







我们在使用Sql的过程中,往往避免不了使用Sql制作报表来展示数据,本章属于比较重点的内容,希望大家可以掌握
1、将多行(一个结果集)转置为一行
例如我们现在有如下数据
classno(班级号) c_num(班级人数)
1 33
2 36
3 38
而我们想要的结果是如下格式
classno_1 classno_2 classno_3
33 36 38
我们可以用case when 和聚合函数sum来实现
select sum(case when classno=1 then 1 else 0 end)as classno_1,
sum(case when classno=2 then 1 else 0 end)as classno_2,
sum(case when classno=3 then 1 else 0 end)as classno_3
from tb_class2、将一行转置为多行(一个结果集)
还是上面的例子,只不过是根据 下面的表
 反推到开始的样子
反推到开始的样子
此时我们需要考虑用笛卡尔积的方法,先根据已知的tb_class表来形成对应的行数,再转化,假设上面行转列的表为tb_class_count
select c.classno,
case c.classno
when 1 then cc.class_1
when 2 then cc.class_2
when 3 then cc.class_3
end as num
from tb_class_count cc
cross join (
select classno from tb_class
)c
3、将结果集转置为多行
例如我们有如下数据,根据有几个车轮给车分类型
type_wheel vehice
four car (小汽车)
four bus (公交车)
four truck (卡车)
three tricycle (三轮车)
two bicycle (自行车)
two e-bike (电动车)
而我们想要得如下形式
two three four
e-bike tricycle car
bicycle bus
truck
我们可以用 case when 和聚合函数max来实现
select max(case when type_wheel='two' then vehice else null end) as two,
max(case when type_wheel='three' then vehice else null end) as three,
max(case when type_wheel='four' then vehice else null end) as four
from (
select type_wheel,vehice,
row_number() over(partition by type_wheel order by vehice) rn
from tb_vehice
)v
group by rn4、将结果集转为一列
例如之前说的成绩表tb_scores里面有学号、成绩、班级号等信息,现在我们想要将查询出的这三个字段变为一列并用空格间隔
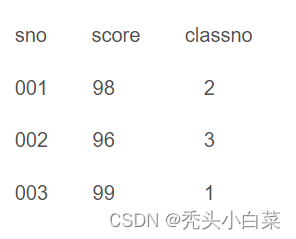

这样做的关键是需要形成4行数据,然后用row_number() over()查询数据
with four_rows--(num) 非oracle的用法,如果是postgresql或mysql需要加关键字recursive
as(
select level n
from dual
connect by level <= 4
),
x_tab--(sno,score,classno,rn) 非oracle的用法
as(
select s.sno,s.score,s.classno,
row_number() over(partition by s.sno order by s.sno)
from tb_scores s
join four_rows on 1=1
)
select case rn
when 1 then sno
when 2 then score
when 3 then classno
end information
from tb_score
如果想要了解详细信息,大家可以参考下面的文章
6、 将数据集按照既定的数量分组
例如我们有20条数据我们想5个一组分为四组,在原有数据上新增一列grp代表组别,我们可以用ceil(SqlServer中用ceiling)函数来实现。
select ceil(row_number() over (order by sno)/5.0) grp,
sno,score,classno
from tb_scores7、 按照时间间隔分组
根据我们上面提到的函数ceil()也可以按照时间分组,例如现在有日志表tb_log,我们需要统计每5秒记录了多少数量
select hr,grp,sum(log_cnt) total
from (
select log_date,log_cnt,
to_number(to_char(log_date,'hh24')) hr,
ceil(to_number(to_char(log_date-1/24/60/60,'miss'))/5.0) grp
from tb_log
) l
group by hr,grp或者tb_log表里有顺序id,每秒计入日志时写入id,可以直接分组
select ceil(log_id/5.0) as grp,
min(log_date) as log_start,
max(log_date) as log_end.
sum(log_cnt) as total
from tb_log
group by ceil(log_id/5.0)8、将数据集按照既定组数分数量
这个点跟上面6的原理有些相反,例如我们有18条数据,我现在就想把这些数据分成4组,那么第一组和第二组就是5行数据,第三组和第四组就是4行数据,可以用ntile(组数)over()函数实现。
select ntile(4) over(order by sno) grp,
score,classno
from tb_scores9、 水平直方图
例如我们想用 * 表示每个班的学生,大概类似于以下的格式
classno cnt
1 * * *
2 * * * * *
3 * * * * * * *
其实比较简单,就是在我们之前讲过的数据库语法总结(6)——处理字符串_第4点替换函数中,把参数换成聚合count(*)就可以了,我们下面来写一下,顺便加深印象
--DB2
select classno,repeat('*',count(*)) cnt
from tb_scores group by classno
--Oracle、PostgreSql、MySql
select classno,lpad('*',count(*),'*') as cnt
from tb_scores group by classno
--SqlServer
select classno,replicate('*',count(*)) cnt
from tb_scores group by classno
10、垂直直方图
顾名思义就是把上面的水平变为垂直,我们利用本文章的第1节就能实现 ,使用函数row_number() over()排序标定每个班的人数顺序,然后使用聚合函数max转置结果。
select max(classno_1) c1,
max(classno_2) c2,
max(classno_3) c3
from (
select row_number() over(partition by deptno order by classno) rn,
case when classno=1 then '*' else null end classno_1,
case when classno=2 then '*' else null end classno_2,
case when classno=3 then '*' else null end classno_3
from tb_scores
)c
gruop by rn
order by 1 desc,2 desc, 3 desc11、返回行数和聚合函数在同一个结果集中
例如我们想要返回1班的学生成绩和成绩总和,例如
sno score
001 95
002 98
003 100
total 293
平时写语句的话,我们一般会用group by 分组求聚合总数和其他列一起展示,但是这种普通数据行和聚合函数结果同时出现在同一个一个结果集怎么办呢?我们用到了group by 的扩展rollup
--DB2、Oracle 使用rollup
select case grouping(sno) when 0 then sno else 'total' end sno,
sum(score) score
from tb_scores
group by rollup(sno)
--SqlServer、MySql 使用 with rollup
select coalesce(sno,'total') sno,
sum(score) score
from tb_scores
group by sno with rollup
--PostgreSql 使用 rollup
select coalesce(sno,'total') sno,
sum(score) score
from tb_scores
group by rollup(sno)
扩展:Oracle中的grouping(columnA)函数的意思:当前行如果是由rollup汇总产生的,那么columnA这个字段值为1否则为0;
rollup()--可以使用一个或者多个参数。意思是从右向左进行数据的汇总统计,并生成一行,rollup是个统计函数。
12、 返回行数和各种不同的聚合函数在同一个结果集中
还是我们提到的tb_scores表,我们在其中新增了一列科目subject,目前的数据是这样的
| classno | score | subject | sno |
| 1 | 98 | 语文 | 001 |
| 1 | 95 | 数学 | 001 |
| 1 | 99 | 英语 | 001 |
| 1 | 96 | 语文 | 002 |
| 2 | 95 | 数学 | 003 |
| 2 | 97 | 英语 | 003 |
| 2 | 96 | 数学 | 004 |
大概就是这种形式,当然咱们种类没有写全,只是列举了一部分,大家明白意思即可
现在我们不考虑学号,想要不同的班级、学科、班级/学科的成绩总和,加上全校所有班级所有学科的成绩总和。总之想要实现以下效果:
| classno | subject | score | category(分组类别) |
| 1 | 语文 | 194 | classno & subject |
| 1 | 数学 | 95 | classno & subject |
| 1 | 英语 | 99 | classno & subject |
| 2 | 数学 | 191 | classno & subject |
| 2 | 英语 | 97 | classno & subject |
| 1 | 388 | classno | |
| 2 | 288 | classno | |
| 语文 | 194 | subject | |
| 数学 | 286 | subject | |
| 英语 | 196 | subject | |
| 676 | total(总和) |
我们使用上述扩展的group cube(columnA,columnB)和grouping函数实现:
--DB2
select classno,subject,
case cast(grouping(classno) as char(1)) || cast(grouping(subject) as char(1))
when '00' then 'classno & subject'
when '10' then 'subject'
when '01' then 'classno'
when '11' then 'total' end category,
sum(score) score
from tb_scores
group by cube(classno,subject)
order by grouping(subject),grouping(classno)
--SqlServer 注意with cube
select classno,subject,
case cast(grouping(classno) as char(1)) + cast(grouping(subject) as char(1))
when '00' then 'classno & subject'
when '10' then 'subject'
when '01' then 'classno'
when '11' then 'total' end category,
sum(score) score
from tb_scores
group by classno,subject with cube
order by grouping(subject),grouping(classno)
--Oracle
select classno,subject,
case grouping(classno) || grouping(score)
when '00' then 'classno & subject'
when '10' then 'subject'
when '01' then 'classno'
when '11' then 'total' end category,
sum(score) score
from tb_scores
group by cube(classno,subject)
order by grouping(subject),grouping(classno)
--PostgreSql
select classno,subject,
case concat(cast(grouping(classno) as char(1)),cast(grouping(subject) as char(1)))
when '00' then 'classno & subject'
when '10' then 'subject'
when '01' then 'classno'
when '11' then 'total' end category,
sum(score) score
from tb_scores
group by cube(classno,subject)而关于mysql中没有cube这个函数,我们可以用union all来拼接语句,在这就列举了。
扩展: group by 后面还有一些常用用法,例如 group by cube(columnA,columnB):首先根据:group by columnA,columnB查询数据,其次对columnB进行汇总(不考虑columnA,单独汇总,而rollup是在同一个columnA下面)再对columnA进行汇总,最后全部汇总。
想要了解更多知识,可以参考以下文章oracle分组_详解Oracle数据库分组函数group by 、rollup、cude、grouping等-CSDN博客
cube与rollup之间的细微差别
rollup(a,b) 统计列包含:(a,b)、(a)、()
rollup(a,b,c) 统计列包含:(a,b,c)、(a,b)、(a)、()
……以此类推……
cube(a,b) 统计列包含:(a,b)、(a)、(b)、()
cube(a,b,c) 统计列包含:(a,b,c)、(a,b)、(a,c)、(b,c)、(a)、(b)、(c)、()
CUBE在ROLLUP的基础上进一步从各种维度上给出细化的统计汇总结果。
13、聚合移动区间的值
例如我们想要计算从第一位员工入职日期至90天之后的薪资总计,用来观察薪资涨幅情况,需要在开窗函数中用到range between 90 preceding and current row,不同的数据库写法略有不同
--DB2
select hiredat,
sal,
sum(sal)over(order by days(hiredate)
range between 90 preceding
and current row) spending_pattern
from emp e
--Oracle
select hiredate,
sal,
sum(sal)over(order by hiredate
range between 90 preceding
and current row) spending_pattern
from emp e
--PostgreSql、SqlServer 和Mysql(时间取值用 interval 90 day)
select e.hiredate,
e.sal,
(select sum(sal) from emp d
where d.hiredate between e.hiredate-90
and e.hiredate) as spending_pattern
from emp e
order by 1
详细信息可以参考SQL 动态区间聚合运算|极客教程
扩展:窗口子句一般和order by 子句同时使用,且如果指定了order by 子句未指定窗口子句,则默认为RANGE BETWEEN unbounded preceding AND CURRENT ROW;
如果分析函数没有指定ORDER BY子句,也就不存在ROWS/RANGE窗口的计算;
range是逻辑窗口,是指定当前行对应值的范围取值,列数不固定,只要行值在范围内,对应列都包含在内;
rows是物理窗口,即根据order by 子句排序后,取的前N行及后N行的数据计算(与当前行的值无关,只与排序后的行号相关);
--说明:
--unbounded preceding and unbouned following针对当前所有记录的前一条、后一条记录,也就是表中的所有记录
--unbounded:不受控制的,无限的
--preceding:在...之前
--following:在...之后
--current:当前的
--row:行
rows between unbounded preceding and unbounded following 表中的所有记录
rows between unbounded preceding and current row 是指第一行至当前行的汇总
rows between current row and unbounded following 指当前行到最后一行的汇总
rows between 1 preceding and current row 是指当前行的上一行(rownum-1)到当前行的汇总
rows between 1 preceding and 2 following 是指当前行的上一行(rownum-1)到当前行的下两行(rownum+2)的汇总
rows between n preceding and n following 是指前面n行到后面n行的值关于这块内容,目前先介绍这么多,有兴趣的小伙伴可以自己研究一下,下面文章可以参考:
https://www.cnblogs.com/xulinforDB/p/17496452.html
该文章中的 有关ROWS/RANGE窗口的例子(借鉴其他的博客) 这一板块
好了,这章就先介绍这么多了,希望大家可以多多掌握,后续我还会继续更新,希望大家多多关注支持!















 3233
3233











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









