







 本文详细介绍了PyTorch中内置数据集如MNIST、CIFAR、COCO和ImageNet的加载过程,以及如何使用torchvision.transforms进行数据预处理。同时,展示了如何自定义数据集,如ImageFolder加载方式和自定义子类Dataset的使用,以手动加载MNIST数据并进行数据加载和可视化。
本文详细介绍了PyTorch中内置数据集如MNIST、CIFAR、COCO和ImageNet的加载过程,以及如何使用torchvision.transforms进行数据预处理。同时,展示了如何自定义数据集,如ImageFolder加载方式和自定义子类Dataset的使用,以手动加载MNIST数据并进行数据加载和可视化。
1.数据集种类
在Pytorch中存在2种Dataset,即内置数据集和自定义数据集。该2种数据集在使用时有所区别。
2.内置数据集加载
2.1 内置数据集介绍
PyTorch自带了许多常用的数据集,主要用于CNN网络的数据集主要有:
MNIST/FashionMNIST:手写数字图像数据集,用于图像分类任务。
CIFAR:包含10个类别、60000张32x32的彩色图像数据集,用于图像分类任务。
COCO:通用物体检测、分割、关键点检测数据集,包含超过330k个图像和2.5M个目标实例的大规模数据集。
ImageNet:包含超过1400万张图像,用于图像分类和物体检测等任务。
Penn-Fudan Database for Pedestrian Detection and Segmentation:用于行人检测和分割任务的数据集。
STL-10:包含100k张96x96的彩色图像数据集,用于图像分类任务。
2.2 内置数据集加载
自带数据集可以通过PyTorch的torchvision.datasets模块中的函数进行加载,加载的格式固定,需要变化的为transform方法,根据实际项目需求进行更改即可。
内置数据集加载格式如下:
import torchvision
train_data = torchvision.datasets.MNIST(root='./data',
train=True,
transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.MNIST(root='./data',
train=False,
transform=torchvision.transforms.ToTensor(),
download=True)执行上述代码后,下载的数据会存放在当前目录的data文件夹下。
参数:
train = False表示只下载测试数据,不下载训练数据,True表示下载训练数据。
transform=torchvision.transforms.ToTensor()标示数据集转换成tensor数据类型(从 PIL 图像转换为 PyTorch 张量。 0 到 255 -> 0.0 到 1.0 )。
download=True会检测你的data文件夹中是否有该数据集,如果已经下载了,就不会继续下载了,如果是false就是不下载数据,所以这个代码运行之后不会重复下载数据。
下载数据如下:
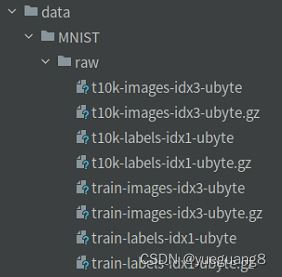
- train-images-idx3-ubyte.gz:训练集数据
- train-labels-idx1-ubyte.gz: 训练集标签
- t10k-images-idx3-ubyte.gz: 验证集数据
- t10k-labels-idx1-ubyte.gz: 验证集标签
2.3 数据可视化
可视化操作可以对加载的数据集中的数据进行直观的观察,便于了解数据样式。
实现代码如下:
#数据可视化
import matplotlib.pyplot as plt
labels_map = {
0:'0',
1:'1',
2:'2',
3:'3',
4:'4',
5:'5',
6:'6',
7:'7',
8:'8',
9:'9'
}
#figsize”参数用于设置图像的大小,单位为英寸(inch),此例中的大小为10英寸宽度和10英寸高度。
#另外,还可以通过其他参数设置画面的分辨率,背景色和边缘宽度等属性。
figure=plt.figure(figsize=(10,10), dpi=56)
cols, rows = 4, 4
for i in range(1, cols*rows+1):
index = torch.randint(len(train_data), size=(1,)).item()
img,label = train_data[index]
figure.add_subplot(rows, cols, i) #创建子图,
plt.title(labels_map[label])
plt.axis('off') #关闭坐标轴
plt.imshow(img.squeeze(), cmap='gray')
plt.show() #显示图像Note: 原始的img.shape为(H,W,1)。squeeze()函数的功能是:从矩阵shape中,去掉维度为1的。例如一个矩阵是的shape是(28, 28, 1),使用过这个函数后,结果为(28,28),因此img.squeeze() 对应的shape为(H,W)。
可视结果如下图所示:

3 自定义数据集
自定义数据集加载也存在2种类型格式:
使用ImageFolder 加载数据集;自定义子类加载数据集。
3.1 使用ImageFolder 加载数据集
ImageFolder 适合于分类数据集,并且每一个类别的图片在同一个文件夹, 训练数据为文件件下的图片, 训练标签是对应的文件夹, 每个文件夹为一个类别,label是按照文件夹名顺序排序后存成字典,即{类名:类序号(从0开始)},一般情况下直接将文件夹命名为从0开始的数字,这样会和ImageFolder实际的label一致,否则, 需要制定label和文件夹名的映射关系。
使用类 torchvision.datasets.ImageFolder 进行数据加载。
3.2 自定义子类加载数据集
自定义数据集,需要定义一个子类,继承Dataset类, 重写 len(), getitem() 方法。
Dataset定义了数据集的内容,它相当于一个类似列表的数据结构,具有确定的长度,能够用索引获取数据集中的元素。【本质:大数组】
Dataset类的使用: 是一个抽象类,所有的类都应该是此类的子类(也就是说应该继承该类)。 所有的子类都要重写__len__方法和__getitem__方法。
示例代码为读取MNIST的RAW数据的子类:
import os.path
import numpy as np
import torch
import gzip
################# 手动加载数据 ###################
class MyMnistDataset(Dataset):
def __init__(self, folder, data, label, transform=None):
(dataset, label) = self.load_data(folder, data, label)
self.dataset = dataset
self.label = label
self.tranform = transform
def __getitem__(self,index):
img, label = self.dataset[index], self.label[index]
if self.tranform is not None:
#img = self.tranform(img) #会报waring:The given NumPy array is not writable
img = self.tranform(np.array(img, copy=True))
return img, label
def __len__(self):
return len(self.dataset)
def load_data(self, folder, data, label):
with gzip.open(os.path.join(folder, label), 'rb') as lbpath:
label_set = np.frombuffer(lbpath.read(), np.uint8, offset=8)
print("y_train len={0}".format(len(label_set)))
with gzip.open(os.path.join(folder, data), 'rb') as datapth:
#image_set = np.frombuffer(datapth.read(), np.uint8, offset=16).reshape(len(label_set), 28, 28)
image_set = np.frombuffer(datapth.read(), np.uint8, offset=16).reshape(-1, 28, 28)
return (image_set, label_set)
myTrainData = MyMnistDataset("./data/MNIST/raw",
"train-images-idx3-ubyte.gz",
"train-labels-idx1-ubyte.gz",
transform=torchvision.transforms.ToTensor())
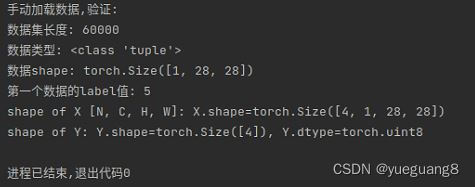
print("\n手动加载数据,验证:")
print("数据集长度:", len(myTrainData))
print("数据类型:", type(myTrainData[0])) #tuple
print("数据shape:", myTrainData[0][0].shape)
print("第一个数据的label值:", int(myTrainData[0][1]))
loader1 = DataLoader(dataset=myTrainData, shuffle=True, batch_size=4, num_workers=0, drop_last=False)
for X,Y in loader1:
print('shape of X [N, C, H, W]: X.shape={0}'.format(X.shape))
print('shape of Y: Y.shape={0}, Y.dtype={1}'.format(Y.shape, Y.dtype))
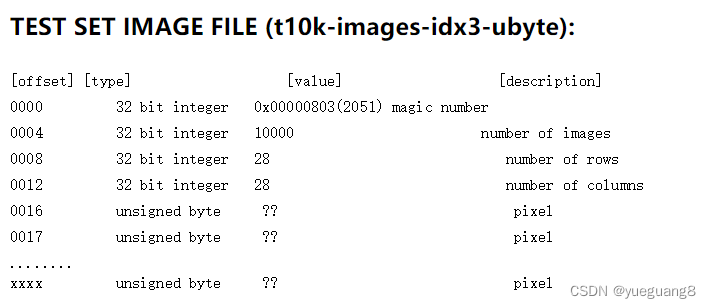
break读取数据操作中offset=8 及 offset=16说明:
MNIST数据集的官方页面介绍了Label数据格式,0-3字节为魔法数,4-8字节为序号。所以加载数需要从第8个数据开始。

同理,针对于数据部分,从第16字节开始是数据部分,所以读取数据时需要跳过前16个字节
通过构造自定义数据集加载方式,运行结果如下图所示
4. 总结
本文章介绍了pytorch内置数据加载以及自定义数据集加载的代码格式及相关参数;代码示例手动加载MNIST数据集,构造自定义数据集进行代码演示说明。















 1753
1753











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









