错误地将一些伪造图像判断为真实图像,反之亦然。
- 作者通过实验验证了这一现象,发现模型会对分辨率较高的伪造图像产生偏见,认为它们更像真实图像。因此,未来的研究可以探讨如何缓解这种分辨率差距引发的偏差,提高模型在不同分辨率下的鲁棒性。
6. 未来的开放研究问题
- 关于Blending的研究问题:
-
- 目前,许多检测方法依赖于“融合”伪造图像和真实图像的技术。作者提出了一个重要问题:融合数据在训练深度伪造检测器中的作用是什么? 如何才能在不依赖“融合”的情况下,训练出更强大的检测模型?这为深度伪造检测领域的未来研究提供了一个关键方向。
- 伪造类型的多样性问题:
-
- 随着伪造技术的不断发展,伪造类型日益多样化。未来的研究需要解决如何设计一个框架来有效联合学习多种伪造类型,而不会导致过拟合某一种类型的问题。
- 数据域不变检测器的开发:
-
- 作者还提到,现有模型面临的一个挑战是如何开发数据域不变的检测器,即模型能够识别来自不同数据域(例如不同图像分辨率、不同拍摄环境等)的伪造图像。
总结:
Discussion & Further Analysis部分总结了DF40数据集的研究成果,并提出了一些深度伪造检测中的关键问题和未来的研究方向。作者讨论了数据集多样性、超分辨率技术、频率域分析、分辨率偏差等问题,并提出了在这些问题上开展进一步研究的建议。这些讨论为深度伪造检测领域的学者提供了新的视角和研究方向,推动了这一领域的进步。
5 Conclusions,BoardImpacts,andLimitations
在论文《DF40: Toward Next-Generation Deepfake Detection》的 5. Conclusions, Board Impacts, and Limitations 部分,作者总结了他们的研究成果,并讨论了研究的广泛影响和潜在局限性。以下是这一部分的详细解读:
1. 结论(Conclusions)
- DF40数据集的贡献:
-
- 作者提出的DF40数据集是目前为止最全面和多样化的深度伪造数据集之一,包含了40种不同的伪造技术,涵盖了面部交换(FS)、面部重演(FR)、整脸合成(EFS)和面部编辑(FE)等多种伪造类型。相比于传统的深度伪造数据集(如FF++),DF40的数据规模更大,伪造类型更加多样,能够更全面地评估深度伪造检测技术的有效性。
- 通过在DF40数据集上的评估,作者揭示了现有检测方法的不足之处,并提出了新的研究方向。这些评估不仅推动了深度伪造检测方法的改进,也为未来的研究者提供了更多的思路和方法。
- 新发现:
-
- 通过对DF40数据集的深入分析,作者得出了7个关键发现,这些发现揭示了当前深度伪造检测技术在处理多样化伪造类型时的挑战。比如,现有的深度伪造检测方法在处理不同伪造类型和跨数据域时存在泛化问题,且许多现有模型在新伪造技术面前的表现并不理想。
- 作者还提出,CLIP模型相较于其他基线方法展现了更强的泛化能力,能够处理多种不同类型的伪造图像,并且在面对跨数据域和跨伪造类型的测试时表现更好。
2. 对领域的影响(Board Impacts)
- 提升深度伪造检测的可靠性:
-
- DF40数据集的推出不仅为深度伪造检测技术的研究提供了一个更具挑战性的基准,还为开发更强大的深度伪造检测工具提供了丰富的资源。通过在DF40数据集上进行评估,研究者可以更好地评估模型在实际应用中的有效性,尤其是在面对复杂和多样化的深度伪造技术时。
- DF40数据集的多样性和大规模特性对于提升深度伪造检测的泛化能力至关重要。随着伪造技术的发展,传统的检测方法可能无法应对新型伪造数据,DF40则提供了应对这些挑战的实验平台。
- 社会影响:
-
- 深度伪造技术的滥用已经对社会产生了深远影响,特别是在隐私侵犯、虚假信息传播和身份盗用等方面。通过提供一个更为强大和全面的深度伪造检测基准,DF40的推出有助于在技术上增强我们对深度伪造的识别能力,从而帮助保护社会信任并减少深度伪造带来的危害。
- 该研究为公众和监管机构提供了一个可靠的工具来应对深度伪造的风险,尤其是在保护个人隐私和防止虚假信息扩散方面,具有重要的社会意义。
3. 研究的局限性(Limitations)
- 视频级检测分析不足:
-
- 尽管本研究使用了大量的视频数据进行评估,但视频级检测的分析仍然较为简略。深度伪造检测不仅是静态图像的任务,还涉及到视频中的时间和空间信息。因此,未来的研究应当更加深入地探讨如何在视频级别上有效检测深度伪造,尤其是如何利用视频中的时间连续性和动态信息来进行伪造检测。
- 作者提到,虽然他们在附录中提供了一些视频模型(如I3D)的实验结果,但尚未对视频模型能否有效捕捉时间和空间伪造伪迹进行详细的分析。因此,未来的研究可以进一步探索视频级别检测模型的改进,提升其对动态伪造的识别能力。
- 模型偏向问题:
-
- 研究表明,现有的深度伪造检测模型可能存在一些偏向性问题。例如,某些检测方法可能过于依赖于图像的分辨率或某些特定的伪造特征,而忽略了其他类型的伪造伪迹。这种偏向可能会影响模型的泛化能力,尤其是在面对不同伪造技术时,检测效果会有所波动。
- 未来的研究需要更多地关注如何减少这种偏向,提高模型在多种伪造类型和数据域上的鲁棒性。
- 不充分的非面部伪造检测:
-
- 本研究主要关注的是面部伪造检测,而对于非面部伪造(如艺术图像生成等)的检测探讨较少。随着生成技术的发展,非面部伪造(如艺术作品、虚拟人物等)可能会成为未来伪造检测中的一个新兴挑战。
- 因此,未来的研究应该扩展到非面部伪造检测,探索如何设计能够有效识别各种非面部伪造类型的检测方法。


















 2796
2796

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









