







* Exploring Temporal Coherence for More General Video Face Forgery Detection
题目:探索更一般的视频人脸伪造检测的时间相干性
1.概述
-
时间相干性网络组成:
第一阶段是一个全时间卷积网络(FTCN)。FTCN的关键见解是 将空间卷积核大小减少到1,同时保持时间卷积核的大小不变。有助于模型提取时间特征,并提高泛化能力。
第二阶段是时间变换网络,旨在探索长期时间相干性。
-
时间相干性:

-
伪影类型:空间相关+时间相关
-
2.贡献
-
全时间卷积网络(FTCN)+时间变换器(Temporal Transformer):利用时间相干性检测。
-
探测器:定位和可视化伪造人脸的时间非相干部分。
-
模型泛化能力优越,可用于不可见的伪造。
3.网络总述
-
问题:如何利用空间+时间的卷积网络来学习时间的不相干性。
-
网络限制:保持所有时间相关卷积核大小为原始值,将所有空间相关卷积内核大小设置为1*1。
限制的作用:可以鼓励网络学习时间不相干。
证明:
ResNet-50(R50)作为主干,并比较了三种类型的分类器: -

证明了1*1的卷积更能使时间网络通过更一般的时间不相干学习分类。
-
网络总述:
全时间卷积网络+时间变压器。
这两个部分经过端到端的训练,用于视频人脸伪造检测。
总的来说,给定一个可疑视频V,
第一阶段:全时间卷积网络(FTCN)。处理局部时间闪烁和不一致性,并提取时间特征
F=FTCN(V)。第二阶段:时间变换器。旨在进一步建模时间特征(F)的每个时间片段之间的长期不相干。
即一个局部特征提取,一个全局对比。
最后,使用MLP头进行最终预测。
3.Fully Temporal Convolution Network
-
现有问题:时空耦合核会削弱模型捕捉纯时间信息的能力,所以同时处理时空伪影不太可能。
-
FTCN主要思想:限制网络处理空间信息的能力,提高处理时间信息的能力。
-
网络架构:
-

网络分析:
根据上述实验得出结论,卷积核为1更加适合学习时间的不相干。
但 因为一些卷积层可能涉及大于1的步长,所以用3DConv(Kt,1,1,1,1)替换1*1的卷积核。
如果Sh或Sw>1,则在卷积运算符后添加max-pooling(最大值池化操作 作用:增大感受野)
*注:3DConv(Kt,Kh,Kw,St,Sh,Sw)
其中Kt,Kh,Kw是时间、高度、宽度维度中的核大小,St、Sh、Sw是时间、高度、宽度维度中的步幅。
-
最终获得:时间特征
F\in R^{C*N*H*W}
(C=2048,N=16, H=1, W =1) F:时间特征。 R:局部视频 C:输入的特征维度。 N:输入的序列长度。 H:高度。 W:宽度。
4.Temporal Transformer
-
作用:学习时间维度上的长期差异。
-
网络架构:
-

1.按时间分割FTCN提取的特征: F\in R^{C*N*H*W}; 2.用时间特征的线性投影(W),将映射尺寸从原特征维数(C)映射到新的特征维度(D);
3.将数据输入Temporal Transformer
输入序列:

F_{class}
:可学习的嵌入(可嵌入的有效位置)。作用是使临时变压器启动分类。E_{pos}
:嵌入的位置。F_t
:第t个时间片段的特征。4.Temporal Transformer组成:
-
LN+MSA+LN+MLP+GELU
* MSA: a multi-head self-attention(MSA) block . attention:注意力机制,根据需求观察注意特定的一部分。 self-attention:优点计算复杂度小+可大量并行计算+可更好学习远距离依赖。 multi-head self-attention:可让模型从不同角度理解输入的序列。因此同时几个Attention的组合效果可能会优于单个Attenion. * MLP:多层感知机(Multi-Layer Perception) 感知机:把训练集分为正反两个部分,并且能够对未来输入的数据进行分类。 * GELU:激活函数。 GELU为非单调激活函数,有助于保持小的负值,从而稳定网络梯度流; GELU的最小值为-0.21,值域为[ − 0.21 , + ∞ ] 上界是任何激活函数都需要的特征,因为这样可以避免导致训练速度急剧下降的梯度饱和,因此加快训练过程。无下界有助于实现强正则化效果; 梯度不容易造成梯度爆炸和梯度消失。 光滑性:光滑的激活函数有较好的泛化能力和稳定的优化能力,可以提高模型的性能。 * LN:LayerNorm. channel方向做归一化,算CHW的均值,主要对RNN作用明显。-
第 l 层特征定义为:

先用MSA着重观察某一部分获取特征,再用MLP进行特征打分(真假概率)。
最终的假概率:

-
5.实验
-
训练数据集:
FaceForensics++(FF++)假视频制作方法:
Face2Face(F2F), FaceSwap(FS), NeuralTex-ture(NT), and Deepfake(DF). -
测试数据集:
FF++ ; FaceShifter;DeeperForensics;DeepFake De-tection Challenge Preview dataset(DFDC);Celeb-DF-v2(CDF). -
评估指标:AUC。
-
实验设置:self-attention heads, hidden size, and MLP size are set to 12,1024, 2048。
batch size of 32 ,
SGD optimizer with momentum。
the weight decay is set as 1e-4.
-
实验过程: the learning rate first increases from 0.01 to 0.1 in the first 10 epochs ,
and then cosinely decayed to 0 for the last 90 epochs.
(在前10个时间段内,学习率首先从0.01增加到0.1,然后在最后90个时间段以余弦方式衰减到0。)
6.结果
table2:在不同方法生成的假脸上对比。
table3:和最先进的检测方法对比。
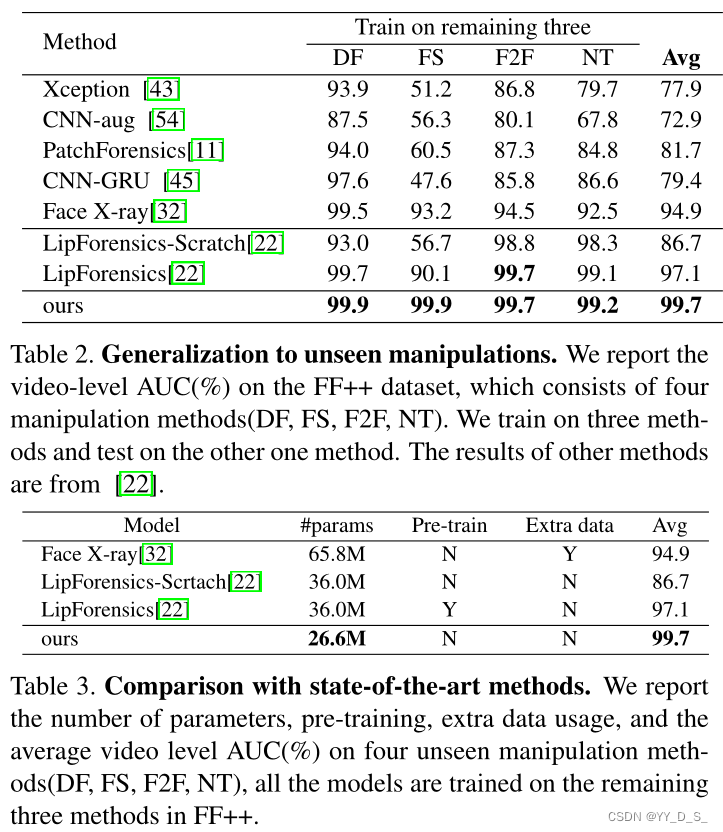
#params:参数数量,越小性能越好,处理越快。
结论:泛化好+最少的参数实现了最高的性能+没有任何预训练或外部训练数据。
-
验证robustness
考虑四种常见的扰动:1)块态畸变;2) 颜色饱和度的变化;3) 高斯模糊;4) 调整大小:按系数对图像进行降采样,然后将其升采样到原始分辨率。
并将每个扰动分为五个强度级别。扰动在不同数据集上的平均结果如下:

结论:robustness好。
7.综合分析和改善
-
无法同时兼顾时空














 2167
2167











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









