







一、任务背景
论文研究的任务为语义角色标注(Semantic Role Labeling, SLR)。语义角色标注以句子的谓词为中心,不对句子所包含的语义信息进行深入分析,只分析句子中各成分与谓词之间的关系,即句子的谓词(Predicate) - 论元(Argument)结构,并用语义角色来描述这些结构关系。核心的语义角色有A0-5六种,A0通常表示动作的施事,A1通常表示动作的影响等,A2-5 根据谓语动词不同会有不同的语义含义。
在一个句子中,谓词是对主语的陈述或说明,指出“做什么”, “是什么”或“怎么样,代表了一个事件的核心,跟谓词搭配的名词称为论元。语义角色是指论元在动词所指事件中担任的角色。主要有:施事者(Agent), 受事者(Patient), 客体(Theme), 经验者(Experiencer), 受益者(Beneficiary), 工具(Instrument), 处所(Location), 目标(Goal)和来源(Source)等。
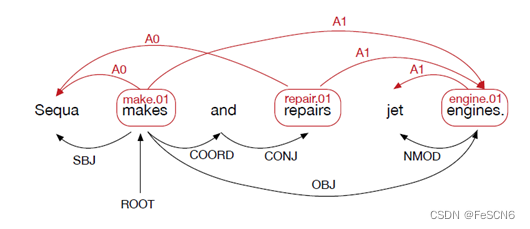
图一:SLR示例
以Figure 1为例,makes, repairs和engines是谓词;针对谓词makes,Sequa是其A0论元,engines是A1论元;针对谓词repairs,Sequa是其A0论元,engines是A1论元;针对谓词engines,jet是其A0论元。
虽然以前有很多SRL方面的工作是基于句法的,但最近SRL却依靠了神经序列模型而将忽视了句法关系,其原因大概是缺乏一种简单高效的方法将句法信息结合到神经网络中。为了解决这个局限性,本文提出了一种将句法信息用GCN有效利用起来,添加到双向LSTM上,有效提高SRL效果的模型。
二、模型方法
1. Graph Convolutional Networks (GCN)
图卷积网络GCN是对图结构数据进行信息处理的一种深度学习模型,为了得到图数据中某顶点A的向量信息,从该顶点A的邻居节点中获取信息进行综合处理。
与传统的卷积神经网络不同,传统卷积神经网络的研究的对象是限制在Euclidean domains的数据,在图像为代表的欧式空间中,结点的邻居数量都是固定的,如图二左侧,绿色结点的邻居始终是8个;而在图这种非欧空间中,结点有多少邻居并不固定,如图二右侧,目前绿色结点的邻居结点有2个,但其他结点也会有5个邻居的情况。欧式空间中的卷积操作实际上是用固定大小可学习的卷积核来抽取特征。但是因为邻居结点不固定,所以传统的卷积核不能直接用于抽取图上结点的特征。于是,设计出了图卷积神经网络,对图数据进行深度学习。
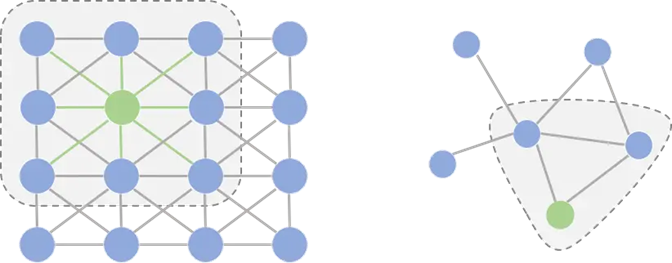
图二:传统卷积(左)与图卷积(右)
具体地说,在GCN中:对于无向图G=(v,ε) ,其中v(|V|=n )是节点集合,节点个数为n;ε 是图中所有边的集合,(v,v)∈ε ,说明边集合包括自环。xv∈<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5686
5686

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









