






spider
前言
笔者作为一位爬虫方面约零基础同学
根据B站视频
并总结了相关教训和易错点,给出这份教程。
本文适合:
写过python代码,会安装库,但是没有接触过爬虫的同学。
一、代码详解
1.引入相关库
import requests # 数据请求模块
import re # 正则表达式模块
import os # 文件操作模块
如果没有相关库,先学习如何安装库
稍微解释一下这三个模块
- 数据请求模块 所谓爬虫,就是要模拟浏览器发请求嘛。这个模块有一个功能就是这样子,当然他还提供相关的辅助功能,例如返回结果的解析啊啥的
- 正则表达式模块 对于返回的内容都是一大片的html语言,我们需要利用“正则表达式”,方便地筛选出我们需要的内容(例如本代码需要的是歌曲的名字和链接地址)
- 文件操作模块 歌曲的链接地址找到了,你要保存下来,总得有路径吧,总得涉及到文件的操作吧
2.做好路径准备
filename = 'music\\'
if not os.path.exists(filename): # 如果不存在的话
os.mkdir(filename)
代码效果:
- 如果不存在music的文件夹,就创建一个music的文件夹
- 当然你也可以把‘music\\’改成别的名字,你喜欢就好
3.获取网页信息
url = 'https://music.163.com/discover/toplist?id=3778678'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36(KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
# print(response.text)
逐句解析
1.这个url是怎么来的?
搜索该音乐网站(见下方),点击进入后
可以看到有很多榜单(飙升榜、新歌榜……)
我们选择的是热歌榜(点击热歌榜)
我们的目的是下载热歌榜上的所有歌曲,那么该页面就是我们的目标
我们接下来所做的都是对这个页面进行分析
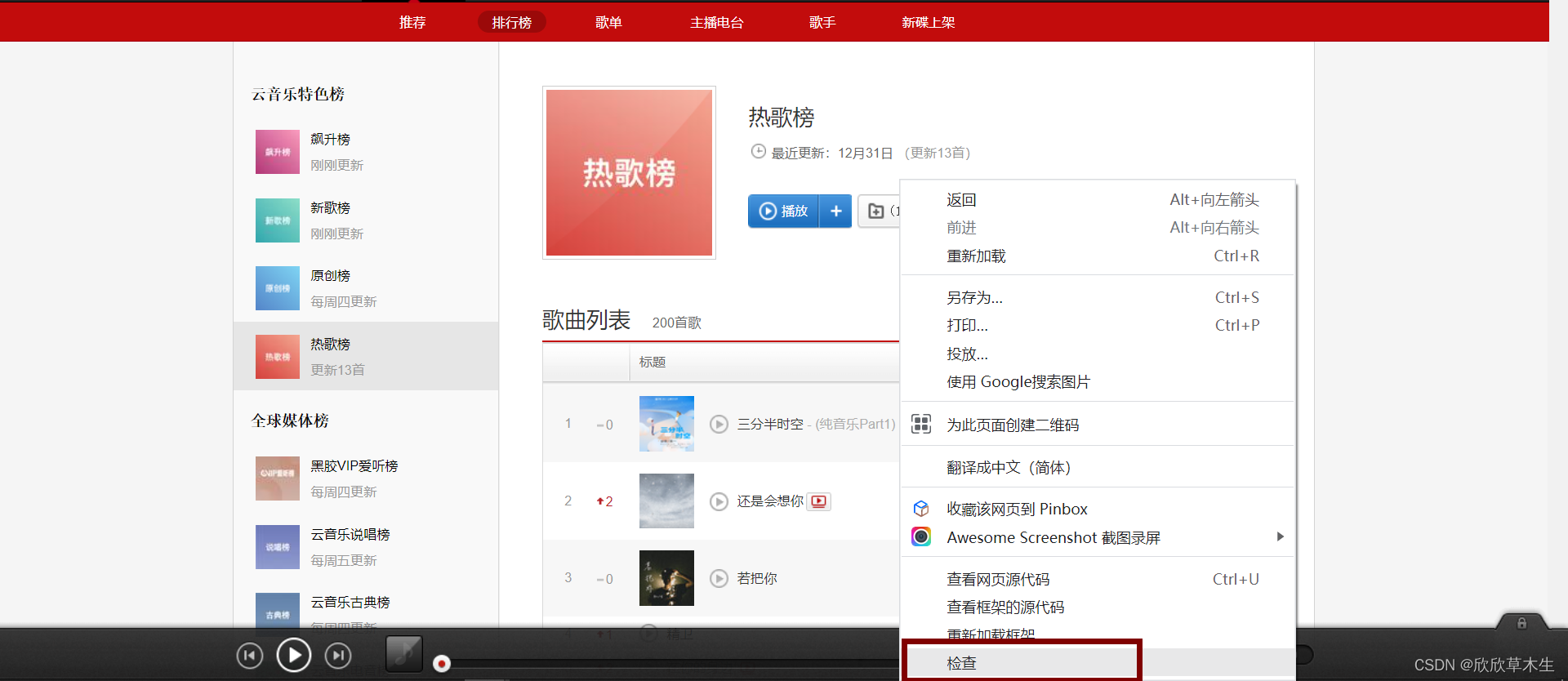
点击鼠标右键,再点击检查,进入检查页面。
(或者按F12,或者按Fn+F12)
那么打开这个检查以后呢,记得刷新(重新加载)一下页面
一定要刷新一下把数据内容重新加载一遍,在network模块中才会有相关记录,方便查找
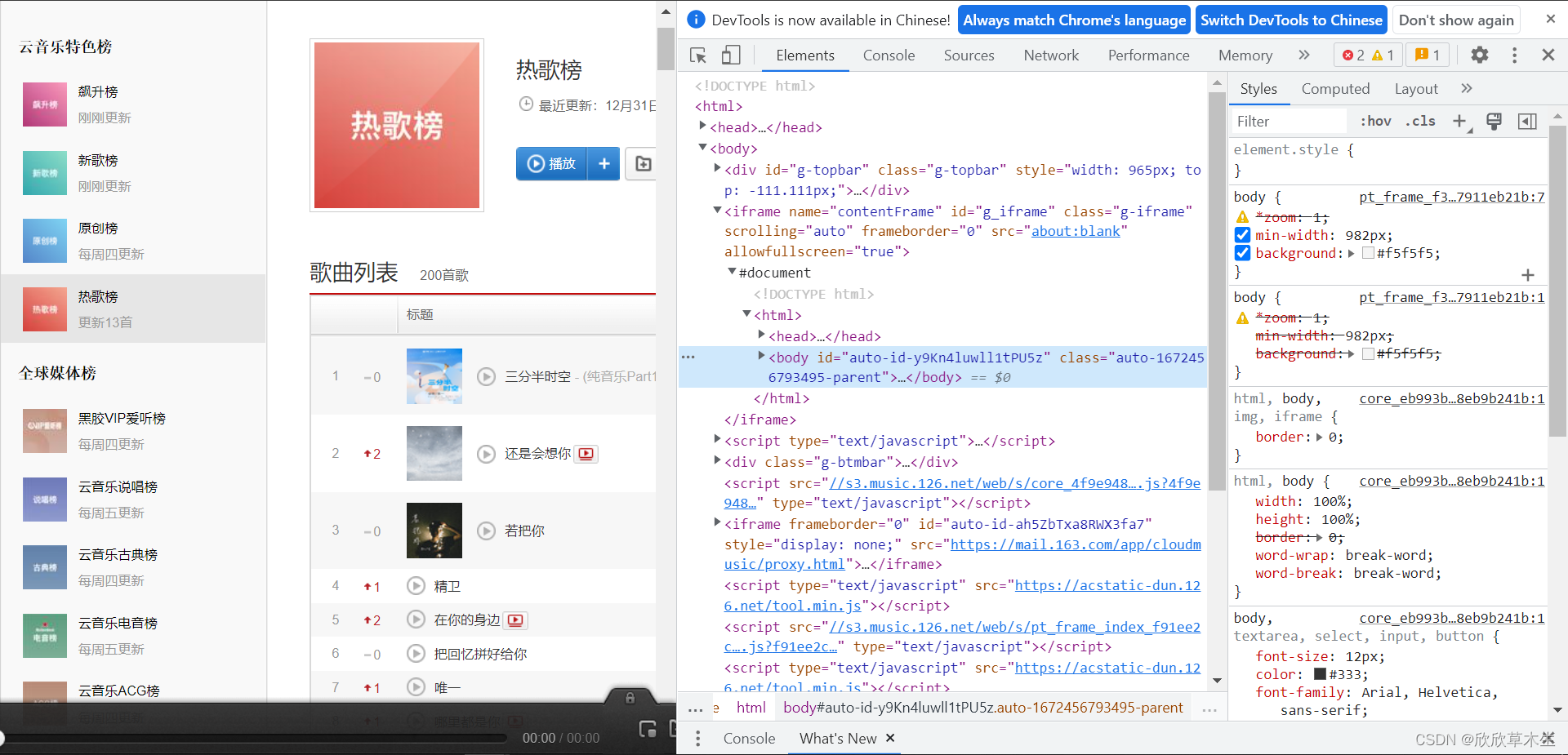
这个检查页面里有我们想要的信息
虽然全是英文,但是不用害怕,学会怎么看就行
每当我们发送一个请求,服务器就会返回我们一个response
我们通过解析response里面的内容获得想要的信息
我们看页面上有什么
要下载歌曲,我们看的要搜索歌曲相关的信息对吧
从上往下依次点击Network、放大镜、输入框(输入歌曲名字比方说第一首三分半时空)
再敲回车就可以进行搜索了

url来自于:点击headers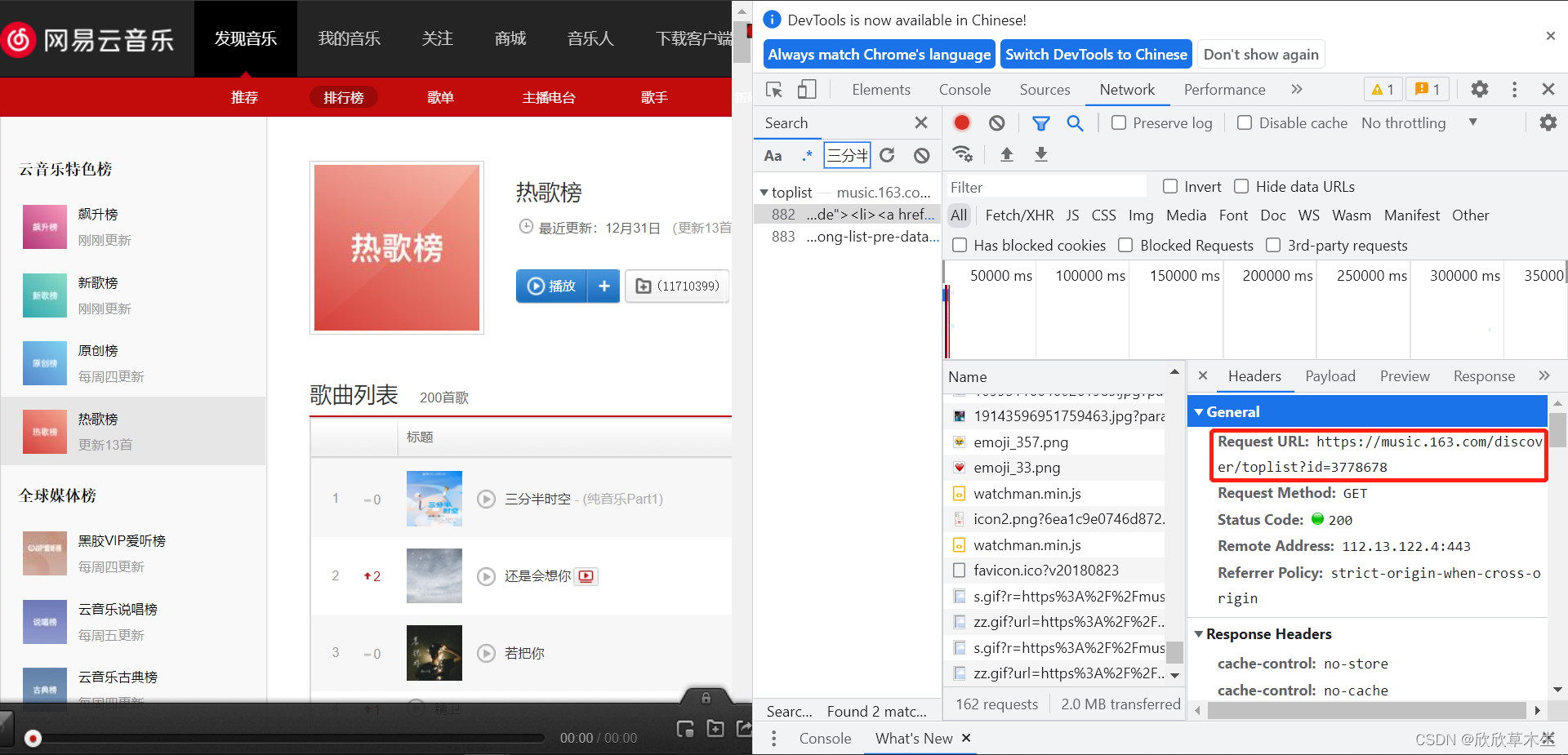
复制就行
其实把id号换成别的内容就是别的榜单
2.这个headers是怎么来的?
在刚刚的页面扒拉到最底下可以找到user_agent参数
把这段复制了就行
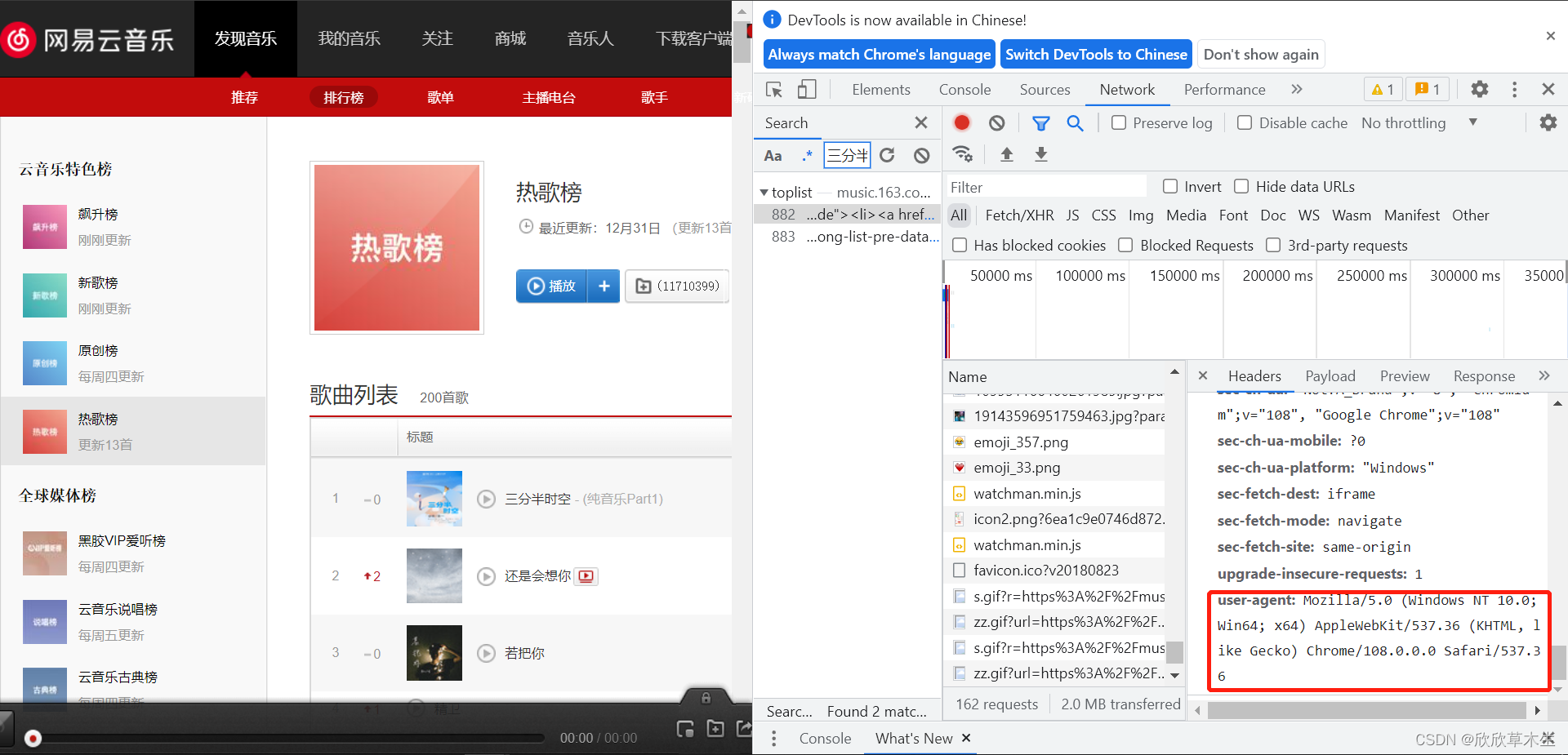
注意:空格别写多了
不要写成
headers = {
'user-agent': ' Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36(KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36'
}
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36(KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36 '
}
注意前后都不用加空格
3.这个最后一行是什么意思?
url就是被访问的地址,header就是要模拟的请求。
接下来就放出一只小爬虫,模拟headers中的样式,对url进行访问。
将返回的内容存到response变量中。
4.正则筛选内容
:所谓正则其实就是高阶版的查找,不知这样子是不是好理解些
html_data = re.findall('<li><a href="/song\?id=(\d+)">(.*?)</a>', response.text)
print(html_data)
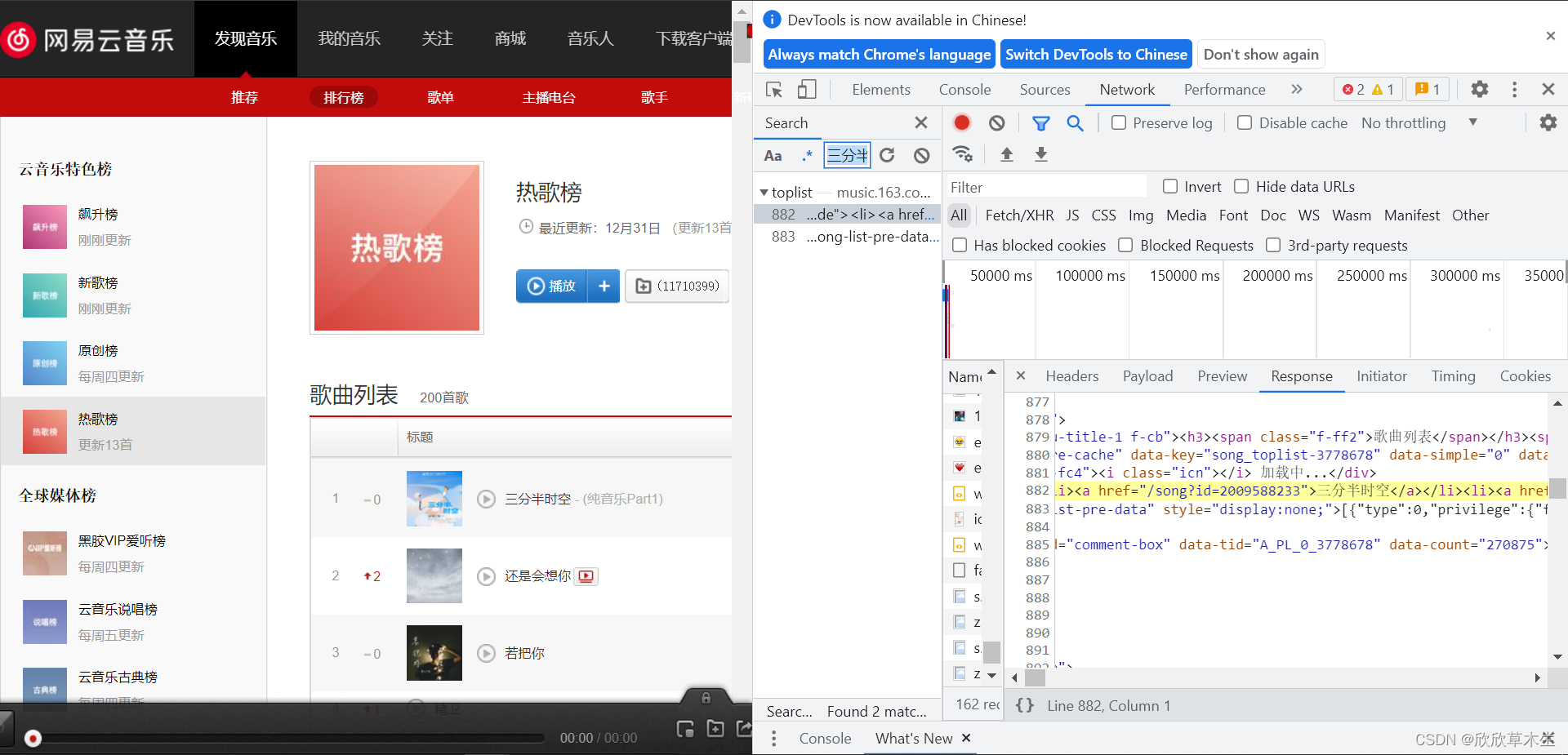
可以看到,我们所需要的信息:歌曲名和id号 都是以如下的信息存在
<li><a href="/song?id=2009588233">三分半时空</a></li><li><a href="/song?id=1827600686">还是会想你</a></li><li><a href="/song?id=865632948">若把你</a></li>......
我们需要在response返回的所有内容中将该信息提取出来
就用到了正则表达式
观察,不一样的地方只有id号(数字)和歌曲名(字符)不一样

在正则表达式的语法中
- 括号()代表整体
- \d+代表出现n个数字
- .*?代表出现n个字符
- (具体语法需要自己去学习)
html_data = re.findall('<li><a href="/song\?id=(\d+)">(.*?)</a>', response.text)
'''
.*具有贪婪的性质,首先匹配到不能匹配为止,根据后面的正则表达式,会进行回溯。
.*?则相反,一个匹配以后,就往下进行,所以不会进行回溯,具有最小匹配的性质。
?表示非贪婪模式,即为匹配最近字符 如果不加?就是贪婪模式a.*bc 可以匹配 abcbcbc'''
print(html_data)
使用re库进行正则,存到html_data中,以元组的列表形式存在。
5.进行下载
for num_id, title in html_data:
music_url = 'http://music.163.com/song/media/outer/url?id={music}.mp3'
music_content = requests.get(url=music_url, headers=headers).content
with open(filename + title + '.mp3', mode='wb') as f:
f.write(music_content)
print(num_id, title)
music_url 这个网址怎么来的?
------是别人提供的接口。
只要把{music}的地方换成歌曲的id号就可以听歌了。
例如访问http://music.163.com/song/media/outer/url?id=2009588233.mp3
可以出现id号为2009588233的歌曲《三分半时空》的听歌页面
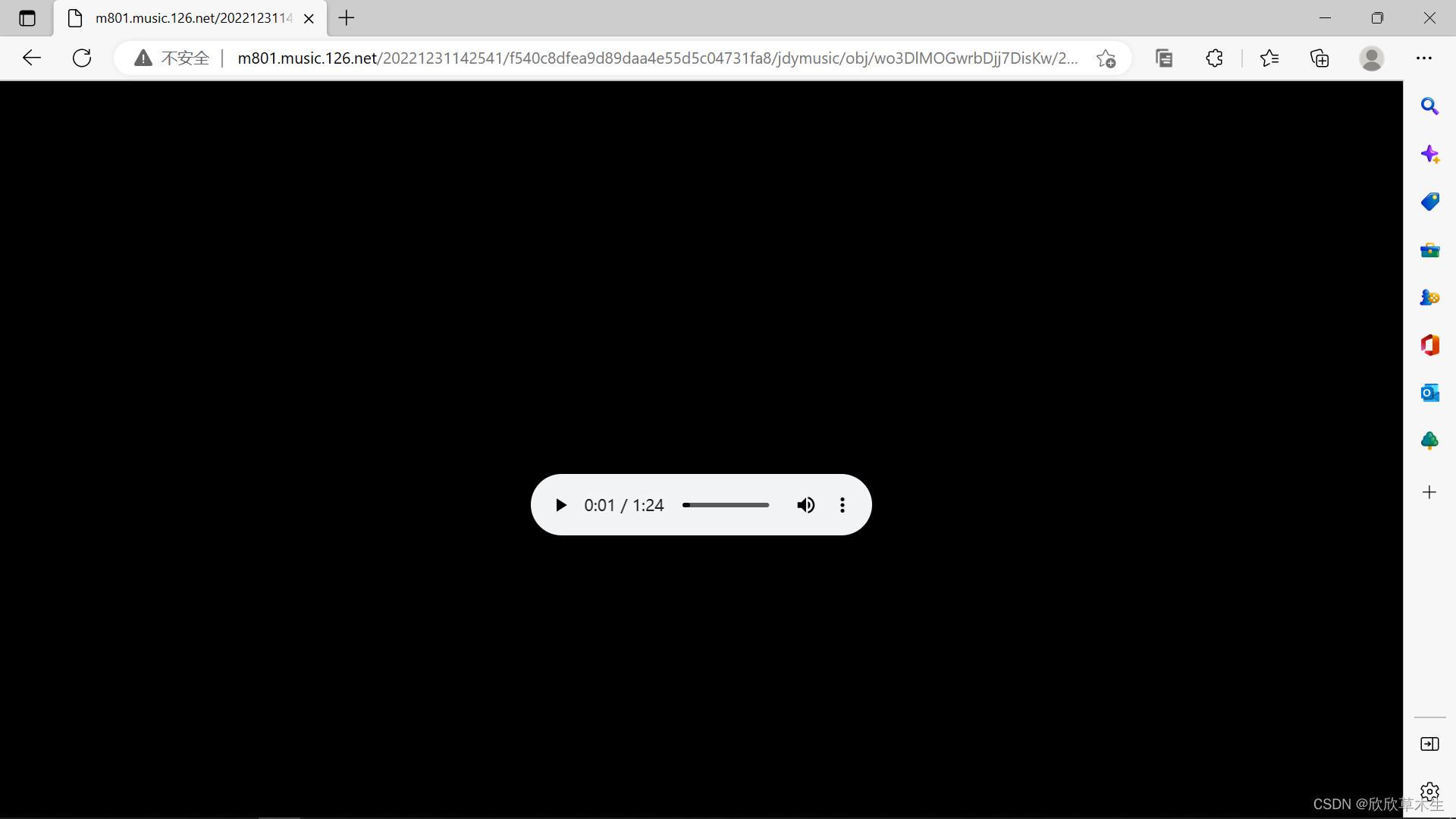
通过调用request的get方法,获取页面内容,并保存到文件夹中。
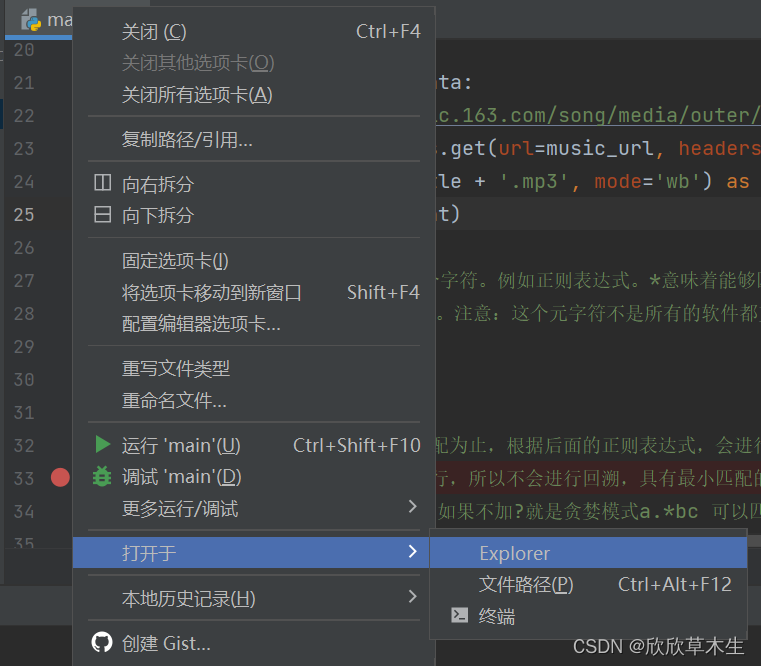
二、如何查找你的music文件夹
右键点击py文件,左键点击打开于, explorer

三、完整代码如下
import requests # 数据请求模块
import re # 正则表达式模块
import os # 文件操作模块
filename = 'music\\'
if not os.path.exists(filename):
os.mkdir(filename)
url = 'https://music.163.com/discover/toplist?id=3778678'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36(KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
# print(response.text)
html_data = re.findall('<li><a href="/song\?id=(\d+)">(.*?)</a>', response.text)
print(html_data)
for num_id, title in html_data:
music_url = 'http://music.163.com/song/media/outer/url?id={music}.mp3'
music_content = requests.get(url=music_url, headers=headers).content
with open(filename + title + '.mp3', mode='wb') as f:
f.write(music_content)
print(num_id, title)
【复制了直接跑就行】
















 1132
1132

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









