







Map与Set
一.搜索
1.1 概念和场景
概念及场景
Map和set是一种专门用来进行搜索的容器或者数据结构,其搜索的效率与其具体的实例化子类有关。以前常见的
搜索方式有:
- 直接遍历,时间复杂度为O(N),元素如果比较多效率会非常慢
- 二分查找,时间复杂度为 ,但搜索前必须要求序列是有序的
上述排序比较适合静态类型的查找,即一般不会对区间进行插入和删除操作了,而现实中的查找比如: - 根据姓名查询考试成绩
- 通讯录,即根据姓名查询联系方式
- 不重复集合,即需要先搜索关键字是否已经在集合中
可能在查找时进行一些插入和删除的操作,即动态查找,那上述两种方式就不太适合了,本节介绍的Map和Set是
一种适合动态查找的集合容器。
1.2 模型
一般把搜索的数据称为关键字(Key),和关键字对应的称为值(Value),将其称之为Key-value的键值对,所以
模型会有两种:
- 纯 key 模型,比如:
有一个英文词典,快速查找一个单词是否在词典中
快速查找某个名字在不在通讯录中 - Key-Value 模型,比如:
统计文件中每个单词出现的次数,统计结果是每个单词都有与其对应的次数:<单词,单词出现的次数>
梁山好汉的江湖绰号:每个好汉都有自己的江湖绰号
而Map中存储的就是key-value的键值对,Set中只存储了Key。
二 Map的使用
2.1 Map说明
Map是一个接口类,该类没有继承自Collection,该类中存储的是<K,V>结构的键值对,并且一定是唯一的,不能重复。
2.2 Map.Entry<K,V>说明
Map.Entry<K, V> 是Map内部实现的用来存放<key, value>键值对映射关系的内部类,该内部类中主要提供了<key, value>的获取,value的设置以及Key的比较方式。
比如 getKey() , getValue(), setValue(V value);
2.3Map 的常用方法说明

注意:
1.map是一个接口,不能直接实例化,如果要实例化,必须实例化他的实现类TreeMap或HashMap
2.Map中的key是唯一值,val可以重复
3.Map中key可以分离出来,放入Set中,val也可以分离出来,放在Collection中的子集合中
4.Map中key不能修改,val可以,如果要修改key只能删除这个键值对,重新插入
2.4 Map代码示例(TreeMap/HashMap)
//Map使用 TreeMap和HashMap的底层结构,key值有序与否等
public static void main1(String[] args){
Map<String, Integer> m = new TreeMap<>();
//key value value可以为null key不行
m.put("abc", 1);
m.put("eeee",3);
m.put("fffff",4);
m.put("eeee",7);//替换旧val值
//m.put("null",7); key不能为空
System.out.println(m);
System.out.println(m.get("abc"));//获取key对应的value值
System.out.println(m.getOrDefault("bbb",1000));//如果key不存在,则返回设置的val
//检查key是否在Map中,时间复杂度O(logN)
//红黑树的性质来查找
//找到 true or false
System.out.println(m.containsKey("abc"));
//时间复杂度O(N)
System.out.println(m.containsValue(1));
//打印所有的key
System.out.println("=====");
Set<String> keySet = m.keySet();
System.out.println(keySet);
System.out.println("====");
for(String s : m.keySet()){
System.out.println(s+" ");
}
//打印所有的value
//values()是将map中的value放在collect的一个集合中返回的
System.out.println("====");
System.out.println(m.values());
//entrySet() 将Map中的键值对放在Set中返回
System.out.println("打印所有的键值对");
Set<Map.Entry<String,Integer>> entrySet = m.entrySet();
for(Map.Entry<String,Integer> entry : entrySet){
System.out.println("key="+entry.getKey()+" value="+entry.getValue());
}
System.out.println(m.entrySet());
}
三 Set的使用
3.1 常见方法
1.boolean add(E e) 添加元素,重复元素不会被添加(所以Set可以用来数据去重)
2.void clear() 清空集合
3.boolean contains(Object o) 判断o是否在集合中
4.boolean remove(Object o) 删除集合中的o
5.int size() 返回set中元素的个数
6.boolean isEmpty() 检测set是否为空,空返回true,否则返回false
注意:
1.Set是继承Collection的一个接口类
2.Set只放key 而且是唯一key
3.Set的底层是Map来实现的
4.Set最大用处就是用来数据去重
5.Set中不能插入null的key
6 Set中key不能修改
3.2 Set的代码示例(TreeSet/HashSet)
//数据出现的次数统计
public static void main(String[] args){
int[] arr = new int[100000];
Random random = new Random();
for (int i = 0; i < arr.length; i++) {
arr[i] = random.nextInt(5000);
}
System.out.println("去除数据的重复元素");
fun1(arr);
int ret = fun2(arr);
System.out.println("数据中第一个重复的元素"+ret);
System.out.println("数据出现的次数的统计");
fun3(arr);
}
/** Set的使用
*
* @param args
*/
//Set和Map的不同 1.set是继承自Collection的接口类,2.set中只放key
public static void main2(String[] args) {
Set<String> s = new HashSet<>();
s.add("aaa");
System.out.println(s);
System.out.println( s.contains("b"));
System.out.println(s.contains("aaa"));
}
四 Map(TreeMap/HashMap)区别和Set(TreeSet/HashSet)区别
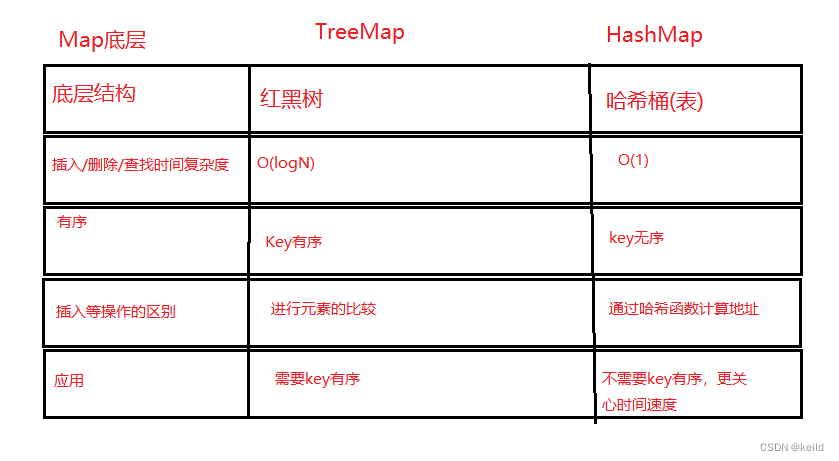
4.1TreeMap和HashMap的区别
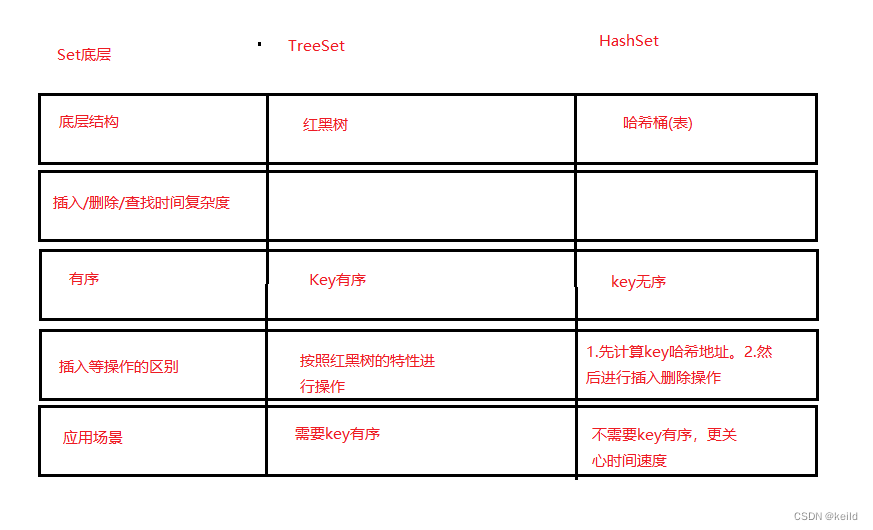
4.2 TreeSet和HashSet的区别
五 Map和Set应用场景
/**
* Map 和 Set 使用场景
* @param arr
*/
//1.10w数据的重复元素 删除掉
//使用HashSet去重
public static void fun1(int[] arr){
Set<Integer> set = new HashSet<>();
for(int i = 0; i < arr.length; i++){
set.add(arr[i]);
}
System.out.println(set);
}
//2.10w数据中 第一个重复的元素
public static int fun2(int[] arr){
Set<Integer> set = new HashSet<>();
for (int i = 0; i < arr.length; i++) {
if(!set.contains(arr[i])){//检查set中是否有key
set.add(arr[i]);//没有的话 放入
}else{
return arr[i];//有的话 就是第一个重复的元素
}
}
return -1;
}
//3.10w数据中,每个数据出现的次数
public static void fun3(int[] arr){
Map<Integer,Integer> map = new HashMap<>();
for(int i = 0; i < arr.length; i++){
int key = arr[i]; //
if(map.get(key) == null){//map中没有key
map.put(key,1);
}else{
int val = map.get(key);
map.put(key,val+1);
}
}
System.out.println(map);
}
//数据出现的次数统计
public static void main(String[] args){
int[] arr = new int[100000];
Random random = new Random();
for (int i = 0; i < arr.length; i++) {
arr[i] = random.nextInt(5000);
}
System.out.println("去除数据的重复元素");
fun1(arr);
int ret = fun2(arr);
System.out.println("数据中第一个重复的元素"+ret);
System.out.println("数据出现的次数的统计");
fun3(arr);
}
















 4525
4525











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











