






1. 构建LeNet-5网络,在CIFAR10数据集上完成分类任务:
(1)构建LeNet-5网络
LeNet-5网络由两个卷积层、两个池化层和三个全连接层构成。选择使用最大池化,激活函数设置为需要传入的参数,便于完成实验2的对比。前向传播过程为:1)第一层卷积 -> 激活函数 -> 第一层池化;2)第二层卷积 -> 激活函数 -> 第二层池化;3)三个全连接层。
网络搭建代码如下:
class LetNet5(nn.Module):
def __init__(self, activation):
super(LetNet5, self).__init__()
# 激活函数
self. activation = activation
# 第一层卷积
self.conv1 = nn.Conv2d(in_channels=3, out_channels=6, kernel_size=5)
# 第一层池化
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)
# 第二层卷积
self.conv2 = nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5)
# 第二层池化
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)
# 三个全连接层
self.fc1 = nn.Linear(16*5*5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.activation(self.conv1(x))
x = self.pool1(x)
x = self.activation(self.conv2(x))
x = self.pool2(x)
x = x.view(x.size(0), -1)
x = self.activation(self.fc1(x))
x = self.activation(self.fc2(x))
x = self.fc3(x)
return x
(2)数据集准备
使用torchvision直接下载Cifar10数据集,设置transform参数为torchvision. transforms.ToTensor(),将图像数据转换为Tensor,数据范围调整到0-1(相当于进行了归一化)。
再使用DataLoader加载数据,设置batch_size为64,在训练集上对数据随机打乱(shuffle=True)以避免过拟合,测试集上则不打乱。
相关代码如下:
train_dataset = datasets.CIFAR10(root=data_path, train=True, download=False,
transform=transforms.ToTensor()) # 首次下载时download设为true
test_dataset = datasets.CIFAR10(root=data_path, train=False, download=False, transform=transforms.ToTensor())
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False)
查看test_dataset的具体内容,发现其数据类型为torchvision.datasets.cifar.CIFAR10,结构类似于list。
![]()
图一:test_dataset类型
输出第一个元素,发现其包含的一个维度为[3, 32, 32]的tensor(表示3通道的32*32图像)和一个标量数据label(表示图像的分类)。
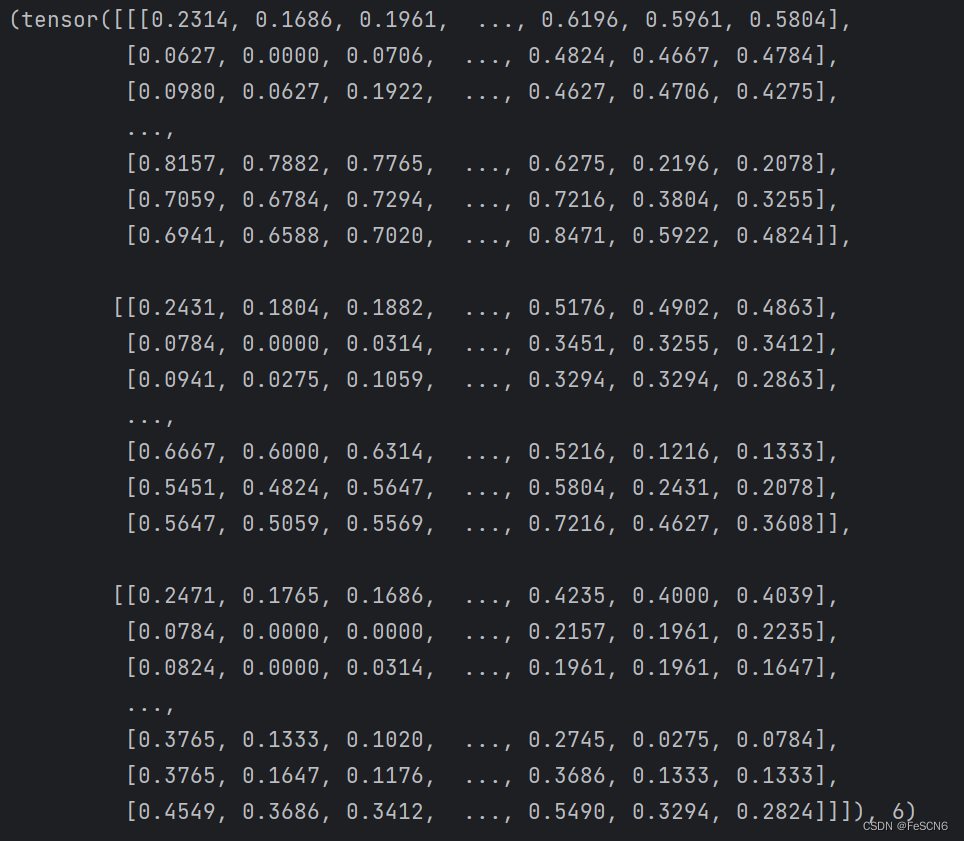
图二:查看第一个元素
(3)定义模型、损失函数和优化器
设置激活函数为ReLU,损失函数为交叉熵损失函数,优化器为Adam优化器、学习率设置为0.001。
相关设置代码如下:
model = LetNet5(activation=nn.ReLU())
model.to(device) # 将模型移动到GPU上
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model. Parameters(), lr=0.001)
(4)模型训练与评估
设置epoch为30,训练模型并打印loss和每轮在训练集上的准确率。在测试集上计算准确率并打印。结果如下:
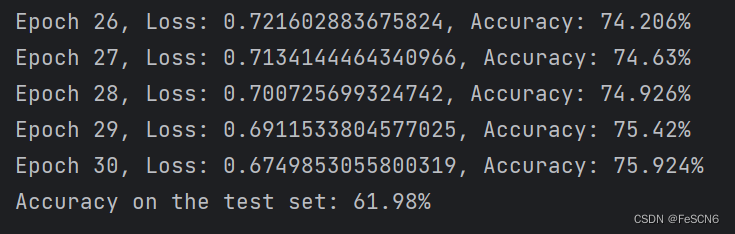
图三:训练30轮结果
可以看到训练集上准确率能达到75%,但是测试集上准确率只有62%。
更改激活函数为Sigmoid和Tanh,训练结果如下:
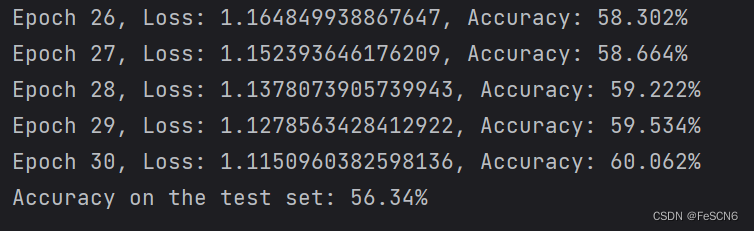
图四:训练30轮结果(Sigmoid)
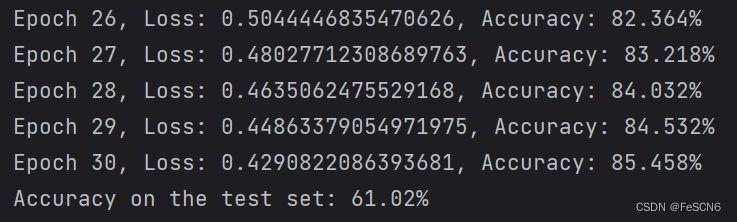
图五:训练30轮结果(Tanh)
比较发现,激活函数为Sigmoid时,在训练集和测试集上的准确率都比较低。而激活函数为Tanh时,训练集上准确率可达85%、测试集上只能达到61%,怀疑发生了过拟合。
2. 对比并分析ReLU、Sigmoid和tanh激活函数对收敛速度的影响,将结果可视化
设置epoch=30,分别使用ReLU, Sigmoid, Tanh激活函数训练模型,可视化训练时的loss变化和训练集上的准确率,结果如下所示:
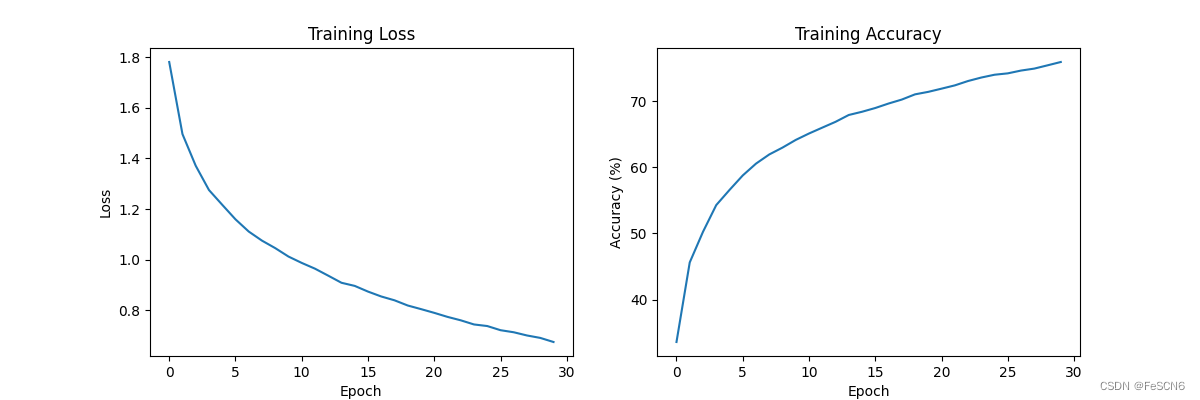
图六:ReLu函数收敛速度及准确率(epoch=30)
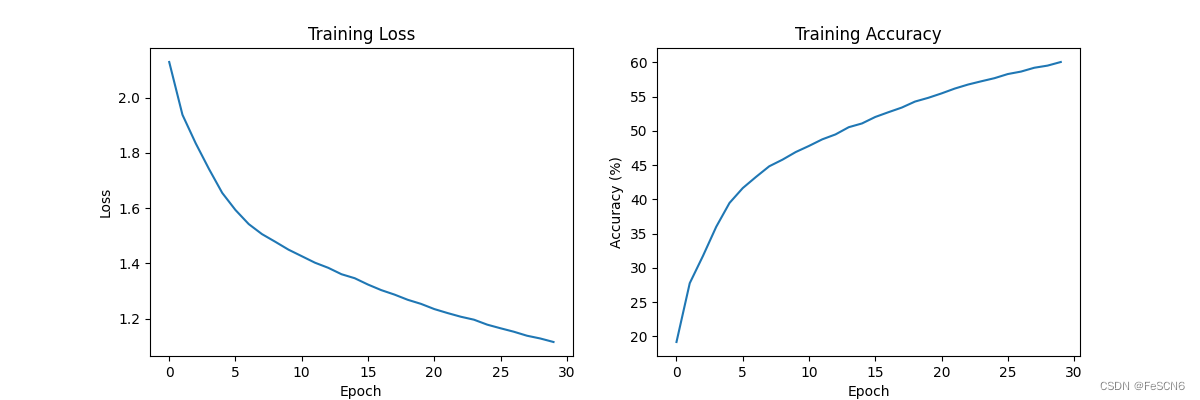
图七:Sigmoid函数收敛速度及准确率(epoch=30)
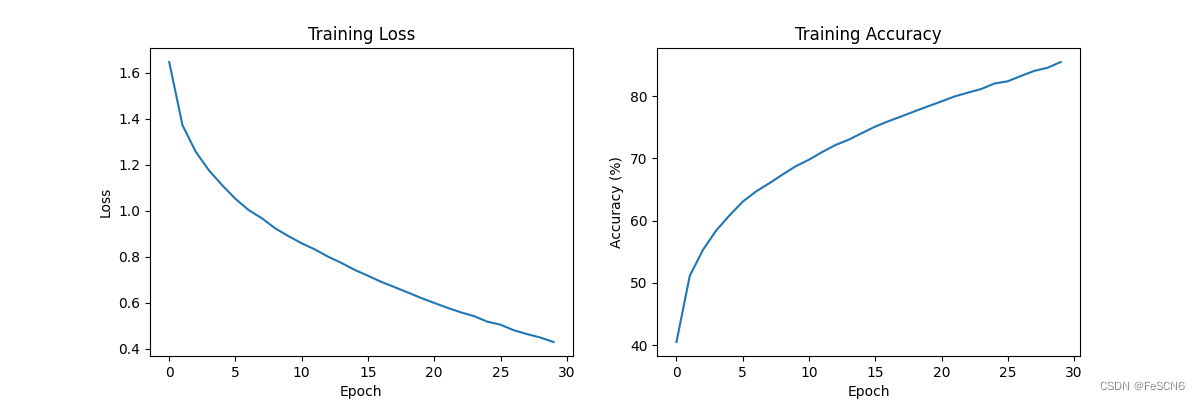
图八:Tanh函数收敛速度及准确率(epoch=30)
通过对比发现,Tanh激活函数收敛速度最快且在训练集上准确率最高,其次是ReLU,最后是Sigmoid。但是课上讲的分析是ReLU 激活函数收敛最快,因为在正数范围内是此函数线性的,而且在负数范围内是零,这样可以减少梯度消失的问题,并且加速了梯度下降的收敛速度。相比之下,Sigmoid 和 Tanh 函数在输入值较大或较小时,梯度较小,容易出现梯度消失问题,且这两个函数计算复杂度较高,所以导致收敛速度较慢。
再对比epoch=10的情况,发现ReLU函数和Tanh收敛速度相差不大,但ReLU稍慢一点。Sigmoid明显收敛速度慢且准确率低。
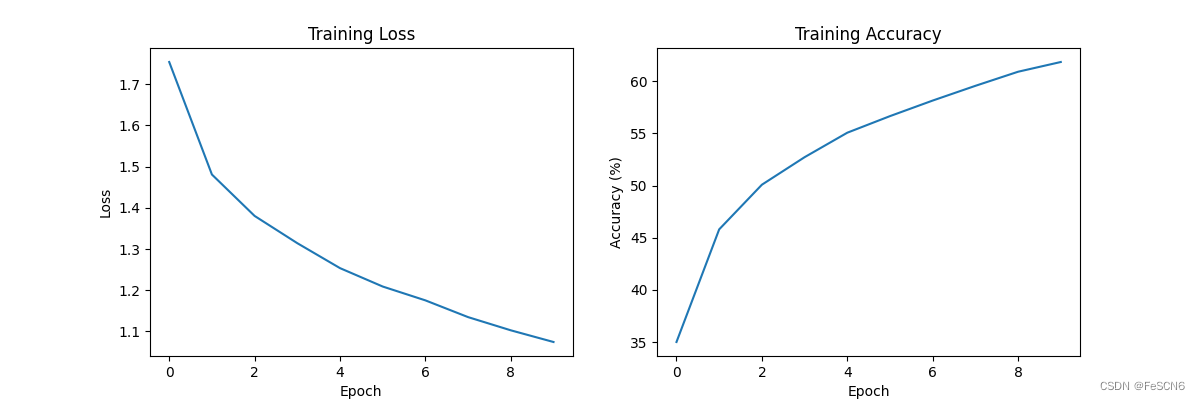
图九:ReLu函数收敛速度及准确率(epoch=10)
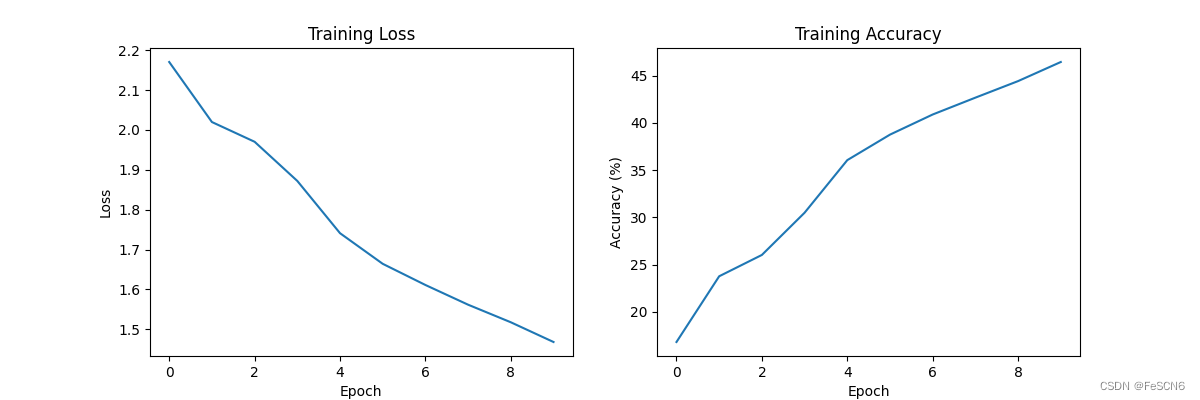
图十:Sigmoid函数收敛速度及准确率(epoch=10)
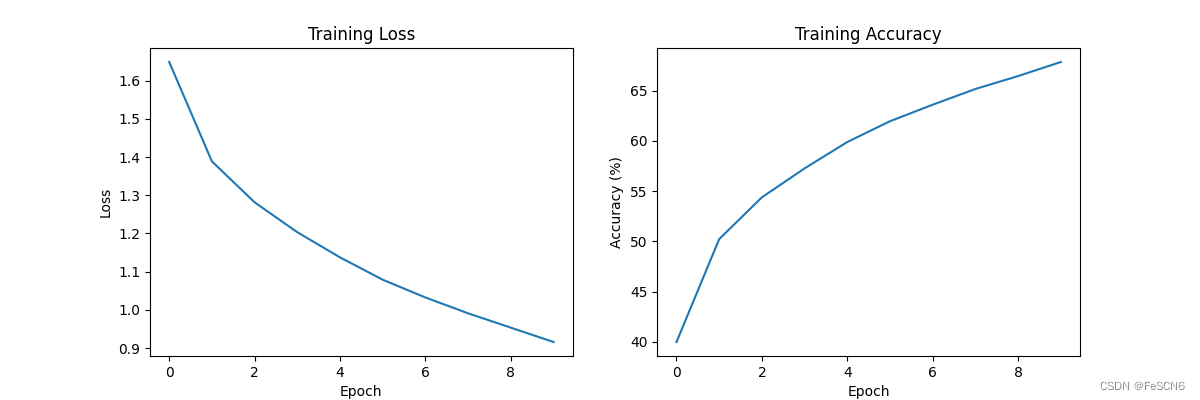
图十一:Tanh函数收敛速度及准确率(epoch=10)
得出结论,实际在这个任务里,激活函数表现为:Tanh好于ReLU好于Sigmoid,具体表现为收敛速度快且准确率高。
3. 总结与结论:
1. 激活函数设置为ReLU时,训练集上准确率能达到75%,但是测试集上准确率只有62%。激活函数为Sigmoid时,在训练集和测试集上的准确率都比较低,低于60%。而激活函数为Tanh时,训练集上准确率可达85%、测试集上只能达到61%,怀疑发生了过拟合。
2. 在设置不同的epoch进行训练并比较发现,激活函数表现为:Tanh好于ReLU好于Sigmoid,具体表现为收敛速度快且准确率高。

















 872
872

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









