







1 instruction tuning & in context learning
| 论文名称 | 来源 | 主要内容 |
| Finetuned Language Models Are Zero-Shot Learners | 2021 | 机器学习笔记:李宏毅ChatGPT Finetune VS Prompt_UQI-LIUWJ的博客-CSDN博客 早期做instruction tuning的work |
| MetaICL: Learning to Learn In Context | 2021 | 机器学习笔记:李宏毅ChatGPT Finetune VS Prompt_UQI-LIUWJ的博客-CSDN博客 in-context learning都是没有finetune过程,这里相当于finetune了一下 |
| Rethinking the Role of Demonstrations: What Makes In-Context Learning Work? | 2023 | 机器学习笔记:李宏毅ChatGPT Finetune VS Prompt_UQI-LIUWJ的博客-CSDN博客 在in-context learning的时候,故意给一些错误的例子、其他领域的返利,看看大模型的效果 ——>这篇论文的结论是,in-context learning只起到“唤醒”的作用,LLM本身就具备了所需要的功能。这里给LLM范例的作用只是提示LLM要做这个任务了 |
| Larger language models do in-context learning differently | 2023 | 机器学习笔记:李宏毅ChatGPT Finetune VS Prompt_UQI-LIUWJ的博客-CSDN博客 在更大的LLM中,in context learning 确实也起到了让模型学习的作用 |
2 Chain of Thought
| 论文名称 | 来源 | 主要内容 |
| Chain-of-Thought Prompting Elicits Reasoning in Large Language Models | 2022 |
|
| Large Language Models are Zero-Shot Reasoners | 2022 | 在进行CoT的时候,范例输完了,需要模型回答的问题说完了,加一行’Let's think step by step',可以获得更好的效果 |
3 others
| 论文略读:Onthe Expressivity Role of LayerNorm in Transformers’ Attention-CSDN博客 | ACL 2023 | LayerNorm为Transformer的Attention提供了两个重要的功能:
|
| 论文笔记:Frozen Language Model Helps ECG Zero-Shot Learning_冻结语言模型帮助心电图零样本学习-CSDN博客 | 2023 MIDL | 利用临床报告来引导ECG数据的预训练,实现ECG数据的零样本学习
|
| Is ChatGPT A Good Translator? A Preliminary Study | 2023 |
专项翻译任务上,ChatGPT不如一些专门做翻译的模型 |
| 论文笔记:Evaluating the Performance of Large Language Models on GAOKAO Benchmark-CSDN博客 | 测评gpt在高考各科(文理)上得分的异同 | |
| How Good Are GPT Models at Machine Translation? A Comprehensive Evaluation | 2023 |
专项翻译任务上,ChatGPT不如一些专门做翻译的模型 |
| 论文笔记:Can Large Language Models Beat Wall Street? Unveiling the Potential of AI in Stock Selection-CSDN博客 | 202401 arxiv | 提出了 MarketSenseAI,整合了多种数据来源,包括实时市场动态、财经新闻、公司基本面和宏观经济指标,利用GPT-4生成全面的投资建议
|
| 论文笔记:Lost in the Middle: How Language Models Use Long Contexts_lost in the middle人工智能-CSDN博客 | Transactions of the Association for Computational Linguistics 2024 |
|
| 论文笔记:FROZEN TRANSFORMERS IN LANGUAGE MODELSARE EFFECTIVE VISUAL ENCODER LAYERS-CSDN博客 | iclr 2024 spotlight reviewer 评分 6668 |  |
| ReLU Strikes Back: Exploiting Activation Sparsity in Large Language Models-CSDN博客 | iclr 2024 oral reviewer 评分 688 | 目前LLM社区中通常使用GELU和SiLU来作为替代激活函数,它们在某些情况下可以提高LLM的预测准确率 但从节省模型计算量的角度考虑,论文认为经典的ReLU函数对模型收敛和性能的影响可以忽略不计,同时可以显着减少计算和权重IO量\ |
| 论文笔记:The Reversal Curse: LLMs trained on “A is B” fail to learn “B is A”-CSDN博客 | iclr 2024 reviewer 评分668 |
|
| 论文笔记:The Expressive Power of Transformers with Chain of Thought-CSDN博客 | ICLR 2024 reviewer 评分 6888 | 论文描述在生成答案前采取中间步骤的Transformer解码器的推理能力,并将其与没有中间步骤的Transformer进行比较 |
| 论文笔记:BooookScore: A systematic exploration of book-length summarization in the era of LLMs-CSDN博客 | iclr oral reviewer 评分 88810 |
|
| 论文略读:LLMCarbon: Modeling the End-to-End Carbon Footprint of Large Language Models-CSDN博客 | iclr 2024 oral reviewer 评分 556810 | 论文提出了一个端到端的碳足迹预测模型LLMCarbon
|
| 论文略读:Memorization Capacity of Multi-Head Attention in Transformers-CSDN博客 | iclr spotlight reviewer评分 6888 | 论文研究了一个具有H个头的单层多头注意力(MHA)模块的记忆容量 |
| 论文略读:EDT: Improving Large Language Models’ Generation by Entropy-based Dynamic Temperature Sampling-CSDN博客 | 南大 2024年3月的work |
|
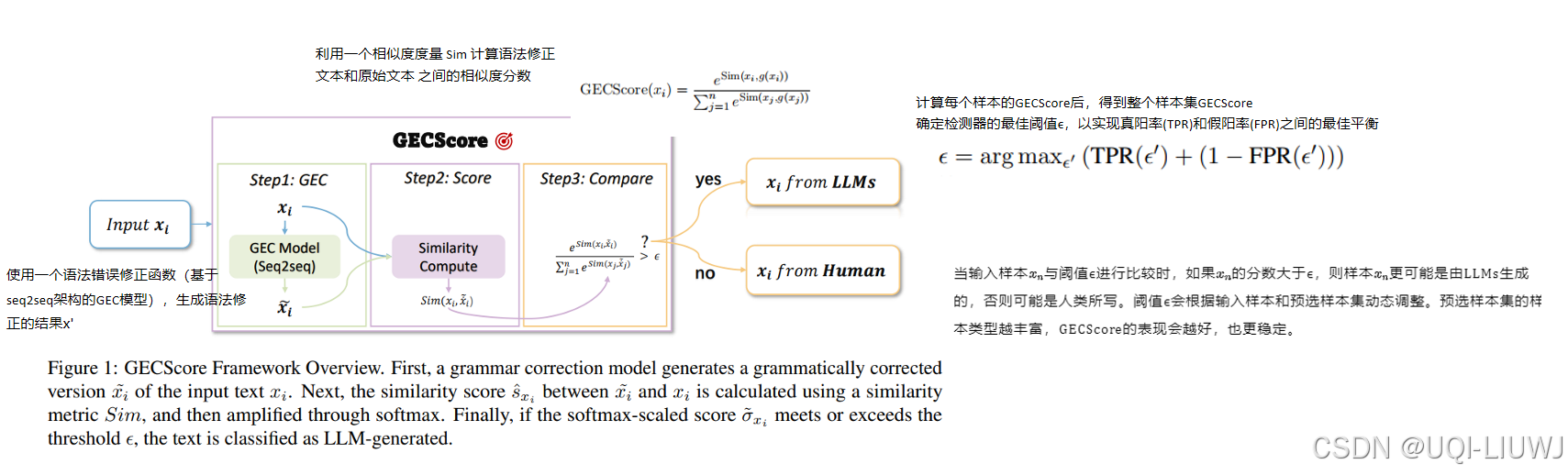
| 论文略读:Who Wrote This? The Key to Zero-Shot LLM-Generated Text Detection Is GECScore-CSDN博客 | arxiv 202405 | 人类在写作时比语言模型更容易犯语法错误
|
| 论文笔记:Does Writing with Language Models Reduce Content Diversity?-CSDN博客 | iclr 2024 reviewer评分 566 | 同质化:使用LLM写作的用户彼此写得是否更相似? |
| 论文略读Fewer Truncations Improve Language Modeling-CSDN博客 | icml 2024 | 在传统LLM训练过程中,为了提高效率,通常会将多个输入文档拼接在一起,然后将这些拼接的文档分割成固定长度的序列。 论文提出了最佳适配打包 (Best-fit Packing)
|
| 论文略读: LLaMA Pro: Progressive LLaMA with Block Expansion-CSDN博客 | 提出了一种用于LLMs的新的预训练后方法
| |
| 论文略读:Can Long-Context Language Models Subsume Retrieval, RAG, SQL, and More?-CSDN博客 | 论文提出了LOFT(Long-Context Frontiers)基准测试,全面测试长上下文模型的能力 | |
| 论文略读: Scaling laws with vocabulary: larger model deserve larger vocabularies-CSDN博客 | 更大的模型应该配备更大的词表,且在给定算力的情况下,最优的词表大小是有上限的 | |
| 论文略读: TransTab: Learning Transferable Tabular Transformers Across Tables-CSDN博客 | 2022 neurips |
|
| 论文笔记:Are we there yet? Revealing the risks of utilizing large language models in scholarly peer revi-CSDN博客 | 202412 arxiv | 大语言模型在审稿中存在各种潜藏的风险 |





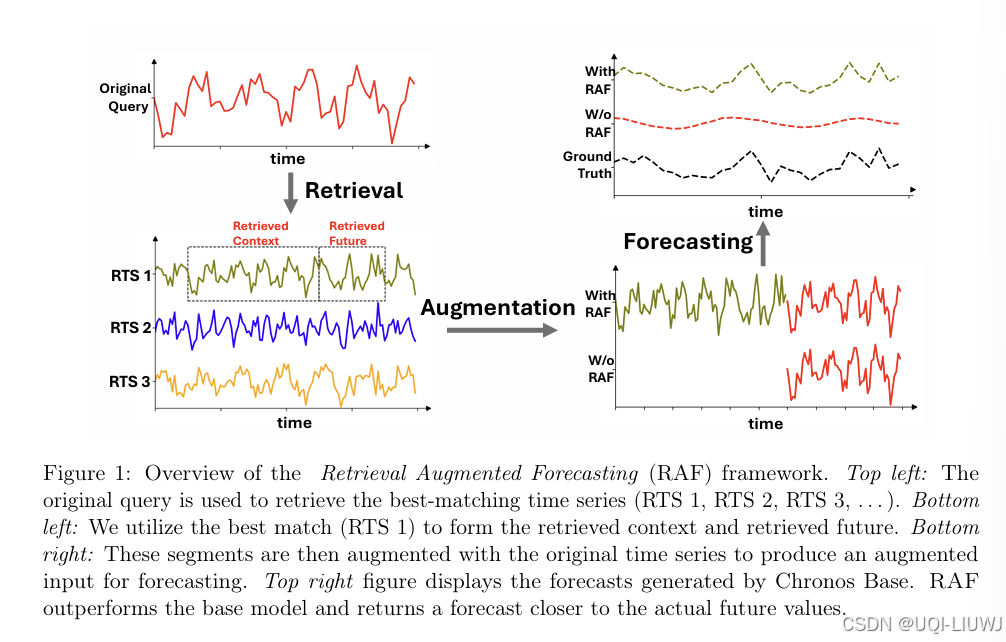
4 大模型+时间序列











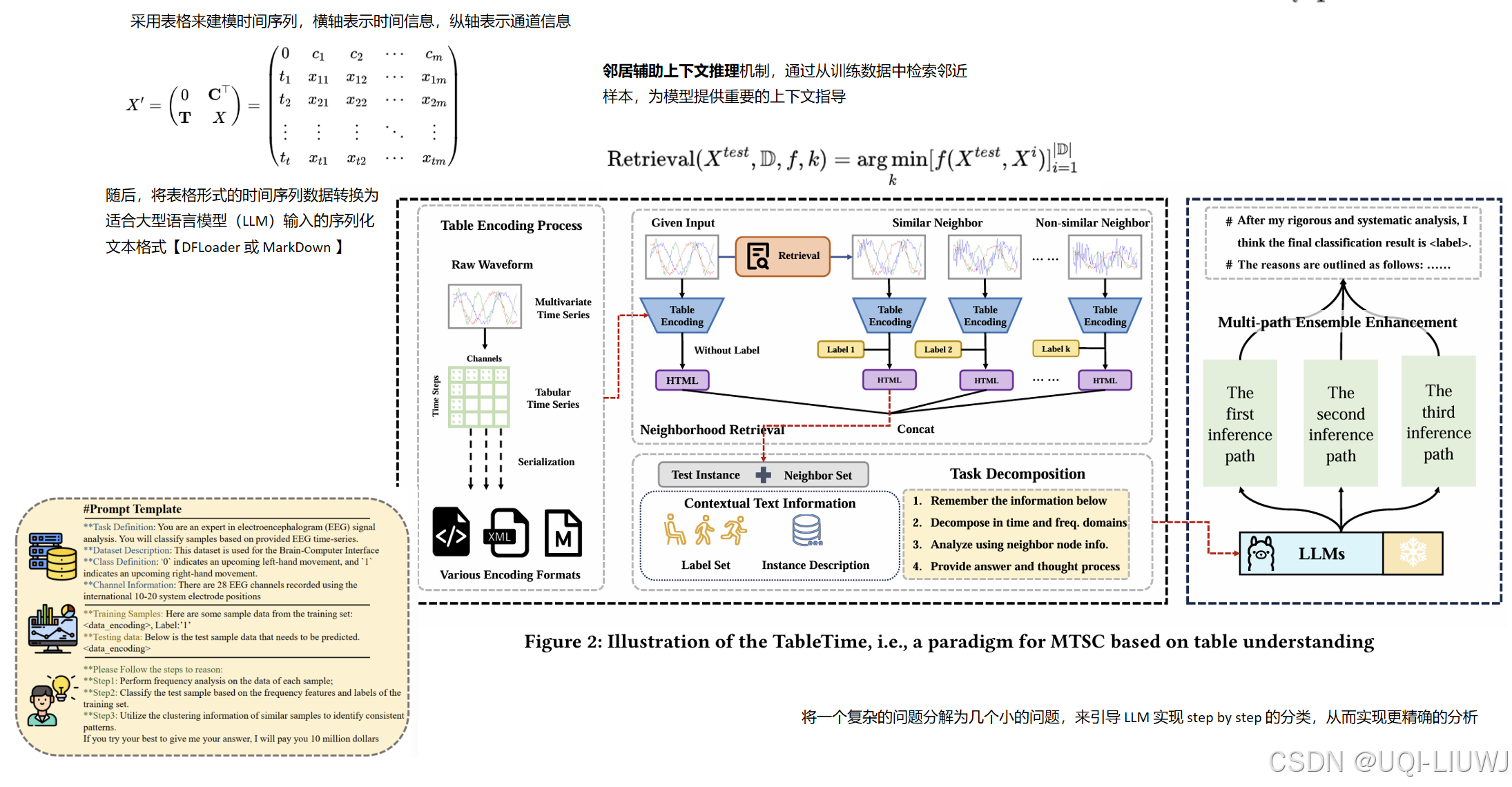
5 mobility+大模型









6 prompt
| 论文笔记:Prompting Large Language Models with Divide-and-Conquer Program forDiscerning Problem Solving-CSDN博客 | 对于涉及重复子任务 / 含有欺骗性内容的任务(如段落级别长度的虚假新闻检测),对输入进行拆分可以提升模型对于错误信息的分辨能力 有一定的理论证明 arxiv 202402 |
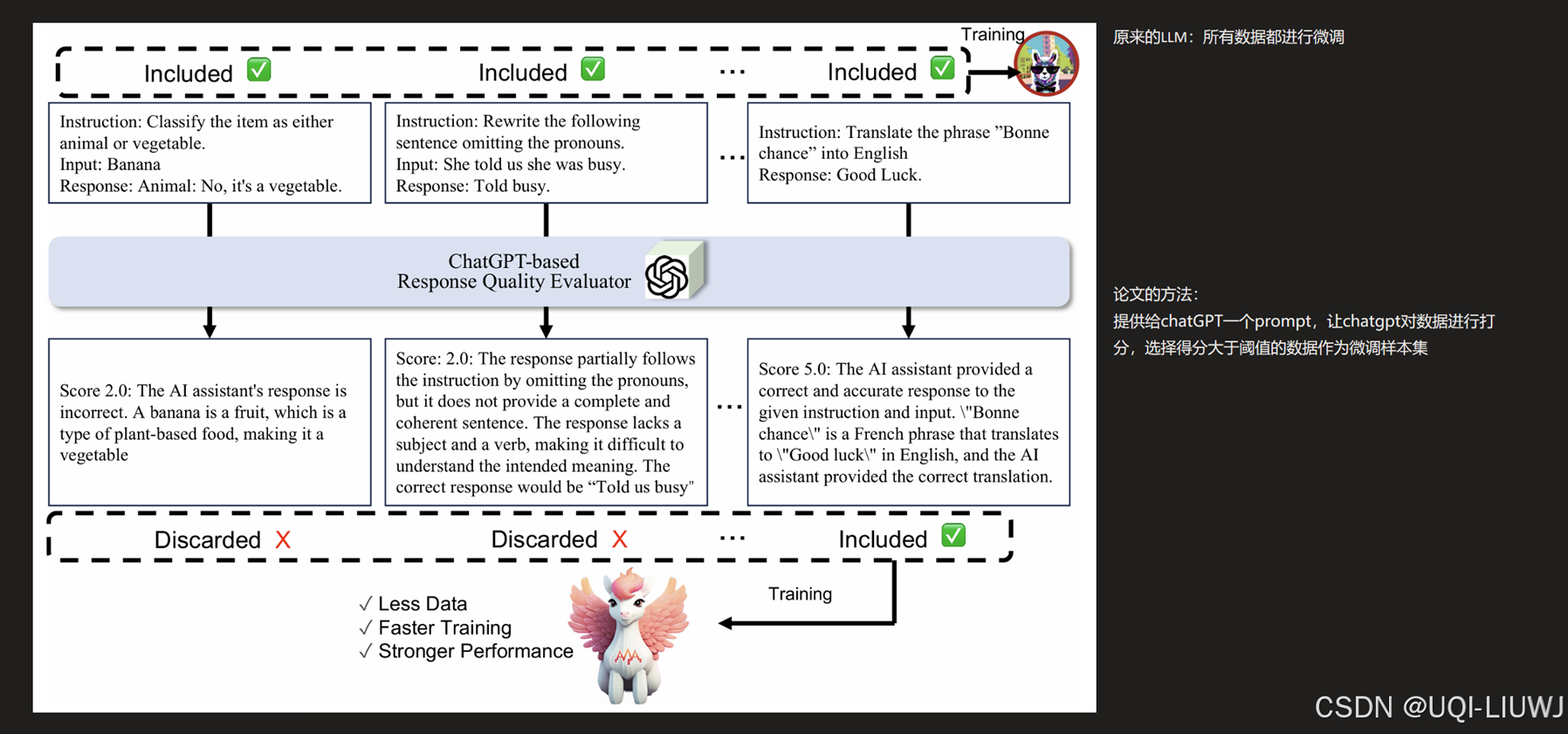
| 论文略读: ALPAGASUS: TRAINING A BETTER ALPACA WITH FEWER DATA-CSDN博客 | ICLR 2024 论文提出了一种简单有效的数据选择策略,使用ChatGPT自动识别和过滤掉低质量数据 |
| 论文笔记:TALK LIKE A GRAPH: ENCODING GRAPHS FORLARGE LANGUAGE MODELS-CSDN博客 | ICLR 2024,reviewer评分 6666
|
| 论文笔记:ChatEval: Towards Better LLM-based Evaluators through Multi-Agent Debate-CSDN博客 | ICLR 2024 最终评分 55666
论文采用了多agent辩论框架
|
| 论文笔记:Chain-of-Table:EVOLVING TABLES IN THE REASONING CHAIN FOR TABLE UNDERSTANDING-CSDN博客 | ICLR 2024 reviewer评分 5566
提出了CHAIN-OF-TABLE,按步骤进行推理,将逐步表格操作形成一系列表格
|
| 论文笔记:Chain-of-Discussion: A Multi-Model Framework for Complex Evidence-Based Question Answering-CSDN博客 |
|
| 论文笔记:Take a Step Back:Evoking Reasoning via Abstraction in Large Language Models-CSDN博客 | ICLR 2024 reviewer 打分 888 在进行prompt的时候,先后退一步,从更宏观的角度来看问题,让LLM对问题有一个整体的理解;然后再回到detail上,让模型回答更具体的问题
|
| 论文笔记:Can LLMs Express Their Uncertainty? An Empirical Evaluation of Confidence Elicitation in LLMs-CSDN博客 | 不需要微调来激发LLMs置信度表达的方法
|
| 论文笔记:Teaching Large Language Models to Self-Debug-CSDN博客 | ICLR 2024 REVIEWER打分 6666 提出了一种名为 Self-Debugging 的方法,通过执行生成的代码并基于代码和执行结果生成反馈信息,来引导模型进行调试
|
| 论文笔记:Large Language Models as Analogical Reasoners-CSDN博客 | iclr 2024 reviewer打分5558 论文提出一种“归纳学习”的提示方法
|
| 论文笔记:UNDERSTANDING PROMPT ENGINEERINGMAY NOT REQUIRE RETHINKING GENERALIZATION-CSDN博客 | ICLR 2024 reviewer评分 6888 zero-shot prompt 在视觉-语言模型中,已经取得了令人印象深刻的表现
|
| 论文笔记:Are Human-generated Demonstrations Necessary for In-context Learning?-CSDN博客 | iclr 2024 reviewer 评分 6668 >提出了自我反思提示策略(简称 SEC)
|






7 RAG
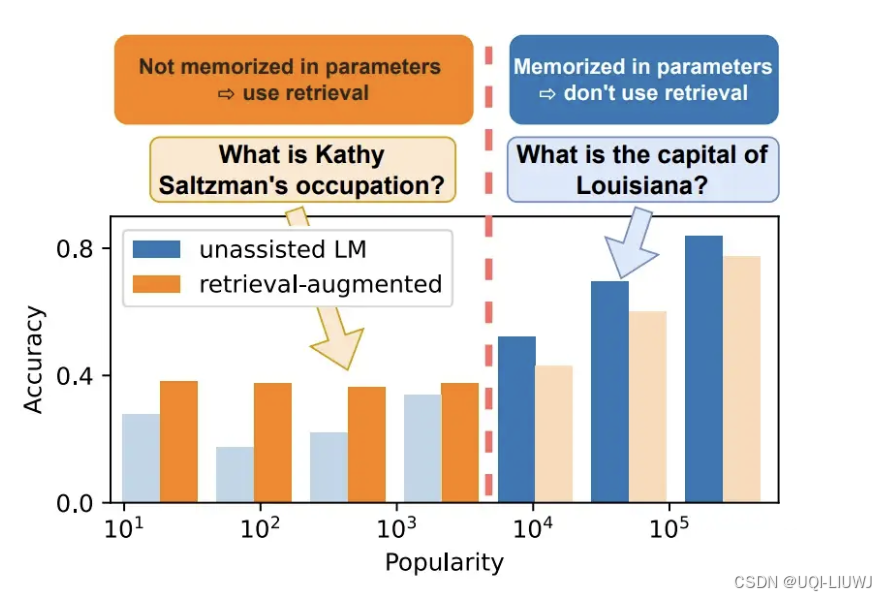

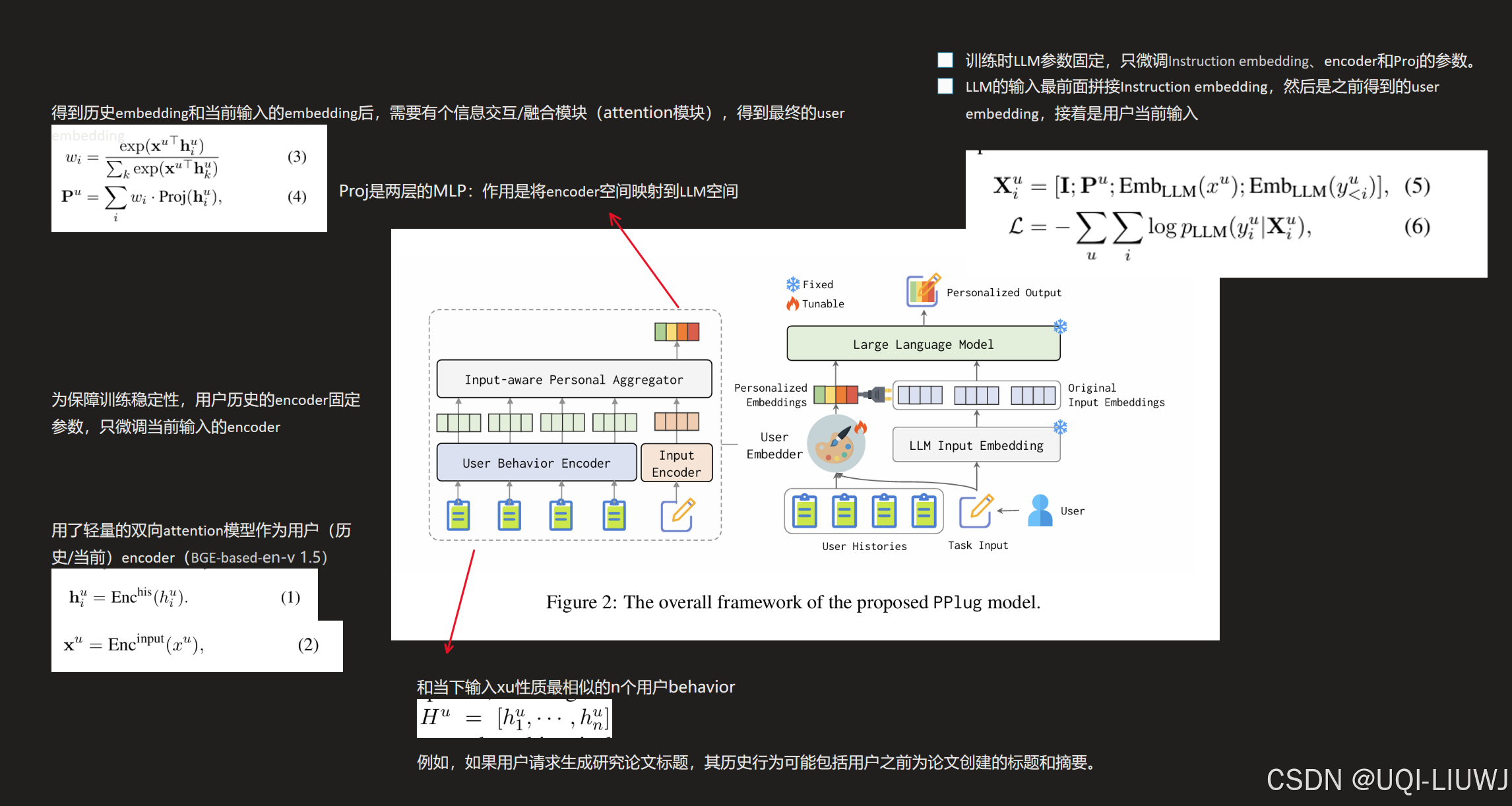
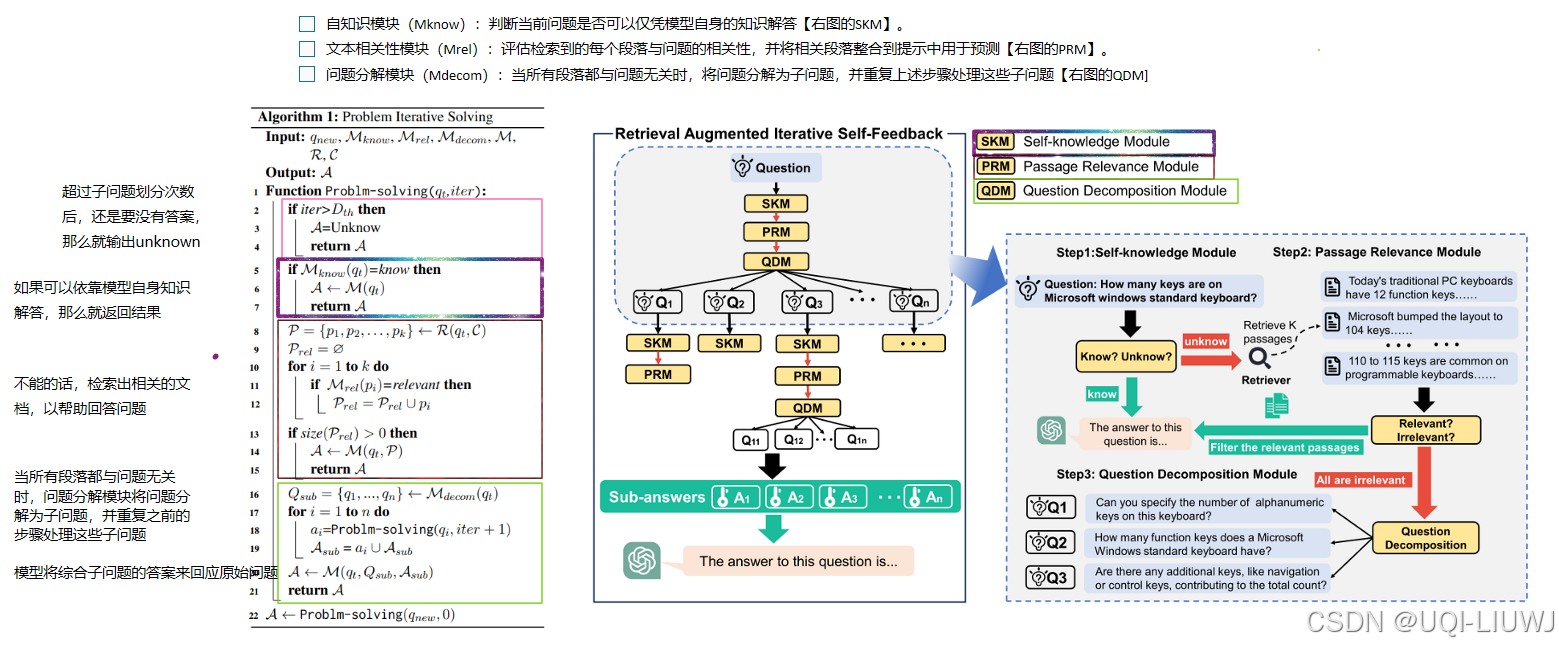
8 finetune
| 论文笔记:GEOLLM: EXTRACTING GEOSPATIALKNOWLEDGE FROM LARGE LANGUAGE MODELS_geollm-base-CSDN博客 | ICLR 2024 reviewer 评分 35668 介绍了GeoLLM,一种新颖的方法
|
| Knowledge Card: Filling LLMs‘ Knowledge Gaps with Plug-in Specialized Language Models-CSDN博客 | ICLR 2024 (oral) reviewer评分 888 提出了KNOWLEDGE CARD |
| 论文笔记:NEFTune: Noisy Embeddings Improve Instruction Finetuning-CSDN博客 | iclr 2024 reviewer 评分 5666 在finetune过程的词向量中引入一些均匀分布的噪声即可明显地提升模型的表现 |
| 论文略读:LoRA Learns Less and Forgets Less-CSDN博客 | LORA相比于全参数训练,学的少,但忘的也少 |
| 论文笔记:LayoutNUWA: Revealing the Hidden Layout Expertise of Large Language Models-CSDN博客 | iclr 2024 reviewer 评分 568 论文提出了LayoutNUWA,这是第一个将布局生成视为代码生成任务的模型,以增强语义信息并利用大型语言模型(LLMs)的隐藏布局专长。
|
| 论文略读:RankRAG: Unifying Context Ranking with Retrieval-Augmented Generation in LLMs-CSDN博客 | 2024 Neurips
|


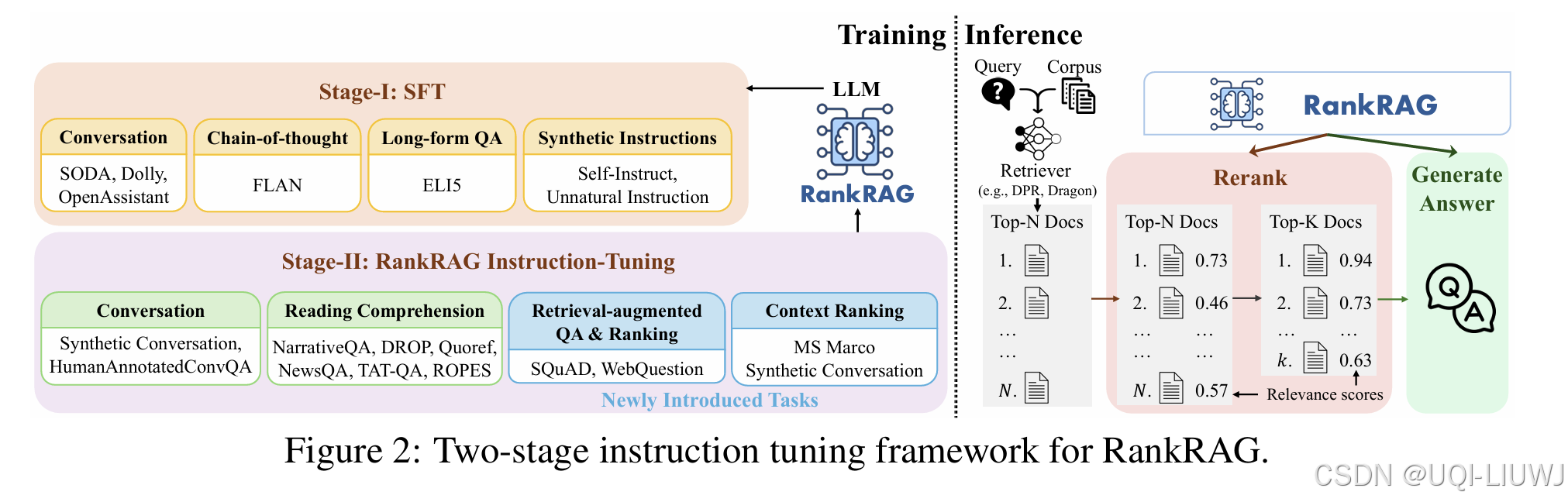
9 安全&隐私



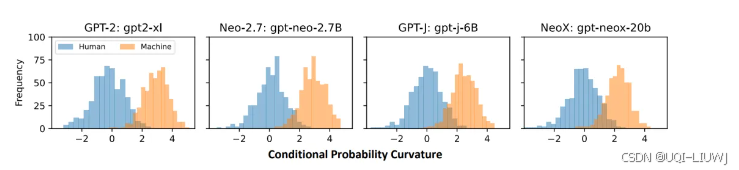


10 benchmark
| 论文笔记/数据集笔记:E-KAR: A Benchmark for Rationalizing Natural Language Analogical Reasoning-CSDN博客 | ACL 2022
|
| 论文略读:MathBench: Evaluating the Theory and Application Proficiency of LLMswith a Hierarchical Mathem_mathbench数据集 中文-CSDN博客 | ACL 2024 findings 数学benchmark,涵盖从小学、初中、高中、大学不同难度,从基础算术题到高阶微积分、统计学、概率论等丰富类别的数学题目 |
| 论文略读:MathScale: Scaling Instruction Tuning for Mathematical Reasoning-CSDN博客 |
|
| 论文笔记:Better to Ask in English: Cross-Lingual Evaluation of Large Language Models for Healthcare Quer-CSDN博客 | WWW 2024
|
| 论文笔记:SmartPlay : A Benchmark for LLMs as Intelligent Agents-CSDN博客 | iclr 2024 reviewer评分 5688
|
| 论文略读:SWE-bench: Can Language Models Resolve Real-world Github Issues?-CSDN博客 | iclr 2024 oral reviewer评分 5668 论文引入了SWE-bench
|
| 论文笔记:(INTHE)WILDCHAT:570K CHATGPT INTERACTION LOGS IN THE WILD-CSDN博客 | iclr 2024 spotlight reviewer 评分 5668 介绍了(INTHE)WILDCHAT数据集
|
| 论文略读:X-VARS: Introducing Explainability in Football Refereeingwith Multi-Modal Large Language Model_soccernet xfoul-CSDN博客 | 用于足球犯规视频识别和解释的数据集
|
11 大模型压缩
| 论文笔记:A Simple and Effective Pruning Approach for Large Language Models-CSDN博客 | iclr 2024 reviewer 评分 5668 引入了一种新颖、简单且有效的剪枝方法,名为Wanda (Pruning by Weights and activations)
|
|
| |

12 大模型+Graph
| 论文略读:OpenGraph: Towards Open Graph Foundation Models-CSDN博客 |  |
| 论文略读:ASurvey of Large Language Models for Graphs_graph2text or graph2token: a perspective of large -CSDN博客 |
|
12.1 graph prompt tuning for 推荐系统
| 论文笔记:GPT4Rec: Graph Prompt Tuning for Streaming Recommendation-CSDN博客 | SIGIR 2024
|
| 论文笔记:Integrating Large Language Models with Graphical Session-Based Recommendation-CSDN博客 |  |

13 efficient ML
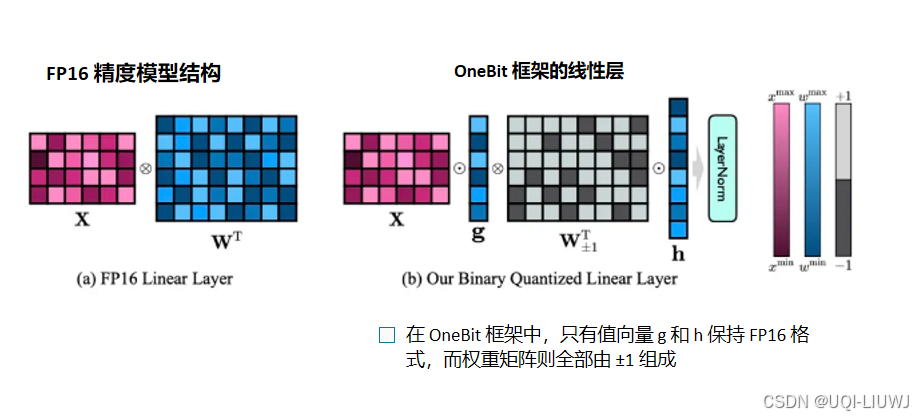
| 论文笔记:OneBit: Towards Extremely Low-bit Large Language Models-CSDN博客 |
论文提出OneBit 框架,包括全新的 1bit 层结构、基于 SVID 的参数初始化方法和基于量化感知知识蒸馏的知识迁移 |
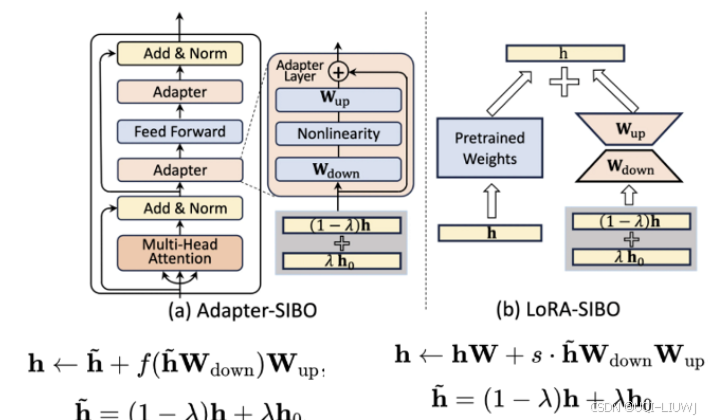
| 论文笔记:SIBO: A Simple Booster for Parameter-Efficient Fine-Tuning-CSDN博客 | ACL 2024
|
| 论文略读:Not all Layers of LLMs are Necessary during Inference-CSDN博客 |
动态减少激活神经元的数量以加速LLM推理 根据输入实例动态决定推理终止时刻 |
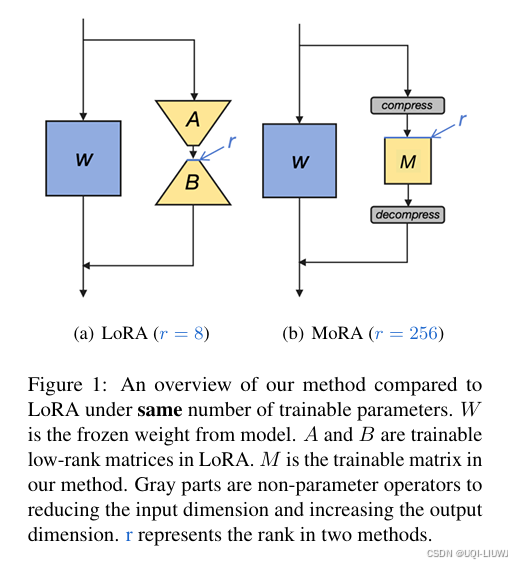
| 论文略读:MoRA: High-Rank Updating for Parameter-Efficient Fine-Tuning-CSDN博客 | 过低的秩会严重限制模型学习和记忆新知识的能力,尤其在需要获取大量领域知识的任务上 oRA的关键在于使用方阵M取代LoRA的低秩矩阵A和B,以提升rank
|
| 论文略读:LoRA+: Efficient Low Rank Adaptation of Large Models-CSDN博客 | 从理论分析了LoRA最优解必然是右矩阵的学习率大于左矩阵的学习率(数量级差距是O(n))
|
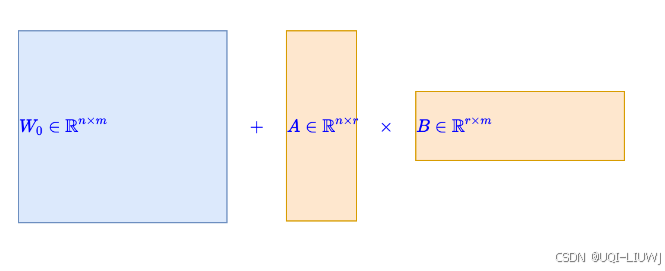
14 多模态
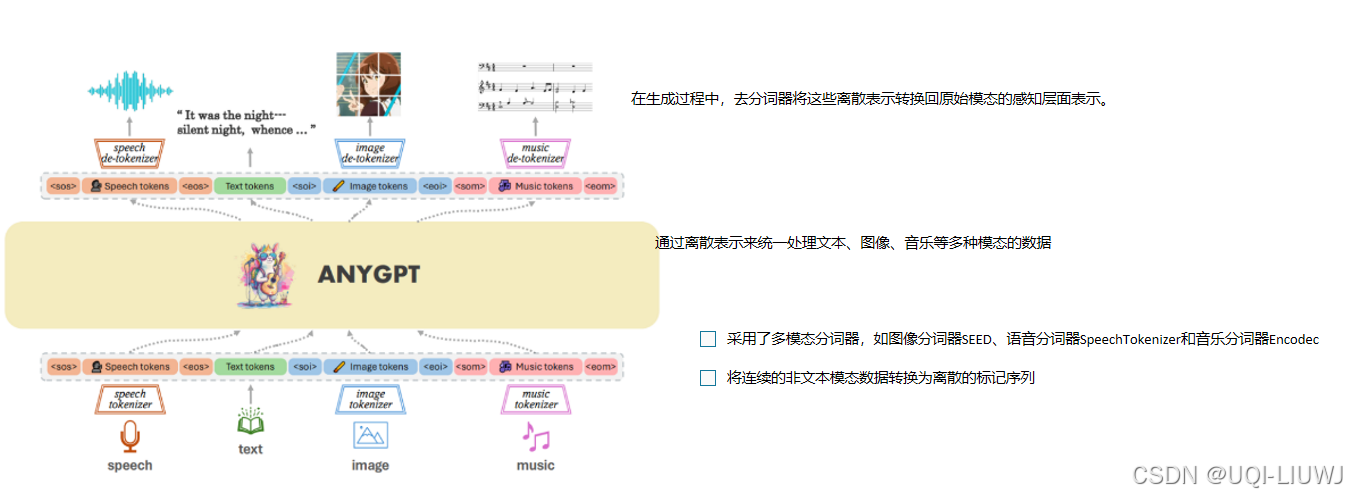
| 论文略读:AnyGPT: Unified Multimodal LLM with Discrete Sequence Modeling-CSDN博客 | ACL 2024
|
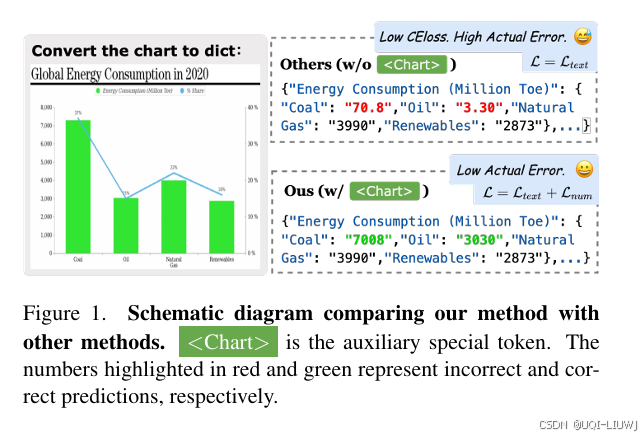
| 论文略读:OneChart: Purify the Chart Structural Extraction via One Auxiliary Token-CSDN博客 |
|
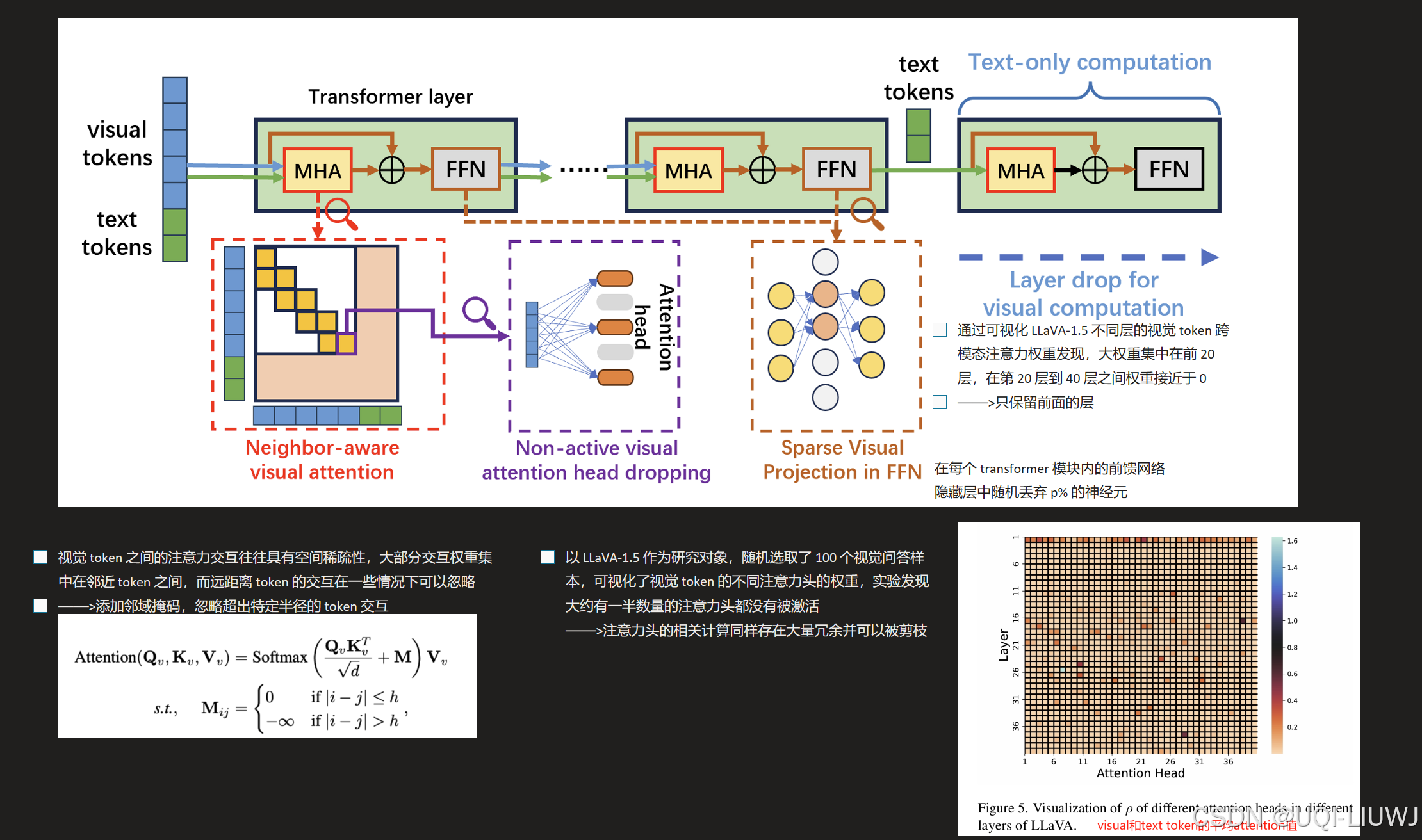
| 论文笔记:Treat Visual Tokens as Text? But Your MLLM Only Needs Fewer Efforts to See-CSDN博客 | 2024 10 保持性能的同时显著降低计算复杂度
|
| 论文结论:From Redundancy to Relevance: EnhancingExplainability in Multimodal Large Language Models-CSDN博客 | 在浅层与深层中不同token信息流汇聚情况有所区别
|
15 幻觉
| 论文结论:GPTs and Hallucination Why do large language models hallucinate-CSDN博客 |
|
16 moe
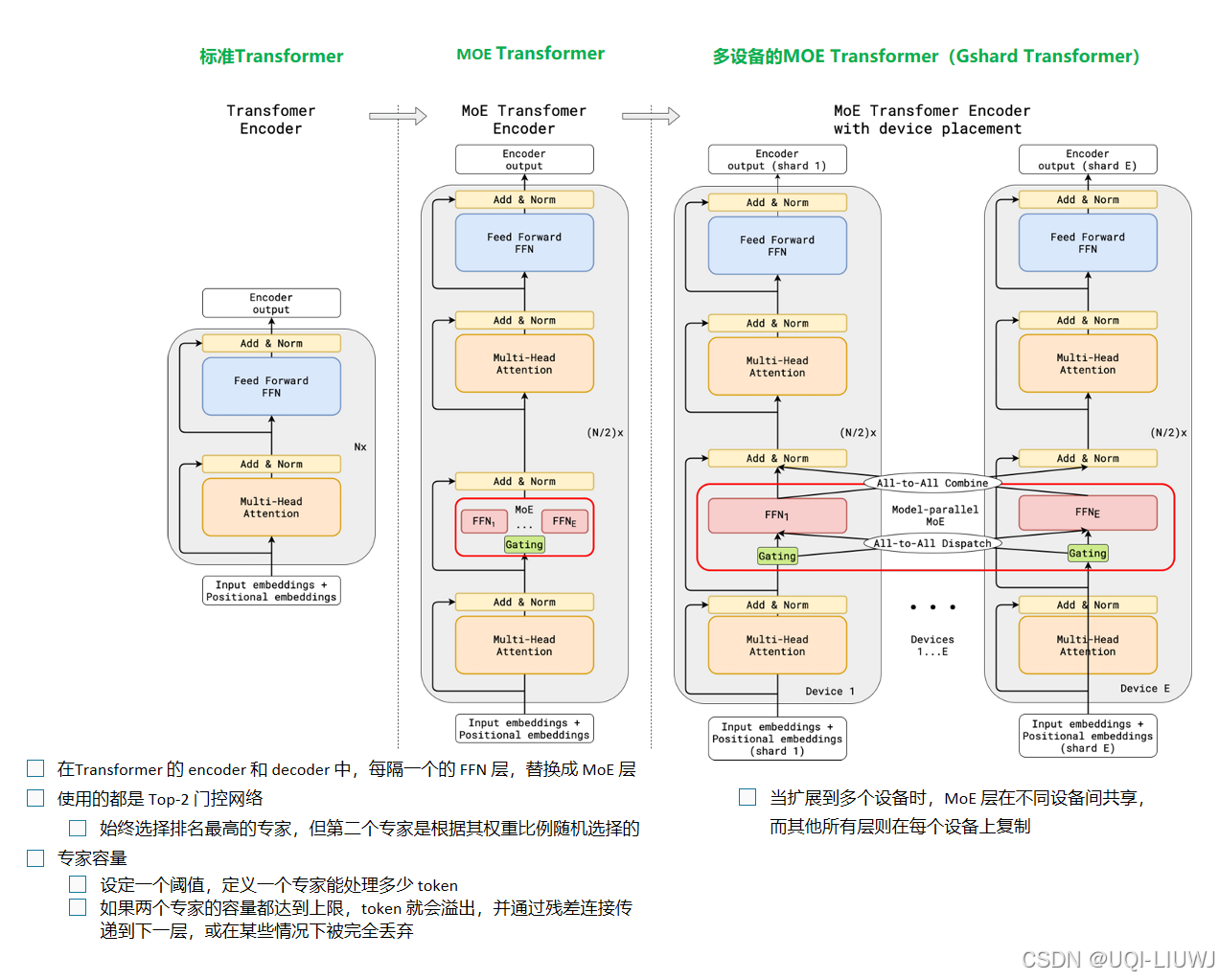
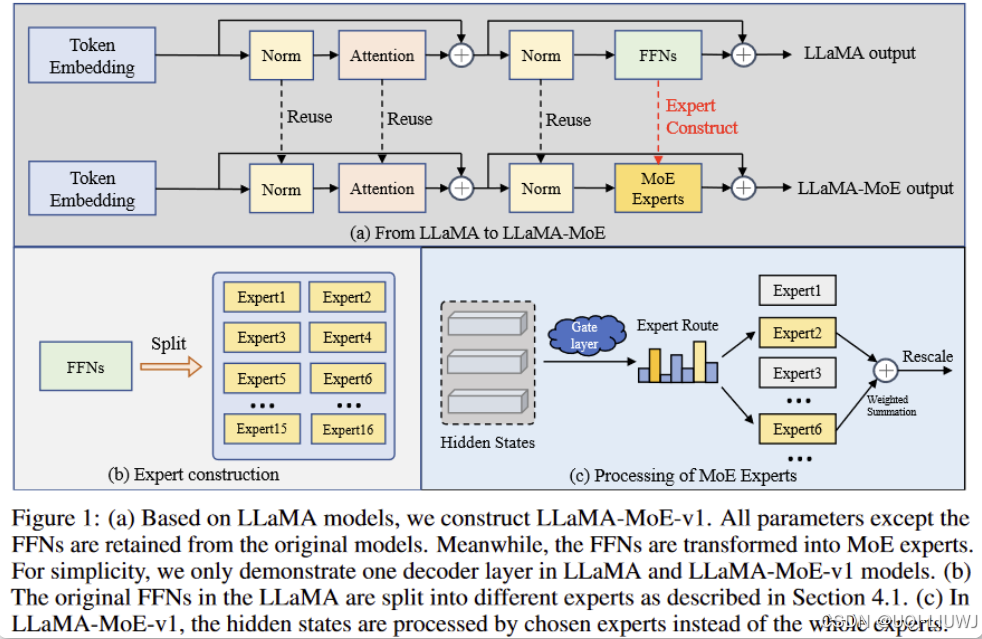
| 论文略读:GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding -CSDN博客 | 2021 ICLR 第一个将 MoE 的思想拓展到 Transformer 上的工作
|
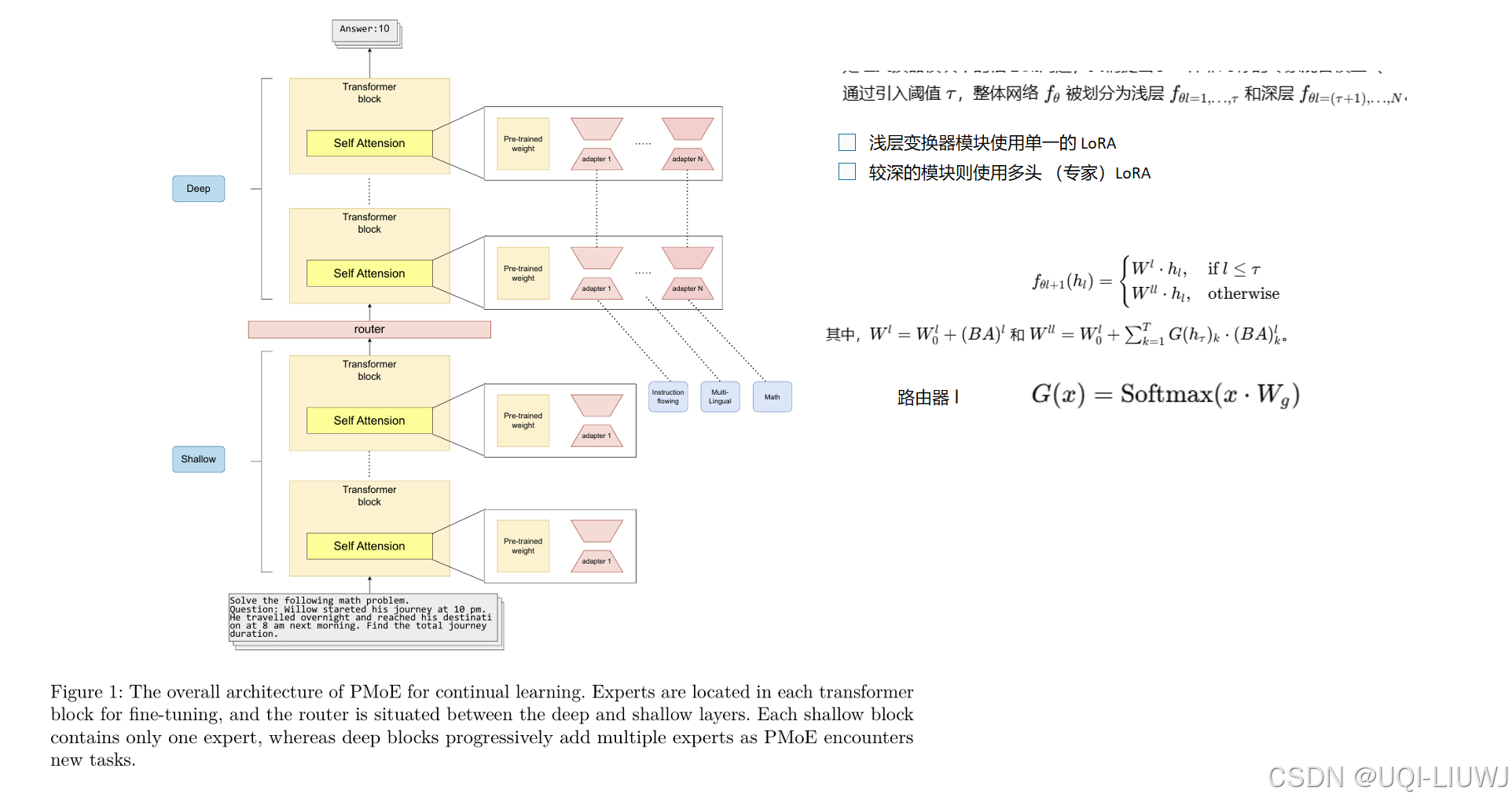
| 论文略读:On the Embedding Collapse When Scaling Up Recommendation Models-CSDN博客 |
|
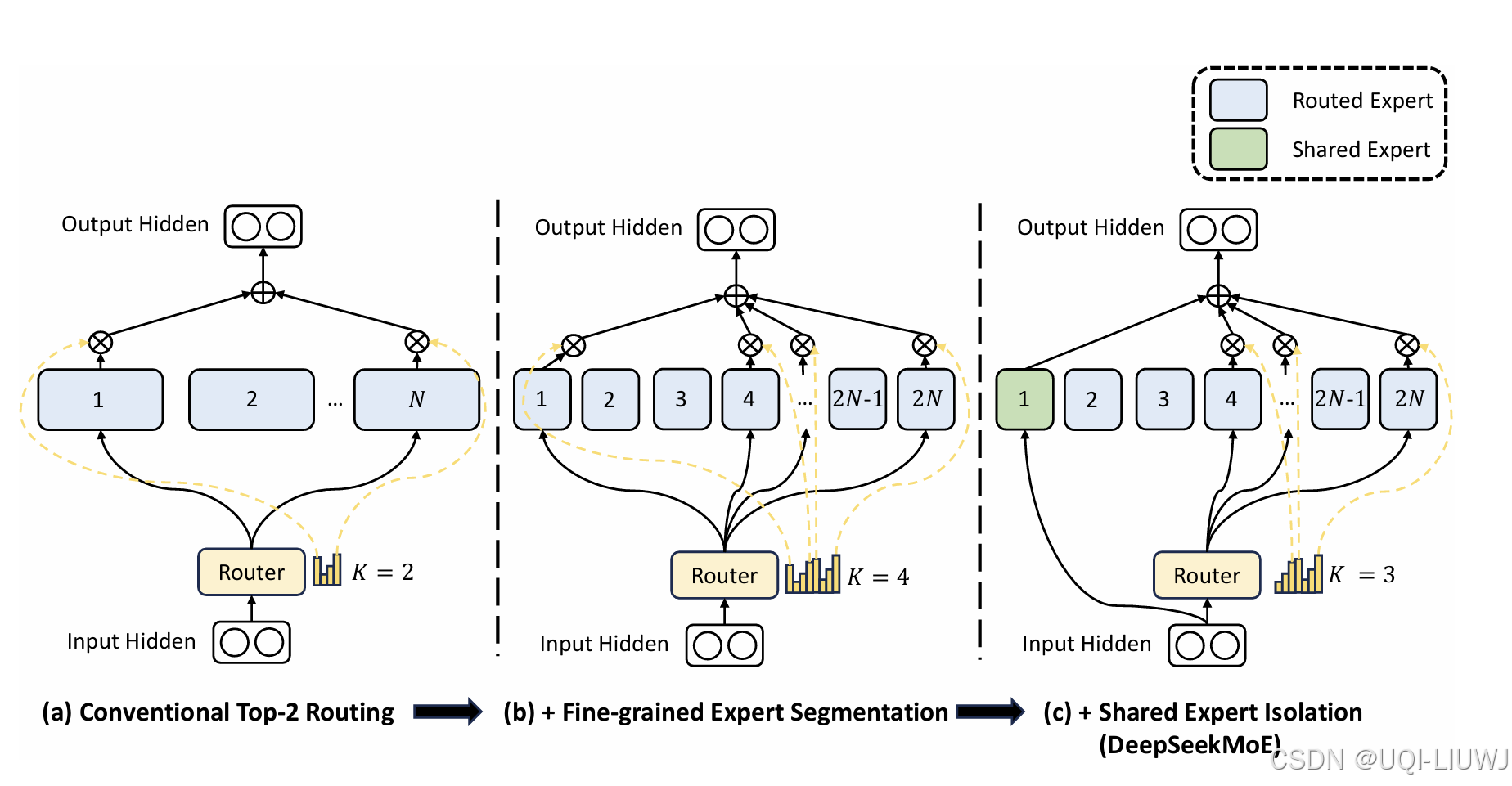
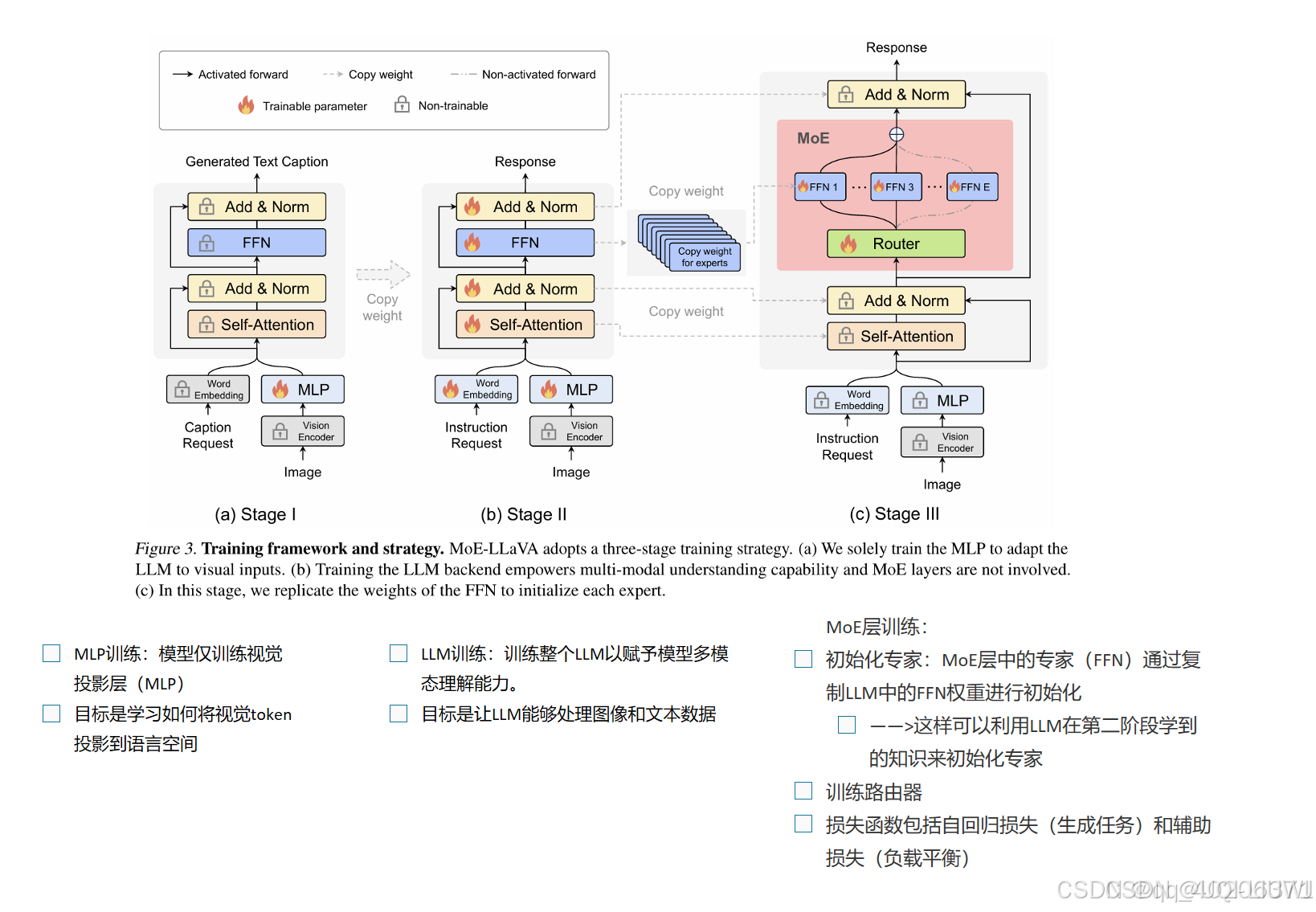
| 论文笔记:DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models-CSDN博客 |
|
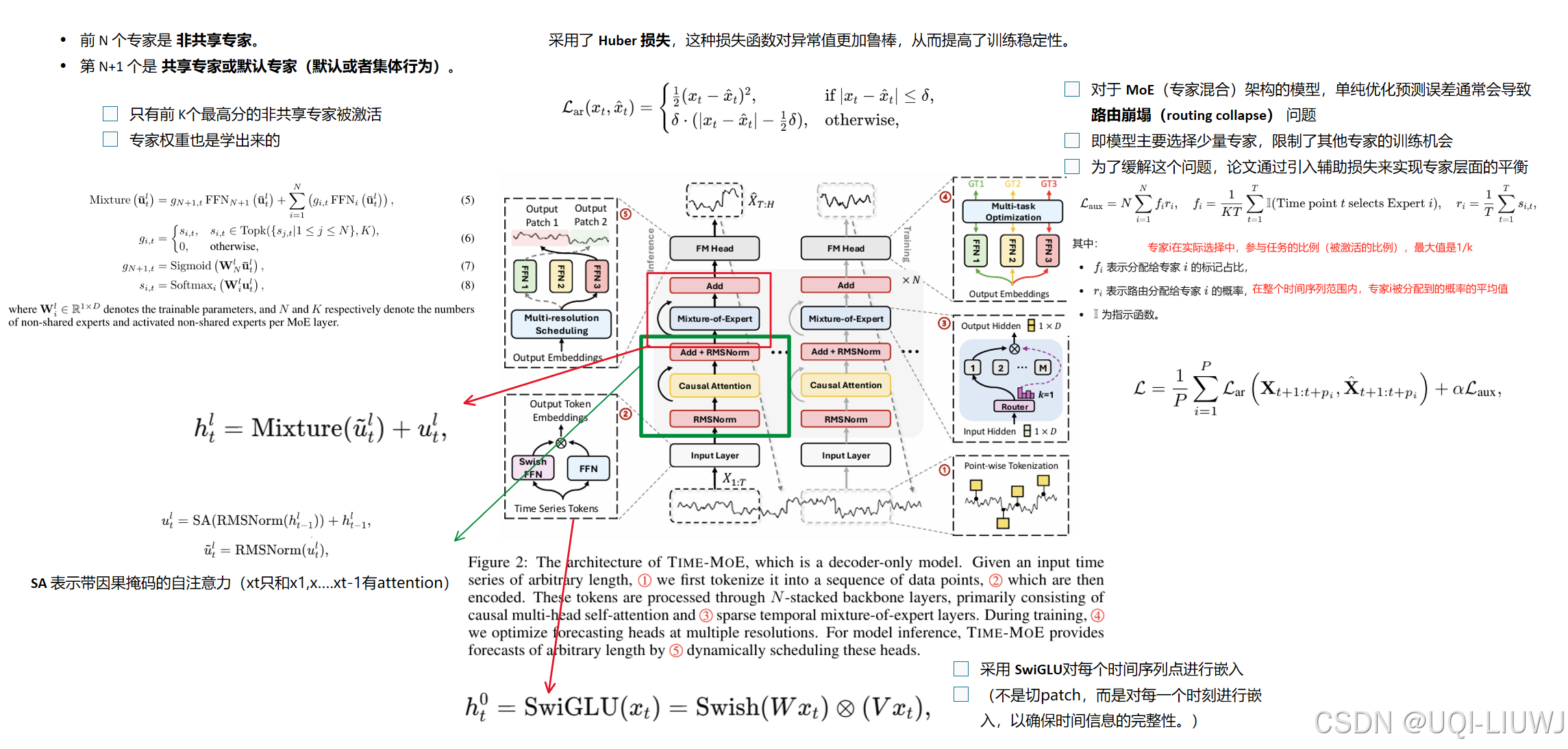
| 论文笔记:TIME-MOE: BILLION-SCALE TIME SERIES FOUNDATION MODELS WITH MIXTURE OF EXPERTS_timer moe-CSDN博客 | 提出了TIME-MOE,一个可扩展的统一架构,用于预训练更大规模、更强能力的预测基础模型,同时降低计算成本
|
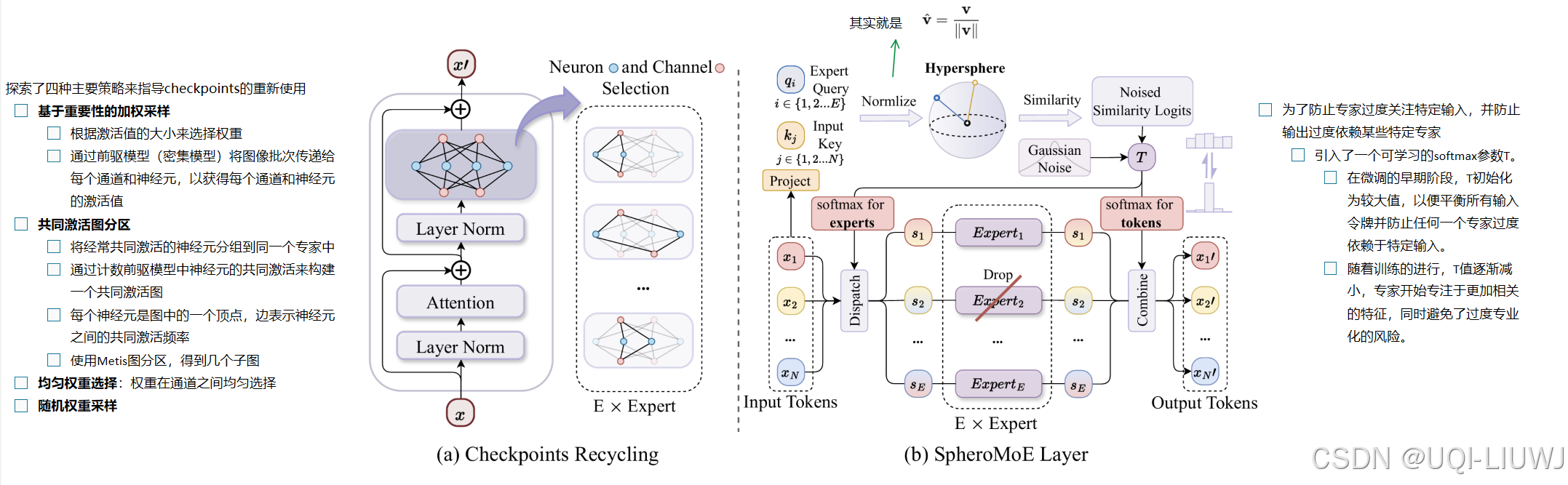
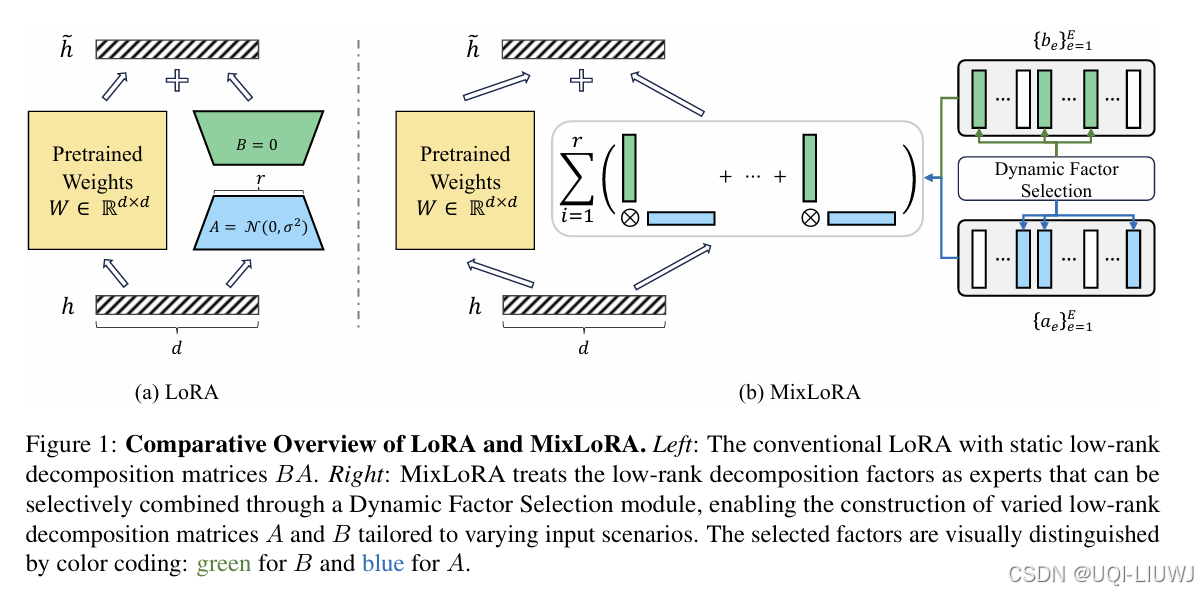
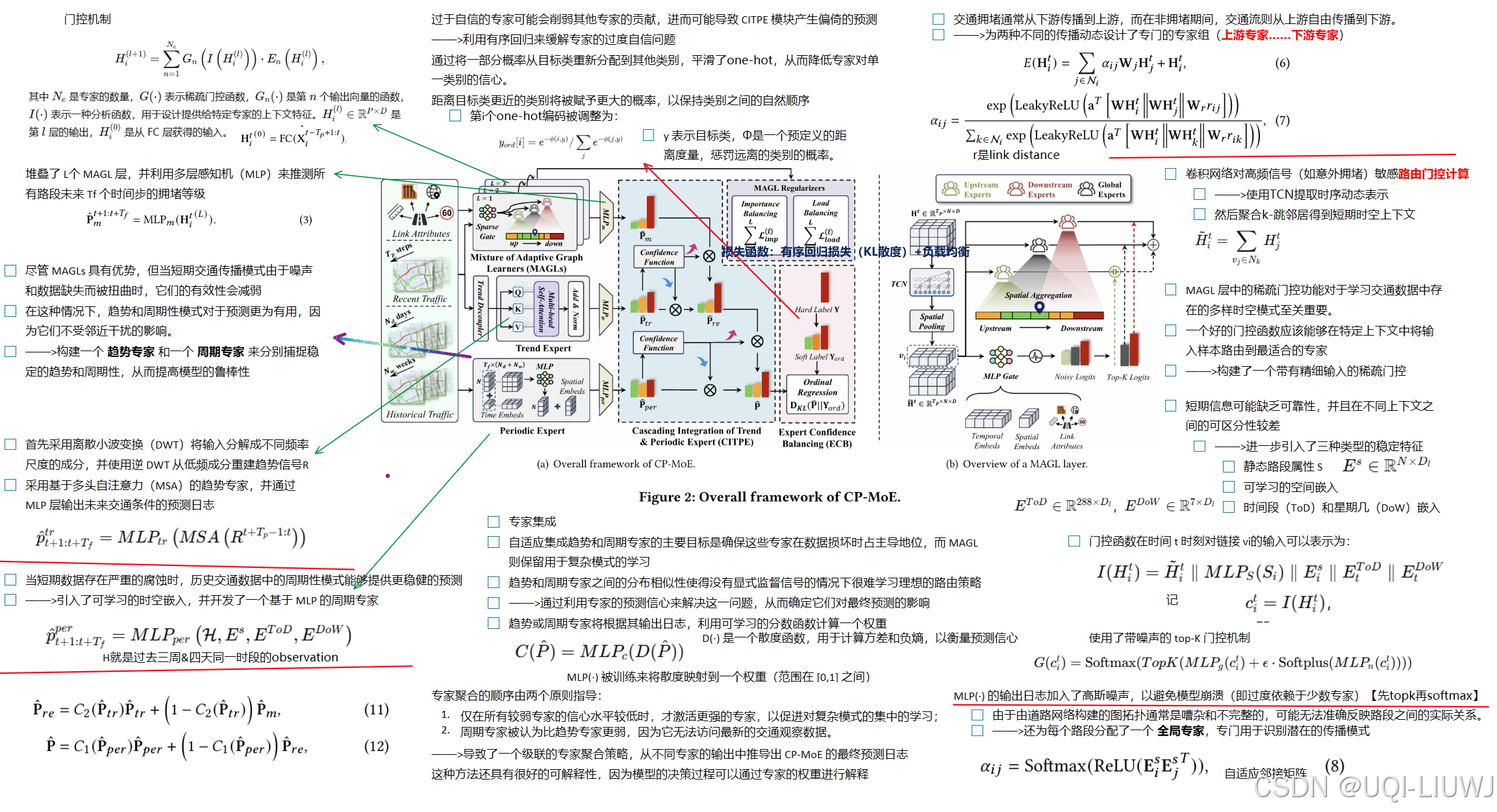
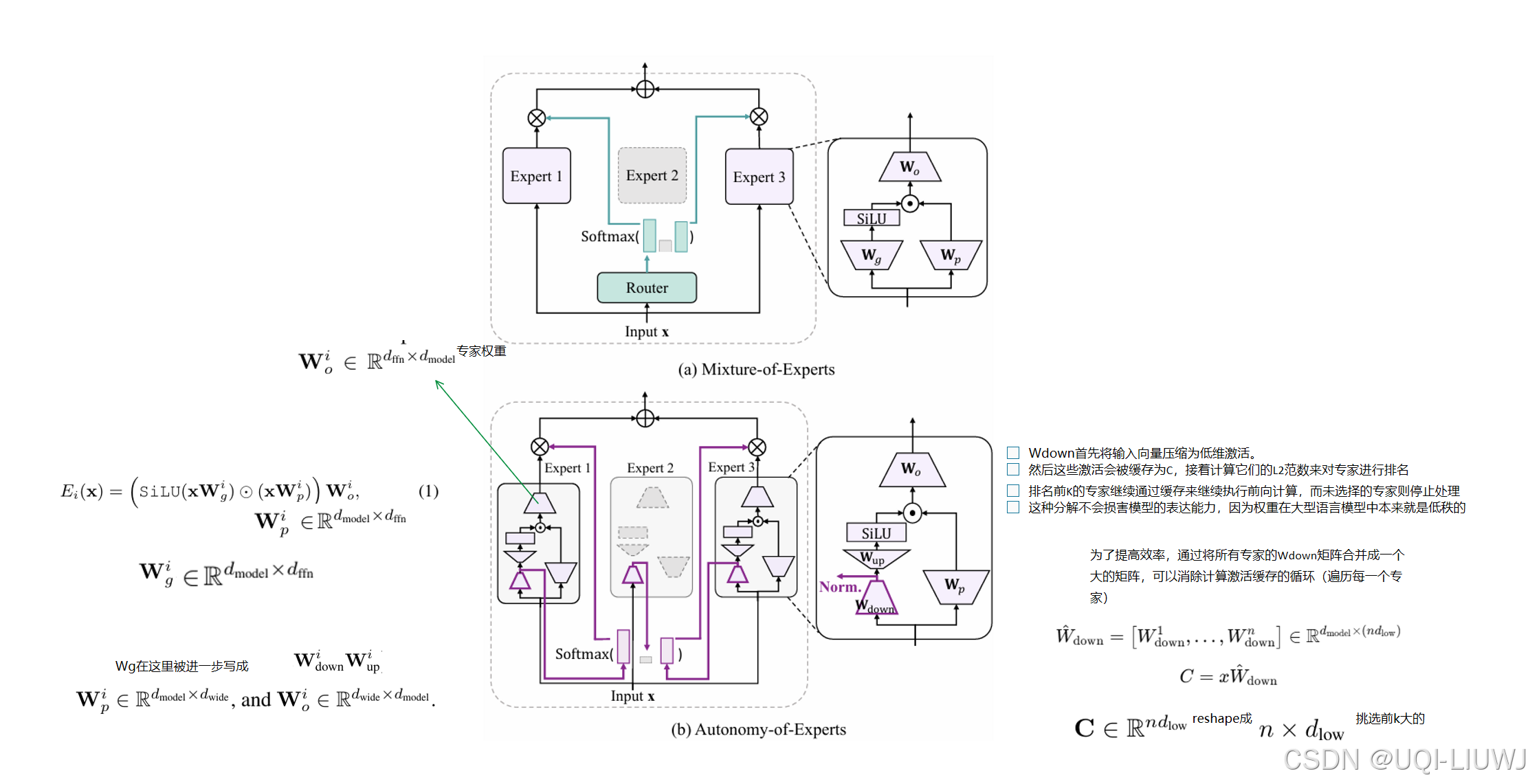
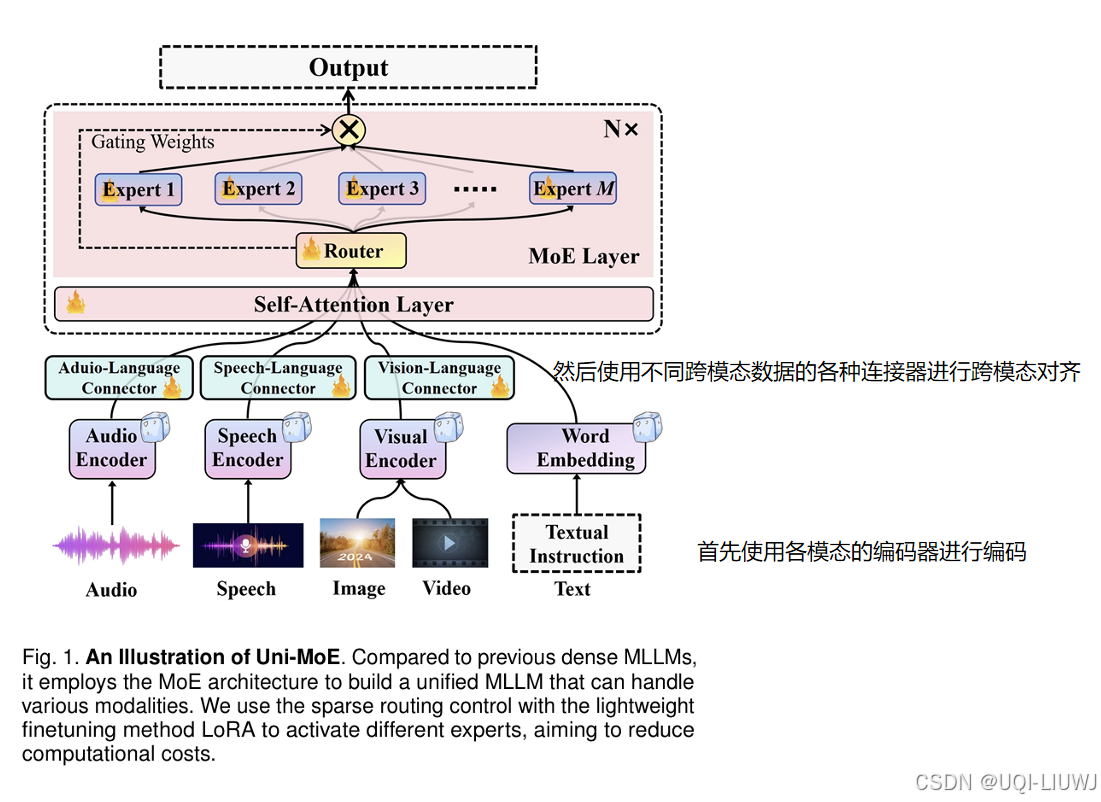
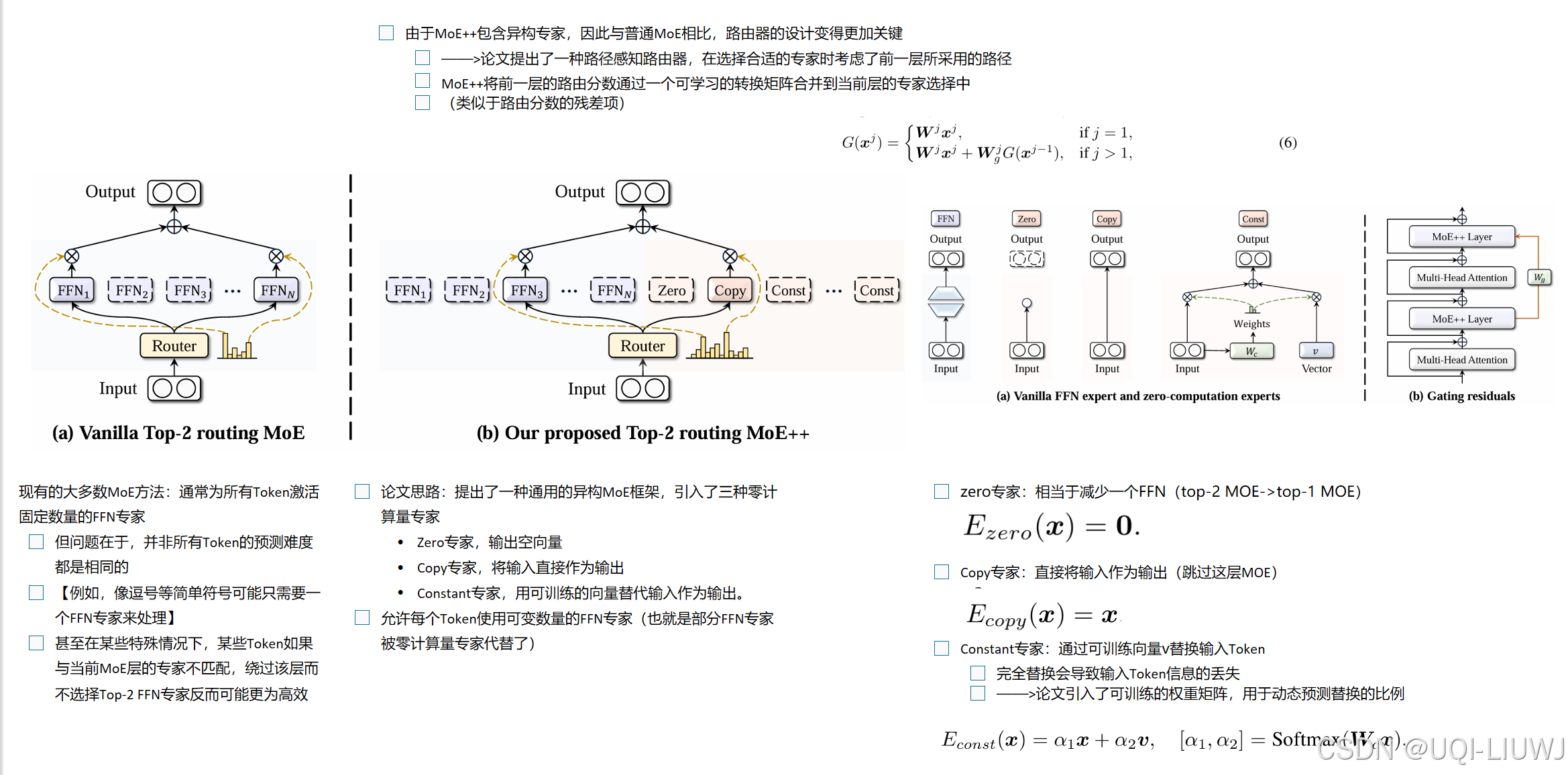
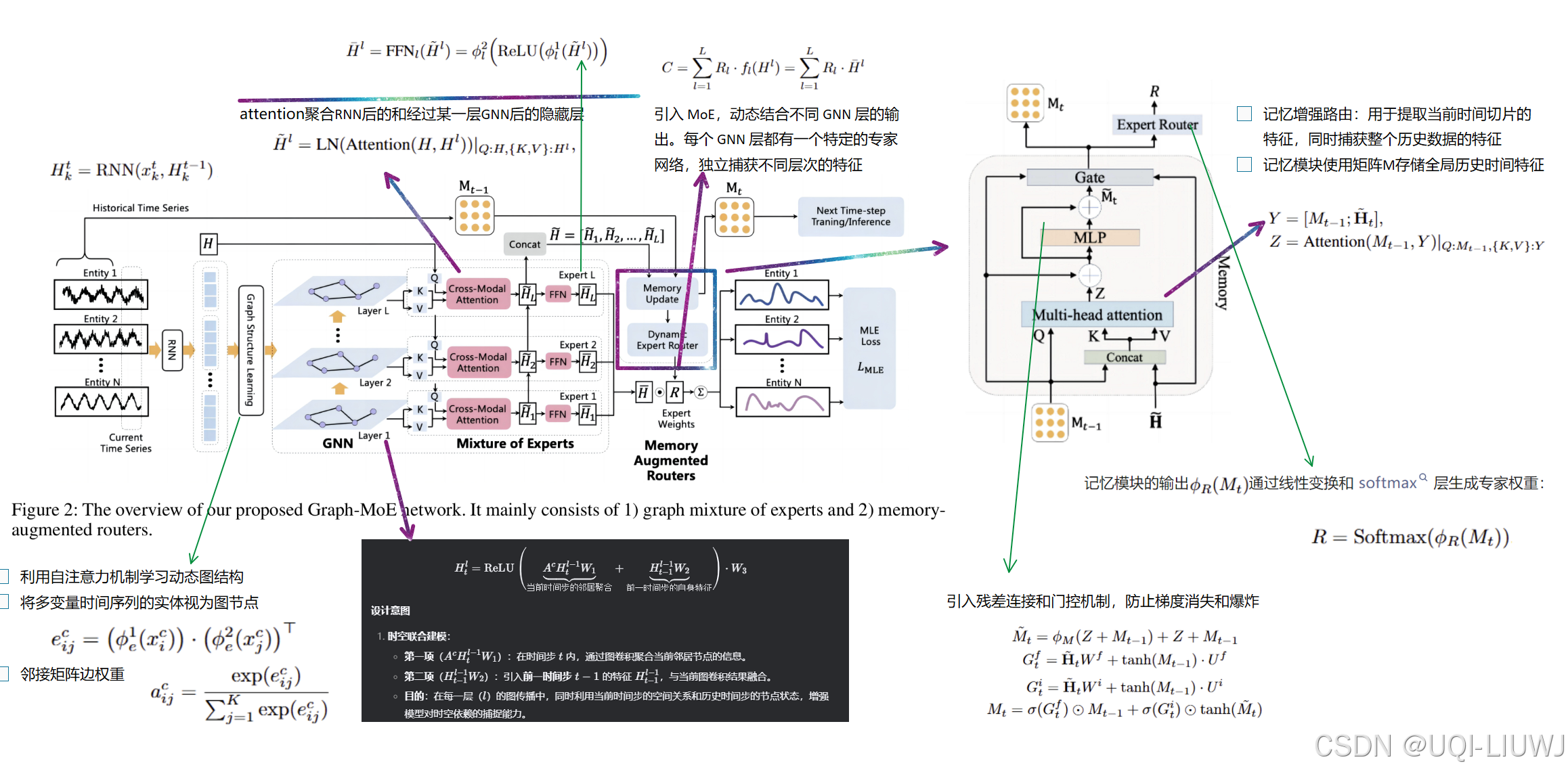
17 text embedding
| 论文略读:Matryoshka Representation Learning-CSDN博客 | 2022 Neurips
|
| 论文笔记:Enhancing Sentence Embeddings in Generative Language Models-CSDN博客 |
|
| 论文笔记:Scaling Sentence Embeddings with Large Language Models-CSDN博客 | 2024 ACL findings
|
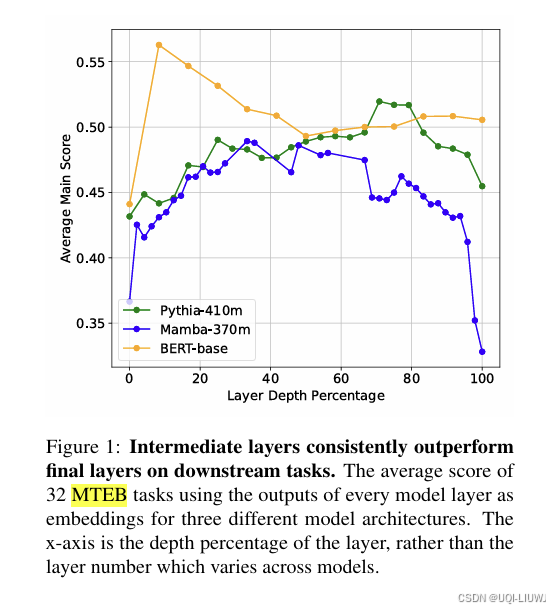
| 论文略读:Uncovering Hidden Representations in Language Models_linearity of relation decoding in transformer lang-CSDN博客 | 202502 arxiv 对于下游任务,语言模型的中间层在所有架构和任务中始终优于最后一层
|

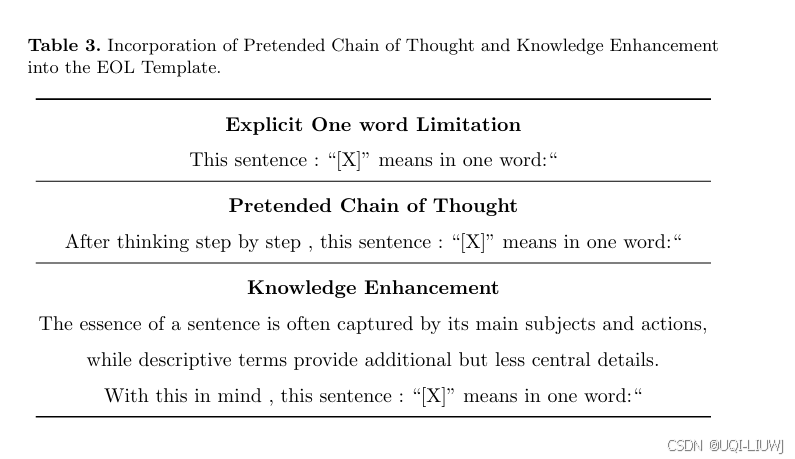
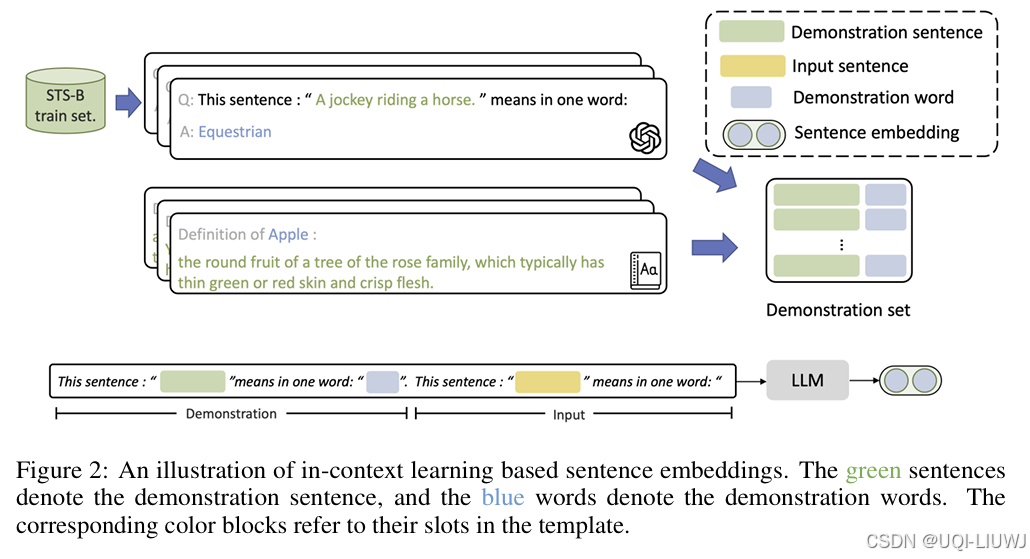
18 推荐
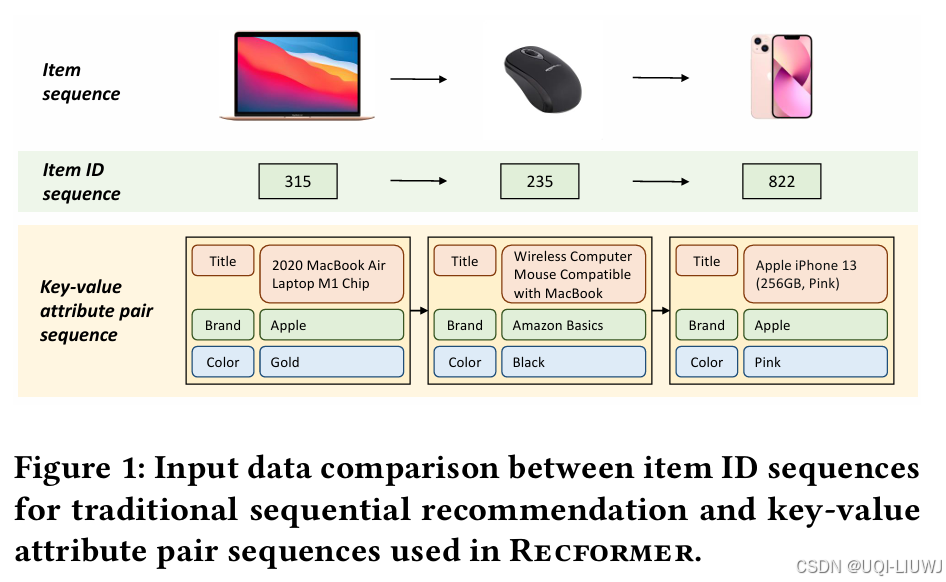
| 论文笔记:Text Is All You Need: Learning Language Representations for Sequential Recommendation-CSDN博客 | 2023 KDD 论文用自然语言的方式对用户偏好和商品特征进行建模
|


















 8182
8182

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











