






这周的工作主要是数字人模型原理解读,为了之后部署做准备
之前第三周的时候调研过的数字人模型SadTalker,对应论文地址为:https://arxiv.org/abs/2211.12194
这个模型是为了对图片和音频进行3D人脸运动数字人生成
通过人脸图像生成说话的头部视频,一段语音音频仍然包含许多挑战,即不自然的头部运动、扭曲的表达和身份修改。论文认为这些问题主要是由于从耦合的 2D 运动场中学习。另一方面,明确使用 3D 信息也存在表达僵硬和不连贯视频的问题。论文提出了 SadTalker,它从音频中生成 3DMM 的 3D 运动系数(头部姿势、表情),并隐式调制一种新颖的 3D 感知人脸渲染,用于说话头部生成
这篇论文的贡献有:
• 提出了 SadTalker,这是一种使用生成的逼真的 3D 运动系数进行风格化音频驱动的单幅图像说话人脸动画的新系统。
• 为了从音频中学习 3DMM 模型的真实 3D 运动系数,分别提出了 ExpNet 和 PoseVAE。
• 提出了一种新的语义解缠和 3D 感知人脸渲染来生成逼真的说话头视频。
主流程

使用3DMM的系数作为中间运动表示。首先从音频中生成逼真的3D运动系数(面部表情β、头部姿势ρ),然后使用这些系数隐式地调制3D感知面部渲染,以生成最终的视频。
可以看成两步:音频驱动的运动系数生成,和运动系数驱动的图像动画生成
使用VoxCeleb数据集进行训练,其中包含超过10万个1251名受试者的视频。将视频大小调整为256×256
由于一些视频和音频在VoxCeleb中没有对齐,论文选择了46名受试者的1890个对齐的视频和音频来训练我们的PoseVAE和ExpNet。输入音频被下采样到16kHz,并转换为具有与Wav2lip相同设置的mel频谱图。
expnet的结构如下:
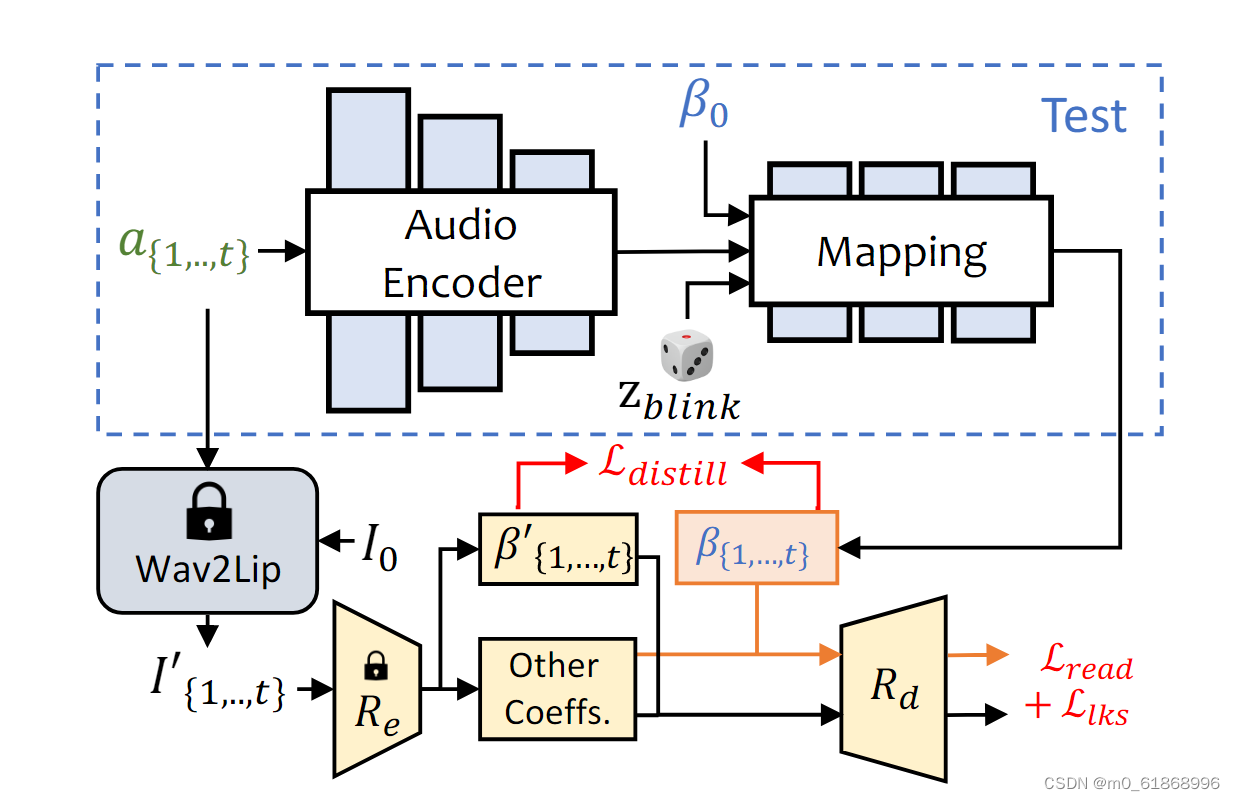
使用单眼3D人脸重建模型(Re和Rd)来学习逼真的表情系数。其中Re是预训练的3DMM系数估计器,Rd是没有可学习参数的可微分3D人脸渲染。使用参考表达式β0来降低同一性的不确定性,并且从预训练的Wav2Lip和第一帧生成的帧作为目标表达系数,因为它只包含嘴唇相关的运动。
poseVAE的网络结构图如下:
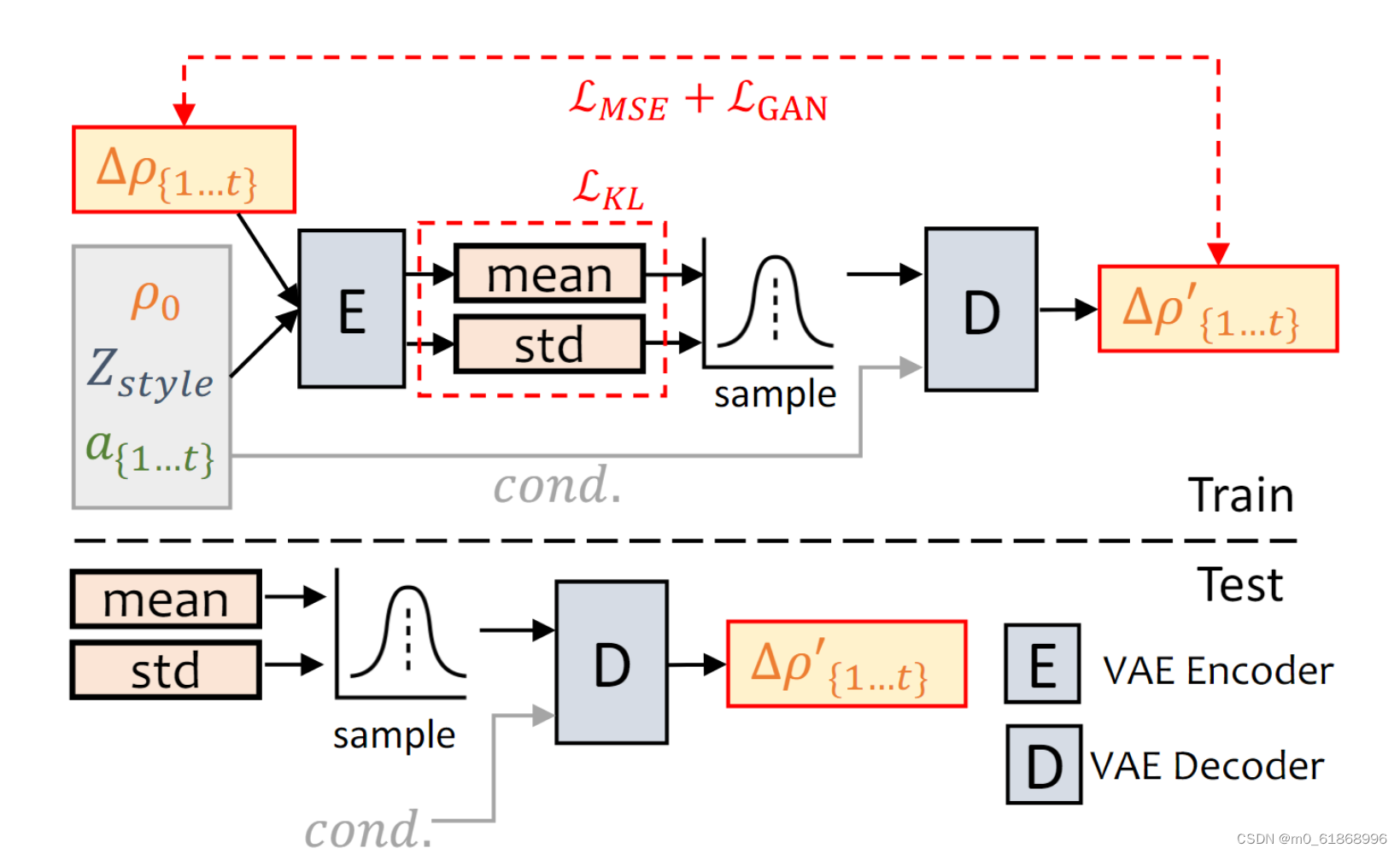
通过条件VAE结构来学习输入头部姿态ρ0的残差。给定条件:第一帧ρ0,风格标识Zstyle和音频片段a{1,…,t},我们的方法学习残差头部姿态∆ρ{1,..,t}=ρ{1…,t}-ρ0的分布。经过训练后,我们可以仅通过姿势解码器和条件(cond.)生成风格化的结果。
faceRender的网络(以及和fice vid2vid的比较):
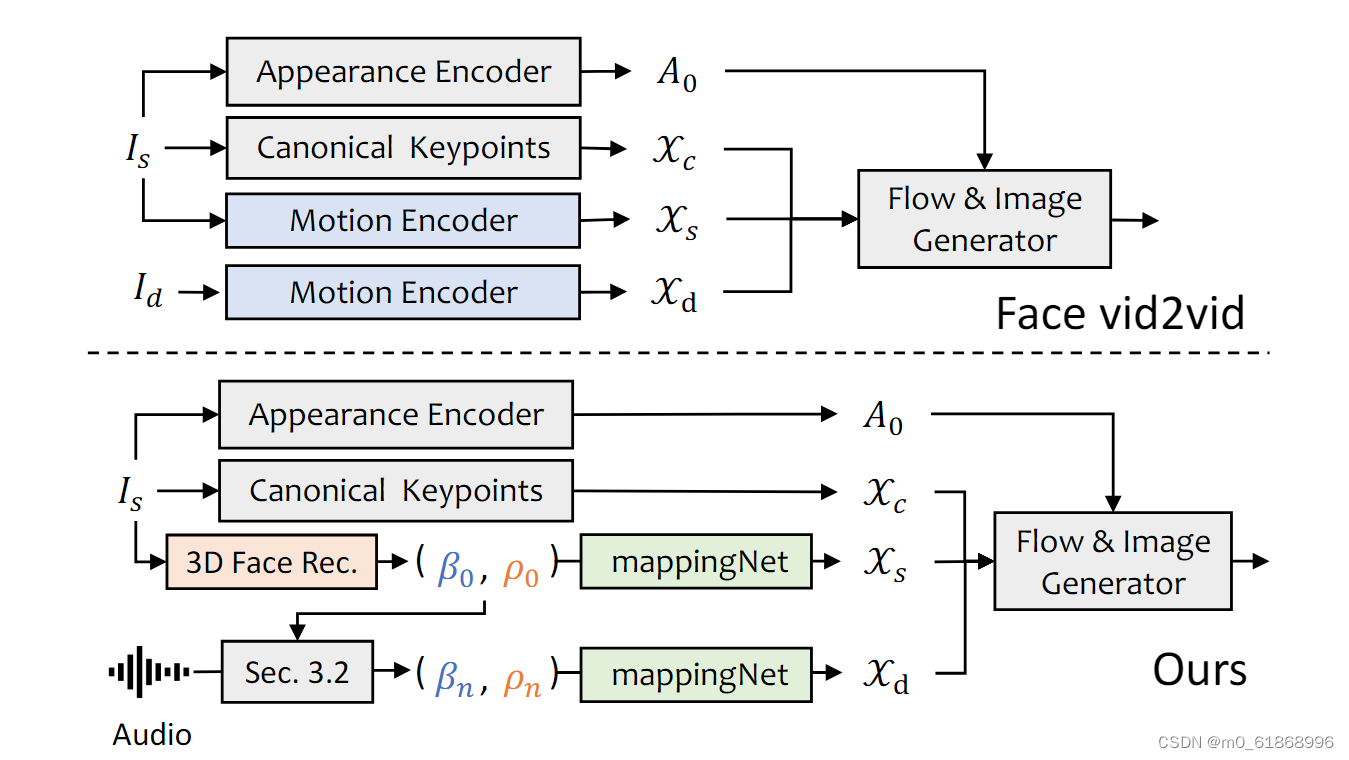
给定源图像Is和驱动图像Id,facevid2vid在Xc、Xs和Xd的无监督3D关键点空间中生成运动。然后,可以通过外观A0和关键点来生成图像。由于我们没有驱动图像,我们使用显式解纠缠的3DMM系数作为代理,并将其映射到无监督的3D关键点空间。
这里facevid2vid是也是人脸视频生成的一篇论文中的方法,但是需要真实的视频作为运动驱动信号
SadTalker的人脸渲染使其可以通过3DMM系数进行驱动。















 877
877











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









