



根据PPL两种不同的计算公式,有两种不同的代码实现。
实现一:使用perplexity的对数形式:将每个位置上的概率取对数再平均
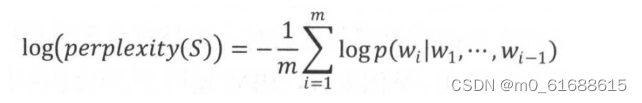
# 定义计算PPL的函数
def calculate_ppl(model, conversations):
total_loss = 0
for conversation in conversations:
with torch.no_grad():
# 计算对话的概率分布
outputs = model(input_ids=input_ids, labels=target_ids)
logits = outputs.logits
loss = CrossEntropyLoss(reduction='sum')(logits.view(-1, logits.shape[-1]), target_ids.view(-1))
total_loss += loss.item()
avg_loss = total_loss / len(conversations)
ppl = torch.exp(avg_loss)
实现二:
针对文本中的词预测任务来说,离散概率分布p的困惑度由下式给出,其中H(p) 是该分布的熵,x遍历事件空间。概率分布的perplexity:
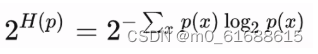
代码:
#nn.NLLLoss负对数似然函数作为损失函数
self.criterion_ppl = nn.NLLLoss(ignore_index=config.PAD_idx)
loss = self.criterion_ppl(
logit.contiguous().view(-1, logit.size(-1)),
dec_batch.contiguous().view(-1),
)
ppl = math.exp(min(loss.item(), 100))

















 3612
3612

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









