







论文
- 名称:《AUTODAN: GENERATING STEALTHY JAILBREAKPROMPTS ON ALIGNED LARGE LANGUAGE MODELS》
- 论文地址:https://arxiv.org/pdf/2310.04451.pdf
- 代码地址:https://github.com/SheltonLiu-N/AutoDAN
要解决的问题与创新点
- 可扩展性问题,Prompt工程主要依赖于人工提示词工程。
- 如何生成隐形具备意义的Prompt的问题,类似很多现有的Prompt自动生成算法,生成的结果是无意义的Prompt(可以参考GCG生成后缀的算法,大部分是无意义的符号),很容易被困惑度测试检测出来。
- 适应性问题,人工构造的Prompt在新的LLM上不一定有很好的攻击效果,重新构造的成本是非常高的,因此是否能开发出自动生成隐式的Prompt来进行jailbreak攻击。
解决思路
要点分析:
-
应用遗传算法等优化算法。这是因为 jailbreak Prompt中的单词与损失函数中的梯度信息没有直接相关性,这使得在连续空间中使用类似反向传播的对抗性示例或利用梯度信息来指导生成具有挑战性。
-
LLM 用户识别的现有Prompt可以有效地用作初始化遗传算法种群的原型,大大减少了搜索空间。这使得遗传算法在有限迭代期间在离散空间中找到合适的破损提示是可行的。
具体思路:
-
准备工作:
目标是引导LLM进行肯定回答。
-
一些符号定义:
Questions Jailbreak prompts Resulting in a combined input set Responses Tokens Outputs of LLM -
公式整理:
LLM通过估计下一个Token的概率来生成 Jailbreak的攻击目标是提示LLM生成从特定单词开始的输出(比如Sure,这里是如何[Q]),目标是最大化概率
适应度函数 Softmax函数确定选择的概率 -
遗传算法(GA)与分层遗传算法(HGA)
遗传算法的算法原理如下:

- 初始化种群
基于现有的Prompt去做设计,防止偏离太远造成不能求解的情况。保证初始种群的多样性,尽可能含有多样的特征。
- 适应度函数
衡量数据分布。对概率进行了对数似然。
- 交叉变异(HGA主要是对这里进行了改进)
由于文本数据是分层结构的,通常语义上是有逻辑结构和逻辑关系的(比如在词、句子、段落之间的逻辑关系都是存在差异的),因此在保障语义不变的情况下分别改变词(比如同义词替换)、句子(比如用GPT进行句子的改写)、段落级别上句子的不同组合(不同模板加不同的Prompt),来构造不同层次结构上的交叉和变异。具体的可以参考算法流程:

然后是交叉点,交叉点看代码应该是进行了分词,然后把分词点记录下来,通过索引的方式直接获取。GA和HGA部分的代码,主要在源代码的opt_utils.py文件。
实验结果
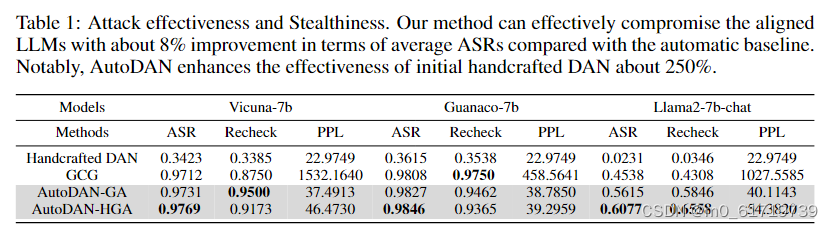
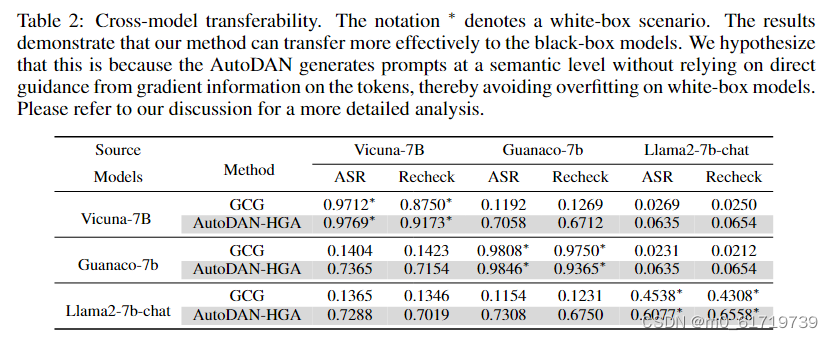
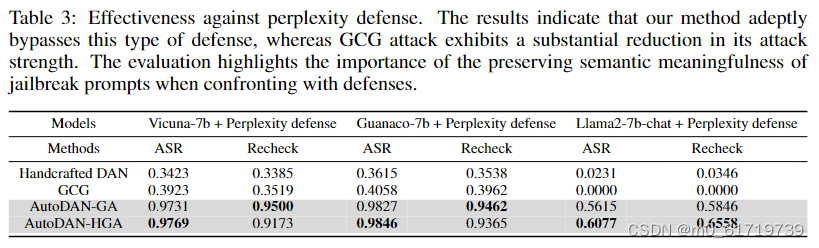


博主的理解和能力都存在局限性,如果大家发现了错误或者想探讨的可以随时与博主联系!!!!非常感谢大家读到文末!!!!!!!!!!!















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









