






小样本图像分类
1.什么是小样本图像分类?
小样本图像分类能够利用的少量样本, 即一个或者几个样本进行图像分类.
2.为什么要小样本图像分类?
一是数据量少. 比如在医疗领域, 医学影像的产生来源于病例,通常少量的病例并不能够辅助机器对医疗影像进行分析.
二是让机器学会以人类的方式进行学习.人类能够在获取少量样本的情况下, 对样本进行分类和识别, 并且具有快速理解新概念并将其泛化的能力。
3.小样本图像分类难点有哪些?
难点在于训练样本的数量太少,很容易过拟合
常用方法:Meta-learning(元学习):又称“学会学习“(Learning to learn), 即利用以往的知识经验来指导新任务的学习,使网络具备学会学习的能力。元学习的目标是利用已经学到的知识来解决新的问题。这也是基于人类学习的机制,我们学习都是基于已有知识的,而不像深度学习一样都是从 0 开始学习的。如果我们已有的先验知识来帮助我们解决新的问题,那么我们对于新的问题就可以不需要那么多的样本,从而解决小样本图像分类的问题。
网络结构

这张图是这篇论文的总体结构:主要包含两个模块,嵌入模块和图像到类的度量模块
第一个模块 :嵌入模块 ,采用的是一个全卷积神经网络(不带有全连接层)
输出是一个h x w x d维的一个张量,可以将长度为d的特征向量看作一个局部描述子Xi(因为卷积神经网络中的卷积核池化操作,会将图像压缩,其中输出的每一个像素,其实代表了原图中的一个局部块),所以一共可以得到m = h x w 个长度为d的局部描述子。
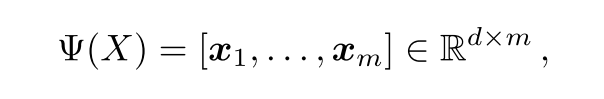
第二个模块:图像到类的模块,主要介绍的是图像到类是怎么计算的
比如:5 way 1shot
支持集:取5个类别,每个类别1个样本
查询集:从支持集中的5个类别中每个类别取15个样本,共75个样本
支持集和查询集中的都经过第一个模块,得到相应的局部描述子。然后对于查询集中的每一张图片来判断属于支持集中的哪一类
计算公式如下:

总结
本文的创新点主要有两个:
1.将基于度量学习的小样本学习算法的图像级别的特征向量改为局部描述子
2.将图像与图像之间的相似度量,通过求和改为图像到类的相似度量















 2950
2950











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









