







论文

论文:Multi-Content Complementation Network for Salient Object Detection in Optical Remote Sensing Images
发表: IEEE TGRS, vol. 60, pp. 1-13, 2022
https://arxiv.org/abs/2112.01932
代码: https://github.com/mathlee/mccnetGitHub - MathLee/MCCNet: [TGRS2022] [MCCNet] Multi-Content Complementation Network for Salient Object Detection in Optical Remote Sensing Images
正文
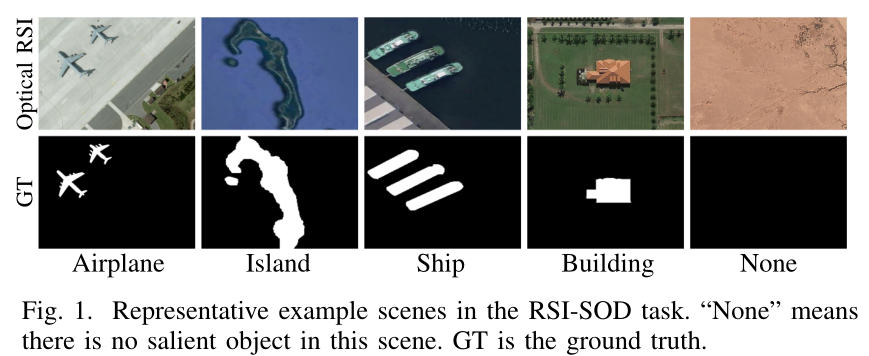
动机
光学遥感图像显著性目标检测(RSI-SOD),很具有挑战性。现有的SOD方法多是自然场景(NSI),但两者间存在较大差异。(获取方式差异很大,使得两种图像差异很大,NSI使用手机、相机等设配拍摄,RSI使用卫星或航空器拍摄)。直接将NSI-SOD的方式用于RSI-SOD可能不合适,以前的工作借鉴NSI-SOD和结合RSI的特点提出解决方案证明是可行的,本文结合前人的工作(前景特征、边缘特征、背景特征单独使用都是有效的,BCE损失、IoU损失、度量感知F-m损失也能work),提出自己的方法。
做法
- 提出多内容互补网络( Multi-Content Complementation Network,MCCNet)来探索RSI-SOD多内容的互补性。在多尺度特征上使用MCCM模块,利用前景特征、边缘特征、背景特征和全局图像级特征间的内容互补性,通过注意力机制来突出RSI特征在不同尺度上的显著区域。
- 结合三种损失构成综合损失,并加入边缘损失,共同监督模型的训练。
网络架构
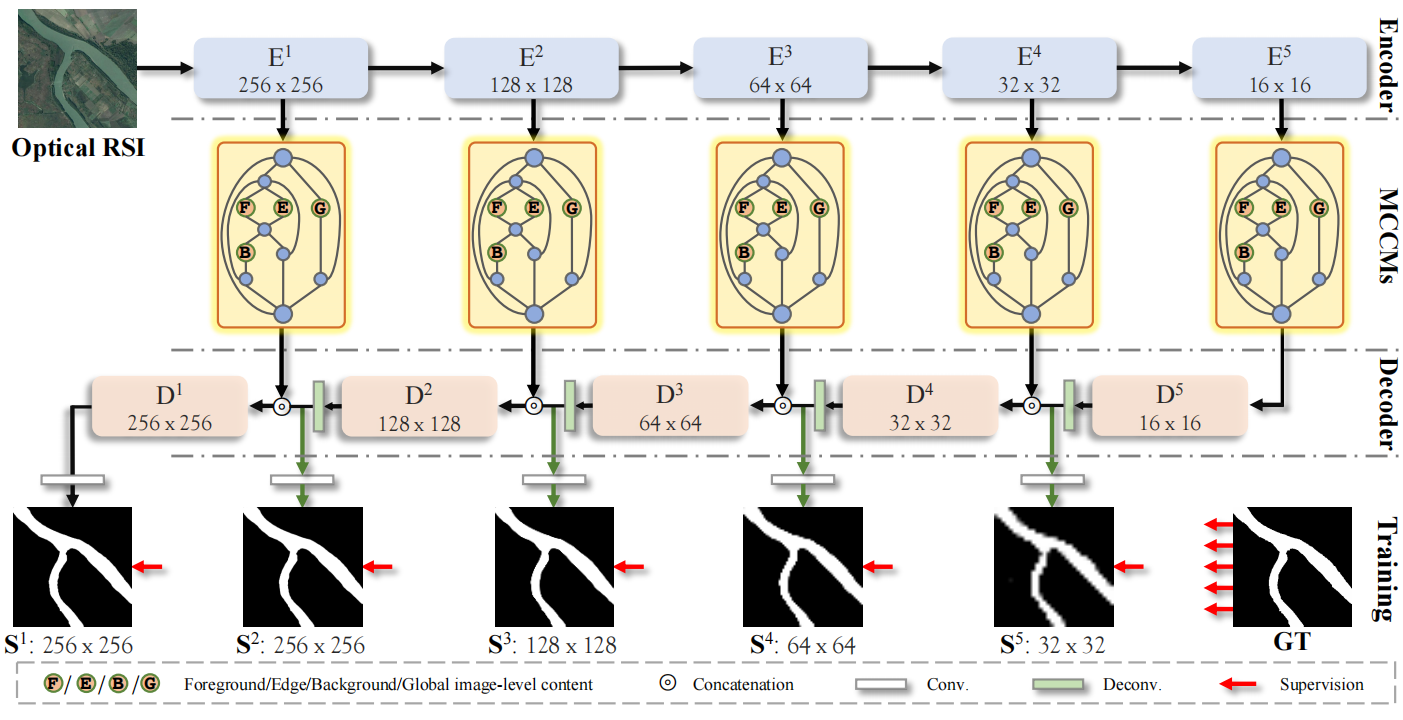
 MCCNet由三个部分组成:编码器网络、5个MCCM组件、解码器网络。
MCCNet由三个部分组成:编码器网络、5个MCCM组件、解码器网络。
- 编码器网络,用vgg16提取基本特征;
- 5个MCCM组件,对前景、边缘、背景和全局图像特征间的互补信息进行建模;
- 解码器网络,逐级上采样推断出显著目标。
训练时对5层进行监督,采用三种损失。 同时利用边缘损失监督MCCM中的产生的边缘。
Multi-Content Complementation Module,MCCM
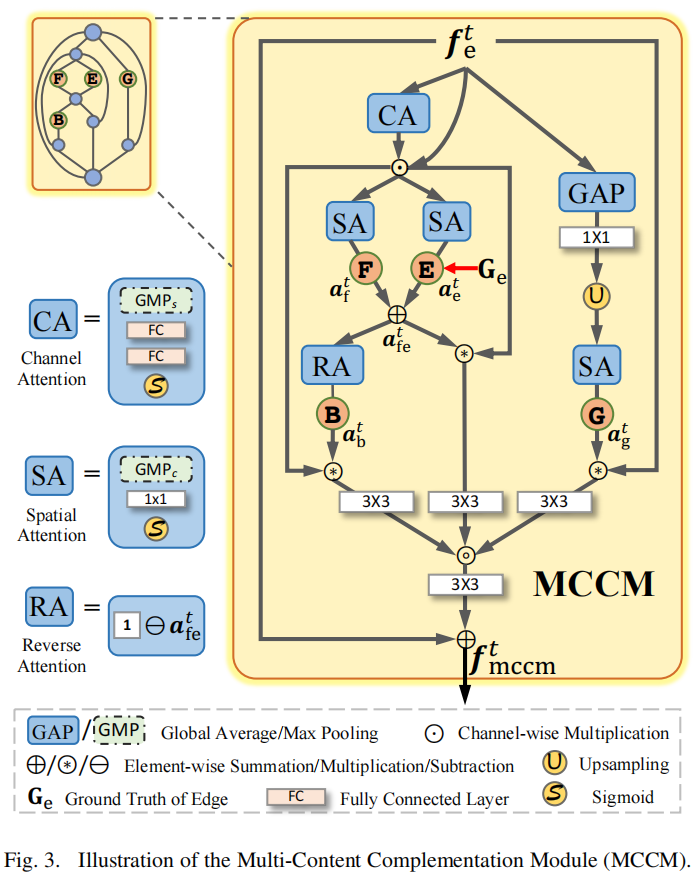
设计动机: 前景特征、背景特征、边缘特征都有助于显著性检测,于是提出多内容互补模块(MCCM)结合它们,并添加全局信息。
输入:编码器提取的特征;输出:多内容互补特征。 中间过程:产生4种不同类型特征,并进行聚合。(看图或代码即可,后面附有代码)
前景和边缘特征,都与显著区域相关,相辅相成,求和聚集。 背景特征,由前者取反得到,关注到非显著区域。 前面三者包含了局部细节。 全局信息,丢失细节信息,捕捉特征整体基调。
4种特征聚合方式:拼接后卷积,再相加。
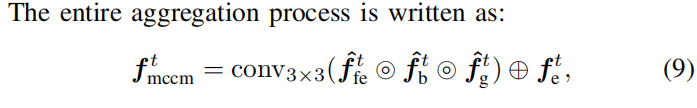
MCCM 特征可视化

损失函数

实验
23个对比方法在两个数据集上的实验
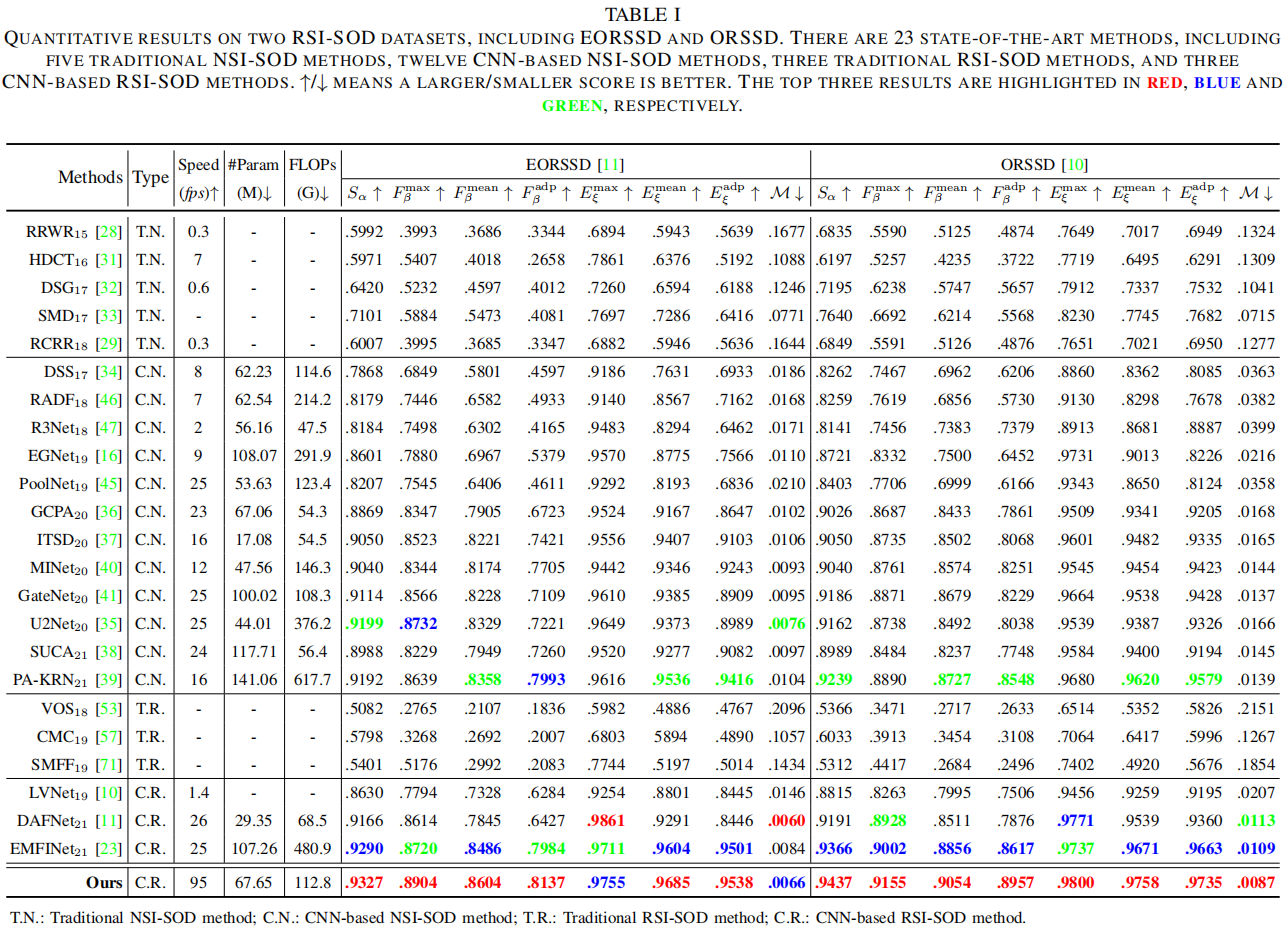

不同场景不同方法可视化效果对比
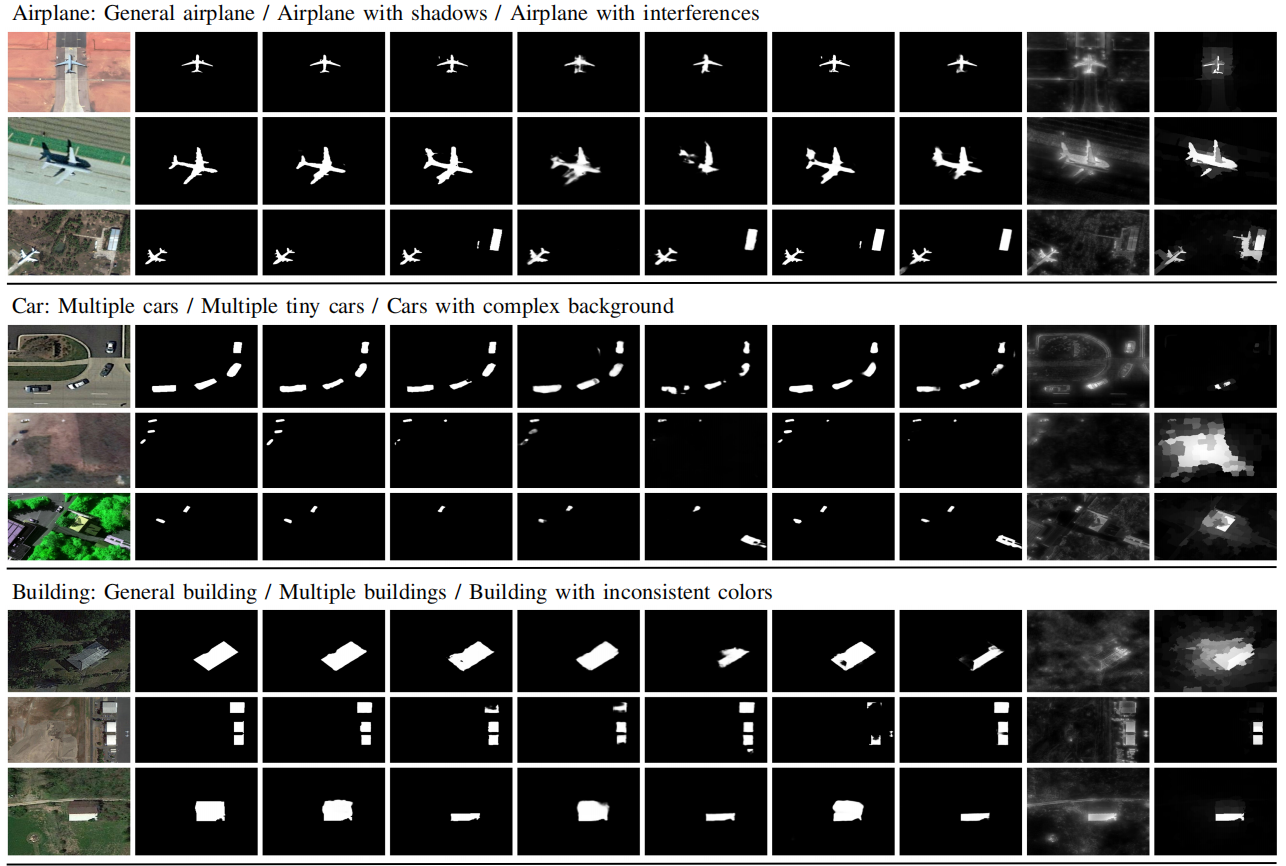

消融实验
验证MCCM中不同特征都能work,相互间存在互补性
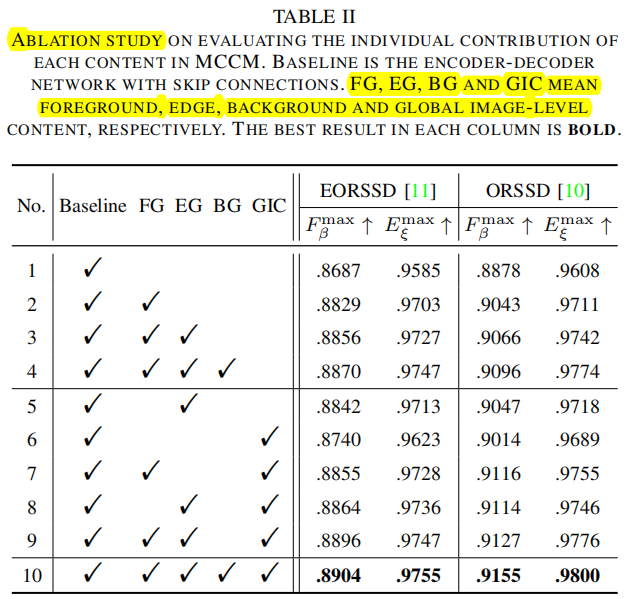
消融的MCCM具体结构
MCCM中残差路径的效果提升
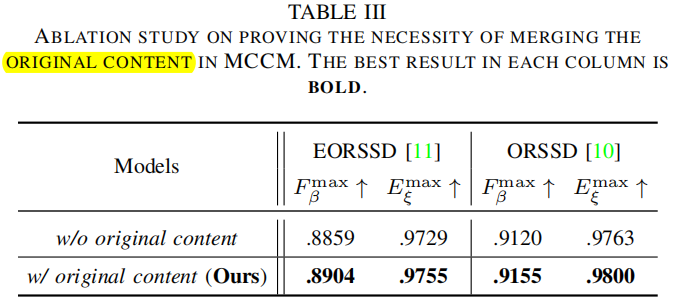
使用不同损失组合的性能比较
关键代码 MCCM
# https://github.com/MathLee/MCCNet/blob/main/model/MCCNet_models.py
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import os
# 定义一个卷积操作:卷积+BN+ReLU
class BasicConv2d(nn.Module):
def __init__(self, in_planes, out_planes, kernel_size, stride=1, padding=0, dilation=1):
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(in_planes, out_planes,
kernel_size=kernel_size, stride=stride,
padding=padding, dilation=dilation, bias=False)
self.bn = nn.BatchNorm2d(out_planes)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.relu(x)
return x
# 通道注意力(SE)
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc1 = nn.Conv2d(in_planes, in_planes // 16, 1, bias=False)
self.relu1 = nn.ReLU()
self.fc2 = nn.Conv2d(in_planes // 16, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))
out = max_out
return self.sigmoid(out)
# 空间注意力 SA
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv1 = nn.Conv2d(1, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = max_out
x = self.conv1(x)
return self.sigmoid(x)
# 空间注意力,不带sigmoid
class SpatialAttention_no_s(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention_no_s, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv1 = nn.Conv2d(1, 1, kernel_size, padding=padding, bias=False)
# self.sigmoid = nn.Sigmoid()
def forward(self, x):
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = max_out
x = self.conv1(x)
return x
# Multi-Content Complementation Module,MCCM
class MCCM(nn.Module):
def __init__(self, cur_channel):
super(MCCM, self).__init__()
self.relu = nn.ReLU(True)
self.ca = ChannelAttention(cur_channel)
self.sa_fg = SpatialAttention_no_s()
self.sa_edge = SpatialAttention_no_s()
self.sigmoid = nn.Sigmoid()
self.FE_conv = BasicConv2d(cur_channel, cur_channel, 3, padding=1)
self.BG_conv = BasicConv2d(cur_channel, cur_channel, 3, padding=1)
self.global_avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv1 = BasicConv2d(cur_channel, cur_channel, 1)
self.sa_ic = SpatialAttention()
self.IC_conv = BasicConv2d(cur_channel, cur_channel, 3, padding=1)
self.FE_B_I_conv = BasicConv2d(3 * cur_channel, cur_channel, 3, padding=1)
def forward(self, x):
x_ca = x.mul(self.ca(x))
# Foreground attention
x_sa_fg = self.sa_fg(x_ca)
# Edge attention
x_edge = self.sa_edge(x_ca)
# Foreground and Edge (FE) feature
x_fg_edge = self.FE_conv(x_ca.mul(self.sigmoid(x_sa_fg) + self.sigmoid(x_edge)))
# Background feature
x_bg = self.BG_conv(x_ca.mul(1 - self.sigmoid(x_sa_fg) - self.sigmoid(x_edge)))
# Image-level content
in_size = x.shape[2:]
x_gap = self.conv1(self.global_avg_pool(x))
x_up = F.interpolate(x_gap, size=in_size, mode="bilinear", align_corners=True)
x_ic = self.IC_conv(x.mul(self.sa_ic(x_up)))
x_RE_B_I = self.FE_B_I_conv(torch.cat((x_fg_edge, x_bg, x_ic), 1))
return (x + x_RE_B_I), x_edge














 502
502











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









