 硬件与模型部署:rknn工具链与yolov5在路口行人识别中的应用
硬件与模型部署:rknn工具链与yolov5在路口行人识别中的应用




 本文详细描述了在硬件环境中,如何准备训练数据、使用rknn-toolkit进行模型转换、通过adb连接进行设备管理,以及使用yolov5进行行人检测和结果输出的过程。
本文详细描述了在硬件环境中,如何准备训练数据、使用rknn-toolkit进行模型转换、通过adb连接进行设备管理,以及使用yolov5进行行人检测和结果输出的过程。
我负责硬件方面,首先先提交好训练比赛样本,方便我们下一步的操作:
1:先将训练比赛的提交,以下记录这次操作
首先,根据环境搭配,我们先弄好板卡和基本命令操作。
下载好车行人识别:
路口车辆行人识别例程网盘下载;
链接:https://pan.baidu.com/s/1VI7OYCX0xF-F9YkdHS7ncA
提取码:0825
下载的文件包中含有两个子文件加成,如下图所示:

将模型放到ubuntu中,可以放到rknn-toolkit(自己创造一个)文件下面。
启动环境配置下面的bash环境,也就是docker,使用这个进行一个模型变换,下面是进入docker的命令(配置请看之前的pdf文档)
docker run -t -i --privileged -v /dev/bus/usb:/dev/bus/usb -v /home/developer/rknn-toolkit/model_convert:/test rknn-toolkit:1.7.1 /bin/bash
进入之后如下图所示:(你没看错,我们的前缀不一样)不用怀疑

进入我们的模型中,根据下面指示进行即可:如图
cd test/
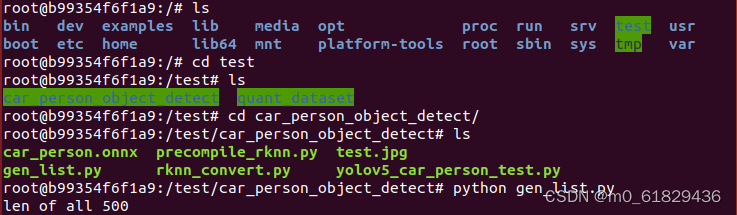
我们先进行了gen_list.py文件的使用,具体作用是:
import os
import random
def main(image_dir):
# 定义保存图片路径的txt文件路径
save_image_txt = './pic_path.txt'
# 定义保存验证集数量的变量
save_val_number = 0
# 定义一个空列表,用于保存图片文件的路径
img_path_list = []
# 使用os.listdir()函数获取指定目录下的文件列表,并遍历每个文件
image_list = os.listdir(image_dir)
for i in image_list:
# 构建图片文件的完整路径
image_path = os.path.join(image_dir, i)
# 将image_path添加到img_path_list中
img_path_list.append(image_path)
# 打印所有图片的数量
print('len of all', len(img_path_list))
# 使用random.shuffle()函数打乱img_path_list中的元素顺序
random.shuffle(img_path_list)
# 使用with open()语句打开save_image_txt文件,并以写入模式打开
with open(save_image_txt, 'w') as F:
# 遍历img_path_list列表,将每个元素写入txt文件中,每个路径占一行
for i in range(len(img_path_list)):
F.write(img_path_list[i]+'\n')
if __name__ == '__main__':
# 设置指定目录的路径
image_dir = '/test/quant_dataset/car_person_data'
# 调用主函数
main(image_dir)
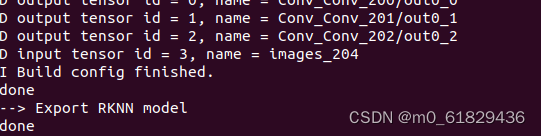
随后进行模型转换,用于python rknn_convert.py ,将.onnx变成.rknn。出现这个就是成功了。
接下来就是关于adb方面的连接和关闭。先关闭虚拟机上面的adb服务,在docker里面下载adb.代码如下:
apt install adb
重新开一个终端,关闭adb在本机上的服务,
adb kill-server
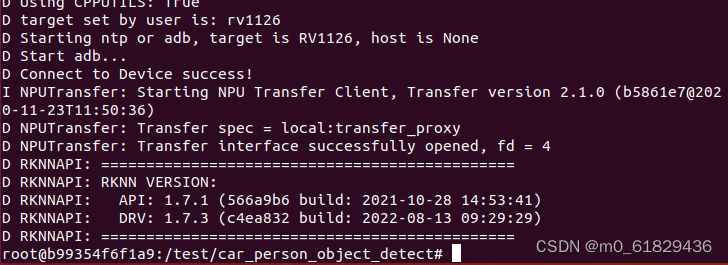
在使用adb devices之后,docker环境里面出现了下面这种形式就可以了。

接下来就可以进行一个预编译了,稍等片刻就可。
python precompile_rknn.py
完成之后会出现下面的图片:
好的,预编译完成,将文件保存,经过机不操作,有下面的文件添加
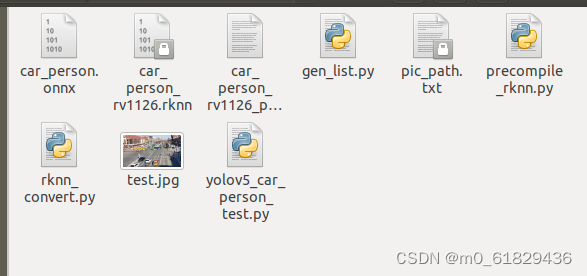
保存好预编译的文件。
下面操作就是进行交叉编译环境操作,运行./run.sh文件,进入交叉编译环境。
然后直接进入 cd /opt/文件,这是对应的映射文件,可以看到我们电脑里面的主文件。
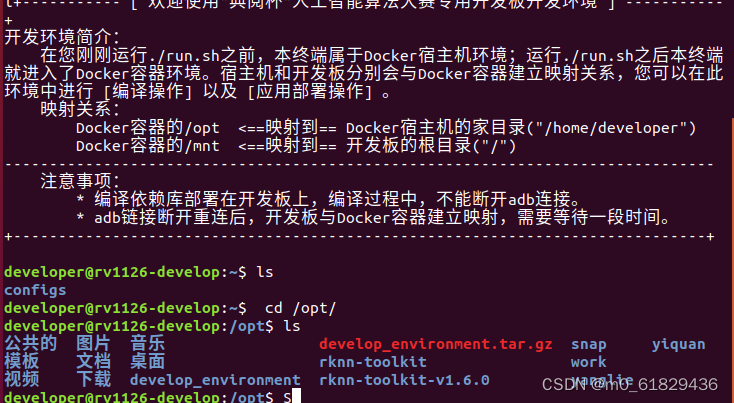
进入里面,进行一个编译即可。
运行编译文件:(注意前缀)
./bulid.sh
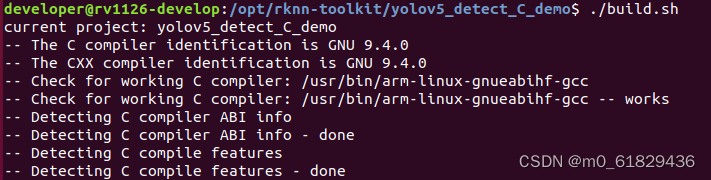
然后把东西传到板卡上面即可:
cp yolov5_detect_demo_release/ /mnt/userdata/ -rf
另外开启一个终端,我们就可以在板卡里面进行已给运行了。
注意adb的连接。运行之后,退出板卡环境,将运行好的图片取出来(注:记得退出板卡环境)
adb pull /userdata/yolov5_detect_demo_release/result.jpg
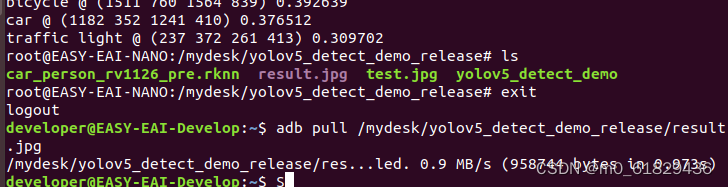
上面是所有的基本步骤,接下来,是关于如何运行多张图片的步骤。我们只需要改变.cpp文件的代码就可以了,如下:
#include <opencv2/opencv.hpp>
#include <stdio.h>
#include <sys/time.h>
#include"yolov5_detect.h"
#include <dirent.h>
using namespace cv;
using namespace std;
static Scalar colorArray[10]={
Scalar(255, 0, 0, 255),
Scalar(0, 255, 0, 255),
Scalar(0,0,139,255),
Scalar(0,100,0,255),
Scalar(139,139,0,255),
Scalar(209,206,0,255),
Scalar(0,127,255,255),
Scalar(139,61,72,255),
Scalar(0,255,0,255),
Scalar(255,0,0,255),
};
int plot_one_box(Mat src, int x1, int x2, int y1, int y2, char *label, char colour)
{
int tl = round(0.002 * (src.rows + src.cols) / 2) + 1;
rectangle(src, cv::Point(x1, y1), cv::Point(x2, y2), colorArray[colour], 3);
int tf = max(tl -1, 1);
int base_line = 0;
cv::Size t_size = getTextSize(label, FONT_HERSHEY_SIMPLEX, (float)tl/3, tf, &base_line);
int x3 = x1 + t_size.width;
int y3 = y1 - t_size.height - 3;
rectangle(src, cv::Point(x1, y1), cv::Point(x3, y3), colorArray[colour], -1);
putText(src, label, cv::Point(x1, y1 - 2), FONT_HERSHEY_SIMPLEX, (float)tl/3, cv::Scalar(255, 255, 255, 255), tf, 8);
return 0;
}
int main(int argc, char **argv) {
/* 参数初始化 */
int output_nboxes_left = 0;
coco_detect_result_group_t detect_result_group;
/* 算法模型初始化 */
rknn_context ctx;
coco_detect_init(&ctx, "./car_person_rv1126_pre.rknn");
/* 图片文件夹路径 */
std::string folder_path = "picture/";
/* 遍历文件夹 */
DIR *dir;
struct dirent *ent;
if ((dir = opendir(folder_path.c_str())) != NULL) {
while ((ent = readdir(dir)) != NULL) {
std::string file_name = ent->d_name;
if (file_name == "." || file_name == "..") {
continue;
}
/* 算法运行 */
Mat src, rgb_img;
std::string file_path = folder_path + file_name;
src = imread(file_path, 1);
cvtColor(src, rgb_img, COLOR_BGR2RGB);
struct timeval start;
struct timeval end;
float time_use = 0;
gettimeofday(&start, NULL);
coco_detect_run(ctx, rgb_img, &detect_result_group);
gettimeofday(&end, NULL);
time_use = (end.tv_sec - start.tv_sec) * 1000000 + (end.tv_usec - start.tv_usec); // 微秒
printf("time_use is %f\n", time_use / 1000);
/* 算法结果在图像中画出并保存 */
for (int i = 0; i < detect_result_group.count; i++) {
coco_detect_result_t *det_result = &(detect_result_group.results[i]);
if (det_result->prop < 0.3) {
continue;
}
printf("%s @ (%d %d %d %d) %f\n",
det_result->name,
det_result->box.left, det_result->box.top, det_result->box.right, det_result->box.bottom,
det_result->prop);
int x1 = det_result->box.left;
int y1 = det_result->box.top;
int x2 = det_result->box.right;
int y2 = det_result->box.bottom;
char label_text[50];
memset(label_text, 0, sizeof(label_text));
sprintf(label_text, "%s %0.2f", det_result->name, det_result->prop);
plot_one_box(src, x1, x2, y1, y2, label_text, i % 10);
}
std::string save_folder = "./res/"; // 例如:std::string save_folder = "/home/user/recognize_results/";
std::string save_path = save_folder + "result_" + file_name;
imwrite(save_path, src);
}
closedir(dir);
} else {
/* 无法打开文件夹 */
perror("");
return EXIT_FAILURE;
}
/* 算法模型空间释放 */
coco_detect_release(ctx);
return 0;
}
随后进行操作即可。得到结果如下:(当然,这样子是不好看的,并且不好传输回来)所以我们将图片放到一个文件夹里面,方便传输。
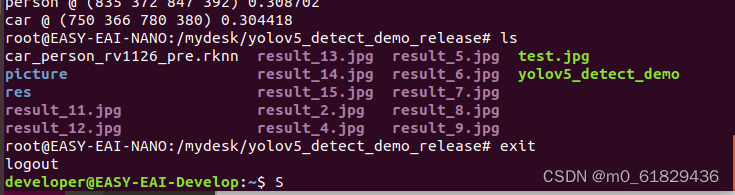
改变之后:
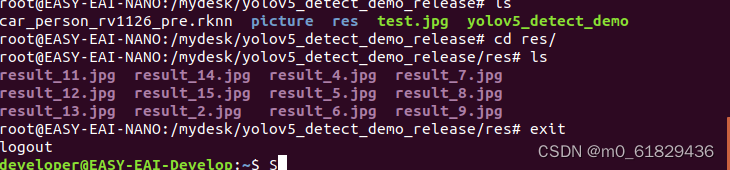
传输回来,就可以在本机上看到识别出来的图片
adb pull /userdata/yolov5_detect_demo_release/res/
接下来就是关于怎么把我们得到的结果传上去了。


















 80
80

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









