






系列文章目录
情感分析入门 1-Simple Sentiment Analysis
前言
在上一节 1-Simple Sentiment Analysis中,我们利用简单的RNN完成了情感分析的大体流程:数据准备-模型搭建-模型训练及预测。这一节,我们将在上述基础上进行优化。
我们将用到:
- packed padded sequences
- pre-trained word embeddings
- different RNN architecture: bidirectional RNN, multi-layer RNN
- regulization
- a different optimizer
一、Preparing Data
数据准备的流程和上一节几乎一样。因为同一batch中时序信息的长度通常是不同的,所以我们会按照某一指定长度对其进行填充(pad)或截断。这一节改进点之一在于,我们使用了 packed padded sequences,这使得我们的RNN能只处理序列中的non-padded元素,而对于padded元素的输出为0。
为了使用padded packed sequences,我们需要设置 include_lengths=True,来告诉RNN实际句子的长度。这使得batch.text现在成为了一个元组:(句子,实际句子长度)
import torch
from torchtext.legacy import data
SEED = 1234
torch.manual_seed(SEED)
torch.backends.cudnn.deterministic = True
#分词
TEXT = data.Field(tokenize = 'spacy',
tokenizer_language = 'en_core_web_sm',
include_lengths = True)
LABEL = data.LabelField(dtype = torch.float)
#load the IDMB dataset
from torchtext.legacy import datasets
train_data, test_data = datasets.IMDB.splits(TEXT, LABEL)
import random
train_data, valid_data = train_data.split(random_state = random.seed(SEED))接下来是pre-trained word embedding的使用。我们用到的是"glove.6B.100d"vectors。经过预训练的词向量已经可以让有相似情绪语义的单词在向量空间的距离更近。(The theory is that these pre-trained vectors already have words with similar semantic meaning close together in vector space, e.g. "terrible", "awful", "dreadful" are nearby)
Totchtext默认会把在你的词汇表中,但是没有在预训练embedding中的单词初始化为0。所以这里我们通过把unk_int设置为torch.Tensor.normal_来用高斯分布初始化这些单词。
MAX_VOCAB_SIZE = 25_000
#embedding
TEXT.build_vocab(train_data,
max_size = MAX_VOCAB_SIZE,
vectors = "glove.6B.100d",
unk_init = torch.Tensor.normal_)
LABEL.build_vocab(train_data)另外,packed padded sequences一个batch中的所有tensors需要按照长度排序。(sort_within_batch = True) 默认条件下,我们必须把输入数据按照序列长度从大到小排列后才能送入 pack_padded_sequence ,否则会报错。
BATCH_SIZE = 64
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
train_iterator, valid_iterator, test_iterator = data.BucketIterator.splits(
(train_data, valid_data, test_data),
batch_size = BATCH_SIZE,
sort_within_batch = True,
device = device)二、Build the Model
模型特点的变化是最剧烈的。
LSTM通过引入一个额外的recurrent state-记忆单元c,来overcome RNN梯度消失的问题.并且使用多个gates(门)来控制信息的流入和流出。
代码如下(示例):
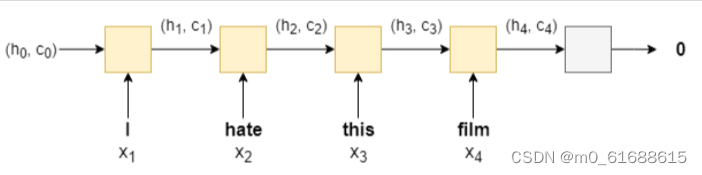
-
Bidirectional RNN
我们使用 forward RNN 从前往后处理句子中单词的同时,使用backward RNN从后往前处理单词。在Pytorch中,由前向RNN和后向RNN返回的hidden state(and cell state)在单个张量中相互堆叠。
我们使用前向RNN最后的hidden state 和后向RNN最后的hidden state
拼接,来做情感预测。
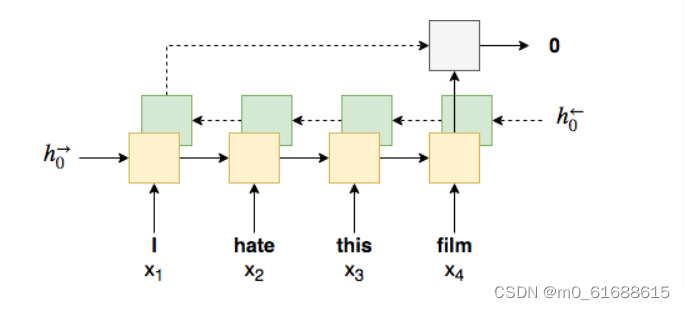
-
Multi-layer RNN
We add additional RNNs on top of the initial standard RNN, The hidden state output by the first (bottom) RNN at time-step t will be the input to the RNN above it at time step t.
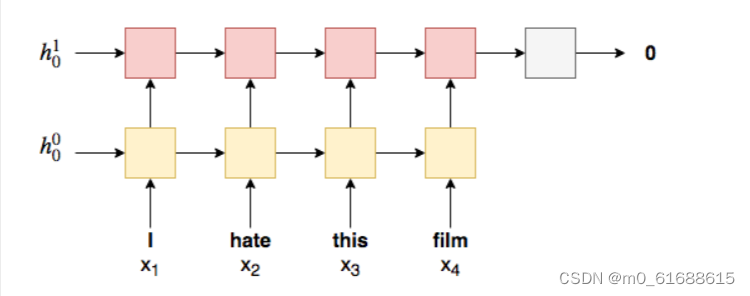
-
Regularization
我们使用正则化来过拟合。具体来说,我们使用了dropout的正则化方法。一个关于为什么dropout有效的理论是,a model with parameters dropped out can be seen as a "weaker" (less parameters) model。所有来自这些“较弱”模型的预测(每个正向传递一个)在模型的参数中被平均在一起。 Thus, your one model can be thought of as an ensemble of weaker models, none of which are over-parameterized and thus should not overfit.
-
Implementation Details
我们不需要再学习 unk token的embedding。因为我们明确告知了我们的模型,padding tokens和句子情感的预测是无关的。我们实现方式是,把padding_idx传入nn.Embedding。
我们使用nn.LSTM而不是nn.RNN。LSTM返回output 和 the final hidden,以及the final cell state。并且LSTM的 final hidden state has both a forward and a backward component, which will be concatenated together。The size of the input to the nn.Linear layer is twice that of the hidden dimension size。
注意:never use dropout on the input or output layers。LSTM的dropout,在一层的隐藏状态与下一层的隐藏状态之间的连接上添加dropout。(竖直方向上,而不是时间方向)
因为在填充(pad)过程中产生了冗余,所以需要对其进行pack(压紧)。pack_padded_sequence 是 PyTorch 中用于处理填充序列的函数。它可以将填充的序列压缩成一个不包含填充部分的有序序列,并且还可以返回原始序列中每个元素的长度。这样可以在计算损失或进行其他操作时节省空间和计算时间。下面我们具体说明,为什么要使用这个函数。
RNN 读取数据的方式:网络每次吃进去一组同样时间步 (time step) 的数据,也就是 mini-batch 的所有样本中下标相同的数据,然后获得一个 mini-batch 的输出;再移到下一个时间步 (time step),再读入 mini-batch 中所有该时间步的数据,再输出;直到处理完所有的时间步数据。
第一个时间步:

第二个时间步:

mini-batch 中的 0 只是用来做数据对齐的 padding_value ,如果进行 forward 计算时,把 padding_value 也考虑进去,可能会导致RNN通过了非常多无用的 padding_value,这样不仅浪费计算资源,最后得到的值可能还会存在误差。
为了使 RNN 可以高效的读取数据进行训练,就需要在 pad 之后再使用 pack_padded_sequence 对数据进行处理。我们在pack过程中按列进行pack,而不是按行进行pack。

RNN 会返回 packed_output (a packed sequence) 以及 the hidden and cell states (both of which are tensors). Without packed padded sequences, hidden and cell are tensors from the last element in the sequence, which will most probably be a pad token, however when using packed padded sequences they are both from the last non-padded element in the sequence.
注意packed_padded_sequence的参数 lengths如果输入为张量形式,则必须在CPU上.to('cpu')
The final hidden state 的形状是[num layers*num directions,batch size,hid dim],即 [forward_layer_0, backward_layer_0, forward_layer_1, backward_layer 1, ..., forward_layer_n, backward_layer n].我们想要the final (top) layer forward and backward hidden states, 从第一维取得:hidden[-2,:,:] and hidden[-1,:,:], 并将其通过dropout后传入线性层.
import torch.nn as nn
class RNN(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim, output_dim, n_layers,
bidirectional, dropout, pad_idx):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim, padding_idx = pad_idx)
#num_layers: add addtional layers;bidirectional: implement bidirectionality
self.rnn = nn.LSTM(embedding_dim,
hidden_dim,
num_layers=n_layers,
bidirectional=bidirectional,
dropout=dropout)
self.fc = nn.Linear(hidden_dim * 2, output_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, text, text_lengths):
#text = [sent len, batch size]
embedded = self.dropout(self.embedding(text))
#embedded = [sent len, batch size, emb dim]
#pack sequence
# lengths need to be on CPU!
packed_embedded = nn.utils.rnn.pack_padded_sequence(embedded, text_lengths.to('cpu'))
packed_output, (hidden, cell) = self.rnn(packed_embedded)
#unpack sequence:transform it from a paced sequence to a tensor
#output, output_lengths = nn.utils.rnn.pad_packed_sequence(packed_output)
#output = [sent len, batch size, hid dim * num directions]
#output over padding tokens are zero tensors
#hidden = [num layers * num directions, batch size, hid dim]
#cell = [num layers * num directions, batch size, hid dim]
#concat the final forward (hidden[-2,:,:]) and backward (hidden[-1,:,:]) hidden layers
#and apply dropout
hidden = self.dropout(torch.cat((hidden[-2,:,:], hidden[-1,:,:]), dim = 1))
#hidden = [batch size, hid dim * num directions]
return self.fc(hidden)
我们从词汇表中,获取pad token的索引,从field's pad_token属性得到表示pad_token的实际字符串。
#RNN实例化
INPUT_DIM = len(TEXT.vocab)
#the EMBEDDING_DIM must be equal to that of the pre-trained GloVe vectors
EMBEDDING_DIM = 100
HIDDEN_DIM = 256
OUTPUT_DIM = 1
N_LAYERS = 2
BIDIRECTIONAL = True
DROPOUT = 0.5
PAD_IDX = TEXT.vocab.stoi[TEXT.pad_token]
model = RNN(INPUT_DIM,
EMBEDDING_DIM,
HIDDEN_DIM,
OUTPUT_DIM,
N_LAYERS,
BIDIRECTIONAL,
DROPOUT,
PAD_IDX)We retrieve the embeddings from the field's vocab, and check they're the correct size, [vocab size, embedding dim]
pretrained_embeddings = TEXT.vocab.vectors
print(pretrained_embeddings.shape)我们将embedding层的初始权重替换为pre-trained embeddings.
model.embedding.weight.data.copy_(pretrained_embeddings)我们需要把 unk_init全部初始化为0,来明确告知模型他们和情绪预测无关。
我们通过tokens的索引找到其所在的行,并把他们在embedding weight matrix中设置为0.
UNK_IDX = TEXT.vocab.stoi[TEXT.unk_token]
model.embedding.weight.data[UNK_IDX] = torch.zeros(EMBEDDING_DIM)
model.embedding.weight.data[PAD_IDX] = torch.zeros(EMBEDDING_DIM)
print(model.embedding.weight.data) We can now see the first two rows of the embedding weights matrix have been set to zeros. As we passed the index of the pad token to the padding_idx of the embedding layer it will remain zeros throughout training, however the token embedding will be learned.
三、Train the model
我们把SGD换为了Adam. SGD updates all parameters with the same learning rate and choosing this learning rate can be tricky. Adam adapts the learning rate for each parameter, giving parameters that are updated more frequently lower learning rates and parameters that are updated infrequently higher learning rates.
import torch.optim as optim
optimizer = optim.Adam(model.parameters())
criterion = nn.BCEWithLogitsLoss()
model = model.to(device)
criterion = criterion.to(device)
def binary_accuracy(preds, y):
"""
Returns accuracy per batch, i.e. if you get 8/10 right, this returns 0.8, NOT 8
"""
#round predictions to the closest integer
rounded_preds = torch.round(torch.sigmoid(preds))
correct = (rounded_preds == y).float() #convert into float for division
acc = correct.sum() / len(correct)
return accAs we have set include_lengths = True, our batch.text is now a tuple with the first element being the numericalized tensor and the second element being the actual lengths of each sequence. We separate these into their own variables, text and text_lengths, before passing them to the model.
def train(model, iterator, optimizer, criterion):
epoch_loss = 0
epoch_acc = 0
#turn on the dropout
model.train()
for batch in iterator:
optimizer.zero_grad()
text, text_lengths = batch.text
predictions = model(text, text_lengths).squeeze(1)
loss = criterion(predictions, batch.label)
acc = binary_accuracy(predictions, batch.label)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
epoch_acc += acc.item()
return epoch_loss / len(iterator), epoch_acc / len(iterator)#tell us how long our epochs are taking
import time
def epoch_time(start_time, end_time):
elapsed_time = end_time - start_time
elapsed_mins = int(elapsed_time / 60)
elapsed_secs = int(elapsed_time - (elapsed_mins * 60))
return elapsed_mins, elapsed_secsN_EPOCHS = 5
best_valid_loss = float('inf')
for epoch in range(N_EPOCHS):
start_time = time.time()
train_loss, train_acc = train(model, train_iterator, optimizer, criterion)
valid_loss, valid_acc = evaluate(model, valid_iterator, criterion)
end_time = time.time()
epoch_mins, epoch_secs = epoch_time(start_time, end_time)
if valid_loss < best_valid_loss:
best_valid_loss = valid_loss
torch.save(model.state_dict(), 'tut2-model.pt')
print(f'Epoch: {epoch+1:02} | Epoch Time: {epoch_mins}m {epoch_secs}s')
print(f'\tTrain Loss: {train_loss:.3f} | Train Acc: {train_acc*100:.2f}%')
print(f'\t Val. Loss: {valid_loss:.3f} | Val. Acc: {valid_acc*100:.2f}%')model.load_state_dict(torch.load('tut2-model.pt'))
test_loss, test_acc = evaluate(model, test_iterator, criterion)
print(f'Test Loss: {test_loss:.3f} | Test Acc: {test_acc*100:.2f}%')四、User Input
我们的predict_sentiment函数做了如下事情:
- 分词:tokenizes the sentence,i.e. splits it from a raw string into a list of tokens
- 构建分词在词汇表中的索引:indexed the tokens by converting them into their integer representation from vocabulary
- squashes the output prediction from the real number between 0 and 1 with the sigmoid function
- converts the tensor into an integer
import spacy
nlp = spacy.load('en_core_web_sm')
def predict_sentiment(model, sentence):
model.eval()
tokenized = [tok.text for tok in nlp.tokenizer(sentence)]
#indexes the tokens by converting them into their integer representation from our vocabulary
indexed = [TEXT.vocab.stoi[t] for t in tokenized]
#gets the length of our sequence
length = [len(indexed)]
length_tensor = torch.LongTensor(length)
tensor = torch.LongTensor(indexed).to(device)
tensor = tensor.unsqueeze(1)
prediction = torch.sigmoid(model(tensor, length_tensor))
#converts the tensor holding a single value into an integer with the item() method
return prediction.item()
#predict_sentiment(model, "This film is terrible")
#predict_sentiment(model, "This film is great")
















 383
383

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









