







对Series数据结构的理解:
(1)Series是Pandas中的数据结构;
(2)Series是DataFrame的一列数据;
(3)Series的索引,默认为0,1,2,3,4,5...,与列表不同的是Series的index可以自定义,列表不能自定义索引;
(4)Series有名字name,相当于列名;
(5)Series数据是对列表的封装;
总结:Series是由一维数组组成,具有索引和name的一种数据结构,且可以自定义索引的一种数据结构。
| Series的数据结构 | ||
| 位置索引 | 标签索引 | 值(name) |
| 0 | a | 1 |
| 1 | b | 2 |
| 2 | c | 3 |
| 3 | d | 4 |
| 4 | e | 5 |

目录
一、 Series数据的创建
import pandas as pd
import numpy as np
#通过数组创建
arr=np.arange(5)
s=pd.Series(arr,name='A')
#通过列表创建
lista=[0,1,2,3,4]
s=pd.Series(lista,name='A')
#通过字典创建,字典的键为索引,值为Series的值
dicta={0:0,1:1,2:2,3:3,4:4}
s=pd.Series(dicta,name='A')
sSeries数据可以通过数组,列表,字典来创建,在创建的过程中可以定义name和index。
二、Series数据的索引(标签)
2.1Series数据的索引
Series数据的默认索引为0,1,2,3,4,5...,也称位置索引或隐式索引,后文称位置索引。自定义索引后,后文称为标签索引,任然可以以位置索引访问Series。
2.2通过索引查找Series的值
s=pd.Series(np.arange(5),name='A',index=['a','b','c','d','e'])
#通过位置索引
#单个值
s[2]
#使用属性索引
s.c
#多个值
s[2:4]
#通过标签索引
#单个值
s['c']
#多个值
s[['c','d']]Series通过位置索引和标签索引都可以访问元素,使用位置索引访问时,与列表一样,使用切片的方式;使用标签索引时,访问一个值标签放在‘[ ]’内,访问多个值,标签放在'[[ ]]'。
2.3Series数据的删除
#Series元素的删除
s=pd.Series(np.arange(5),name='A',index=['a','b','c','d','e'])
#单个值删除
# s.drop('c',inplace=True)
#多个值删除
s.drop(['c','e'],inplace=True)
sSeries数据的删除,使用s.drop()函数,删除单个值为索引,inplace参数为是否作用在原数据上。
2.4Series元素的修改
#Series元素的修改
#修改单个值
s.b=5
s[1]=5
#修改多个值
s[:2]=[8,9]
sSeries元素的修改,使用Series切片的方式,修改方式与列表一样。
三、Series的算数运算和数据对齐
3.1Series的算数运算
# Series的算数运算
s1=pd.Series(np.arange(5),name='A',index=['a','b','c','d','e'])
s2=pd.Series(np.arange(5,10),name='A',index=['a','b','c','d','e'])
s3=pd.Series(np.arange(5,10),name='B',index=['a','b','c','d','f'])
s4=pd.Series(['张三','李四','王五','赵六','麻七'],index=['a','b','c','d','e'])
s5=pd.Series(['1','2','3','4','5'],name='序号',index=['a','b','c','d','e'])
print(s1+s2)
print('='*100)
print(s1+s3)
print('='*100)
print(s4+s5)
print('='*100)
(1)我们定义了5个Series数据结构,s1,s2,s3的数据类型为int32,s1与s2相加,得到了一个新的Series,如下:
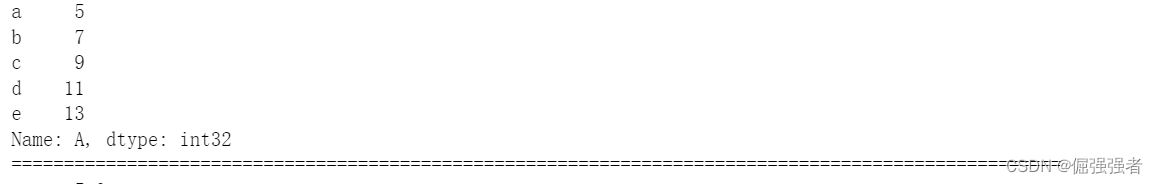
两个int32的Series数据相加,得到了数据的和。
(2)s3改变了一个Series数据的索引,将索引'e'改为'f',s1+s3结果如下:

显而易见,两个'int32'的Series相加,是将对应索引上面的数值相加,如果没有对应索引,返回空值。
(3)s4与s5的的数值类型为'object',s4+s5得到的结果为:

两个‘object’的Series相加,会将对应索引的元素进行拼接,其拼接形式与字符串的拼接一致。
3.2Series数据对齐
Series的数据对齐是指pandas自动将数据转换为统一的数值类型。
#数据对齐
s1=pd.Series([1,2,3,None,4],name='A',index=['a','b','c','d','e'])
s2=pd.Series([1,2,3,'',4],name='A',index=['a','b','c','d','e'])
print(s1)
print('='*140)
print(s2)
现在有两组Series数据,数据内的数值类型不一致,运行输出s1和s2,s1的dtype为数值型‘float64’,s2的dtype为字符串型‘object’,我们将这种自动统一数值类型的方式叫做数据对齐。在实际的应用过程中,要特别注意,如果数值类型不一致,需要进行转换。
四、Series的常见用法
#空值判断
s=pd.Series([1,2,3,np.nan,4,2],name='A',index=['a','b','c','d','e','f'])
s.isnull()
s.notnull()
#重复值查看
s=pd.Series([1,2,3,np.nan,4,2],name='A',index=['a','b','c','d','e','f'])
print(s.duplicated())
#删除重复值
s.drop_duplicates(inplace=True)
s
#显示唯一值
s=pd.Series([1,2,3,np.nan,4,2],name='A',index=['a','b','c','d','e','f'])
s.unique()
#统计性描述分析
s=pd.Series([1,2,3,np.nan,4,2],name='A',index=['a','b','c','d','e','f'])
s.describe()
#重置索引
s=pd.Series([1,2,3,np.nan,4,2],name='A',index=['a','b','c','d','e','f'])
s1=pd.Series(np.arange(5,11))
s.reset_index(drop=True)五、Series数据基本操作总结
| Series数据的基本操作总结 | ||
| Series的创建 | 通过数组创建 | pd.Series(数组,name,index) |
| 通过列表创建 | pd.Series(列表,name,index) | |
| 通过字典创建 | pd.Series({索引:值...},name) | |
| Series的索引 | 位置索引 | Series[位置索引] |
| 标签索引 | Series[[标签索引]] | |
| Series的删除 | Series.drop(索引) | |
| Series的修改 | Series[位置索引]=值 | |
| Series的算数运算 | 数值型相加 | 数值型相加,返回对应位置的和 |
| 字符串型相加 | 字符串拼接 | |
| Series的数据对齐 | 统一Series的数据类型 | |
| Series的常见用法 | 空值判断 | Series.isnull() |
| 非空值判断 | Series.notnull() | |
| 查看重复值 | Series.duplicated() | |
| 删除重复值 | Series.drop_duplicates(inplace=True) | |
| 查看唯一值 | Series.unique() | |
| 描述性统计分析 | Series.describe() | |
| 重置索引 | Series.reset_index(drop=True) | |
















 1139
1139











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











