







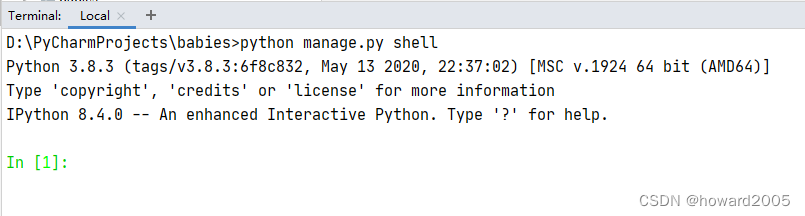
在PyCharm的Terminal下开启Shell模式,输入python manage.py shell指令即可,如下图所示。
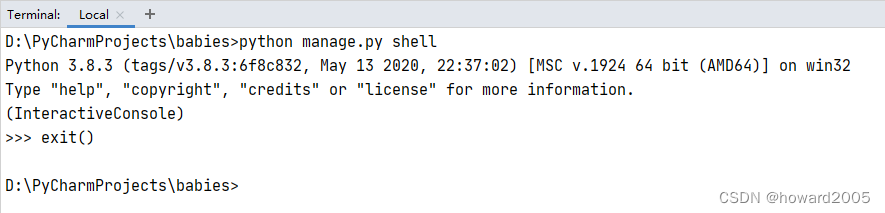
如果Shell模式示符是“>>>”
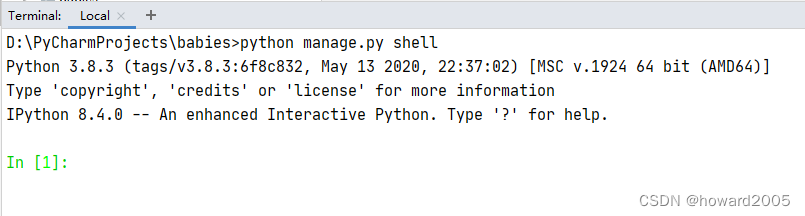
可以安装IPython,如下图所示

此时,再进入Shell模式
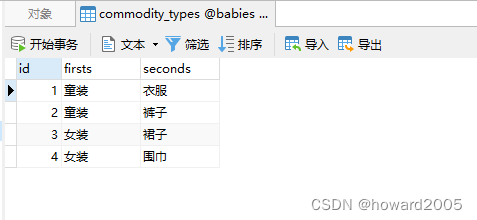
下面准备针对商品类别表进行操作,表里目前有4条记录
在Shell模式下,若想对数据表commodity_types新增数据,则可输入以下代码实现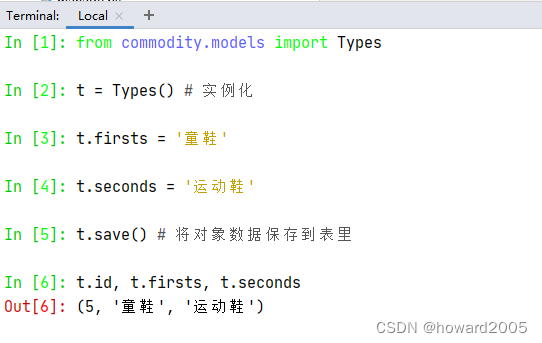
-
新增数据步骤:导入模型
在PyCharm的Terminal下开启Shell模式,输入python manage.py shell指令即可,如下图所示。
如果Shell模式示符是“>>>”
可以安装IPython,如下图所示
此时,再进入Shell模式
下面准备针对商品类别表进行操作,表里目前有4条记录
在Shell模式下,若想对数据表commodity_types新增数据,则可输入以下代码实现
新增数据步骤:导入模型
 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















