







原文下载:https://arxiv.org/pdf/1903.12290v1.pdf
源码地址:https://github.com/WenbinLee/DN4
部分引用格式的是我自己添加的一点认识,其他部分都是摘自深视大佬:https://blog.csdn.net/qq_36104364/article/details/106479996
动机和笔记
在图像级别学习嵌入可能不够有效,这里采用基于局部描述符的图像到类的度量,灵感来自于局部不变特征当年的强大之处。不够有效的原因下文有说。
本文将同一类的所有训练样本的深度局部不变特征集合到一个池中,然后对于查询图像,测量其局部不变特征最近的类别。
创新点:不再使用基于图像级别的特征进行分类,而是基于deep local descriptors 和image-to-class度量。
其中,image-to-class模块是非参数化的,即直接使用最近邻,因此泛化性更强一点。
核心思想
本文采用基于度量学习的方式实现小样本学习任务,但与其他基于度量学习的方式不同,本文通过比较图像与类别之间的局部描述子(Local Descriptor),来寻找与输入图像最接近的类别。本文的灵感来自于朴素贝叶斯最近邻算法(Naive-Bayes Nearest-Neighbor,NBNN),根据这一算法作者有两点发现:一、如果将一幅图像的特征信息压缩到一个紧凑的图像级别的表征(换言之就是用一个特征向量或者特征图来表示一张图片),这将会损失许多有区分度的信息,而且这种损失在训练集较少的情况下是无法被恢复的。二、如果采用图片与图片之间的比较,直接使用局部特征进行分类是不可能的,这是因为即使是相同类别的两幅图片,他在局部区域上特征也有很大的差别(比如都是狗,但是不同狗的尾巴区别也很大)。基于这两点观察,作者提出了本文的算法深度最近邻神经网络(Deep Nearest Neighbor Neural Network ,DN4),首先对于图像特征描述,作者并没用采用图像级的特征向量,而是使用若干个局部描述子,每个局部描述子对应图片中的一个局部区域;其次,在分类时,作者同样采用了kNN算法,但是与比较两幅图之间的相似性的方法不同,作者比较输入图像与每个类别的局部描述子之间的相似程度,并借此进行分类,这是因为对于一个类别的物体,其公共的特征还是比较接近的。具体的实现方式如下图所示

如图所示,整个网络分成两大部分:嵌入特征提取网络ψ与最近邻分类器ϕ 。首先对于嵌入特征提取网络ψ采用全卷积神经网络,不带有全连接层,因此输出为h × w × d 维的张量,如果将“每一条”长度为d的特征向量看做一个局部描述子xi(因为卷积神经网络中的卷积和池化操作,会将图像压缩,因此输出特征图中的一个像素,其实代表了原图中的一个局部图块),则一共可以得到m = h w 个长度为d 的局部描述子:
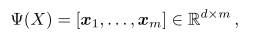
然后对于支持集中每个类别中的每幅图像,都能够得到一个由m个局部描述子构成的描述向量。得到查询图像q 的描述向量[ x1,, . . . , x m ],对于其中的每个局部描述子x1, 在每一个类别c 中都寻找到与其距离最接近的k 个局部描述子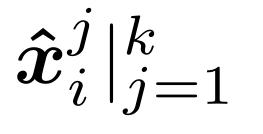 ,则查询图像q 与类别c之间的相似性可以通过对局部描述子之间的余弦相似性求和来得到
,则查询图像q 与类别c之间的相似性可以通过对局部描述子之间的余弦相似性求和来得到
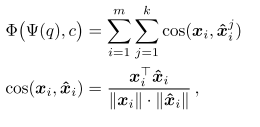
最后选择相似程度最高的那一类别作为预测结果。
实现过程
网络结构
特征提取网络采用4层卷积神经网络,最近邻分类器使用KNN搜索。
损失函数
与常规的基于度量学习的算法相同。
训练策略
与常规的基于度量学习的算法相同。
创新点
将基于度量学习的小样本学习算法中的图像级别的特征向量,改为局部描述子
将图像与图像之间的相似性度量,通过求和方式改为图像与类别之间的相似性度量
算法评价
本文最重要的思想在于使用局部描述子取代简单的图像特征向量,虽然结构上并没有什么变化,只不过取消了全连接层,但是在思想上是有很大区别的。之前的特征向量是希望特征提取网络能够将图像特征高度抽象化,将其转化为一个对位置不敏感的向量,在进行比较时也是直接度量两个图像对应的特征向量之间的距离,这对于小样本学习来讲可能比较困难。而本文则这种特征描述要求放宽到局部区域上了,**我不要求两张图片每个位置都很相似,但要求你最相似的k个区域是非常接近的,这就消除了类内差异和背景混淆的问题。**这一思想其实与之前解读的一篇文章《Spot and Learn: A Maximum-Entropy Patch Sampler for Few-Shot Image Classification》非常接近,根据实验结果来看相对于其他的基于度量学习的算法,如Matching Network和Prototypical Network,效果都有明显的改善。
加粗部分指的是对于背景复杂多变的对象,可以过滤掉无关的背景信息,仅仅关注该对象的固有特征。
————————————————
这里作者还做了一个实验探究shots对精度的影响。探索了类别数量相等的情况下,训练集和测试集shot不匹配时的精度,基本结论是训练的shot越多越好。

版权声明:本文为CSDN博主「深视」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_36104364/article/details/106479996















 443
443











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









