






一、任务内容
(1)了解Groceries_dataset.csv中事务集的属性信息,根据每个用户每天的购买记录构造事务(比如用户1000在2015年3月15日对应的事务为{‘sausage’,’whole milk’,’semi-finished bread’,’yogurt’}),然后按照用户ID递增,时间递增的方式对事务进行排序;
(2)选择事务集中前100条事务,选择合适的支持度阈值,使用Apriori算法和FP-growth算法挖掘频繁项集(推荐使用mlxtend包的apriori和fpgrowth函数),并对比apriori算法和fpgrowth算法的时间复杂度;
(3)重复步骤(3),依次选择前500条,前1000条事务,对比apriori算法和fpgrowth算法的时间复杂度;
(4)使用前100条事务时,选择合适的置信度阈值,利用挖掘到的频繁项集生成强关联规则(推荐使用mlxtend包的association_rules函数)。然后使用提升度、全置信度、最大置信度、Kluc度量和余弦度量评估这些强关联规则。
二、实现过程
1. 了解Groceries_dataset.csv中事务集的属性信息,根据每个用户每天的购买记录构造事务,然后按照用户ID递增,时间递增的方式对事务进行排序;
打开Groceries_dataset.csv文件,如下图所示:

观察发现共有三列,分别为会员ID,时间和购买商品,每一行只有一种商品。需要根据ID和时间进行合并,生成事务集。
编写函数loadDataset读入数据并进行合并、转化为二元表:读入.csv文件,使用df.groupby()将数据按ID和时间分组合并,提取合并后grouped['itemDescription']作为dataset;使用mlxtend包中的TransactionEncoder将list转化为dataframe类型的二元表,输出如下图所示:

输出显示[14963 rows x 167 columns],说明该数据集中商品种类共167种,共有14963条事务。
相关代码如下所示:
def loadDataset():
csv_file = 'Groceries_dataset.csv' # 用你的数据集文件名替换
df = pd.read_csv(csv_file)
# 将数据按ID和时间分组合并
grouped = df.groupby(['Member_number', 'Date'])['itemDescription'].apply(list).reset_index()
merged_dataset = grouped['itemDescription'].tolist()
# print(merged_dataset)
Encoder = TransactionEncoder()
encoded_data = Encoder.fit_transform(merged_dataset)
df_encoded = pd.DataFrame(encoded_data, columns=Encoder.columns_)
# pd.set_option('display.max_columns', None)
print(df_encoded)
return df_encoded
2. 选择事务集中前100条事务,选择合适的支持度阈值,使用Apriori算法和FP-growth算法挖掘频繁项集,并对比apriori算法和fpgrowth算法的时间复杂度;
在调用每个算法开始前计时star_time=time.time(),结束时再次计时end_time=time.time(),两个时间相减得出算法运行时间。
调用库中apriori函数和fpgrowth函数:apriori(data1, min_support=0.02, use_colnames=True),fpgrowth(data1, min_support=0.02, use_colnames=True)。设置支持度阈值为0.02,两种算法运行结果如下:

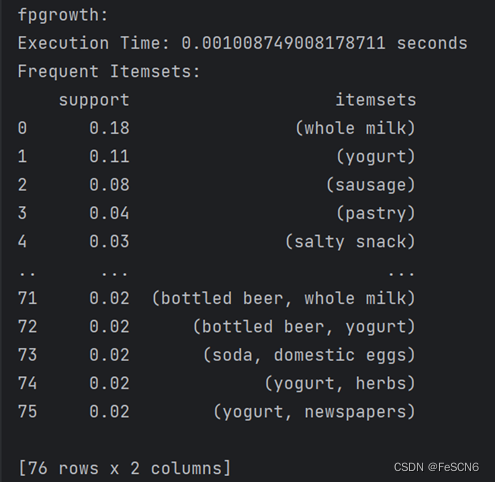
其中,apriori算法运行时间为0.0029997825622558594 s,fpgrowth算法运行时间为0.001008749008178711 s,快于apriori算法。
相关代码如下:
if __name__ == "__main__":
dataset = loadDataset()
data1 = dataset[0:100]
data2 = dataset[0:500]
data3 = dataset[0:1000]
start_time_apriori = time.time()
frequent_itemsets_apriori = apriori(data1, min_support=0.02, use_colnames=True)
end_time_apriori = time.time()
print("\nApriori:")
print(f"Execution Time: {end_time_apriori - start_time_apriori} seconds")
print(f"Frequent Itemsets:\n{frequent_itemsets_apriori}")
start_time_fpgrowth = time.time()
frequent_itemsets_fpgrowth = fpgrowth(data1, min_support=0.02, use_colnames=True)
end_time_fpgrowth = time.time()
print("\nfpgrowth:")
print(f"Execution Time: {end_time_fpgrowth - start_time_fpgrowth} seconds")
print(f"Frequent Itemsets:\n{frequent_itemsets_fpgrowth}")
3. 重复上一步,依次选择前500条,前1000条事务,对比apriori算法和fpgrowth算法的时间复杂度;
选择前500条事务运行结果如下:


( 500条事务(Apriori算法))


(500条事务(fpgrowth算法))
选择前1000条事务运行结果如下:
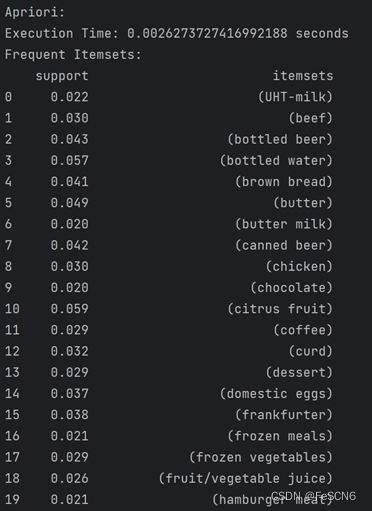

(1000条事务(Apriori算法))


(1000条事务(fpgrowth算法))
从结果看出在事务较少时(100条事务时),fpgrowth算法快于Apriori算法。而事务较多时(500/1000条事务时),两种算法花费时间差别不大或Apriori算法快于fpgrowth算法。并且,如果在整个数据集上(38765条事务)跑这两个算法,Apriori花费时间0.054 s而fpgrowth花费时间0.038 s,Apriori明显慢于fpgrowth。

4. 使用前100条事务时,选择合适的置信度阈值,利用挖掘到的频繁项集生成强关联规则。然后使用提升度、全置信度、最大置信度、Kluc度量和余弦度量评估这些强关联规则。
使用association_rules(frequent_itemsets_apriori, metric="confidence", min_threshold=0.5)生成关联规则,设置置信度阈值为0.5。打印关联规则前五行结果如下所示:

观察发现总共生成了8个关联规则。其中:1)antecedents为关联规则中的前件;2)consequents为关联规则中的后件;3)antecedent support为前件的支持度;4)consequent support为后件的支持度;5)support为规则的支持度,指同时包含前件和后件的事务数与总事务数的比;6)confidence为规则的置信度;7)lift为提升度,大于1表示正相关,等于1表示无关,小于1表示负相关;8)leverage为杠杆度,衡量了前项和后项共同出现的频率超过了预期的程度;9)conviction为最大置信度,是基于规则的置信度计算的,可以衡量前项和后项的独立性程度,较高的值表示较强的依赖性;10)zhangs_metric为一种关联规则评价指标,综合考虑了关联规则的支持度、提升度、置信度等。
(1) 打印各个关联规则的提升度:
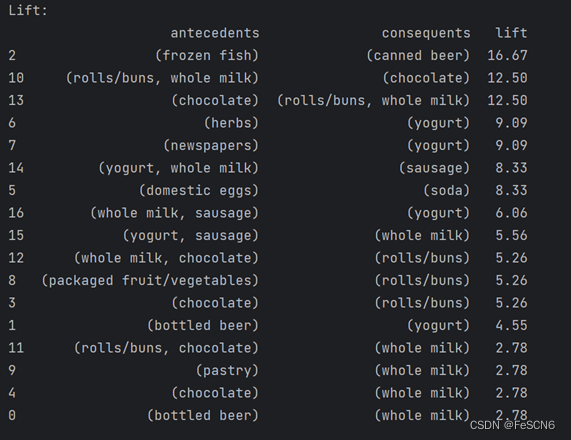
观察发现,关联规则lift均大于1 ,说明前件与后件均为正相关。
(2) 打印各个关联规则的全置信度:(全置信度计算公式为min{P(X|Y), P(Y|X)} )

(3) 打印各个关联规则的最大置信度:(最大置信度计算公式为max{P(X|Y), P(Y|X)} )

(4) 打印各个关联规则的Kulc度量:(Kulc计算公式为1/2( P(X|Y)+P(Y|X) ) )

(5)打印各个关联规则的余弦度量:
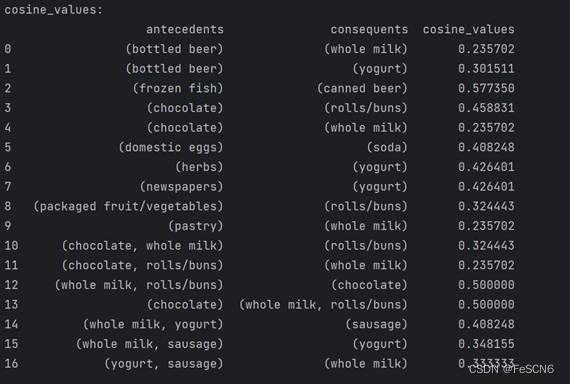
相关代码如下:
# 生成关联规则
rules = association_rules(frequent_itemsets_apriori, metric="confidence", min_threshold=0.5)
print("Generated Association Rules:")
print(rules. Head())
# 评估关联规则
rules["lift"] = rules["lift"].round(2)
rules["leverage"] = rules["leverage"].round(2)
rules["conviction"] = rules["conviction"].round(2)
print("\nAssociation Rules Evaluation:")
print("Lift:")
print(rules.sort_values(by="lift", ascending=False)[['antecedents', 'consequents', 'lift']])
all_confidence = []
kulc_values = []
max_confidence = []
cosine_values = []
# 针对每条关联规则
for idx, row in rules.iterrows():
antecedent = row['antecedents']
consequent = row['consequents']
# print(antecedent)
# print(consequent)
# 寻找规则前项到后项的置信度
confidence_antecedent_to_consequent = \
rules.loc[(rules['antecedents'] == antecedent) & (rules['consequents'] == consequent)]['support'].values[0]\
/ rules.loc[(rules['antecedents'] == antecedent) & (rules['consequents'] == consequent)]['antecedent support'].values[0]
# 寻找规则后项到前项的置信度
confidence_consequent_to_antecedent = \
rules.loc[(rules['antecedents'] == antecedent) & (rules['consequents'] == consequent)]['support'].values[0] \
/ rules.loc[(rules['antecedents'] == antecedent) & (rules['consequents'] == consequent)]['consequent support'].values[0]
# 计算各相关性度量
kulc_measure = 0.5 * (confidence_antecedent_to_consequent + confidence_consequent_to_antecedent)
cosine_measure = (confidence_antecedent_to_consequent * confidence_consequent_to_antecedent) ** 0.5
all_confidence.append(min(confidence_antecedent_to_consequent, confidence_consequent_to_antecedent))
max_confidence.append(max(confidence_antecedent_to_consequent, confidence_consequent_to_antecedent))
kulc_values.append(kulc_measure)
cosine_values.append(cosine_measure)
# 添加全置信度列到 rules
rules['all_confidence'] = all_confidence
print("\nAll_confidence:")
print(rules[['antecedents', 'consequents', 'all_confidence']])
# 添加全置信度列到 rules
rules['max_confidence'] = max_confidence
print("\nMax_confidence:")
print(rules[['antecedents', 'consequents', 'max_confidence']])
# 添加kulc列到 rules
rules['kulc_values'] = kulc_values
print("\nKulc_values:")
print(rules[['antecedents', 'consequents', 'kulc_values']])
# 添加cosine列到 rules
rules['cosine_values'] = cosine_values
print("\ncosine_values:")
print(rules[['antecedents', 'consequents', 'cosine_values']])
三、总结与结论
1. 在最坏情况下,Apriori 算法的时间复杂度为O(2^N),其中N是数据集中项的数量,因为 Apriori 算法需要多次扫描数据集来发现频繁项集。而fpgrowth算法的时间复杂度通常是O(N*M),其中N是数据集中的项的数量,M是数据集中的事务数量。
2. 使用前100条事务,设置信度阈值为0.5时生成的关联规则提升度均大于1,说明前后件正相关。部分关联规则最大置信度为1,说明前后件同时出现。可以看出kulc度量最大的规则是(frozen fish)->(canned beer),值为0.666667;余弦度量最大的是(frozen fish)->(canned beer),值为0.577350。两者一致表示,(frozen fish)->(canned beer)是该事务集上关联性最紧密的两项。















 976
976











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









