







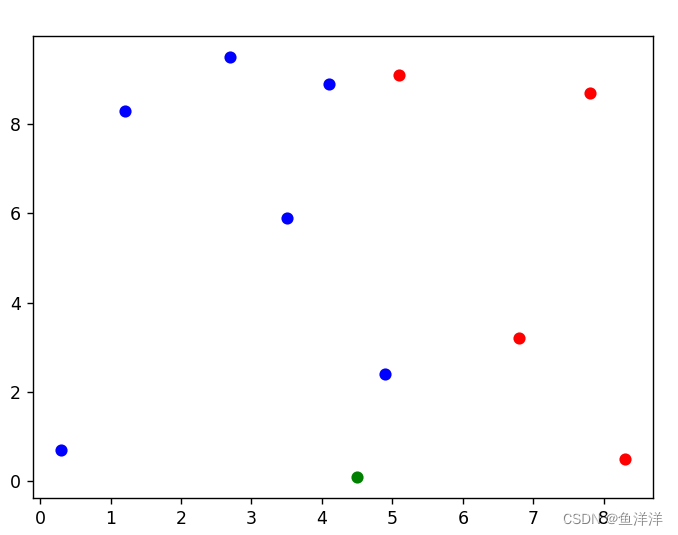
 KNN近邻法的简单例子:预测绿点为什么颜色
KNN近邻法的简单例子:预测绿点为什么颜色
邻近算法,或者说K最邻近(KNN,K-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一。所谓K最近邻,就是K个最近的邻居的意思,说的是每个样本都可以用它最接近的K个邻近值来代表。近邻算法就是将数据集合中每一个记录进行分类的方法
训练的数据集:将蓝点红点分别列出坐标值
训练的标签集:对应数据集的蓝点红点,蓝色阵营为1,红为0
测试的数据集:绿点的坐标值
import numpy as np
import matplotlib.pyplot as plt
# 训练的数据集x和标签集y
def load_data():
x = np.array([[0.3, 0.7],
[1.2, 8.3],
[2.7, 9.5],
[3.5, 5.9],
[4.1, 8.9],
[4.9, 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3253
3253

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









