







批量梯度下降法(Batch Gradient Descent,BGD):在更新参数时,BGD根据batch中的所有样本对参数进行更新。(计算速度快)
随机梯度下降法(Stochastic Gradient Descent,SGD):和BGD的原理类似,区别在于每次随机选取一个样本j求梯度。(计算性能好,耗时)
小批量梯度下降法(Mini-batch Gradient Desent,也称Mini-batch SGD):BGD和SGD二者的折中法,对于m个样本,选取x个子样本进行迭代,且1<x<m。
均和性能和训练时间需求:mini-batch

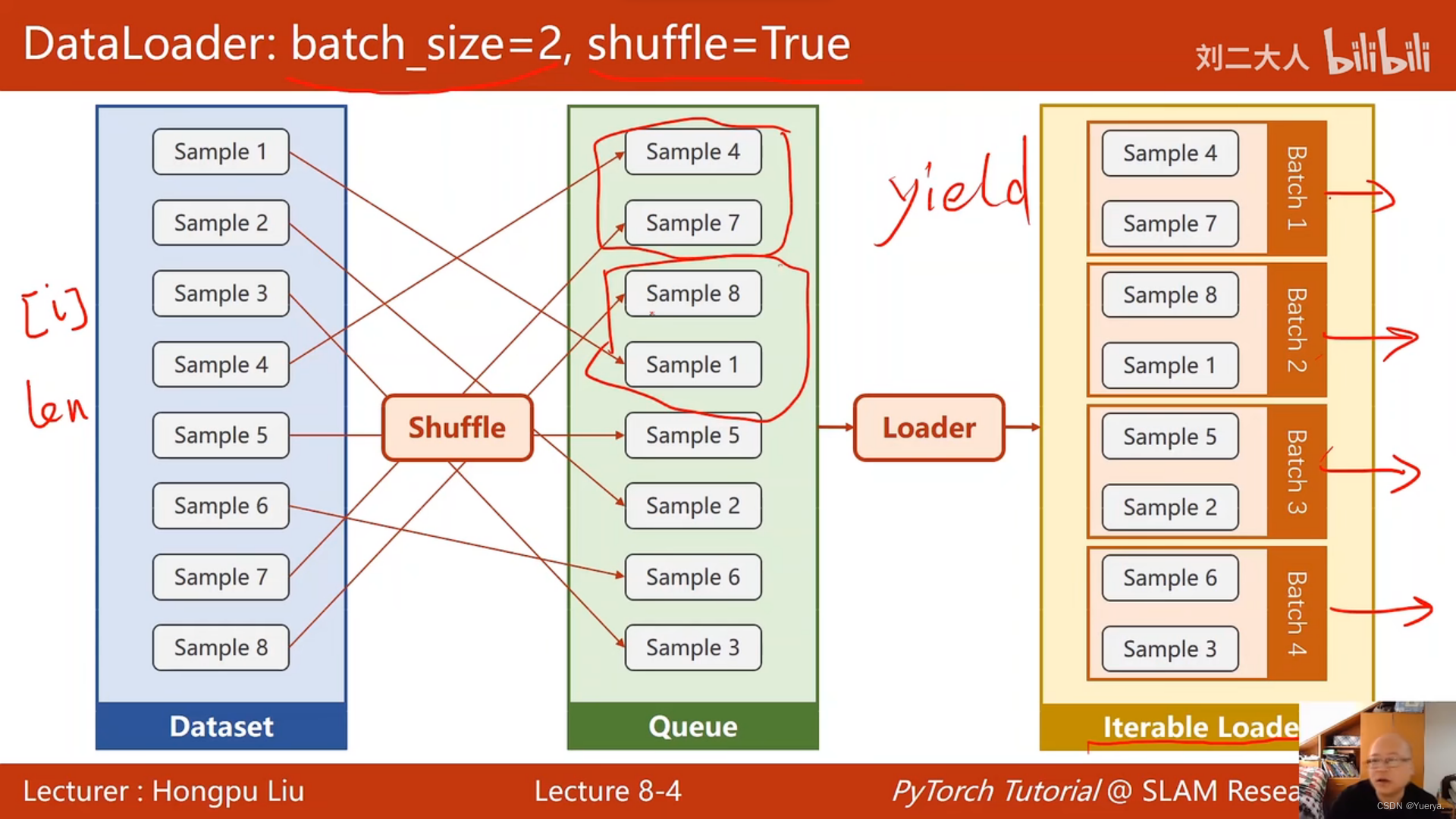
shuffle:打乱数据集顺序
用for in循环把里面batch依次拿出来
dataset是一个抽象类,由自己设计继承
dataLoader帮助自助加载数据(shuffle\batch_size)
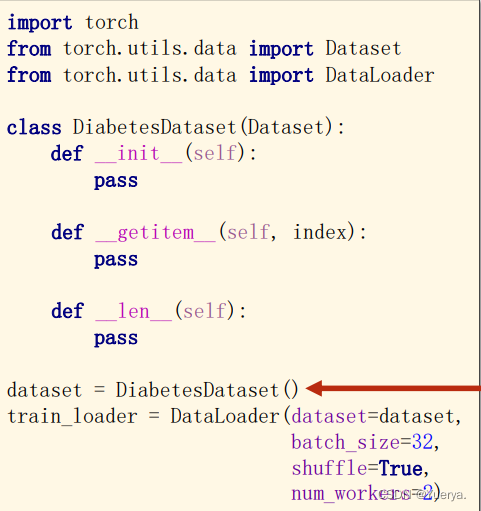
1.class()中表示继承dataset的类
2.getitem用于通过下标索引把数据拿出来(魔法方法)
3.len可以把数据数量拿出来
4.init有两种选择:a.把所有数据都加载到内存里面,用getitem把每一个[i]传出去(用于数据集本身不大);b.放入pack文件里面,定义一个列表把每一个数据集文件放到相应列表or标签中用getitem读取i列表j文件元素(数据集本身很大)
5.dataloader参数:数据集参数,容量,是否打乱,使用多线程数量
多线程时需要注意加上: if_name_=='_main_'

1.len/batch_size=epoch中需要迭代次数
2.inputs, labels = data中的inputs的shape是[32,8],labels 的shape是[32,1]。也就是说mini_batch在这个地方体现的

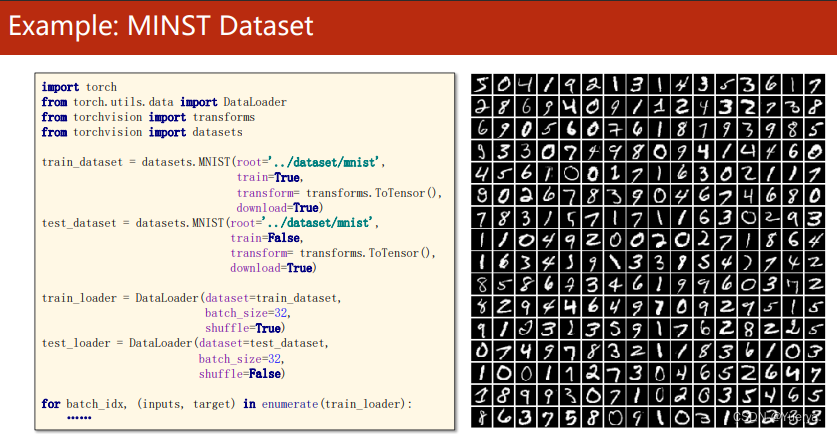
pandas库用于数据分析和处理















 818
818











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









